





Abstract
智能合约是分布式的、自我执行的程序,在区块链网络上执行。它们有可能彻底改变金融机构和供应链等许多行业。然而,智能合约存在基于代码的漏洞,这为其应用蒙上了一层阴影。由于智能合约不可修补(区块链具有不变性),因此保证智能合约没有漏洞至关重要。不幸的是,诸如 Solidity 之类的智能合约语言是图灵完备的,这意味着静态验证它们是不可行的。因此,必须开发替代方法来提供保证。在这项工作中,我们开发了一种自动转换智能合约的方法,以便它们可以证明没有 4 种常见的漏洞。关键思想是以有效且可证明正确的方式在应用运行时验证。 5000 个智能合约的实验结果表明,我们的方法在时间(即 14.79%)和 gas(即 0.79%)方面产生较小的运行时开销。
INTRODUCTION
区块链是把记录链接在一起的公共列表。 由于底层的密码学机制,区块链中的记录不可修改。以太坊是一个平台,允许程序员编写在区块链网络之上执行的分布式、自我执行的程序(也称为智能合约)。 智能合约一旦部署在区块链网络上,就成为参与方之间不可更改的承诺。因此,它们有可能彻底改变金融机构和供应链等许多行业。 然而,与传统程序一样,智能合约也存在基于代码的漏洞,这可能会造成巨大的经济损失并阻碍其应用。 考虑到智能合约一旦部署在网络上就无法修补,问题就更糟了。 换句话说,确保智能合约在部署之前没有漏洞是至关重要的。
近年来,研究人员提出了多种方法来确保智能合约无漏洞。这些方法大致可以分为两类,即验证和测试。 然而,现有的努力并没有提供所需的保证。 智能合约的验证通常是不可行的,因为智能合约是用图灵完备的编程语言(例如最流行的智能合约语言 Solidity)编写的,而众所周知,测试(智能合约或其他)只显示存在而不是没有漏洞。
在这项工作中,我们提出了一种称为 SGUARD 的方法和工具,它可以自动修复潜在易受攻击的智能合约。 SGUARD 的灵感来自于 C 或 Java 等传统程序的程序修复技术,但专为智能合约而设计。 首先,SGUARD 旨在保证修复的正确性。 现有的程序修复方法(例如,GenFrog [1]、PAR [2]、Sap-fix [3])经常遇到弱规范的问题,即,将测试套件作为正确性规范。 由这种弱正确性标准驱动的修复可能会过度拟合给定的测试套件,并且不能在所有情况下提供正确性保证。 此外,智能合约的修复可能不仅会受到时间开销的影响,还会受到 gas 开销的影响(即额外的运行附加代码的费用),SGUARD 旨在最大限度地减少修复引入的时间和gas方面的运行时开销。请注意,我们的静态分析引擎是从头开始构建的,因此扩展现有的智能合约静态分析引擎(例如,Securify [4] 和 Ethainter [5])是不可行的。例如,他们的语义规则集是不完整的,有时会产生相互矛盾的结果(即合同既遵守又违反安全规则)。此外,它们在本地执行抽象解释(即上下文/路径不敏感分析),因此会遭受许多误报。 根据这些工具的分析结果确定的合同可能会引入不必要的开销。
第二步,SGUARD 为源代码上的每种类型的漏洞应用特定的修复模式,以保证智能合约没有这些漏洞。 对于 SGUARD 支持的漏洞,我们的方法在终止时被证明是合理和完整的。
总而言之,我们在这项工作中的贡献如下。
- 我们提出了一种自动修复智能合约中 4 类漏洞的方法。
- 我们证明了我们的方法对于考虑的漏洞是合理和完整的。
- 我们将我们的方法作为一个独立的工具来实施,然后用 5000 个智能合约进行评估。 实验结果表明,SGUARD 修复了 1605 个智能合约。 此外,修复在时间(即平均 14.79%)和 gas(即 0.79%)方面会产生较小的运行时开销。
BACKGROUND AND OVERVIEW
在本节中,我们将介绍智能合约的相关背景,并通过示例说明我们的方法如何解决智能合约漏洞问题。
A.Smart Contract
智能合约的概念随着以太坊(即具有执行可编程代码能力的数字货币平台)而产生 [6], 随后它得到了 RSK [7] 和 Hyperledger [8] 等平台的支持。 在这项工作中,我们专注于以太坊智能合约,因为它仍然是最受欢迎的智能合约平台。
直观地说,以太坊智能合约实现了一套管理以太坊账户中数字资产的规则。 在以太坊平台中,有两种类型的账户,即外部拥有账户(EOA)和合约账户。 这两种类型的账户都有一个 256 位的唯一地址和一个余额,代表账户中的以太币(也就是以太坊货币单位)的数量。 合约账户是与可用于执行某些预定义任务的智能合约相关联的账户。智能合约类似于面向对象编程语言(例如JAVA,C#)中的类,它包含持久性数据,例如存储变量和可以修改这些变量的函数(包括初始化它们的构造函数。声明为 public 的函数可以通过交易从其他账户(EOA 或其他合约账户)调用,即序列函数调用。
以太坊平台支持多种编程语言进行智能合约编程。 目前最流行的是 Solidity,一种图灵完备的编程语言。 例如,图 1(a) 显示了用 Solidity 编写的名为 SmartMesh 的合约中的公共函数。 一旦被调用,该函数就会将一定数量的代币从一个账户(地址为)转移到另一个账户(地址为)。Solidity 合约被编译成以太坊字节码, 使用字节码,交易由矿工机器上的以太坊虚拟机(EVM)执行。 从本质上讲,EVM 是一个基于堆栈的机器,其详细信息可参见第 III-A 部分。
Solidity 程序具有许多特定于智能合约的语言功能,并且通常与漏洞相关。例如,一个用关键字payable标记的公共函数在被调用时允许接收Ether。收到的以太币数量用变量 msg.value 的值表示。也就是说,如果一个账户调用了一个合约的payment函数,并将msg.value的值设置为大于0,则Ether从调用账户转移到被调用账户。除此之外,还可以使用全局定义的函数 send() 或 transfer() 将 Ether 发送到其他合约。请注意,在这种情况下,如果在接收合约中定义了一个名为 fallback 函数的特定匿名函数,则会执行该函数。请注意,当一个不存在的函数被调用时,回退函数是一个安全阀,尽管它似乎是问题的根源。此外,为了防止网络的有害利用,例如运行无限循环,每个字节码指令(称为操作码)都与称为 gas 的运行成本相关联,该成本从调用者的帐户中支付。
B. Vulnerabilities
就像传统程序一样,智能合约也存在基于代码的漏洞。 在现实世界的智能合约中已经发现了各种漏洞,其中一些已被攻击者利用并造成了重大的经济损失(例如,[9]、[10])。 下面我们通过实例介绍两种漏洞。
Example II.1.
一类漏洞是算术漏洞,例如溢出。例如,2018 年 4 月,攻击者利用名为 SmartMesh 的智能合约中的整数溢出漏洞窃取了大量代币(即数字货币)。同一错误当时影响了 9 个可交易代币,并被命名为 ProxyOverflow。图 1(a) 显示了包含错误的 SmartMesh 合约中的(简化的)函数 transferProxy。该函数旨在将代币从一个账户转移到另一个账户,同时向发送方支付一定的费用(见第 6 行和第 7 行)。尽管开发人员意识到潜在的溢出并在第 2、4 和 5 行引入了相关检查,不幸的是,检查遗漏了一个微妙的错误。也就是说,如果 fee+value 为 0(由于溢出)并且 balances[from]=0,攻击者能够绕过第 2 行的检查并随后增加 msg.sender 和 to 的余额(参见第 6 行和第 7 行) ) 的金额超过 balances[from],在攻击过程中,这个漏洞被利用来创建空中代币。此示例强调手动编写的检查可能容易出错。
Example II.2.
重入漏洞可以说是智能合约中最臭名昭著的漏洞。它发生在智能合约 C 调用另一个合约 D 的函数时,之后在合约 C 处于不一致状态时(例如,合约 C 的余额未更新)进行回调(例如,通过合约 D 中的fallback函数)。图 2(a) 显示了名为 MasBurn 的智能合约的一部分,其中包含跨功能重入漏洞。MasBurn 实现了 Midas 协议代币,即可交易的 ERC20 代币。它允许代币持有者通过将代币发送到特定的 BURN_ADDRESS 来销毁他们拥有的代币,如第 17 行所示。 一周内销毁代币的总量不能超过weeklyLimit(见第 16 行),这是一个限制数量的变量每周要销毁的代币数量。然而,问题是函数 getThisWeekBurnAmountLeft(见第 16 行)的返回值对变量 numOfBurns 有数据依赖性,并且在第 17 行的可重入调用的情况下会被错误地计算。也就是说,如果BURN_ADDRESS 处的合约包含对函数burn 的回调,调用函数getThisWeekBurnAmountLeft 时使用过时的numOfBurns 值。结果,销毁的代币数量将超过允许的数量。尽管在这种攻击中没有丢失(或从空气中创建)以太币,但在这种情况下违反了 MasBurn 的(隐式)规范。这个例子也说明了处理重入漏洞的难度,即重入是否是漏洞可能取决于合约的规范。

