










为了保证 DRL 算法能够顺利收敛,policy 性能达标并具有实用价值,结果有说服力且能复现,需要算法工作者在训练前、训练中和训练后提供全方位一条龙服务。我记得 GANs 刚火起来的时候,因为训练难度高,有人在 GitHub 上专门开了 repository,总结来自学术界和工业界的最新训练经验,各种经过或未经验证的 tricks 被堆砌在一起,吸引了全世界 AI 爱好者的热烈讨论,可谓盛况空前。在玄学方面,DRL 算法训练有得一拼。但毕竟在科研领域没有人真的喜欢玄学,只有久经考验的一般化规律才能凝结成知识被更多的人接受和推广。本篇接下来的内容融合了许多个人经验和各种参考资料,算是在 DRL 训练 “去玄学” 化上做出的一点微不足道的努力。
1. 训练开始前
1.1 环境可视化
如果条件允许,开始训练前最好先可视化一个随机环境,观察是否会出现你希望的状态(即上一篇里的主线事件)。如果靠随机选择 action 都能以一定概率探索到目标状态,那说明该任务难度比较低,心里就可以更有底;如果从来不会出现目标状态,说明该任务难度较高,需要在状态空间和 reward 函数设计时特别下功夫,从而更好地引导 agent 向目标状态前进。

1.2 数据预处理
你还可以实时打印出 state 和 reward,看看它们是否在合理范围内取值,是否存在幅值过大的情况,如果是则需要增加必要的归一化操作。事实上,我推荐无条件进行状态空间归一化和 reward rescale & clipping,实践证明这两个操作无论在收敛速度还是最终性能上都会带来明显提升。前一个操作很好理解,我只介绍一下 reward rescale & clipping,该操作尤其适合基于 episode 的 A3C/A2C/PPO 算法,参考形式为 r=clip(r/(std(Return)+ ϵ \epsilon ϵ,其中 Return = ∑ t = 0 T γ t r t \sum_{t=0}^{T}{\gamma^{t}r_{t}} ∑t=0Tγtrt,是一段 episode 内 reward 的折扣累加和,也就是 V 网络拟合的对象,而 V 网络输出又为 policy 优化提供参考,使用该值的统计方差对 reward 进行 rescale,可以反过来有效降低 Return 的 variance,有助于 V 网络和 policy 网络进行更加无偏地学习。训练过程中通常采用 Return 的 running std 来 rescale 当前 reward。最外层的 clip 操作可以滤除那些绝对值过大的 reward,作用类似。
注意 reward 只能进行 rescale,而不能整体平移(减去均值)。回报函数中各项 reward 的符号以及它们之间的相对大小唯一确定了回报函数的实际功能,各项 reward 的整体缩放对其没有影响,但整体平移会改变这种相对大小,也就改变了回报函数的功能。事实上,哪怕是 clip 操作也在一定程度上存在这种问题,但通常影响不大。
2. 训练进行中
2.1 拥抱不确定性
终于要开始调参了!如果你做过 CV 项目,会发现相对来说 DRL 训练的不确定性更高,可复现性更差。这是因为 DRL 算法不仅超参数多,而且对它们非常敏感,这里贴张图给大家感受一下。
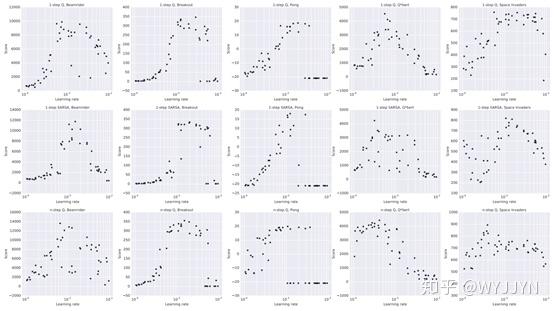
上图是三个 DRL 算法(纵向)在五个 Atari 游戏(横向)中的得分随学习率变化的趋势。可以看到,以 10 倍为单位,高性能所对应的学习率区间普遍很窄,要达到最优性能真得靠地毯式搜索。其实原作者本意是想通过这张图表明他们的方法对超参数变化抵抗力较好……,况且这还只是针对学习率这一个超参数。
当我们刚开始尝试用 DRL 算法解决一个全新问题时,性能好坏甚至都是其次,能否收敛才是最关键的。牛逼闪闪的 OpenAI Five 都听说过吧?其团队成员在接受采访时承认,他们第一次将训练跑起来后因为心里实在没底,干脆全体度假去了,回来后打开屏幕发现竟然收敛了,上帝保佑!

