







原文链接:https://zhuanlan.zhihu.com/p/512327050
0.引言
PPO算法(Proximal Policy Optimization)[1]是目前深度强化学习(DRL)领域,最广泛应用的算法之一。然而在实际应用的过程中,PPO算法的性能却受到多种因素的影响。本文总结了影响PPO算法性能的10个关键技巧,并通过实验结果的对比,来探究各个trick对PPO算法性能的影响。同时,我们将代码开源在了github上,分别提供了PPO算法的离散动作空间实现和连续动作空间实现(见下面github链接中的4.PPO-discrete和5.PPO-continuous(包括了Gaussian分布和Beta分布))
1.PPO算法概述
PPO算法的核心是使用如下策略损失函数:
(1)LCLIP(θ)=E^t[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]\delta_{t}^{V}=r_{t}+\gamma V_{\omega}\left(s_{t+1}\right)-V_{\omega}\left(s_{t}\right)\tag{4}
以上便是PPO原始论文的核心内容。其实在PPO的原始论文中,除了利用GAE计算优势函数外,并没有提到其他的实现细节和技巧。但是在实际的各种代码实现,例如Open AI Baseline、Open AI Spinning Up中,却包括了许许多多的“trick”,实验表明,这些trick都会在一定程度上影响PPO算法的性能。我在参考了《PPO-Implementation matters in deep policy gradients A case study on PPO and TRPO》[3]这篇论文,以及下面这篇博客后
通过自己的亲身实践,总结了影响PPO算法性能最关键的10个trick,如下表所示:
| Trick 1 | Advantage Normalization |
| Trick 2 | State Normalization |
| Trick 3 & Trick 4 | Reward Normalization & Reward Scaling |
| Trick 5 | Policy Entropy |
| Trick 6 | Learning Rate Decay |
| Trick 7 | Gradient clip |
| Trick 8 | Orthogonal Initialization |
| Trick 9 | Adam Optimizer Epsilon Parameter |
| Trick 10 | Tanh Activation Function |
我们把集成了上述10个trick后的PPO算法命名为PPO-max,而不使用这10个trick的最基础的PPO算法命名为PPO-min。我们在gym中的四个连续动作空间环境下(BipedalWalker-v3、HalfCheetah-v2、Hopper-v2、Walker2d-v2)分别进行了实验,训练结果对比如图1所示。
注:
1.关于Trick 3 & Trick 4,由于只能对reward进行一种操作,我们默认选择使用Reward Scaling。
2.因为是连续动作空间,因此我们默认使用Gaussian分布来输出动作。
3.我们在每个环境中都使用了3个随机种子进行实验,并使用seaborn画图,采用“滑动平均”的方法来平滑训练曲线,后文的实验结果图同理。
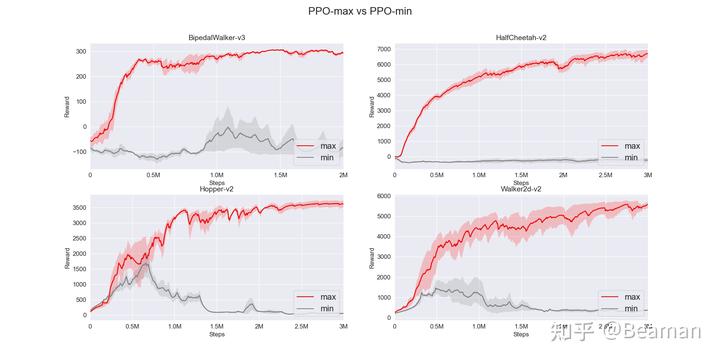

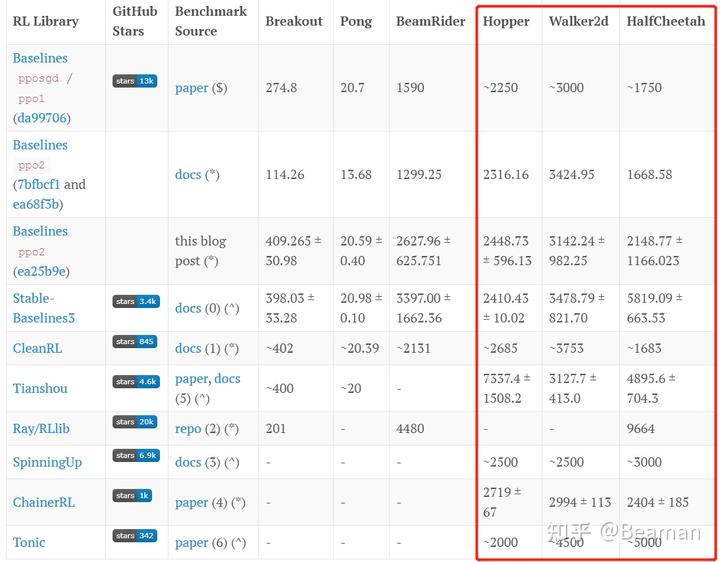
通过对比可以看出,不使用上述10个trick的PPO-min在四个gym环境上几乎无法训练,而PPO-max均可以到达非常理想的训练效果。在3M steps内,PPO-max在HalfCheetah-v2环境上reward可以达到6700,在Hopper-v2环境下可以达到3600,Walker2d-v2环境下可以达到5500。对比https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/这篇博客中给出的各个强化学习算法库的训练效果,除了“Tianshou”外,我们的实验结果均更胜一筹。

我们将代码开源在了github上,分别提供了PPO算法的离散动作空间实现和连续动作空间实现(见下面github链接中的4.PPO-discrete和5.PPO-continuous(包括了Gaussian分布和Beta分布),如果这份代码对您有帮助,欢迎您给一个star~)
2. 探究影响PPO算法性能的10个关键技巧
在这一节中,我们将逐一介绍上述PPO-max中10个trick的具体实现细节,并通过对比实验来探究这些trick究竟对PPO算法的性能有什么影响。(注:下面的实验讨论均已连续动作空间下Gaussian分布为例)
Trick 1—Advantage Normalization
在论文《The Mirage of Action-Dependent Baselines in Reinforcement Learning》[4]中提出了对advantage进行normalization的操作,可以提升PG算法的性能。具体代码实现层面,对advantage做normalization的方式主要有两种:
(1)batch adv norm:使用GAE计算完一个batch中的advantage后,计算整个batch中所有advantage的mean和std,然后减均值再除以标准差。
(2)minibatch adv norm:使用GAE计算完一个batch中的advantage后,不是直接对整个batch的advantage做normalization,而是在用每次利用minibatch更新策略之前,对当前这个minibatch中的advantage做normalization。(https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/ 这篇博客中使用的就是minibatch adv norm)
是否使用advantage normalization,以及batch adv norm和minibatch adv norm的对比如图3所示。在我们的PPO-max中,默认使用的是batch adv norm(红色曲线);如果关闭batch adv norm(棕色曲线),PPO算法几乎无法训练,由此可见advantage normalization对PPO算法的性能有非常重要的影响。如果把batch adv norm替换成minibatch adv norm(黑色曲线),训练性能会有一定程度的下降。
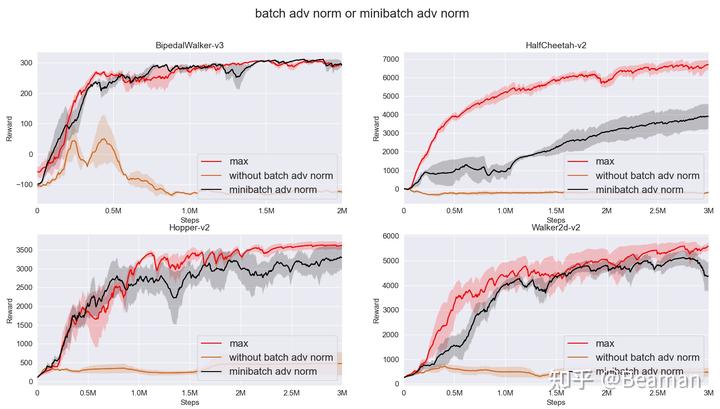

从原理角度分析,我个人认为如果是对每一个minibatch中的advantage单独做normalization,可能会导致每一次计算的mean和std有较大的波动,从而对算法的训练带来一定负面影响。因此,我们在这里建议使用batch adv norm的方式。
Trick 2—State Normalization
state normalization的核心在于,与环境交互的过程中,维护一个动态的关于所有经历过的所有state的mean和std, 然后对当前的获得的state做normalization。经过normalization后的state符合mean=0,std=1的正态分布,用这样的状态作为神经网络的输入,更有利于神经网络的训练。
具体实现方式如下:
(1)首先定义一个动态计算mean和std的class,名为RunningMeanStd。这个class中的方法的核心思想是已知n个数据的mean和std,如何计算n+1个数据的mean和std
注:使用这种方法计算mean和std的主要原因是,我们不可能事先初始化一个无限大的buffer,每获得一个新的状态数据后都重新计算buffer中所有数据的mean和std,这样太浪费计算资源和时间,也不现实。
class RunningMeanStd:
# Dynamically calculate mean and std
def __init__(self, shape): # shape:the dimension of input data
self.n = 0
self.mean = np.zeros(shape)
self.S = np.zeros(shape)
self.std = np.sqrt(self.S)
<span class="k">def</span> <span class="nf">update</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">x</span><span class="p">):</span>
<span class="n">x</span> <span class="o">=</span> <span class="n">np</span><span class="o">.</span><span class="n">array</span><span class="p">(</span><span class="n">x</span><span class="p">)</span>
<span class="bp">self</span><span class="o">.</span><span class="n">n</span> <span class="o">+=</span> <span class="mi">1</span>
<span class="k">if</span> <span class="bp">self</span><span class="o">.</span><span class="n">n</span> <span class="o">==</span> <span class="mi">1</span><span class="p">:</span>
<span class="bp">self</span><span class="o">.</span><span class="n">mean</span> <span class="o">=</span> <span class="n">x</span>
<span class="bp">self</span><span class="o">.</span><span class="n">std</span> <span class="o">=</span> <span class="n">x</span>
<span class="k">else</span><span class="p">:</span>
<span class="n">old_mean</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">mean</span><span class="o">.</span><span class="n">copy</span><span class="p">()</span>
<span class="bp">self</span><span class="o">.</span><span class="n">mean</span> <span class="o">=</span> <span class="n">old_mean</span> <span class="o">+</span> <span class="p">(</span><span class="n">x</span> <span class="o">-</span> <span class="n">old_mean</span><span class="p">)</span> <span class="o">/</span> <span class="bp">self</span><span class="o">.</span><span class="n">n</span>
<span class="bp">self</span><span class="o">.</span><span class="n">S</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">S</span> <span class="o">+</span> <span class="p">(</span><span class="n">x</span> <span class="o">-</span> <span class="n">old_mean</span><span class="p">)</span> <span class="o">*</span> <span class="p">(</span><span class="n">x</span> <span class="o">-</span> <span class="bp">self</span><span class="o">.</span><span class="n">mean</span><span class="p">)</span>
<span class="bp">self</span><span class="o">.</span><span class="n">std</span> <span class="o">=</span> <span class="n">np</span><span class="o">.</span><span class="n">sqrt</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">S</span> <span class="o">/</span> <span class="bp">self</span><span class="o">.</span><span class="n">n</span> <span class="p">)</span></code></pre></div><p data-pid="nfCvm6o2">(2)定义一个名叫<b><span class="nolink">Normalization</span></b>的类,其中实例化上面的<b>RunningMeanStd</b>,需要传入的参数shape代表当前环境的状态空间的维度。训练过程中,每次得到一个state,都要把这个state传到Normalization这个类中,然后更新mean和std,再返回normalization后的state。</p><div class="highlight"><pre><code class="language-python3"><span class="k">class</span> <span class="nc">Normalization</span><span class="p">:</span>