C. Patching Smart Contracts
下面我们通过上面提到的两个例子来说明 SGUARD 是如何修补智能合约的,技术细节将在第四节中介绍。注意, SGUARD 是基于字节码识别漏洞,同时基于相应的源代码修补它们。 这是因为基于字节码的分析比基于源代码的分析更精确(因为前者不受 Solidity 编译器中的错误或优化的影响),而在源代码上打补丁对用户是透明的。
Example II.3.
使用 SGUARD 修补图 1(a) 所示函数的结果如图 1(b) 所示。 几乎所有算术运算(在语句或表达式中)都被替换为安全执行相应操作的函数调用(即,适当检查算术上溢或下溢)。 这有效地防止了漏洞,因为如果第 2 行的费用 + 值溢出,函数会立即恢复。请注意,第 9 行的添加没有被修补,因为变量 nonce 本身不被认为是关键的,或者被一些关键变量所依赖。
有人可能会争辩说,某些修改是不必要的,例如第 4 行的修改。如果目标是防止这个特定漏洞,则对于这个智能合约来说是正确的。一般来说,是否需要修改只能在智能合约的规范存在时才能回答。 SGUARD 不要求用户提供规范,因为这会限制其在实践中的适用性。 因此,SGUARD 总是保守地假设所有可能导致漏洞的算术溢出都是有问题的。虽然这个补丁不是最精妙的,但我们保证打上补丁后的transferProxy没有算术漏洞。
Example II.4.
将 SGUARD 应用于图 2(a) 所示合约的结果如图 2(b) 所示。 SGUARD 将第 17 行识别为外部调用,这是至关重要的,因为外部调用会调用可能受攻击者控制的另一个合约的功能。 SGUARD 系统地识别第 17 行的外部调用所依赖的变量(通过控制依赖或数据依赖),之后,SGUARD 相应地修补这些变量和操作。 例如,这个外部调用对第 5 行的 if 语句具有控制依赖性,并且紧随其后的是存储更新(第 18 行的 ++numOfBurns)。
- 第 4、5、6、12 行的减法被替换为函数 sub_uint256 的调用,该函数检查下溢。
- 第 6、18 行的添加被替换为函数 add_uint256 的调用以避免溢出。
- burn函数被修补以防止重入。 也就是说,我们在第 15 行引入了修饰符 nonReentrant。这个修饰符源自 OpenZeppelin [11],一个用于安全智能合约开发的库。
通过SGUARD生成的智能合约没有算术漏洞和重入漏洞。

PROBLEM DEFINITION
下面,我们首先介绍 Solidity 智能合约的语义,然后定义我们的问题。
A. Concrete Semantics
智能合约 S 可以看作是一个有限状态机 S = (Var, init, N, i, E) 其中 Var 是一组变量; init 是变量的初始估值; N 是一组有限的控制位置; i ∈ N 是初始控制位置,即合约的开始; E ⊆ N × C × N 是一组带标签的边,每条边的形式为 (n, c, n’),其中 c 是一个操作码。 Solidity 共有 78 个操作码(从 0.5.3 版本开始),如表 I 所示。 注意每个操作码都静态分配了一个唯一的程序计数器,即每个操作码都可以根据程序计数器进行唯一标识。
请注意,Var 包括堆栈变量、内存变量和存储变量。 堆栈变量主要用于存储原始值,内存变量用于存储类似数组的值(用关键字 memory 显式声明)。 堆栈和内存变量都是易失性的,即它们在每次事务后都会被清除。 相比之下,存储变量是非易失性的,即它们在区块链上是持久的。 总之,变量的值确定了智能合约在特定时间点的状态。 在 Solidity 源代码层面,堆栈和内存变量可以被视为特定函数中的局部变量; 而存储变量可以被认为是合约级别的变量。
智能合约的具体轨迹是状态和操作码 <s0, op0, s1, op1, · · ·> 的交替序列,每个状态码 si 的形式为 (pci, Si, Mi, Ri) 其中 pci ∈ N 是程序计数器;Si是堆栈变量的值; Mi 是内存变量的值; Ri 是存储变量的值。这里,初始状态 s0 是 (0, S0, M0, R0),其中 S0、M0 和 R0 是 init 定义的变量的初始值。此外,对于所有的 i,(pci+1, Si+1, Mi+1, Ri+1) 是根据 opi 的语义在给定状态 (pci, Si, Mi, Ri) 的情况下执行 操作码opi 的结果。操作码的语义以执行规则的形式显示在图 3 中,每个执行规则都与一个特定的操作码相关联。每个规则由线上方的多个条件和线下方的状态变化组成。从左到右读取状态变化,即如果满足该行上方的条件,则左侧的状态变为右侧的状态。请注意,这种形式语义基于最近对形式化 Etherum 的努力 [12]。
大多数规则是不言自明的,因此我们跳过细节让读者自己参考 [12]。 值得一提的是,我们的语义模型中是如何抽象外部调用的:给定一个外部函数调用(即操作码 CALL),执行临时切换到调用合约的执行,外部调用的结果抽象为 res,被压入堆栈。