尽管 DRL 对超参数如此敏感,也没有必要过分悲观。当我们在心理上接受了这一事实,并开始潜心研究时,就会发现 DRL 训练还是有迹可循的,尤其是随着实际经验的积累和对算法本质理解的不断深入,将每个超参数的作用都了然于胸,那么训练出优秀 policy 的可能性就会大很多。接下来我以 DQN,DDPG 和 PPO 为例,介绍一下其中的主要超参数和调参技巧。
2.2 DRL 通用超参数
有些超参数不是某个算法所特有,而是 DRL 普遍使用的,而且作用原理和设置依据都差不多,我放到最前面集中介绍。典型的通用超参数包括折扣因子、网络结构和学习率。
2.2.1 折扣因子
2.2.1.1 作用原理
折扣因子通常以符号γ表示,在强化学习中用来调节近远期影响,即 agent 做决策时考虑多长远,取值范围 (0,1]。γ越大 agent 往前考虑的步数越多,但训练难度也越高;γ越小 agent 越注重眼前利益,训练难度也越小。我们都希望 agent 能 “深谋远虑”,但过高的折扣因子容易导致算法收敛困难。还以小车导航为例,由于只有到达终点时才有奖励,相比而言惩罚项则多很多,在训练初始阶段负反馈远多于正反馈,一个很高的折扣因子(如 0.999)容易使 agent 过分忌惮前方的 “荆棘丛生”,而宁愿待在原地不动;相对而言,一个较低的折扣因子(如 0.9)则使 agent 更加敢于探索环境从而获取抵达终点的成功经验;而一个过低的折扣因子(如 0.4),使得稍远一点的反馈都被淹没了,除非离终点很近,agent 在大多数情况下根本看不到 “光明的未来”,更谈不上为了抵达终点而努力了。
2.2.1.2 选取方法
总之,折扣因子的取值原则是,在算法能够收敛的前提下尽可能大。在实践中,有个经验公式 1/(1-γ),可以用来估计 agent 做决策时往前考虑的步数。根据对特定任务的分析,合理选择γ值,避免 “近视” 和“远视”。比如可以根据观察或统计 agent 到达终点所需的步数分布,选择合适的步数使得 agent 在该步数内的探索下有一定概率到达终点(正样本),注意这个概率越高训练难度就越小,然后利用经验公式把该步数换算成γ即可。
2.2.1.3 Frame Skipping
上述折扣因子的选择方法并非无往不利,有时我们会面临这样的窘境:无法设置合理的γ在 “近视” 和“远视”间找到满意折中,常见于 “细粒度” 复杂任务。复杂决定了 agent 需要看得很远才能做出合理决策,而 “细粒度” 指 agent 决策间隔很短以至于一段较长的 episode 只对应较少的 agent 状态变化。仍以小车导航为例,0.1s 的决策间隔显然满足了实时防碰撞的机动性要求,但也大大延长了 episode 长度,即到达终点所需步数。如果 agent 平均需要 1min 才能到达终点,那就要求向前考虑 1min/0.1s=600 步,按照经验公式计算合理的折扣因子γ≈1-1/600=0.998,如此高的折扣因子 + 如此长的 episode,训练难度可想而知。
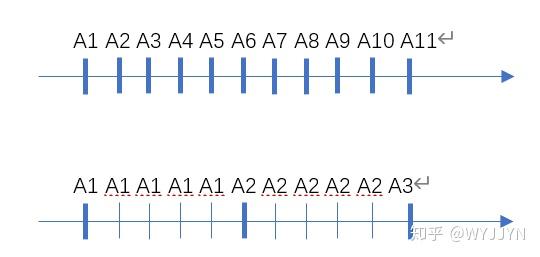
假如我们在保证足够机动性的前提下适当延长决策间隔,比如 0.5s,中间 4 帧重复上一次决策的 action 不变,相当于跳了几帧达到 “快进” 效果,从而使 episode 长度大大缩短,训练难度也直线下降,即使采用较高折扣因子也能顺利收敛。通过这个例子我们也可以知道,在 DRL 中 agent“看得远” 表面上指的是向前考虑的步数多,实质上是指 agent 向前考虑的系统动态演化跨度大。
2.2.2 网络结构
DRL 算法中的网络结构也属于超参数,然而与 CV 任务不同,DRL 绝不应该片面追求网络的复杂化,否则你会发现训练根本无法收敛。对于网络结构的选择,DRL 有自己的规矩——契合状态,够用就好。前者针对网络类型,后者针对网络深度。
2.2.2.1 网络类型
网络类型的选择主要取决于状态空间设计,如果状态信息是向量式的,即一组拉成一维的标量,比如位置、角度、速度等,那就适合采用全连接(MLP)网络;如果状态信息是 imagelike 的,比如图像,或者其他以二维形式重组的信息,就适合采用卷积神经网络(CNN)。实际应用中往往同时包含这两种状态信息,因此网络类型也可以既有 CNN 也有 MLP,处理完各自对应的输入信息后,在高层通过 concat 操作汇集在一起,再通过若干层全连接,最后输出 action 或 Q/V 值。