<span class="k">def</span> <span class="nf">__init__</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">shape</span><span class="p">):</span>
<span class="bp">self</span><span class="o">.</span><span class="n">running_ms</span> <span class="o">=</span> <span class="n">RunningMeanStd</span><span class="p">(</span><span class="n">shape</span><span class="o">=</span><span class="n">shape</span><span class="p">)</span>
<span class="k">def</span> <span class="nf">__call__</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">x</span><span class="p">,</span> <span class="n">update</span><span class="o">=</span><span class="kc">True</span><span class="p">):</span>
<span class="c1"># Whether to update the mean and std,during the evaluating,update=Flase</span>
<span class="k">if</span> <span class="n">update</span><span class="p">:</span>
<span class="bp">self</span><span class="o">.</span><span class="n">running_ms</span><span class="o">.</span><span class="n">update</span><span class="p">(</span><span class="n">x</span><span class="p">)</span>
<span class="n">x</span> <span class="o">=</span> <span class="p">(</span><span class="n">x</span> <span class="o">-</span> <span class="bp">self</span><span class="o">.</span><span class="n">running_ms</span><span class="o">.</span><span class="n">mean</span><span class="p">)</span> <span class="o">/</span> <span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">running_ms</span><span class="o">.</span><span class="n">std</span> <span class="o">+</span> <span class="mf">1e-8</span><span class="p">)</span>
<span class="k">return</span> <span class="n">x</span></code></pre></div><p data-pid="XRfb8pkw">是否使用state normalization的对比如图4所示,红色曲线为PPO-max,蓝色曲线为在PPO-max的基础上关闭state normalization。通过对比可以看出,state normalization这个trick对PPO算法的整体性能有一定提升。</p><figure data-size="normal"><noscript><img src="https://pic2.zhimg.com/v2-108c691f74efcc309d2de644669e79b1_b.jpg" data-size="normal" data-rawwidth="1600" data-rawheight="907" class="origin_image zh-lightbox-thumb" width="1600" data-original="https://pic2.zhimg.com/v2-108c691f74efcc309d2de644669e79b1_r.jpg"/></noscript><div><img src="https://pic2.zhimg.com/v2-108c691f74efcc309d2de644669e79b1_r.jpg" data-size="normal" data-rawwidth="1600" data-rawheight="907" class="origin_image zh-lightbox-thumb lazy" width="1600" data-original="https://pic2.zhimg.com/v2-108c691f74efcc309d2de644669e79b1_r.jpg" data-actualsrc="https://pic2.zhimg.com/v2-108c691f74efcc309d2de644669e79b1_b.jpg" data-original-token="v2-ec5a60ef7a758653731483db2640776b" height="907" data-lazy-status="ok"></div><figcaption>图4 是否使用state normalization</figcaption></figure><h3 id="h_512327050_4" data-into-catalog-status=""><b>Trick 3 & Trick 4—— Reward Normalization & Reward Scaling</b></h3><p data-pid="DoSo9Ijd">对reward的处理,目前有reward normalization和reward scaling两种方式:这两种处理方式的目的都是希望调整reward的尺度,避免因过大或过小的reward对价值函数的训练产生负面影响。</p><p data-pid="ds1d0gAz"><b>(1)reward normalization</b>:与state normalization的操作类似,也是动态维护所有获得过的reward的mean和std,然后再对当前的reward做normalization。</p><p data-pid="lZx2gDLm"><b>(2)reward scaling:</b>在《PPO-Implementation matters in deep policy gradients A case study on PPO and TRPO》<sup data-text="Engstrom L, Ilyas A, Santurkar S, et al. Implementation matters in deep policy gradients: A case study on PPO and TRPO[J]. arXiv preprint arXiv:2005.12729, 2020." data-url="" data-numero="3" data-draft-node="inline" data-draft-type="reference" data-tooltip="Engstrom L, Ilyas A, Santurkar S, et al. Implementation matters in deep policy gradients: A case study on PPO and TRPO[J]. arXiv preprint arXiv:2005.12729, 2020." data-tooltip-preset="white" data-tooltip-classname="ztext-referene-tooltip"><a id="ref_3_1" href="#ref_3" data-reference-link="true" aria-labelledby="ref_3">[3]</a></sup>这篇论文中,作者中提出了一种名叫reward scaling的方法,如图5所示。reward scaling与reward normalization的区别在于,reward scaling是动态计算一个standard deviation of a rolling discounted sum of the rewards,然后只对当前的reward除以这个std。</p><figure data-size="normal"><noscript><img src="https://pic1.zhimg.com/v2-ac1607e95b9a25c849afb838978400e8_b.jpg" data-size="normal" data-rawwidth="678" data-rawheight="191" class="origin_image zh-lightbox-thumb" width="678" data-original="https://pic1.zhimg.com/v2-ac1607e95b9a25c849afb838978400e8_r.jpg"/></noscript><div><img src="https://pic1.zhimg.com/v2-ac1607e95b9a25c849afb838978400e8_r.jpg" data-size="normal" data-rawwidth="678" data-rawheight="191" class="origin_image zh-lightbox-thumb lazy" width="678" data-original="https://pic1.zhimg.com/v2-ac1607e95b9a25c849afb838978400e8_r.jpg" data-actualsrc="https://pic1.zhimg.com/v2-ac1607e95b9a25c849afb838978400e8_b.jpg" data-original-token="v2-6741bfb567aefee86099e21e387504ae" height="191" data-lazy-status="ok"></div><figcaption>图5 PPO reward scaling</figcaption></figure><p data-pid="-RdnvxOY">reward scaling的代码实现被集成在了<b>RewardScaling</b>这个class中,具体代码如下:</p><div class="highlight"><pre><code class="language-python3"><span class="k">class</span> <span class="nc">RewardScaling</span><span class="p">:</span>
<span class="k">def</span> <span class="nf">__init__</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">shape</span><span class="p">,</span> <span class="n">gamma</span><span class="p">):</span>
<span class="bp">self</span><span class="o">.</span><span class="n">shape</span> <span class="o">=</span> <span class="n">shape</span> <span class="c1"># reward shape=1</span>
<span class="bp">self</span><span class="o">.</span><span class="n">gamma</span> <span class="o">=</span> <span class="n">gamma</span> <span class="c1"># discount factor</span>
<span class="bp">self</span><span class="o">.</span><span class="n">running_ms</span> <span class="o">=</span> <span class="n">RunningMeanStd</span><span class="p">(</span><span class="n">shape</span><span class="o">=</span><span class="bp">self</span><span class="o">.</span><span class="n">shape</span><span class="p">)</span>