B. Symbolic Semantics
为了定义我们的问题,我们必须定义我们关注的漏洞类型。 直观地说,如果存在满足某些约束的智能合约的执行,我们就说智能合约存在某些漏洞。下面我们扩展具体的路径来定义智能合约的符号路径,这样我们就可以定义一个符号路径是否存在某种漏洞。
为了定义符号路径,我们首先将具体值扩展为符号值。形式上,符号值的形式为 op(operand0,···,operandn),其中 op 是操作码,operand0,···,operandn 是操作数,每个操作数可以是具体值(例如,整数或地址)或符号值。请注意,如果一个操作码的所有操作数都是具体值,则符号值也是一个具体值,即将 op 应用于具体操作数的结果。例如,ADD(5,6) 是 11。否则,该值是符号的。一个例外是,如果 op 是 MLOAD 或 SLOAD,即使操作数是具体的,结果也是符号的,因为维护内存或存储的具体内容并非易事。例如,从存储器加载地址 0x00 的值会产生符号值 SLOAD(0x00),将存储器地址 0x00 处的值增加 6 会产生符号值 ADD(SLOAD(0x00),0x06)。再比如,符号化执行SHA3(n,p)的结果是SHA3(MLOAD(n,p)),即内存中地址n到n+p的值的SHA3哈希。
有了上述,符号路径是状态和操作码 <s0, op0, s1, op1, · · · > 的交替序列,使得每个状态 si 的形式为 (pci, Sis, Mis, Ris) 其中 pci 是 程序计数器; Sis、Mis 和 Ris 分别是堆栈、内存和存储的值。 请注意,Sis、Mis 和 Ris 可能具有象征性的价值以及具体的价值。 对于所有 i,(pci+1, Sis+1, Mis+1, Ris+1) 是在给定状态 (pci, Sis, Mis, Ris) 的情况下象征性地执行操作码 opi 的结果。
符号执行引擎是一种系统地生成智能合约符号路径的引擎。 请注意,与具体执行不同,符号执行会在给定 if 语句的情况下生成两条路径,一条访问 then 分支,另一个访问 else 分支。 此外,在外部调用(即 CALL)的情况下,我们可以简单地使用符号值来表示外部调用的返回值,而不是将当前执行上下文切换到另一个智能合约。
C. Problem Definition
直观地说,当某些关键指令(例如,CALL 和 DELEGATECALL)依赖于一组特定指令(例如,ADD、SUB 和 SSTORE)时,就会出现漏洞。 因此,要定义我们的问题,我们首先定义(控制和数据)依赖项,在此基础上我们定义漏洞。
Definition 1 (Control dependency).
如果从 op_i 开始的所有路径都必须经过 op_j ,则认为操作码 op_j后支配操作码 op_i。如果存在从 op_i 到 op_j的执行,使得 op_j 后支配从 op_i到 op_j的路径中的所有 op_k(不包括 op_i),但不后支配 op_i,则认为操作码 op_j 控制依赖于 op_i。

图 4 说明了控制依赖的示例。源代码显示在顶部,相应的控制流图显示在底部, 所有变量及其符号值汇总在表 II 中。 源代码提供了将 _value 从 msg.sender 帐户转移到 _to 帐户的安全步骤。 有 3 个 then-branch,然后是 2 个存储更新。 根据定义,SSTORE3 和 SSTORE4 都是控制依赖于 ISZERO1、ISZERO2 和 GT0。
Definition 2 (Data dependency).
如果存在从操作码 op_i到随后的 op_j 的执行路径,使得 W(op_i) ∩ R(op_j ) ≠ ∅ ,则认为操作码op_j 依赖于 op_i数据;其中 R(op_j ) 是op_j 读取的一组位置,W(op_i) 是由 op_i 写入的一组位置。
图 4 还说明了数据相关性的示例。 操作码 ISZERO1 和 ISZERO2 依赖于 SSTORE3 和 SSTORE4 的数据。 它有 2 条轨迹,一条轨迹从存储地址 SHA3(MLOAD(0x00,0x40)) 加载数据,该地址由 SSTORE1 和 SSTORE2 在另一条轨迹写入。
如果 opj 是控制或数据依赖于 opi 或 opj 依赖于操作码 opk 使得 opk 依赖于 opi,我们就说操作码 opj 依赖于操作码 opi。
Vulnerabilities
下面,我们定义了我们关注的 4 种漏洞,即函数内和跨函数重入、危险的 tx.origin 和算术溢出。 虽然我们当然可以检测到更多种类的漏洞,但如何修复它们并不总是很清楚,即可能无法知道预期的行为。 例如,在修复可访问的自毁漏洞的情况下(即,如果智能合约可能被任何人破坏,它就会遭受此漏洞的影响),我们不确定谁应该拥有访问自毁的权限。
令 C 为一组关键操作码,其中包含 CALL、CALLCODE、DELEGATECALL、SELFDESTRUCT、CREATE 和 CREATE2,即除 STATICCALL 外与外部调用相关的所有操作码的集合。 STATICCALL 被排除在 C 之外的原因是 STATICCALL 不能更新被调用智能合约的存储变量,因此被认为是安全的。
Definition 3 (Intra-function reentrancy vulnerability).
如果符号路径执行操作码 opc ∈ C 并随后在同一函数中执行操作码 ops,使得 ops 为 SSTORE,并且 opc 依赖于 ops,则符号路径会遭受函数内重入漏洞。
当且仅当其至少一个符号路径存在函数内可重入漏洞时,智能合约才存在函数内可重入漏洞。 上述定义的灵感来自调用后无写入 (NW) 属性 [4]。 然而,它比 NW 更准确,因为它避免了对不被视为可重入漏洞的 NW 的违反。 例如,图 5 中所示的函数违反了 NW,尽管它不受可重入漏洞的影响。 这是因为外部调用 msg.sender.call 不依赖于 numWithdraw。 换句话说,不存在从 opc 到 ops 的依赖。

Definition 4 (Cross-function reentrancy vulnerability).
如果符号路径 tr 执行 ops 为 SSTORE 的操作码操作并且存在受函数内重入漏洞影响的符号路径 tr’ 使得 tr’ 的操作码 opc 依赖于操作,则符号路径 tr 会遭受跨功能重入漏洞 属于不同的功能。
当且仅当其至少一个符号路径存在跨功能重入漏洞时,智能合约存在跨功能重入漏洞。 该漏洞不同于函数内可重入性,因为攻击者通过两个不同的函数发起攻击,这使得它更难被检测到。 图 6 显示了跨功能可重入的示例。 开发者显然是意识到函数内可重入,因此将修饰符 nonReentrant 添加到withdraw函数以防止重入。 然而,通过函数转移仍然可以重入,在这种情况下,攻击者可以将他的以太币加倍。 也就是说,攻击者在第 10 行收到 Ether 并在第 3 行非法转移到另一个账户。 尽管 Sereum [13] 和 Consensys [14] 中描述了跨功能重入漏洞,但我们的工作是第一个正式定义它的工作 .