对于 on-policy 算法,episode 形式的数据天然适合采用 RNN 来挖掘更多时序信息,但同时也会显著提高训练难度,用与不用取决于决策对时序相关性的依赖程度。换句话说,如果之前的经验对当前决策很有参考意义(比如 Dota)就适合用 RNN,反之仅依靠即时信息做应激式决策就足以应付就没必要用 RNN。实践中经常采取折中方案,将最近几个 step 的原始状态信息叠加到一起作为当前时刻的实际状态信息输入 policy,既可以挖掘一定范围内的时序信息,又避免增加训练难度。
2.2.2.2 网络深度
至于网络深度,千万不要认为越深越好,虽然深层网络的表征能力更强,但训练难度非常高,更适合有监督训练。DRL 算法由于数据效率低下又缺乏直接监督信号,并不擅长以 end-to-end 的方式训练过深的网络,如果还同时采用了 RNN 结构,那就是相当不擅长了。除非你有 DeepMind 或 OpenAI 那样的硬件资源,否则还是现实点好。其实多读几篇 DRL 方向的 paper 就会发现,所谓 deep 往往只是 2-3 层 MLP 或 4-5 层 CNN,虚张声势的背后就是这么知趣。
当然,如果任务逻辑和状态信息确实非常复杂,浅层网络不足以提供所需的特征提取和加工能力,那么可以考虑适当加深网络,但仍应以够用为准则,不可矫枉过正。我曾经试过把已经 work 的 3 层 MLP 改成 10 层,发现根本就不收敛或收敛极慢,后来在各层中加了类似 ResNet 的跳线,勉强收敛,但相同训练量下性能还不如 3 层网络。如果输入状态信息是 ImageNet 那样的自然图像,可以像视觉检测应用那样,先用有监督方式预训练一个 backbone,然后再放到 DRL 里 finetune。
2.2.3 学习率
从整个 AI 技术来看,学习率是如此的平淡无奇,相关调参技巧早就被研究透了。毕竟 DRL 算法里的学习率也遵循同样的基本法——大了收敛快,稳定性差,且后期影响性能;小了收敛慢,浪费时间。学习率常用的淬火操作也同样可以应用到 DRL 中。当然,对于不同 DRL 算法而言,学习率也可能有各自的特点,如有必要,我会在下文介绍 DRL 特色超参数的时候顺带多说几句。
2.3 DRL 特色超参数
2.3.1 DQN
DQN 的特色超参数主要有:buffer size,起始训练时间,batchsize,探索时间占比,最终 epsilon,目标网络更新频率等。
Buffer size 指的是 DQN 中用来提高数据效率的 replay buffer 的大小。通常取 1e6,但不绝对。Buffer size 过小显然是不利于训练的,replay buffer 设计的初衷就是为了保证正样本,尤其是稀有正样本能够被多次利用,从而加快模型收敛。对于复杂任务,适当增大 buffer size 往往能带来性能提升。反过来过大的 buffer size 也会产生负面作用,由于标准 DQN 算法是在 buffer 中均匀采集样本用于训练,新旧样本被采集的概率是相等的,如果旧样本或者无效样本在 buffer 中存留时间过长,就会阻碍模型的进一步优化。总之,合理的 buffer size 需要兼顾样本的稳定性和优胜劣汰。顺便说一句,针对 “等概率采样” 的弊端,学术界有人提出了 prioritized replay buffer,通过刻意提高那些 loss 较大的 transition 被选中的概率,从而提升性能,这样又会引入新的超参数,这里就不做介绍了。
起始训练时间的设置仅仅是为了保证 replay buffer 里有足够的数据供二次采样,因此与 batchsize 有直接关系,没啥可说的。Batchsize 指的是从 replay buffer 中二次采样并用于梯度计算的 batch 大小,和 CV 任务中的设定原则基本一致,即兼顾训练稳定性和训练速度,也没啥好说的。