<span class="bp">self</span><span class="o">.</span><span class="n">R</span> <span class="o">=</span> <span class="n">np</span><span class="o">.</span><span class="n">zeros</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">shape</span><span class="p">)</span>
<span class="k">def</span> <span class="nf">__call__</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">x</span><span class="p">):</span>
<span class="bp">self</span><span class="o">.</span><span class="n">R</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">gamma</span> <span class="o">*</span> <span class="bp">self</span><span class="o">.</span><span class="n">R</span> <span class="o">+</span> <span class="n">x</span>
<span class="bp">self</span><span class="o">.</span><span class="n">running_ms</span><span class="o">.</span><span class="n">update</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">R</span><span class="p">)</span>
<span class="n">x</span> <span class="o">=</span> <span class="n">x</span> <span class="o">/</span> <span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">running_ms</span><span class="o">.</span><span class="n">std</span> <span class="o">+</span> <span class="mf">1e-8</span><span class="p">)</span> <span class="c1"># Only divided std</span>
<span class="k">return</span> <span class="n">x</span>
<span class="k">def</span> <span class="nf">reset</span><span class="p">(</span><span class="bp">self</span><span class="p">):</span> <span class="c1"># When an episode is done,we should reset 'self.R'</span>
<span class="bp">self</span><span class="o">.</span><span class="n">R</span> <span class="o">=</span> <span class="n">np</span><span class="o">.</span><span class="n">zeros</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">shape</span><span class="p">)</span></code></pre></div><p data-pid="Ezo9_aYJ"><span class="nolink">reward norm</span>和reward scaling的对比如图6所示。图中,PPO-max(红色)中默认使用的是reward scaling,去掉reward scaling后(橙色),性能有一定程度下降;如果把PPO-max中的reward scaling 换成reward norm(紫色),在HalfCheetah-v2、Hopper-v2和Walker-v2这三个环境下,对训练性能的伤害非常严重。<b>因此,我们建议使用reward scaling而不是reward normalization。</b></p><figure data-size="normal"><noscript><img src="https://pic1.zhimg.com/v2-3550d4ef6137a82825eeea5ea5ddeae4_b.jpg" data-size="normal" data-rawwidth="1595" data-rawheight="910" class="origin_image zh-lightbox-thumb" width="1595" data-original="https://pic1.zhimg.com/v2-3550d4ef6137a82825eeea5ea5ddeae4_r.jpg"/></noscript><div><img src="https://pic1.zhimg.com/v2-3550d4ef6137a82825eeea5ea5ddeae4_r.jpg" data-size="normal" data-rawwidth="1595" data-rawheight="910" class="origin_image zh-lightbox-thumb lazy" width="1595" data-original="https://pic1.zhimg.com/v2-3550d4ef6137a82825eeea5ea5ddeae4_r.jpg" data-actualsrc="https://pic1.zhimg.com/v2-3550d4ef6137a82825eeea5ea5ddeae4_b.jpg" data-original-token="v2-dcf6b2d4767f65cdbf1a3b6f4e762f5e" height="910" data-lazy-status="ok"></div><figcaption>图6 reward scaling or reward normalization</figcaption></figure><h3 id="h_512327050_5" data-into-catalog-status=""><b>Trick 5—Policy Entropy</b></h3><p data-pid="a0vbs-jV">在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量。在强化学习中,策略的熵可以表示为:</p><p data-pid="rhAvQkxj"><span class="ztext-math" data-eeimg="1" data-tex="\mathcal{H}\left(\pi\left(\cdot \mid s_{t}\right)\right)=-\sum_{a_{t}} \pi\left(a_{t} \mid s_{t}\right) \log \left(\pi\left(a_{t} \mid s_{t}\right)\right)=\mathbb{E}_{a_{t} \sim \pi}\left[-\log \left(\pi\left(a_{t} \mid s_{t}\right)\right)\right]\tag{5}"><span></span><span><span class="MathJax_Preview" style="color: inherit;"></span><span class="MathJax_SVG_Display"><span class="MathJax_SVG" id="MathJax-Element-9-Frame" tabindex="0" style="font-size: 100%; display: inline-block; position: relative;" data-mathml="<math xmlns="http://www.w3.org/1998/Math/MathML" display="block"><mtable displaystyle="true"><mlabeledtr><mtd><mtext>(5)</mtext></mtd><mtd><mrow class="MJX-TeXAtom-ORD"><mi class="MJX-tex-caligraphic" mathvariant="script">H</mi></mrow><mrow><mo>(</mo><mi>&#x03C0;</mi><mrow><mo>(</mo><mo>&#x22C5;</mo><mo>&#x2223;</mo><msub><mi>s</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub><mo>)</mo></mrow><mo>)</mo></mrow><mo>=</mo><mo>&#x2212;</mo><munder><mo>&#x2211;</mo><mrow class="MJX-TeXAtom-ORD"><msub><mi>a</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub></mrow></munder><mi>&#x03C0;</mi><mrow><mo>(</mo><msub><mi>a</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub><mo>&#x2223;</mo><msub><mi>s</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub><mo>)</mo></mrow><mi>log</mi><mo>&#x2061;</mo><mrow><mo>(</mo><mi>&#x03C0;</mi><mrow><mo>(</mo><msub><mi>a</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub><mo>&#x2223;</mo><msub><mi>s</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub><mo>)</mo></mrow><mo>)</mo></mrow><mo>=</mo><msub><mrow class="MJX-TeXAtom-ORD"><mi mathvariant="double-struck">E</mi></mrow><mrow class="MJX-TeXAtom-ORD"><msub><mi>a</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub><mo>&#x223C;</mo><mi>&#x03C0;</mi></mrow></msub><mrow><mo>[</mo><mo>&#x2212;</mo><mi>log</mi><mo>&#x2061;</mo><mrow><mo>(</mo><mi>&#x03C0;</mi><mrow><mo>(</mo><msub><mi>a</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub><mo>&#x2223;</mo><msub><mi>s</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub><mo>)</mo></mrow><mo>)</mo></mrow><mo>]</mo></mrow></mtd></mlabeledtr></mtable></math>" role="presentation"><svg xmlns:xlink="http://www.w3.org/1999/xlink" width="79.807ex" height="5.569ex" viewBox="0 -1448.3 34361.2 2397.8" role="img" focusable="false" aria-hidden="true" style="vertical-align: -1.991ex; margin-bottom: -0.215ex; max-width: 68900px;"><g stroke="currentColor" fill="currentColor" stroke-width="0" transform="matrix(1 0 0 -1 0 0)"><g transform="translate(33081,0)"><g id="mjx-eqn-5" transform="translate(0,406)"><use xlink:href="#MJMAIN-28"></use><use xlink:href="#MJMAIN-35" x="389" y="0"></use><use xlink:href="#MJMAIN-29" x="890" y="0"></use></g></g><g transform="translate(1499,0)"><g transform="translate(-16,0)"><g transform="translate(0,406)"><use xlink:href="#MJCAL-48" x="0" y="0"></use><g transform="translate(1012,0)"><use