Definition 5 (Dangerous tx.origin vulnerability).
如果符号路径执行依赖于操作码 ORIGIN 的操作码 opc ∈ C,则它会遭受危险的 tx.origin 漏洞。
智能合约存在危险的 tx.origin 漏洞当且仅当其至少一个符号路径存在危险的 tx.origin 漏洞。 该漏洞的发生是由于错误地使用全局变量 tx.origin 来授权用户。 当用户 U 向恶意合约发送交易时发生攻击
A,有意将此交易转发给依赖于易受攻击的授权检查(例如,require(tx.origin == owner))的合约 B。 由于 tx.origin 返回 U 的地址,因此合约 A 成功冒充 U。 图 7 展示了一个遭受危险 tx.orgin 漏洞的示例,即恶意合约可能冒充所有者撤回所有 Ether。

Definition 6 (Arithmetic vulnerability).
如果符号路径在 C 中执行操作码 opc 并且 opc 依赖于 ADD、SUB、MUL 或 DIV 的操作码 opa,则符号路径会遭受算术漏洞。
智能合约存在算术漏洞当且仅当其至少一个符号轨迹存在算术漏洞。直观地说,当外部调用数据依赖于算术运算(例如,加法、减法或乘法)时,就会出现此漏洞。例如,由于第 17 行的外部调用与第 12 行的表达式weeklyLimit -getThisWeekBurnedAmount() 之间存在数据依赖关系,图2 中的示例很容易受到攻击。算术漏洞是多个设计用于漏洞检测的工具的目标。通常,使用静态分析的算术漏洞检测通常会导致高误报。因此,尽管此漏洞很重要,但诸如 Securify [4] 和 Ethainter [5] 之类的工具并不支持该漏洞。在上面的定义中,我们只关注关键的算术运算以减少误报。也就是说,只要智能合约不通过外部调用将其错误计算传播到其他智能合约,算术运算就不会被认为是关键的。例如,错误的 ERC20 代币传输(例如,CVE-2018-10376)并不重要,因为它可以被合约的管理员恢复,而错误的 Ether 传输是不可逆的。
Problem definition
我们的问题定义如下。 给定一个智能合约 S,构造一个智能合约 T,使得 T 满足以下条件:
- 健全性:T 没有上述任何漏洞。
- 精确性:对于 S 的每个符号轨迹 tr,如果 tr 没有任何漏洞,则在 T 中存在一个符号轨迹 tr’,给定相同的输入,产生相同的输出和状态。
- 效率:T 的执行速度和 gas 消耗与 S 的差异很小。
请注意,前两个是关于构造的正确性,而最后一个是关于计算和 gas 开销方面的性能。
DETAILED APPROACH
在本节中,我们将介绍我们的方法的详细信息。关键挑战是准确识别可能出现漏洞的位置并相应地修复它们。请注意,精确识别控制/数据依赖性是精确识别漏洞的先决条件。识别漏洞的一种方法是通过基于过度近似的静态分析。例如,多个现有工具(例如,Securify [4] 和 Ethainter [5])使用重写规则过度近似以太坊语义,并利用 Datalog 等重写系统通过关键模式匹配来识别漏洞。虽然在检测漏洞方面很有用(并且通常很有效),但由于多种原因,此类方法对于我们的目的并不理想。首先,当它们在本地执行抽象解释(即上下文/路径不敏感分析)时,通常会出现许多误报。在我们的设置中,一旦发现漏洞,我们就会通过引入额外的运行时检查来修复它。因此,误报会转化为时间和gas方面的运行时间开销。其次,现有方法通常是不完整的,即并非所有依赖项都被捕获。例如,Securify 通过存储变量忽略数据依赖,即如果 c 不是常数,则 SSTORE(c,b) 的依赖会丢失,而 Ethainter 完全忽略控制依赖。第三,Datalog 等重写系统可能会在没有任何结果的情况下终止,在这种情况下,分析结果可能不合理。 因此,在我们的工作中,我们提出了一种算法,该算法以高精度覆盖所有依赖项,并始终以正确的结果终止。
我们算法的细节如算法 1 所示。从高层次的角度来看,它的工作原理如下。 首先,系统地枚举符号轨迹,直到每个循环的迭代次数达到特定阈值。 其次,根据我们的定义,检查每个符号路径以查看它是否受到某些漏洞的影响。 最后,根据 AST 识别出漏洞的相应源代码并进行修复。 下面,我们介绍
每一步的细节。