探索时间占比和最终ε共同决定了 DQN 探索和利用的平衡。ε-greedy 策略在训练开始的时候,随机选择 action 的概率ε=1,探索力度最大;随着训练进行ε逐渐线性下降直至达到最终 epsilon 保持恒定,之后 DQN 的训练将以利用为主而只保留少量探索。因此,最终ε取值在区间 [0,1] 内靠近 0 的一端。探索时间占比指的是ε从 1 下降到最终ε的时间占总训练时间的比例,在(0,1)内取值,用来调节以探索为主到以利用为主的过渡。通常来说,复杂任务的探索时间占比应设得大一些,以保证充分的探索;最终ε不宜过大,否则影响模型最终阶段 “好上加好” 的性能冲刺,因为最好的状态往往是在足够好的 Q 网络指导下才能探索到的,训练后期过强的探索干扰了习得知识的利用,也就阻碍了性能的进一步提升。
标准 DQN 引入了一个延迟更新的目标网络用来计算 Q 的目标值,避免 Q 网络误差的 “自激效应”,并借此来提高训练稳定性。目标网络更新频率就是用来控制这个延迟程度的,时间到了就把 Q 网络的参数整个复制过来。通常情况下根据具体问题,参考 Q 网络的更新周期设定,比如 Q 网络每 1 个 step 更新一次,目标 Q 网络可以设定每 500 个 step 更新一次。
2.3.2 DDPG
DDPG 的特色超参数主要包括:buffer size,batchsize,目标网络软更新参数τ,探索噪声等。其中很多超参数与 DQN 类似,比如 buffer size 和 batchsize,这里就不重复介绍了。
DDPG 也使用了目标网络(目标 Q 网络和目标 Policy 网络)稳定训练,不同的是 DDPG 的目标网络与主网络更新频率相同,稳定效果来自于软更新(soft-update),即 (1-τ)target + τmain,τ取很小的值(DDPG paper 中建议 0.001)限制每次更新的幅度。
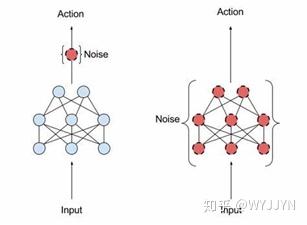
DDPG 值得特别介绍的是探索噪声及其参数。由于 policy 网络输出确定性 action,DDPG 的探索依靠在输出 action 空间叠加噪声来实现。可选的噪声类型主要包括 Gaussian 噪声和 DDPG paper 推荐的 ou 噪声(Ornstein-Uhlenbeck),后者相对于前者主要是增加了噪声强度逐渐衰减的功能。这两种噪声的主要参数是噪声方差,方差越大探索力度越强。虽然论文推荐使用 ou 噪声,但我在实践中发现 ou 噪声并不一定比 Gaussian 噪声效果好,还是要看具体任务。
后来 DeepMind 又提出了 adaptive parameter noise,抛弃了在输出层叠加噪声的方法,转而采用在 policy 网络靠近输出的若干层网络参数上叠加噪声,优点是探索更充分,毕竟参数噪声的影响范围更大,而且可以根据实际情况自适应调节探索力度。类似地,我发现参数噪声在有些任务上效果不错,但在另一些任务中不如传统噪声。综上所述,关于不同噪声的优劣没有确定性结论(局限于我的个人经验),具体选择哪种噪声,还要实际试过才知道。
此外,值得一提的是 Q 网络和 policy 网络采用了不同的学习率,且一般 Q 网络的学习率比 policy 网络大一个数量级,比如前者用 1e-3,后者用 1e-4。这样做的原因是,用于更新 policy 网络的梯度完全来自于 Q 网络,两者地位不是对等的。
2.3.3 PPO
作为 on-policy 方法,PPO 与前两种 DRL 框架有很大不同,无论是算法原理还是超参数设置。PPO 的特色超参数包括:采样环境数量,episode 长度,entropy 系数,V 网络系数,GAE factor,PPO cliprange 等。
并行采样的环境数量越多,整体的探索效率越高,绝对收敛时间越快,该参数的设置主要取决于可用的硬件资源。