xlink:href="#MJMAIN-28" x="0" y="0"></use><use xlink:href="#MJMATHI-3C0" x="389" y="0"></use><g transform="translate(1129,0)"><use xlink:href="#MJMAIN-28" x="0" y="0"></use><use xlink:href="#MJMAIN-22C5" x="389" y="0"></use><use xlink:href="#MJMAIN-2223" x="945" y="0"></use><g transform="translate(1502,0)"><use xlink:href="#MJMATHI-73" x="0" y="0"></use><use transform="scale(0.707)" xlink:href="#MJMATHI-74" x="663" y="-213"></use></g><use xlink:href="#MJMAIN-29" x="2327" y="0"></use></g><use xlink:href="#MJMAIN-29" x="3846" y="0"></use></g><use xlink:href="#MJMAIN-3D" x="5525" y="0"></use><use xlink:href="#MJMAIN-2212" x="6582" y="0"></use><g transform="translate(7527,0)"><use xlink:href="#MJSZ2-2211" x="0" y="0"></use><g transform="translate(409,-1051)"><use transform="scale(0.707)" xlink:href="#MJMATHI-61" x="0" y="0"></use><use transform="scale(0.5)" xlink:href="#MJMATHI-74" x="748" y="-213"></use></g></g><use xlink:href="#MJMATHI-3C0" x="9138" y="0"></use><g transform="translate(9878,0)"><use xlink:href="#MJMAIN-28" x="0" y="0"></use><g transform="translate(389,0)"><use xlink:href="#MJMATHI-61" x="0" y="0"></use><use transform="scale(0.707)" xlink:href="#MJMATHI-74" x="748" y="-213"></use></g><use xlink:href="#MJMAIN-2223" x="1552" y="0"></use><g transform="translate(2108,0)"><use xlink:href="#MJMATHI-73" x="0" y="0"></use><use transform="scale(0.707)" xlink:href="#MJMATHI-74" x="663" y="-213"></use></g><use xlink:href="#MJMAIN-29" x="2933" y="0"></use></g><g transform="translate(13368,0)"><use xlink:href="#MJMAIN-6C"></use><use xlink:href="#MJMAIN-6F" x="278" y="0"></use><use xlink:href="#MJMAIN-67" x="779" y="0"></use></g><g transform="translate(14648,0)"><use xlink:href="#MJMAIN-28" x="0" y="0"></use><use xlink:href="#MJMATHI-3C0" x="389" y="0"></use><g transform="translate(1129,0)"><use xlink:href="#MJMAIN-28" x="0" y="0"></use><g transform="translate(389,0)"><use xlink:href="#MJMATHI-61" x="0" y="0"></use><use transform="scale(0.707)" xlink:href="#MJMATHI-74" x="748" y="-213"></use></g><use xlink:href="#MJMAIN-2223" x="1552" y="0"></use><g transform="translate(2108,0)"><use xlink:href="#MJMATHI-73" x="0" y="0"></use><use transform="scale(0.707)" xlink:href="#MJMATHI-74" x="663" y="-213"></use></g><use xlink:href="#MJMAIN-29" x="2933" y="0"></use></g><use xlink:href="#MJMAIN-29" x="4452" y="0"></use></g><use xlink:href="#MJMAIN-3D" x="19768" y="0"></use><g transform="translate(20824,0)"><use xlink:href="#MJAMS-45" x="0" y="0"></use><g transform="translate(667,-150)"><use transform="scale(0.707)" xlink:href="#MJMATHI-61" x="0" y="0"></use><use transform="scale(0.5)" xlink:href="#MJMATHI-74" x="748" y="-213"></use><use transform="scale(0.707)" xlink:href="#MJMAIN-223C" x="885" y="0"></use><use transform="scale(0.707)" xlink:href="#MJMATHI-3C0" x="1663" y="0"></use></g></g><g transform="translate(23340,0)"><use xlink:href="#MJMAIN-5B" x="0" y="0"></use><use xlink:href="#MJMAIN-2212" x="278" y="0"></use><g transform="translate(1223,0)"><use xlink:href="#MJMAIN-6C"></use><use xlink:href="#MJMAIN-6F" x="278" y="0"></use><use xlink:href="#MJMAIN-67" x="779" y="0"></use></g><g transform="translate(2503,0)"><use xlink:href="#MJMAIN-28" x="0" y="0"></use><use xlink:href="#MJMATHI-3C0" x="389" y="0"></use><g transform="translate(1129,0)"><use xlink:href="#MJMAIN-28" x="0" y="0"></use><g transform="translate(389,0)"><use xlink:href="#MJMATHI-61" x="0" y="0"></use><use transform="scale(0.707)" xlink:href="#MJMATHI-74" x="748" y="-213"></use></g><use xlink:href="#MJMAIN-2223" x="1552" y="0"></use><g transform="translate(2108,0)"><use xlink:href="#MJMATHI-73" x="0" y="0"></use><use transform="scale(0.707)" xlink:href="#MJMATHI-74" x="663" y="-213"></use></g><use xlink:href="#MJMAIN-29" x="2933" y="0"></use></g><use xlink:href="#MJMAIN-29" x="4452" y="0"></use></g><use xlink:href="#MJMAIN-5D" x="7345" y="0"></use></g></g></g></g></g></svg><span class="MJX_Assistive_MathML MJX_Assistive_MathML_Block" role="presentation"><math xmlns="http://www.w3.org/1998/Math/MathML" display="block"><mtable displaystyle="true"><mlabeledtr><mtd><mtext>(5)</mtext></mtd><mtd><mrow class="MJX-TeXAtom-ORD"><mi class="MJX-tex-caligraphic" mathvariant="script">H</mi></mrow><mrow><mo>(</mo><mi>π</mi><mrow><mo>(</mo><mo>⋅</mo><mo>∣</mo><msub><mi>s</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub><mo>)</mo></mrow><mo>)</mo></mrow><mo>=</mo><mo>−</mo><munder><mo>∑</mo><mrow class="MJX-TeXAtom-ORD"><msub><mi>a</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub></mrow></munder><mi>π</mi><mrow><mo>(</mo><msub><mi>a</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub><mo>∣</mo><msub><mi>s</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub><mo>)</mo></mrow><mi>log</mi><mo></mo><mrow><mo>(</mo><mi>π</mi><mrow><mo>(</mo><msub><mi>a</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub><mo>∣</mo><msub><mi>s</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub><mo>)</mo></mrow><mo>)</mo></mrow><mo>=</mo><msub><mrow class="MJX-TeXAtom-ORD"><mi mathvariant="double-struck">E</mi></mrow><mrow class="MJX-TeXAtom-ORD"><msub><mi>a</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub><mo>∼</mo><mi>π</mi></mrow></msub><mrow><mo>[</mo><mo>−</mo><mi>log</mi><mo></mo><mrow><mo>(</mo><mi>π</mi><mrow><mo>(</mo><msub><mi>a</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub><mo>∣</mo><msub><mi>s</mi><mrow class="MJX-TeXAtom-ORD"><mi>t</mi></mrow></msub><mo>)</mo></mrow><mo>)</mo></mrow><mo>]</mo></mrow></mtd></mlabeledtr></mtable></math></span></span></span><script type="math/tex;mode=display" id="MathJax-Element-9">\mathcal{H}\left(\pi\left(\cdot \mid s_{t}\right)\right)=-\sum_{a_{t}} \pi\left(a_{t} \mid s_{t}\right) \log \left(\pi\left(a_{t} \mid s_{t}\right)\right)=\mathbb{E}_{a_{t} \sim \pi}\left[-\log \left(\pi\left(a_{t} \mid s_{t}\right)\right)\right]\tag{5}</script><span class="tex2jax_ignore math-holder">\mathcal{H}\left(\pi\left(\cdot \mid s_{t}\right)\right)=-\sum_{a_{t}} \pi\left(a_{t} \mid s_{t}\right) \log \left(\pi\left(a_{t} \mid s_{t}\right)\right)=\mathbb{E}_{a_{t} \sim \pi}\left[-\log \left(\pi\left(a_{t} \mid s_{t}\right)\right)\right]\tag{5}</span></span></span> </p><p data-pid="J2u5dm_s">一个策略的熵越大,意味着这个策略选择各个动作的概率更加“平均”。