A. Enumerating Symbolic 路径
请注意,我们对漏洞的定义基于符号轨迹。 因此,在第一步中,我们着手收集一组符号路径 Tr。 如第 III-B 节中所定义,符号轨迹是形式为 <s0, op0, · · · , sn, opn, sn+1> 的序列。 在下文中,我们关注最大的符号轨迹,即最后一个操作码 opn 是 REVERT、INVALID、SELFDESTRUCT、RETURN 或 STOP。
在没有循环的情况下,系统地生成最大符号轨迹很简单,即,我们只需迭代地应用符号语义规则,直到它终止。 但是,在存在循环的情况下,由于退出循环的条件通常是象征性的,因此该过程不会终止。 这是符号执行的一个众所周知的问题,补救措施通常是启发式地限制迭代次数。然而,这种方法在我们的设置中不起作用,因为我们必须识别所有数据/控制依赖以识别所有潜在漏洞。 在下文中,我们建立了循环迭代次数的界限,我们证明这足以识别我们关注的漏洞。
给定一个智能合约 S = (Var, init, N, i, E),循环通常是 S 中的一个强连接组件。由于结构化编程,我们总是可以识别循环头,即控制位置 while 循环开始或递归函数被调用。 在下文中,我们将每个位置 n ∈ N 与一个边界相关联,表示为 bound(n)。 如果 n 是循环头,则 bound(n) 直观地表示在我们收集的至少一个符号路径中必须访问 n 的次数。 如果 n 不是任何强连通分量的一部分,我们有 bound(n) = 1。否则,bound(n) 定义如下
- 如果 (n, opn, n’) ∈ E ,opn 不是赋值并且 n’ 是循环头,则 bound(n) = 0 ;否则bound(n)= 1。
- 如果 (n, opn, n’) ∈ E, n’ 不是循环头, opn 不是赋值并且没有 m 使得 (n, opn, m) ∈ E,即 n 不是分支, bound(n) = bound( n’) ;否则 bound(n) = bound(n’) + 1。
- 如果 (n, opn, m0) ∈ E 且 (n, opn, m1) ∈ E,即 n 是
分支,bound(n) = bound(m1) + bound(m2)。
直观地说,循环头的边界是根据循环内分支语句和赋值语句的数量计算的。 也就是说,循环头 n 的边界可以通过以相反的顺序遍历 CFG 来计算,即从循环的退出节点到 n。 每个执行路径都维护一个界限,该界限等于该路径中赋值语句的数量。 如果两个执行路径在一个分支语句处相遇,则新的界限被设置为它们的界限之和。 在我们的实现中,每个节点 n ∈ N 的边界是使用定点算法静态计算的,复杂度为 O((#N)^2),其中#N 是节点数。 一旦边界被计算出来,我们系统地枚举所有最大符号轨迹,使得每个循环头 n 最多被访问 bound(n) 次。 很容易看出这个过程总是终止并返回一组有限的符号轨迹。
Example IV.1.
下面,我们将说明如何计算 bound(x <100)。 该示例如图 8 所示,其中右侧的图表示左侧的源代码(即可以使用现有方法构建的控制流图 [15])。 赋值语句以蓝色突出显示。 while循环中共有3条路径P1、P2、P3,分别访问5条赋值语句。 由于我们遵循 if 语句的两个分支,因此无论顺序如何,都存在包含 P1、P2、P3 的符号轨迹 tr。 路径 tr 的形式为 <· · · , opi, · · · , opj , · · · , opk, · · · , op’i, · · · > 其中 opi 和 op’i执行循环头 x < 100 的操作码; opj 映射到 y < 100,opk 映射到 z < 100。 opi 和 op’i 之间有 5 条赋值语句,循环头的边界为 5。 注意例子中赋值语句的数量是数字 的 SWAP 出现在 opi 和 op’i 之间。
以下建立了我们方法的合理性,即使用边界,我们保证不会错过任何
我们关注的 4 种漏洞。

Lemma 1.
给定一个智能合约,如果存在函数内重入漏洞(或跨函数重入,或危险的 tx.origin 或算术漏洞)的符号路径,则 Tr 中必定存在一个。
我们在下面勾画证明。第三部分中的所有漏洞都是基于操作码之间的控制/数据依赖性定义的。这意味着我们总是有一个易受攻击的路径,如果有的话,只要我们收集的一组符号路径表现出操作码之间所有可能的依赖关系。为了查看所有依赖关系都显示在我们收集的路径中,我们区分了两种情况。只要智能合约中所有可能的分支都被执行,操作码之间的所有控制依赖就会被识别。根据我们在 Tr 中收集路径的方式,满足此条件。此参数适用于也不属于任何循环的操作码之间的数据依赖性。接下来,我们考虑循环内操作码之间的数据依赖性。请注意,对于每次循环迭代,有两种可能的情况:未识别出新的数据依赖项(即,数据依赖项达到固定点)或至少识别出 1 个新的依赖项。如果循环包含 n 个赋值,在最坏的情况下,所有这些操作码都相互依赖,我们需要一个包含 n 次迭代的路径来识别所有这些操作码。根据我们如何计算循环头的界限,轨迹保证在 Tr 中。因此,我们建立上述引理被证明。
众所周知,符号执行引擎可能会遇到路径爆炸问题。 SGUARD 也不能幸免,即 SGUARD 探索的符号路径的数量在循环边界中通常是指数级的。现有的符号执行引擎通过允许用户配置一个绑定 K 来解决这个问题,K 是任何循环展开的最大次数。在实践中,知道应该使用什么 K 值是非常重要的。考虑到 K 的影响,即路径的数量与 K 的值呈指数关系,现有工具通常默认将 K 设置为一个较小的数字,例如 sCompile [16] 中的 3 和 Manticore [17] 中的 5;并且用户不太可能对其进行不同的配置。较大的 K 会导致路径爆炸问题,而较小的 K 会导致误报。例如,当 K = 3 时,由于图 8 中两个表达式 m = n+1, n = x + 1 导致的溢出漏洞将被忽略,因为此界限不足以推断变量 x 对 m 和 n 的依赖性.相比之下,SGUARD 会自动识别每个循环的循环边界,从而保证不会遗漏任何漏洞。在第五部分,我们凭经验评估路径爆炸问题是否在实践中经常发生。
B. Dependency Analysis
给定一组符号轨迹 Tr,然后我们识别 Tr 中每个符号轨迹中所有操作码之间的依赖关系,目的是检查轨迹是否存在任何漏洞。 在下文中,我们介绍了从符号路径中捕获依赖项的方法。
给定一个符号路径 Tr,一个操作码 opi ,我们的目标是识别 Tr 中的一组操作码 dp 使得:(健全性)对于 dp 中的所有 opk,opi 依赖于 opk; 和(完整性)对于 Tr 中的所有 opk,如果 opi 依赖于 opk,则 opk ∈ dp。 为了识别 dp,我们系统地识别了所有 opi 在 Tr 中控制依赖的操作码,所有 opi 在 Tr 中数据依赖的操作码,然后计算它们的传递闭包。
为了系统地识别所有控制依赖性,我们从 Tr 构建了一个控制流图 (CFG)(如算法 2 所示)。 之后,我们使用 workList 算法基于 CFG 构建后支配树 [18]。 结果是一组 PD(opi),它是后支配 opi 的操作码。 opi 控制依赖于符号路径 tr 的一组操作码然后被系统地识别如下。
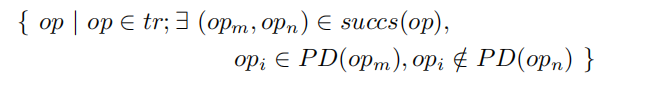
其中 succs(op) 根据 CFG 返回 op 的后继者。
识别 opi 依赖于数据的操作码集更为复杂。 数据依赖来自 3 个数据源,即堆栈、内存和存储。 在下文中,我们展示了基于过度近似的算法,该算法路径这些数据源上的数据流以捕获数据依赖性。 尽管操作码通常将数据读取和写入到同一数据源,但在某些情况下,操作码可能会将数据写入不同的数据源。 这使得数据流路径变得复杂,即数据通过 MSTORE 从堆栈流向内存,通过 MLOAD 从内存流向堆栈,通过 SSTORE 从堆栈流向存储,通过 SLOAD 从存储流向堆栈。 由于只有赋值操作码(即 SWAP、MSTORE 和 SSTORE)会创建数据依赖性,因此我们设计了一种算法来根据 tr 中的赋值操作码来识别数据依赖性。 算法 3 中提供了详细信息,该算法将符号路径 tr 和操作码 opi 作为输入,并返回一组 opi 依赖于数据的操作码。
算法 3 系统地识别出 tr 中污染 opi 的那些操作码。 如果 opi 从 opj 写入的堆栈索引中读取数据,或者存在操作码 opt 使得 opj 污染 opt 和 opt 污染 opi,则认为操作码 opj 污染了另一个操作码 opi。 对于污染 opi 的每个 opj,存在三种可能的依赖情况。
- 堆栈依赖:如果 opj 是赋值操作码(即 SWAP),opi 依赖于 opj 的数据(第 3-4 行)
- 内存依赖:如果 opj 从内存中读取由赋值操作码 opk(即 MSTORE)写入的数据(第 5-7 行),则 opj 依赖于 opk 的数据
- 存储依赖:如果opj 从由赋值操作码opk(即SSTORE)写入的存储中读取数据,opj 依赖于opk(第8-12 行)
请注意,该算法是递归的,即,如果将 opk 添加到要返回的操作码集中,则进行递归调用以进一步识别 opk 依赖于数据的操作码(第 7 行和第 12 行)。 进一步注意,由于存储是全局可访问的,因此分析可能会跨越 Tr(第 11 行)中的不同轨迹。
算法 3 通常过度近似。 例如,由于内存和存储地址可能是符号值,因此读取地址和写入地址通常是不可比较的,在这种情况下,我们保守地假设地址可能相同。 换句话说,如果 R(opj ) 或 W(opk) 是符号地址,则 R(opj ) ∩ W(opk) = ∅ 为真。

