







Prospect of Voiceprint Recognition Based on Deep Learning
Shuaijie Shan1 , Jianbao Liu1* and Yaowu Dun1
1 College of Electrical Engineering, Naval University of Engineering, Wuhan, Hubei,
430000, China
* Corresponding author’s e-mail: [email protected]; [email protected]
Abstract. As a biometric technology, voiceprint recognition is as unique as human fingerprint
and pupil, so voiceprint recognition has great potential in practical application. Aiming at the
feature extraction method and voiceprint recognition method, this paper first introduces the
principle of voiceprint recognition, traditional MFCC, LPDA and other feature parameters and
their performance; secondly, the traditional voiceprint recognition methods such as GMM and
GMM-SVM are introduced, as well as their shortcomings and improvement schemes. Aiming at
the shortcomings of voiceprint recognition system based on traditional algorithms in accuracy,
robustness and real-time, this paper introduces the role of deep learning neural network in
different stages of voiceprint recognition, and introduces the characteristics and network
structure of some typical algorithms based on deep learning. Finally, according to the advantages
and disadvantages of deep learning in voiceprint recognition, the development prospect and
challenges of voiceprint recognition technology are analysed.
1. Introduction
As a biometric technology, voiceprint recognition can uniquely identify a person, so it is also known as
speaker recognition technology[1]. Compared with other biometric technologies, it has obvious
advantages of convenient data collection, simple equipment and high secrecy.
Voiceprint recognition was first proposed for the feasibility of human ear recognition mechanism
and machine listening recognition[2]. Voiceprint recognition technology can be divided into speaker
recognition technology and speaker confirmation technology according to different functions, and can
be divided into text correlation, text restriction and text independence according to different audio
content[3]. The early voiceprint recognition technology is mostly based on template matching[4],
probability equation analysis, dynamic time warping[5] and other methods; feature parameter extraction
is based on cepstrum, Fourier transform[6,7], MFCC and LPC[8]. In recent years, voiceprint features
are mostly based on the feature vector represented by I-vector[9]; recognition is based on Gaussian
mixture model and its optimization model[10,11].
Since 2014, deep learning has been gradually applied in the field of voiceprint recognition, such as
DNN, CNN and LSTM models; j-vector, d-vector and x-vector feature parameters have been
developed[12,13]. Then, aiming at the deep learning ability to extract highly abstract features and strong
nonlinear classification ability, an end-to-end neural network structure is designed and improved to
realize the integration of feature extraction and classification recognition[14,15].
This paper presents three steps of voiceprint recognition. This paper introduces the voiceprint feature
parameters and their performance, the voiceprint recognition method and its principle, and the voiceprint
recognition model based on deep learning. At the same time, the paper also summarizes the advantages
and disadvantages of traditional recognition methods and recognition methods based on deep learning.
2. Brief analysis of voiceprint recognition
2.1. Analysis and principle of voiceprint recognition
Voiceprint refers to the spectrum of sound waves carrying voice information detected by electro
acoustics. Because of the particularity of human body structure and the complex physical process
between organs, the sound is produced. Therefore, in theory, the short-term spectrum, sound source,
time series, rhythm and other characteristics of each person's voice are different, that is, voiceprints are
as unique and unique as fingerprints. Voiceprint recognition includes two steps: training and detection,
and its technical schematic diagram is shown in Figure 1.
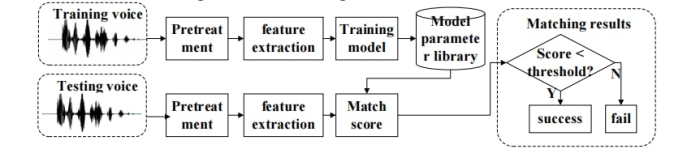
Figure 1. Schematic diagram of voiceprint recognition technology
2.2. Development of voiceprint recognition technology
The voiceprint features can be divided into Auditory feature that can be identified and described by
human ears and Acoustic feature that can be extracted from acoustic signals by mathematical methods.
Mel cepstrum coefficient (MFCC): MFCC is derived from the distorted frequency scale based on
hum
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3223
3223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