在PPO中,为了提高算法的探索能力,我们一般在actor的loss中增加一项策略熵,并乘以一个系数entropy_coef,使得在优化actor_loss的同时,让策略的熵尽可能大。一般我们设置entropy_coef=0.01。</p><p data-pid="dtEBwudg">是否使用策略熵的对比如图7所示,通过对比可以看出,使用策略熵可以一定程度提高训练效果,如果在PPO-max(红色)的基础上不适用策略熵(即令entropy_coef=0,图中粉色),reward往往会收敛到次优解。</p><figure data-size="normal"><noscript><img src="https://pic4.zhimg.com/v2-1a6b99afa539e303ba1474f9c572c4bb_b.jpg" data-size="normal" data-rawwidth="1590" data-rawheight="917" class="origin_image zh-lightbox-thumb" width="1590" data-original="https://pic4.zhimg.com/v2-1a6b99afa539e303ba1474f9c572c4bb_r.jpg"/></noscript><div><img src="https://pic4.zhimg.com/80/v2-1a6b99afa539e303ba1474f9c572c4bb_720w.webp" data-size="normal" data-rawwidth="1590" data-rawheight="917" class="origin_image zh-lightbox-thumb lazy" width="1590" data-original="https://pic4.zhimg.com/v2-1a6b99afa539e303ba1474f9c572c4bb_r.jpg" data-actualsrc="https://pic4.zhimg.com/v2-1a6b99afa539e303ba1474f9c572c4bb_b.jpg" data-original-token="v2-74418520c278ffcb4479970b9ca9d8ff" height="917" data-lazy-status="ok"></div><figcaption>图7 是否使用策略熵</figcaption></figure><h3 id="h_512327050_6" data-into-catalog-status=""><b>Trick 6—Learning Rate Decay</b></h3><p data-pid="3jtfJNoj">学习率衰减可以一定程度增强训练后期的平稳性,提高训练效果。这里我们采用<b>线性衰减</b>学习率的方式,使lr从初始的3e-4,随着训练步数线性下降到0,具体代码如下:</p><div class="highlight"><pre><code class="language-python3"><span class="k">def</span> <span class="nf">lr_decay</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">total_steps</span><span class="p">):</span>
<span class="n">lr_a_now</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">lr_a</span> <span class="o">*</span> <span class="p">(</span><span class="mi">1</span> <span class="o">-</span> <span class="n">total_steps</span> <span class="o">/</span> <span class="bp">self</span><span class="o">.</span><span class="n">max_train_steps</span><span class="p">)</span>
<span class="n">lr_c_now</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">lr_c</span> <span class="o">*</span> <span class="p">(</span><span class="mi">1</span> <span class="o">-</span> <span class="n">total_steps</span> <span class="o">/</span> <span class="bp">self</span><span class="o">.</span><span class="n">max_train_steps</span><span class="p">)</span>
<span class="k">for</span> <span class="n">p</span> <span class="ow">in</span> <span class="bp">self</span><span class="o">.</span><span class="n">optimizer_actor</span><span class="o">.</span><span class="n">param_groups</span><span class="p">:</span>
<span class="n">p</span><span class="p">[</span><span class="s1">'lr'</span><span class="p">]</span> <span class="o">=</span> <span class="n">lr_a_now</span>
<span class="k">for</span> <span class="n">p</span> <span class="ow">in</span> <span class="bp">self</span><span class="o">.</span><span class="n">optimizer_critic</span><span class="o">.</span><span class="n">param_groups</span><span class="p">:</span>
<span class="n">p</span><span class="p">[</span><span class="s1">'lr'</span><span class="p">]</span> <span class="o">=</span> <span class="n">lr_c_now</span></code></pre></div><p data-pid="08vk3bn-">是否使用学习率衰减的对比如图8所示,通过对比可以看出,学习率衰减这一trick的确对训练效果有一定帮助。</p><figure data-size="normal"><noscript><img src="https://pic2.zhimg.com/v2-644516199311777685b6e13e3d9c44f9_b.jpg" data-size="normal" data-rawwidth="1595" data-rawheight="913" class="origin_image zh-lightbox-thumb" width="1595" data-original="https://pic2.zhimg.com/v2-644516199311777685b6e13e3d9c44f9_r.jpg"/></noscript><div><img src="https://pic2.zhimg.com/80/v2-644516199311777685b6e13e3d9c44f9_720w.webp" data-size="normal" data-rawwidth="1595" data-rawheight="913" class="origin_image zh-lightbox-thumb lazy" width="1595" data-original="https://pic2.zhimg.com/v2-644516199311777685b6e13e3d9c44f9_r.jpg" data-actualsrc="https://pic2.zhimg.com/v2-644516199311777685b6e13e3d9c44f9_b.jpg" data-original-token="v2-70f57f1e55cbc4ced9c348a7d0ee08a4" height="913" data-lazy-status="ok"></div><figcaption>图8 是否使用学习率衰减</figcaption></figure><h3 id="h_512327050_7" data-into-catalog-status=""><b>Trick 7—Gradient clip</b></h3><p data-pid="otq5jldx">梯度剪裁是为了防止训练过程中梯度爆炸从而引入的一项trick,同样可以起到稳定训练过程的作用。在Pytorch中,梯度剪裁只需要在更新actor和critic时增加一条语句即可实现。</p><div class="highlight"><pre><code class="language-python"><span class="c1"># Update actor</span>
self.optimizer_actor.zero_grad()
actor_loss.mean().backward()
if self.use_grad_clip: # Trick 7: Gradient clip
torch.nn.utils.clip_grad_norm_(self.actor.parameters(), 0.5)
self.optimizer_actor.step()
# Update critic
self.optimizer_critic.zero_grad()
critic_loss.backward()
if self.use_grad_clip: # Trick 7: Gradient clip
torch.nn.utils.clip_grad_norm_(self.critic.parameters(), 0.5)
self.optimizer_critic.step()
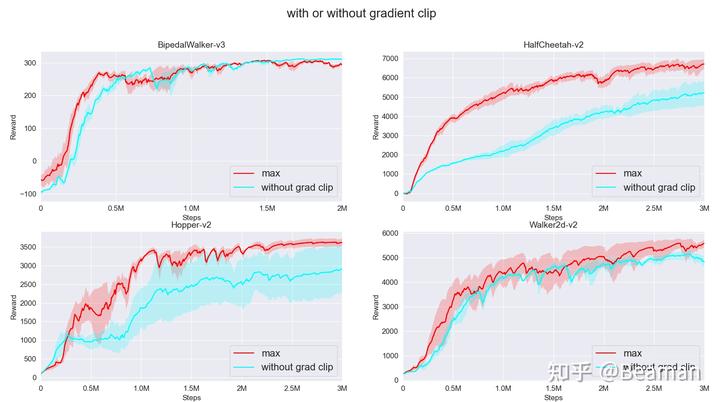
是否增加gradient clip的对比如图9所示,通过对比可以看出,gradient clip对训练效果有一定提升。

Trick 8—Orthogonal Initialization
正交初始化(Orthogonal Initialization)是为了防止在训练开始时出现梯度消失、梯度爆炸等问题所提出的一种神经网络初始化方式。具体的方法分为两步:
(1)用均值为0,标准差为1的高斯分布初始化权重矩阵,
(2)对这个权重矩阵进行奇异值分解,得到两个正交矩阵,取其中之一作为该层神经网络的权重矩阵。
使用正交初始化的Actor和Critic实现如下面的代码所示:
注:
1. 我们一般在初始化actor网络的输出层时,会把gain设置成0.01,actor网络的其他层和critic网络都使用Pytorch中正交初始化默认的gain=1.0。
2. 在我们的实现中,actor网络的输出层只输出mean,同时采用nn.Parameter的方式来训练一个“状态独立”的log_std,这往往比直接让神经网络同时输出mean和std效果好。(之所以训练log_std,是为了保证std=exp(log_std)>0)
# orthogonal init
def orthogonal_init(layer, gain=1.0):
nn.init.orthogonal_(layer.weight, gain=gain)
nn.init.constant_(layer.bias, 0)
class Actor_Gaussian(nn.Module):
def init(self, args):
super(Actor_Gaussian, self).init()
self.max_action = args.max_action
self.fc1 = nn.Linear(args.state_dim, args.hidden_width)
self.fc2 = nn.Linear(args.hidden_width, args.hidden_width)
self.mean_layer = nn.Linear(args.hidden_width, args.action_dim)
self.log_std = nn.Parameter(torch.zeros(1, args.action_dim)) # We use ‘nn.Paremeter’ to train log_std automatically
if args.use_orthogonal_init:
print(“------use_orthogonal_init------”)
orthogonal_init(self.fc1)
orthogonal_init(self.fc2)
orthogonal_init(self.mean_layer, gain=0.01)
<span class="k">def</span> <span class="nf">forward</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">s</span><span class="p">):</span>