C. Fixing the Smart Contract
一旦确定了依赖关系,我们就会检查每个符号 tr 是否存在第 III-C 节中定义的任何漏洞,然后相应地修复智能合约。 通常,智能合约固定如下。 给定一个易受攻击的路径 tr,根据我们在第 III-C 节中的定义,在 tr 中必须有一个外部调用 opc ∈ C。 此外,必须有一些 opc 依赖的其他操作码 op,它们一起使 tr 易受攻击(例如,如果 op 是 SSTORE,则 tr 存在可重入漏洞;如果 op 是 ADD、SUB、MUL 或 DIV,则 tr 存在算术漏洞)。 这个想法是在操作之前引入运行时检查以防止漏洞。 根据漏洞类型,运行时检查注入如下。
- 为了防止函数内可重入漏洞,我们向包含 op 的函数 F 添加了一个修饰符 nonReentrant。 请注意,nonReentrant 修饰符用作阻止攻击者重新进入 F 的互斥锁。为了防止跨函数重入漏洞,我们将修饰符 nonReentrant 添加到包含 op 的函数中。 算法 4 中给出了修复算法的详细信息,该算法采用易受攻击的轨迹 tr 和依赖关系 dp 作为输入。
- 为了修复危险的 tx.origin 漏洞,我们将 op(即 ORIGIN)替换为 msg.sender,它返回调用该函数的直接帐户的地址。
- 为了修复算术漏洞,我们将 op(即 ADD、SUB、MUL、DIV 或 EXP)替换为对安全数学函数的调用,该函数在执行算术运算之前检查上溢/下溢。
请注意,在可重入漏洞和算术漏洞的情况下,如果运行时检查失败(例如,在 x - y 失败之前引入的 assert(x > y)),交易会立即恢复,因此漏洞被阻止,尽管到目前为止执行交易所花费的gas会被浪费掉。进一步注意,当算法 4 应用于每个易受攻击的路径时,相同的修复(例如,在同一函数上引入 nonReentrant)被应用一次。 我们建议读者参阅第 II-C 节以获取有关如何修复智能合约的示例。
以下内容证明了我们方法的合理性。
Theorem 1. 由算法 1 修复的智能合约不存在函数内重入漏洞、跨函数重入漏洞、危险的 tx.origin 漏洞和算术漏洞。
该定理的证明简述如下。根据引理 1,给定一个智能合约 S,如果存在易受攻击的痕迹,则至少其中一个被 SGUARD 识别。鉴于 SGUARD 如何修复每种漏洞,修复 Tr 中所有易受攻击的痕迹意味着所有易受攻击的痕迹都在 S 中修复。
我们承认我们的方法没有达到第 III-C 节中讨论的精确性。也就是说,如果一个不易受攻击的路径与易受攻击的路径共享一些操作码,它可能会受到修复的影响。例如,由易受攻击的路径和非易受攻击的路径共享的算术操作码可以替换为检查溢出的安全版本。即使溢出可能是良性的,在溢出的情况下,非易受攻击的路径也会恢复。这种不精确是在我们的环境中支付安全性的开销,以及时间和gas开销。在第五节中,我们凭经验评估了开销并表明它们可以忽略不计。

IMPLEMENTATION AND EVALUATION
在本节中,我们将介绍 SGUARD 的实现细节,然后通过多个实验对其进行评估。
A. Implementation
SGUARD 是用大约 3K 行 Node.js 代码实现的。 它在 GitHub 上公开可用。 它使用本地安装的编译器将用户提供的合约编译成包含字节码、源映射和抽象语法树 (AST) 的 JSON 文件。 字节码用于检测漏洞,而源映射和 AST 用于在源代码级别修复智能合约。 通常,源映射将操作码链接到语句,将语句链接到 AST 中的节点。 给定 AST 中的一个节点,SGUARD 就可以完全控制如何修复智能合约。
除了前面部分讨论的内容之外,SGUARD 的实际实现还必须处理多种复杂情况。 首先,Solidity 允许开发人员将他们的代码与内联汇编(即使用 EVM 机器操作码的语言)交织在一起。 这允许细粒度的控制,并为难以发现的漏洞(例如算术漏洞)打开了一扇门。 我们已经考虑使用 SGUARD 修复漏洞(通过努力是可能的)。但是,开发人员评估我们修复的正确性并非易事,因为 SGUARD 会将操作码引入内联程序集。 我们相信对源代码的任何修改都应该对用户透明,因此决定不支持修复内联汇编中的漏洞。
其次,SGUARD 使用多种启发式方法来避免无用的修复。 例如,给定一个算术表达式,其操作数是具体值(可能是表达式独立于用户输入的情况),即使它是易受攻击的路径的一部分,SGUARD 也不会用来自安全数学的函数替换它 . 此外,由于每个循环要展开的迭代次数取决于循环内赋值语句的数量,因此 SGUARD 确定了许多可以安全忽略某些赋值的情况,而不会牺牲我们方法的稳健性。 特别是,虽然我们一般将 SSTORE、MSTORE 或 SWAP 算作赋值语句,但它们并不属于以下例外情况。
- 如果未根据 source-map 映射到赋值语句,则不计算 SWAP;
- 如果赋值语句的右侧表达式是常量,则不计算在内;
- 如果赋值语句的左侧表达式是存储变量,则不计算赋值语句(因为无论执行顺序如何,都会分析由存储变量引起的依赖性)。
此外,SGUARD 实现了一种策略来估计内存指针的值。 内存变量总是被放置在一个空闲内存指针上,它永远不会被释放。 然而,自由指针通常是一个符号值。 这增加了复杂性。 为了在不丢失依赖的情况下简化问题,SGUARD 会估计自由指针 ptr 的值,如果它最初是一个符号值。 也就是说,如果变量的内存大小仅在运行时已知,我们假设
它占用10个内存插槽。 空闲指针的计算公式为 ptrn+1 = 10 × 0x20 + ptrn,其中 ptrn 是前一个空闲指针。 如果由于此假设而发生内存重叠,则会引入额外的依赖项,这可能会引入误报,但绝不会出现漏报。
最后,SGUARD 允许用户提供额外的指南来生成特定于合同的修复。 例如,允许用户声明某些变量是关键变量,这样即使变量和外部调用之间没有依赖关系,它也会受到保护。
B. Evaluation
在下文中,我们通过多个实验评估 SGUARD,以回答以下研究问题 (RQ)。 我们的测试对象包括 5000 个合约,其经过验证的源代码是从 EtherScan [19] 收集的。 这包括我们过滤掉 5000 个包含无效语法或基于 Solidity 之前版本(例如 0.3.x 版本)实现的不可编译合约后的所有合约。 我们系统地将 SGUARD 应用于每个合同。 每个合约的超时设置为 5 分钟。 我们的实验是在 10 个并发进程上进行的,需要 6 个小时才能完成。 以下报告的所有实验结果均在
Ubuntu 16.04.6 LTS 机器,带有 Intel® Core™ i9-9900 CPU @ 3.10GHz 和 64GB 内存。
RQ1: How bad is the path explosion problem?
在5000张合约中,SGUARD对1767张(即35.34%)合约超时,并在时限内成功完成对剩余合约的分析和修复。其中,1590 个合约被认为是安全的(即它们不包含任何外部调用)并且没有应用任何修复。剩余的 1643 份合约以一种或另一种方式合约。我们注意到 38 份修复合约是不可编译的。有两个原因。首先,如果相应的智能合约具有特殊字符(例如,版权和心形表情符号),则合约源映射可能会引用无效的代码位置。结果证明这是 Solidity 编译器的一个错误,并已被报告。其次,许多 Solidity 版本的 AST 格式略有不同,例如,0.6.3 版声明了一个函数,该函数实现了属性implemented,而 0.4.26 版中没有该属性。请注意,实验设置中不支持由 pragma 关键字声明的编译器版本,因为 SGUARD 使用由 solc-select [20] 提供的编译器列表。最后,我们试验了 1605 个智能合约并报告了结果。
回想一下,探索的路径数量很大程度上取决于循环边界。 为了理解为什么 SGUARD 在 35.34% 的合约上超时,我们记录了 5000 个智能合约中每一个的最大循环界限。 图 9 总结了循环边界的分布。 从图中我们观察到,80% 的合约的循环边界不超过 17。而其余 20% 的合约的循环边界变化很大,例如最大为 390。平均循环边界为 15,这表明现有符号执行引擎中的默认边界可能确实不够。

RQ2: Is SGUARD capable of pinpointing where fixes should be applied?
此问题询问 SGUARD 是否能够准确确定应在何处应用修复程序。回想一下,SGUARD 根据依赖性分析的结果确定在何处应用修复,即精确的依赖性分析将自动暗示修复将应用在正确的位置。此外,控制依赖很简单,因此这个问题的答案依赖于数据依赖分析的准确性。在检查读/写地址的交集时,算法 3 中的数据依赖性分析可能会在第 5 行和第 8 行引入不精确性(即过度近似)。在 SGUARD 中,通过使用基地址和最大偏移量将每个符号地址转换为一系列具体地址来实现检查。仅当至少一个符号地址由于非标准访问模式而无法转换时才应用过度近似。如果两个符号地址都成功转换,我们可以使用具体地址的范围来精确检查交集,并且没有过度近似。因此,我们可以通过报告失败和成功地址转换的数量来衡量我们分析的过度近似。
图 10 总结了我们的实验结果,其中每个条形表示关于内存(即 MLOAD、MSTORE)和存储(即 SLOAD、SSTORE)操作码的失败和成功地址转换的数量。 从结果中,我们观察到 SLOAD、MLOAD、SSTORE 和 MSTORE 的成功转换百分比分别为 99.99%、85.58%、99.98% 和 98.43%。 MLOAD 在四种操作码中的准确度最差。 这主要是因为某些操作码(例如,CALL 和 CALLCODE)可能会在内存中加载不同大小的数据。 在这种情况下,MLOAD 可能依赖于多个 MSTORE,考虑到加载数据的大小是一个符号值,这变得更加困难。 因此,如果加载数据的大小不是 0x20(内存分配单元大小),我们会通过返回 true(因此过度近似)来简化分析