<span class="n">s</span> <span class="o">=</span> <span class="n">torch</span><span class="o">.</span><span class="n">tanh</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">fc1</span><span class="p">(</span><span class="n">s</span><span class="p">))</span>
<span class="n">s</span> <span class="o">=</span> <span class="n">torch</span><span class="o">.</span><span class="n">tanh</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">fc2</span><span class="p">(</span><span class="n">s</span><span class="p">))</span>
<span class="n">mean</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">max_action</span> <span class="o">*</span> <span class="n">torch</span><span class="o">.</span><span class="n">tanh</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">mean_layer</span><span class="p">(</span><span class="n">s</span><span class="p">))</span> <span class="c1"># [-1,1]->[-max_action,max_action]</span>
<span class="k">return</span> <span class="n">mean</span>
<span class="k">def</span> <span class="nf">get_dist</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">s</span><span class="p">):</span>
<span class="n">mean</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">forward</span><span class="p">(</span><span class="n">s</span><span class="p">)</span>
<span class="n">log_std</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">log_std</span><span class="o">.</span><span class="n">expand_as</span><span class="p">(</span><span class="n">mean</span><span class="p">)</span> <span class="c1"># To make 'log_std' have the same dimension as 'mean'</span>
<span class="n">std</span> <span class="o">=</span> <span class="n">torch</span><span class="o">.</span><span class="n">exp</span><span class="p">(</span><span class="n">log_std</span><span class="p">)</span> <span class="c1"># The reason we train the 'log_std' is to ensure std=exp(log_std)>0</span>
<span class="n">dist</span> <span class="o">=</span> <span class="n">Normal</span><span class="p">(</span><span class="n">mean</span><span class="p">,</span> <span class="n">std</span><span class="p">)</span> <span class="c1"># Get the Gaussian distribution</span>
<span class="k">return</span> <span class="n">dist</span>
class Critic(nn.Module):
def init(self, args):
super(Critic, self).init()
self.fc1 = nn.Linear(args.state_dim, args.hidden_width)
self.fc2 = nn.Linear(args.hidden_width, args.hidden_width)
self.fc3 = nn.Linear(args.hidden_width, 1)
if args.use_orthogonal_init:
print(“------use_orthogonal_init------”)
orthogonal_init(self.fc1)
orthogonal_init(self.fc2)
orthogonal_init(self.fc3)
<span class="k">def</span> <span class="nf">forward</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">s</span><span class="p">):</span>
<span class="n">s</span> <span class="o">=</span> <span class="n">torch</span><span class="o">.</span><span class="n">tanh</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">fc1</span><span class="p">(</span><span class="n">s</span><span class="p">))</span>
<span class="n">s</span> <span class="o">=</span> <span class="n">torch</span><span class="o">.</span><span class="n">tanh</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">fc2</span><span class="p">(</span><span class="n">s</span><span class="p">))</span>
<span class="n">v_s</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">fc3</span><span class="p">(</span><span class="n">s</span><span class="p">)</span>
<span class="k">return</span> <span class="n">v_s</span></code></pre></div><p data-pid="o-nZuBc0">是否使用正交初始化的对比如图所10示,通过对比可以看出,正交初始化对训练性能有一定提高。</p><figure data-size="normal"><noscript><img src="https://pic3.zhimg.com/v2-4193ebc09ce2e6851d68b08e3f814772_b.jpg" data-size="normal" data-rawwidth="1588" data-rawheight="908" class="origin_image zh-lightbox-thumb" width="1588" data-original="https://pic3.zhimg.com/v2-4193ebc09ce2e6851d68b08e3f814772_r.jpg"/></noscript><div><img src="https://pic3.zhimg.com/80/v2-4193ebc09ce2e6851d68b08e3f814772_720w.webp" data-size="normal" data-rawwidth="1588" data-rawheight="908" class="origin_image zh-lightbox-thumb lazy" width="1588" data-original="https://pic3.zhimg.com/v2-4193ebc09ce2e6851d68b08e3f814772_r.jpg" data-actualsrc="https://pic3.zhimg.com/v2-4193ebc09ce2e6851d68b08e3f814772_b.jpg" data-original-token="v2-28971e170fcb064f394ed7970a9d0a5d" height="908" data-lazy-status="ok"></div><figcaption>图10 是否使用正交初始化</figcaption></figure><h3 id="h_512327050_9" data-into-catalog-status=""><b>Trick 9—Adam Optimizer Epsilon Parameter</b></h3><p data-pid="Z55udHCu">pytorch中Adam优化器默认的eps=1e-8,它的作用是提高数值稳定性(pytorch官方文档中对Adam优化器的介绍如图11,eps即红框中的 <span class="ztext-math" data-eeimg="1" data-tex="\epsilon"><span></span><span><span class="MathJax_Preview" style="color: inherit;"></span><span class="MathJax_SVG" id="MathJax-Element-10-Frame" tabindex="0" style="font-size: 100%; display: inline-block; position: relative;" data-mathml="<math xmlns="http://www.w3.org/1998/Math/MathML"><mi>&#x03F5;</mi></math>" role="presentation"><svg xmlns:xlink="http://www.w3.org/1999/xlink" width="0.944ex" height="1.399ex" viewBox="0 -500.7 406.5 602.5" role="img" focusable="false" aria-hidden="true" style="vertical-align: -0.236ex;"><g stroke="currentColor" fill="currentColor" stroke-width="0" transform="matrix(1 0 0 -1 0 0)"><use xlink:href="#MJMATHI-3F5" x="0" y="0"></use></g></svg><span class="MJX_Assistive_MathML" role="presentation"><math xmlns="http://www.w3.org/1998/Math/MathML"><mi>ϵ</mi></math></span></span><script type="math/tex;mode=inline" id="MathJax-Element-10">\epsilon</script><span class="tex2jax_ignore math-holder">\epsilon</span></span></span> )</p><figure data-size="normal"><noscript><img src="https://pic3.zhimg.com/v2-6b63fab469df8d2ee347043064274ff2_b.jpg" data-size="normal" data-rawwidth="510" data-rawheight="484" class="origin_image zh-lightbox-thumb" width="510" data-original="https://pic3.zhimg.com/v2-6b63fab469df8d2ee347043064274ff2_r.jpg"/></noscript><div><img src="https://pic3.zhimg.com/80/v2-6b63fab469df8d2ee347043064274ff2_720w.webp" data-size="normal" data-rawwidth="510" data-rawheight="484" class="origin_image zh-lightbox-thumb lazy" width="510" data-original="https://pic3.zhimg.com/v2-6b63fab469df8d2ee347043064274ff2_r.jpg" data-actualsrc="https://pic3.zhimg.com/v2-6b63fab469df8d2ee347043064274ff2_b.jpg" data-original-token="v2-42fe2b4630229bf7fa54648fbfb2f357" height="484" data-lazy-status="ok"></div><figcaption>图11 Pytorch官方文档中Adam优化器介绍</figcaption></figure><p data-pid="NO78Pm-c">在Open AI的baseline,和MAPPO的论文里,都单独设置eps=1e-5,这个特殊的设置可以在一定程度上提升算法的训练性能。