RQ3: What is the runtime overhead of SGUARD’s fixes?
此问题旨在衡量 SGUARD 修复程序的运行时开销。 请注意,运行时开销通常被视为是否在运行时采用额外检查的决定因素。 例如,由于担心运行时开销,C 编程语言一直拒绝引入运行时溢出检查,尽管许多人认为这会减少大量漏洞。 因此,必须对 SGUARD 提出同样的问题。 此外,智能合约中的运行时检查不仅引入了时间开销,还引入了 gas 开销,即,必须为执行的每个额外检查支付 gas。 考虑到大量交易(例如,以太坊网络上报告的每日交易量为 120 万笔 [21]),每次额外检查都可能转化为巨大的财务负担。
为了回答这个问题,我们测量了与原始合约相比,用户为部署和执行固定合约而支付的额外 gas 和计算时间。 也就是说,我们从以太坊网络下载交易并将它们复制到我们的本地网络上,并比较交易的gas/时间消耗。 在 1605 份智能合约中,有 23 份合约是内部创建的,因此不予考虑。 最后,我们复制了 1582 个固定合约的 6762 笔交易。 我们将每个合约的交易数量限制为最多 10 个,这样结果就不会偏向那些有大量交易的活跃合约。
由于我们的本地设置无法完全模拟实际的以太坊网络(例如,块号和时间戳不同),因此复制的交易最终可能会被还原。 在我们的实验中,3548 (52.47%) 个交易成功执行,因此我们报告了基于它们的结果。仔细调查表明,除了 1 笔交易之外,其余交易由于我们的私有网络和以太坊网络之间的差异而失败,交易失败是因为固定合约的字节码大小超过了大小限制 [22]。
图 11 总结了我们的结果。 x轴和y轴分别表示每笔交易的时间开销和gas开销。 数据显示,最高的 gas 开销为 42%,而最低的 gas 开销为 0%。 平均而言,用户必须额外支付 0.79% 的 gas 才能在修复后的合约上执行交易。 最高和最低的时间开销分别为 455% 和 0%。 平均而言,用户必须在交易上额外等待 14.79% 的时间。 基于结果,考虑到其安全性保证,我们认为使用 SGUARD 修复智能合约的开销是可控的。
对于算术漏洞,有一个简单的修复,即为每个算术运算添加一个检查。 为了了解 SGUARD 和这种方法之间的区别,我们对我们成功修复的一组智能合约(即其中的 1605 个)进行了额外的实验。 我们记录了 SGUARD 和简单方法添加到 4 条算术指令(即 ADD、SUB、MUL 和 DIV)的边界检查总数。 结果显示在表 III 中,其中 BC 列显示了简单方法的数量。 我们观察到,平均而言,SGUARD 引入的边界检查比简单化方法少 5.42 倍。 由于每次绑定检查在执行交易时都会消耗燃料和时间,因此我们认为这种减少是受欢迎的。

RQ4: How long does SGUARD take to fix a smart contract?
这个问题问的是SGUARD本身的效率。 我们通过记录修复每个智能合约的时间来衡量 SGUARD 的执行时间。 自然,更复杂的合约(例如,具有更多符号路径)需要更多时间来修复。 因此,我们展示了不同合约的执行时间如何变化。 图 12 总结了我们的结果,其中每个条形代表 10% 的智能合约,y 轴以秒为单位显示执行时间。 合约按执行时间排序。 从图中,我们观察到 90% 的合约在 36 秒内修复。 在 SGUARD 的不同步骤中,SGUARD 大部分时间用于识别依赖(70.57%)和发现漏洞(20.08%)。 平均而言,SGUARD 需要 15 秒来分析和修复合同。
Manual inspection of results
为了检查修复的质量,我们对市场上排名前 10 的 ERC20 代币进行了额外的实验。 也就是说,我们应用 SGUARD 来分析和修复合约,然后手动检查结果以检查修复的合约是否包含任何漏洞,即 SGUARD 是否未能防止某些漏洞,或者 SGUARD 是否引入了不必要的运行时检查(转化为 考虑到这些合约的交易数量巨大,可观的开销)。 结果报告在表 IV 中,其中 RE(分别为 AE 和 TX)列显示是否发现和修复了任何可重入(分别为算术和 tx.origin)漏洞; 符号 X 和✗ 分别表示是和否。 最后一列显示了探索的符号轨迹的数量。
我们观察到,HT、ZRX 和 DAI 三个代币探索的符号轨迹数为 0。这是因为这些合约不包含外部调用,因此 SGUARD 在扫描字节码后立即停止。 其余 7 个代币中,有 6 个(即 LINK、BNB、CRO、LEND、KNC 和 USDT)被发现是安全的,因此没有做任何修改。 SGUARD 报告并修复了智能合约 BAT 中的一个算术漏洞。 我们确认添加了运行时检查以防止发现的漏洞。然而,仔细调查显示该漏洞是不可利用的,尽管它符合我们的定义。 这是因为合约已经有运行时检查。 我们通过在智能合约上执行从以太坊网络获得的 10 笔交易来进一步测量修复的开销。 结果表明,SGUARD 引入了 18% 的 gas 开销。 最后,我们的人工调查确认所有合约都没有漏洞。

RELATED WORK
据我们所知,SGUARD 是第一个旨在以可证明正确的方式修复智能合约的工具。
SGUARD 与自动程序修复的许多工作密切相关,我们在下面重点介绍一些最相关的工作。 GenProg [1] 应用进化算法来搜索程序修复。如果修复的程序通过测试套件中的所有测试用例,则认为候选修复补丁成功。在 [2] 中,Dongsun 等人。提出了 PAR,它通过从现有的人工编写的补丁中学习修复模式来改进 GenProg,以避免无意义的补丁。在 [23] 中,Abadi 等人。自动重写二进制代码以强制执行控制流完整性 (CFI)。在 [24] 中,Jeff 等人。提出了 ClearView,它从应用程序的正常行为中学习不变量,生成补丁并观察已打补丁的应用程序的执行以选择最佳补丁。尽管还有许多其他程序修复工作,但没有一个专注于以可证明正确的方式修复智能合约。
SGUARD 与将静态分析技术应用于智能合约的许多工作密切相关。 Securify [4] 和 Ethainter [5] 是利用重写系统(即 Datalog)通过模式匹配识别漏洞的方法。在符号执行方面,在 [25] 中,Luu 等人。提出了第一个发现智能合约中潜在安全漏洞的引擎。在 [26] 中,Krupp 和 Rossow 提出了 teEther,它通过专注于金融交易来发现智能合约中的漏洞。在 [27] 中,Nikolic 等人。介绍了 MAIAN,它专注于通过一种符号执行的形式识别基于路径的漏洞。在 [28] 中,托雷斯等人。介绍了 Osiris,它专注于发现整数错误。与这些引擎不同的是,SGUARD 不仅会检测漏洞,还会自动修复它们。
SGUARD 与一些验证和分析智能合约的工作有关。 Zeus [29] 是一个基于 LLVM 验证智能合约正确性和公平性的框架。 巴尔加万等人提出了一个框架,通过将源代码和字节码转换为称为 F* [30] 的中间语言来验证智能合约。 在[31]中,作者使用Isabelle/HOL来验证契约合同。 在 [32] 中,作者表明,根据调用图分析,只有 40% 的智能合约是值得信赖的。 在[33]中,陈等人。 表明大多数合约都受到一些 gas-cost 编程模式的影响。
最后,SGUARD 与测试智能合约的方法有很大关系。 ContractFuzzer [34] 是一个模糊引擎,可以检查 7 种不同类型的漏洞。 sFuzz [15] 是另一个模糊器,它通过使用来自测试用例执行的反馈来扩展 ContractFuzzer 来生成新的测试用例。
CONCLUSION
在这项工作中,我们提出了一种修复智能合约的方法,使其免受 4 种常见漏洞的影响。 我们的方法使用运行时信息并被证明是合理的。 实验结果表明了我们方法的实用性,即 SGUARD 能够正确修复合约,同时只引入很小的开销。 未来,我们打算通过优化技术进一步提高 SGUARD 的性能。














 2239
2239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