</p><p data-pid="dEjhTno0">是否设置Adam优化器中eps参数的对比如图10所示,通过对比可以看出,单独设置Adam优化器的eps=1e-5可以一定程度提升算法性能。</p><figure data-size="normal"><noscript><img src="https://pic2.zhimg.com/v2-bc5c1876dd0f01e0d08b99870fcc50cd_b.jpg" data-size="normal" data-rawwidth="1590" data-rawheight="910" class="origin_image zh-lightbox-thumb" width="1590" data-original="https://pic2.zhimg.com/v2-bc5c1876dd0f01e0d08b99870fcc50cd_r.jpg"/></noscript><div><img src="https://pic2.zhimg.com/80/v2-bc5c1876dd0f01e0d08b99870fcc50cd_720w.webp" data-size="normal" data-rawwidth="1590" data-rawheight="910" class="origin_image zh-lightbox-thumb lazy" width="1590" data-original="https://pic2.zhimg.com/v2-bc5c1876dd0f01e0d08b99870fcc50cd_r.jpg" data-actualsrc="https://pic2.zhimg.com/v2-bc5c1876dd0f01e0d08b99870fcc50cd_b.jpg" data-original-token="v2-5799f4b140ee3d8be5c90e6a6f2e11a0" height="910" data-lazy-status="ok"></div><figcaption>图12 是否设置Adam eps</figcaption></figure><h3 id="h_512327050_10" data-into-catalog-status=""><b>Trick10—Tanh A<span class="nolink">ctivation</span> F<span class="nolink">unction</span></b></h3><p data-pid="v3hFSfcK">一般的强化学习算法,例如DDPG TD3 SAC等算法,都默认使用relu激活函数,但是经过实验表明,PPO算法更适合使用Tanh激活函数。在论文《PPO-Implementation matters in deep policy gradients A case study on PPO and TRPO》<sup data-text="Engstrom L, Ilyas A, Santurkar S, et al. Implementation matters in deep policy gradients: A case study on PPO and TRPO[J]. arXiv preprint arXiv:2005.12729, 2020." data-url="" data-numero="3" data-draft-node="inline" data-draft-type="reference" data-tooltip="Engstrom L, Ilyas A, Santurkar S, et al. Implementation matters in deep policy gradients: A case study on PPO and TRPO[J]. arXiv preprint arXiv:2005.12729, 2020." data-tooltip-preset="white" data-tooltip-classname="ztext-referene-tooltip"><a id="ref_3_2" href="#ref_3" data-reference-link="true" aria-labelledby="ref_3">[3]</a></sup>中,作者也建议使用tanh激活函数。</p><p data-pid="q5fnAZUD">使用tanh和relu激活函数的对比如图13所示,在PPO-max中我们默认使用的是tanh激活函数,把PPO-max中的激活函数替换成relu后(actor网络的最后一层mean_layer依然使用tanh),算法性能有了一定程度的下降。<b>因此我们建议PPO算法默认使用tanh激活函数。</b></p><figure data-size="normal"><noscript><img src="https://pic1.zhimg.com/v2-77af91634481f1c21cd65e0c68ec8bac_b.jpg" data-size="normal" data-rawwidth="1588" data-rawheight="910" class="origin_image zh-lightbox-thumb" width="1588" data-original="https://pic1.zhimg.com/v2-77af91634481f1c21cd65e0c68ec8bac_r.jpg"/></noscript><div><img src="https://pic1.zhimg.com/80/v2-77af91634481f1c21cd65e0c68ec8bac_720w.webp" data-size="normal" data-rawwidth="1588" data-rawheight="910" class="origin_image zh-lightbox-thumb lazy" width="1588" data-original="https://pic1.zhimg.com/v2-77af91634481f1c21cd65e0c68ec8bac_r.jpg" data-actualsrc="https://pic1.zhimg.com/v2-77af91634481f1c21cd65e0c68ec8bac_b.jpg" data-original-token="v2-79681c7ad08561f800ff953612467c86" height="910" data-lazy-status="ok"></div><figcaption>图13 激活函数tanh or relu</figcaption></figure><h2 id="h_512327050_11" data-into-catalog-status="">3.关于PPO算法的一些补充</h2><h3 id="h_512327050_12" data-into-catalog-status="">3.1关于GAE的计算,以及done信号的区分</h3><p data-pid="hO1bcxms">在gym的环境中,done=True有三种情况:</p><ol><li data-pid="nsFW7fKt">游戏胜利(win) </li></ol><p data-pid="cKL6Rl5n">2. 游戏失败(dead)</p><p data-pid="ghLWHWRH">3. 达到最大步长</p><p data-pid="kLTBCbaU">对于前两种情况,即dead or win的时候,我们可以认为当前的状态s就是终止状态,没有下一个状态s'的(例如BipedalWalker-v3这个环境,就会出现智能体通关或者摔倒的情形)。而对于第三种情况,即达到最大步长,这时本质上是人为“截断”了当前的回合,事实上当前的状态s并不是终止状态。因此我们在主循环中,需要对env.step()返回的done进行区分。为了区分前两种情况和第三种情况,我在程序中做了如下处理:</p><div class="highlight"><pre><code class="language-text">if done and episode_steps != args.max_episode_steps:
dw = True
else:
dw = False
我用dw这个变量来表示dead or win这两种情况,然后同时向Buffer中存储dw和done。在计算GAE时,对dw和done进行区分:
if dw=True: deltas=r-v(s)
if dw=False:deltas=r+gamma v(s’)-v(s)
当done=True时,说明出现了上述三种情况的其中之一,即意味着一个episode的结束。在逆序计算adv时,遇到done=True,就要重新计算。
使用GAE计算advangate的具体代码如下
s, a, a_logprob, r, s_, dw, done = replay_buffer.numpy_to_tensor() # Get training data
“”"
Calculate the advantage using GAE
‘dw=True’ means dead or win, there is no next state s’
‘done=True’ represents the terminal of an episode(dead or win or reaching the max_episode_steps). When calculating the adv, if done=True, gae=0
“”"
adv = []
gae = 0
with torch.no_grad(): # adv and v_target have no gradient
vs = self.critic(s)
vs_ = self.critic(s_)
deltas = r + self.gamma (1.0 - dw) vs_ - vs
for delta, d in zip(reversed(deltas.flatten().numpy()), reversed(done.flatten().numpy())):
gae = delta + self.gamma self.lamda gae (1.0 - d)
adv.insert(0, gae)
adv = torch.tensor(adv, dtype=torch.float).view(-1, 1)
v_target = adv + vs
if self.use_adv_norm: # Trick 1:advantage normalization
adv = ((adv - adv.mean()) / (adv.std() + 1e-5))3.2 Guassian分布与Beta分布
一般的连续动作空间版本的PPO算法,都默认使用Gaussian分布来输出动作。在《Improving Stochastic Policy Gradients in Continuous Control with Deep Reinforcement Learning using the Beta Distribution 》[5]指出,由于Gaussian分布是一个无界的分布,我们在采样动作后往往需要clip操作来把动作限制在有效动作范围内,这个clip的操作往往会给算法性能带来负面影响。因此这篇论文提出采用一个有界的Beta分布来代替Guassain分布,通过Beta分布采样的动作一定在[0,1]区间内(Beta分布的概率密度函数曲线如图14所示),因此我们可以把采样到的[0,1]区间内的动作映射到任何我们想要的动作区间。


在PPO中采用Beta分布的主要改动在于actor网络的定义,代码如下:
class Actor_Beta(nn.Module):
def init(self, args):
super(Actor_Beta, self).init()
self.fc1 = nn.Linear(args.state_dim, args.hidden_width)
self.fc2 = nn.Linear(args.hidden_width, args.hidden_width)
self.alpha_layer = nn.Linear(args.hidden_width, args.action_dim)
self.beta_layer = nn.Linear(args.hidden_width, args.action_dim)
if args.use_orthogonal_init:
print(“------use_orthogonal_init------”)
orthogonal_init(self.fc1, gain=1.0)
orthogonal_init(self.fc2, gain=1.0)
orthogonal_init(self.alpha_layer, gain=0.01)
orthogonal_init(self.beta_layer, gain=0.01)
<span class="k">def</span> <span class="nf">forward</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">s</span><span class="p">):</span>
<span class="n">s</span> <span class="o">=</span> <span class="n">torch</span><span class="o">.</span><span class="n">tanh</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">fc1</span><span class="p">(</span><span class="n">s</span><span class="p">))</span>
<span class="n">s</span> <span class="o">=</span> <span class="n">torch</span><span class="o">.</span><span class="n">tanh</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">fc2</span><span class="p">(</span><span class="n">s</span><span class="p">))</span>
<span class="c1"># alpha and beta need to be larger than 1,so we use 'softplus' as the activation function and then plus 1</span>
<span class="n">alpha</span> <span class="o">=</span> <span class="n">F</span><span class="o">.</span><span class="n">softplus</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">alpha_layer</span><span class="p">(</span><span class="n">s</span><span class="p">))</span> <span class="o">+</span> <span class="mf">1.0</span>
<span class="n">beta</span> <span class="o">=</span> <span class="n">F</span><span class="o">.</span><span class="n">softplus</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">beta_layer</span><span class="p">(</span><span class="n">s</span><span class="p">))</span> <span class="o">+</span> <span class="mf">1.0</span>
<span class="k">return</span> <span class="n">alpha</span><span class="p">,</span> <span class="n">beta</span>
<span class="k">def</span> <span class="nf">get_dist</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">s</span><span class="p">):</span>
<span class="n">alpha</span><span class="p">,</span> <span class="n">beta</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">forward</span><span class="p">(</span><span class="n">s</span><span class="p">)</span>
<span class="n">dist</span> <span class="o">=</span> <span class="n">Beta</span><span class="p">(</span><span class="n">alpha</span><span class="p">,</span> <span class="n">beta</span><span class="p">)</span>
<span class="k">return</span> <span class="n">dist</span>
<span class="k">def</span> <span class="nf">mean</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">s</span><span class="p">):</span>
<span class="n">alpha</span><span class="p">,</span> <span class="n">beta</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">forward</span><span class="p">(</span><span class="n">s</span><span class="p">)</span>
<span class="n">mean</span> <span class="o">=</span> <span class="n">alpha</span> <span class="o">/</span> <span class="p">(</span><span class="n">alpha</span> <span class="o">+</span> <span class="n">beta</span><span class="p">)</span> <span class="c1"># The mean of the beta distribution</span>
<span class="k">return</span> <span class="n">mean</span></code></pre></div><p data-pid="4qP1jU1X">在一些环境下,例如HalfCheetah-v2,采用Beta有时会比Gaussian获得更好的效果,如图15所示。</p><figure data-size="normal"><noscript><img src="https://pic4.zhimg.com/v2-ba1186e7a00246c130c52f1d1689b157_b.jpg" data-size="normal" data-rawwidth="1609" data-rawheight="843" class="origin_image zh-lightbox-thumb" width="1609" data-original="https://pic4.zhimg.com/v2-ba1186e7a00246c130c52f1d1689b157_r.jpg"/></noscript><div><img src="https://pic4.zhimg.com/80/v2-ba1186e7a00246c130c52f1d1689b157_720w.webp" data-size="normal" data-rawwidth="1609" data-rawheight="843" class="origin_image zh-lightbox-thumb lazy" width="1609" data-original="https://pic4.zhimg.com/v2-ba1186e7a00246c130c52f1d1689b157_r.jpg" data-actualsrc="https://pic4.zhimg.com/v2-ba1186e7a00246c130c52f1d1689b157_b.jpg" data-original-token="v2-21d8f8949231bb40c39e73d86b453cf4" height="843" data-lazy-status="ok"></div><figcaption>图15 Gaussian VS Beta</figcaption></figure><p data-pid="xy631fOZ">因此,我们在PPO算法的实现中,集成了Beta分布,可以通过设置'policy_dist'参数来实现Gaussian分布和Beta分布之间的切换。</p><h2 id="h_512327050_14" data-into-catalog-status="">4. 总结</h2><p data-pid="HmPNaURm">在这篇文章中,我根据自己个人的实际经验,列出了影响PPO算法性能的10个关键技巧,并通过对比实验来探究这些技巧对PPO算法性能的具体影响,同时给出了完整的PPO算法的pytorch实现(包括了离散动作版本和连续动作版本(集成Gaussian分布和Beta分布))。</p><p data-pid="wyYqqh6T">同时,我想额外指出的是,我上面列出的这10条trick,也不一定在所有的情况下都有效。很多时候,深度强化学习算法的训练是一件很“玄”的事情,不同的环境,不同的状态空间、动作空间和奖励函数的设计,都会对算法的性能产生不同的影响。同样的一个trick,可能在一个任务中效果很好,在另一个任务中却完全不work。我总结这10条trick,更多的是希望给正在学习和使用PPO算法的朋友提供一个整体方向上的引导,当你在用PPO算法解决一个实际任务但是效果不理想时,或许可以尝试一下我列出的这几条trick。当然,过渡迷恋于调参往往是不可取的,我们应该把更多的注意力放在模型算法本身的改进上。</p><p data-pid="YJ8_5d4B">最后,由于本人水平有限,上述文章内容和代码中难免存在错误,欢迎大家与我交流,批评指正!</p><p></p><h2>参考</h2><ol class="ReferenceList"><li id="ref_1" tabindex="0"><a class="ReferenceList-backLink" href="#ref_1_0" aria-label="back" data-reference-link="true">^</a><span>Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv:1707.06347, 2017.</span></li><li id="ref_2" tabindex="0"><a class="ReferenceList-backLink" href="#ref_2_0" aria-label="back" data-reference-link="true">^</a><span>Schulman J, Moritz P, Levine S, et al. High-dimensional continuous control using generalized advantage estimation[J]. arXiv preprint arXiv:1506.02438, 2015.</span></li><li id="ref_3" tabindex="0"><span class="ReferenceList-backHint" aria-label="back">^</span><sup class="ReferenceList-backLink"><a href="#ref_3_0" data-reference-link="true">a</a></sup><sup class="ReferenceList-backLink"><a href="#ref_3_1" data-reference-link="true">b</a></sup><sup class="ReferenceList-backLink"><a href="#ref_3_2" data-reference-link="true">c</a></sup><span>Engstrom L, Ilyas A, Santurkar S, et al. Implementation matters in deep policy gradients: A case study on PPO and TRPO[J]. arXiv preprint arXiv:2005.12729, 2020.</span></li><li id="ref_4" tabindex="0"><a class="ReferenceList-backLink" href="#ref_4_0" aria-label="back" data-reference-link="true">^</a><span>Tucker G, Bhupatiraju S, Gu S, et al. The mirage of action-dependent baselines in reinforcement learning[C]//International conference on machine learning. PMLR, 2018: 5015-5024.</span></li><li id="ref_5" tabindex="0"><a class="ReferenceList-backLink" href="#ref_5_0" aria-label="back" data-reference-link="true">^</a><span>Chou P W, Maturana D, Scherer S. Improving stochastic policy gradients in continuous control with deep reinforcement learning using the beta distribution[C]//International conference on machine learning. PMLR, 2017: 834-843.</span></li></ol></div>















 3353
3353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