PPO 的训练基于 episode(或 trajectory),将其中每个中间 state 到 episode 结束时的 Return 作为目标值拟合一个 V 网络,并用 V 网络作为 baseline 指导 policy 网络的更新。为了便于训练,通常每个环境都采集固定长度的 episode 并返回主进程中拼成一个 batch。Episode 越长,每次计算梯度时的数据量越大,但消耗内存也越多。Episode 长度通常取 4096, 2048, 1024 等 2 的次幂,原因是更新网络参数时整个 batch 还会再分成 minibatch(2 的次幂比较好分),遍历若干个 epoch,从而提高数据利用率,注意 minibatch 不能太大,否则有可能导致 “学不动” 的现象。在实际应用中,除了考虑内存开销,episode 长度选取也跟任务难度息息相关。以小车导航为例,训练刚开始时 agent 可能需要探索很久才能幸运地抵达终点,episode 长度最好能囊括整个探索过程,这样中间状态与理想状态(到终点)间的演进关系就很容易学习到。当然,episode 不可能无限长,如果探索难度实在太高,那也只好提前终止探索,把截断的部分放到下一个 episode 中。
PPO 算法的 loss 由三部分组成:policy loss,value loss 和 entropy loss。其中 entropy loss 项的系数是一个非常重要的超参数,对收敛速度和最终性能有直接影响。我在算法选择篇介绍 PPO 的探索 - 利用平衡时,说过随着训练进行 policy 输出的 action 分布的 variance 会越来越小,反映到统计指标上就是 entropy 越来越小。这本来是一个自然发生的过程,不需要人的干预,然而 DRL 训练早期往往受到各种 local minima 的干扰,容易陷入 “拣了芝麻丢了西瓜” 的怪圈。为了避免模型过早迷失方向,PPO 加入了 entropy loss 用于强迫 policy 输出不那么 “尖锐” 的 action 分布,从而起到加强探索的效果。Entropy 系数负责调节这种 “强迫” 力度,合理的系数既能确保训练早期充分探索从而使模型向正确方向前进,又能使模型在训练中后期充分利用学到的技能从而获得高性能。对于不同任务,最优 entropy 系数往往各不相同,需要若干次试错才能找到。比如在训练开始后 policy entropy 快速下降说明模型陷入了局部最优,根本没学到有用技能,这时就应该提升 entropy 系数;如果训练很长时间 policy entropy 仍然未下降或者下降缓慢,说明模型探索过头了,学到的知识被随机性淹没,无法进一步用来提升性能,此时应该适当降低 entropy 系数。
V 网络系数是 PPO loss 中 value loss 项的系数,通常取 0.5(policy loss 系数默认是 1),在实践中不太需要修改。
由于 on-policy 算法对数据的使用方式是 “现采现用,用完就扔”。为了防止 policy 跑偏,在错误道路上越走越远,需要通过特定方法限制其每次参数更新的幅度。PPO 与更早的 TRPO 类似,核心思想都是针对更新前后 policy 输出的 KL 散度设定阈值,但 PPO 通过一个简单的 clip 操作大大简化了运算,兼顾了效率和性能。PPO 相关的参数主要是 cliprange,通常取略大于 0 的小数,代表使 policy 更新前后 KL 散度控制在 1-cliprange 到 1+cliprange 之间,超出该范围的梯度直接被忽略(相当于对应数据被弃用)。Cliprange 越小训练越稳定,越大越节省数据。一般在训练早期取较小的值,比如 0.2,保证训练平稳进行;到训练后期可以适当放大,因为此时 policy 已经足够优秀,所采集数据中正样本比例非常高,可以放心利用。此外,PPO 使用了 GAE 来估计 advantage,相应增加了一个超参数 GAE factor,用于在 bias 和 variable 之间寻求平衡,也是在 (0,1] 内取值,一般都默认取 0.95。
2.4 给 DRL 初学者的建议
以热门平台作为切入点。热门平台维护频率高,关注度高,遇到问题容易找到解决方案。比如在 OpenAI Gym 平台上找些简单的任务多练手,baselines 里提供了大量参考代码。使用现成代码训练的最大好处是可以排除 bug 的干扰,把注意力都放在调参上,这对于初学者非常重要。
**不要迷信默认超参数。**在实际应用中可以先采用参考代码里的默认超参数,但一定要记住它们不是万能的。可以用 tensorboard 显示出各种训练曲线,理解其中主要曲线的含义和作用,并根据这些曲线判断超参数设置是否合理,应该朝哪个方向调整。
重视首次成功经验,学会简化问题。实践多了你会发现,对于特定 Domain 和特定算法,最优超参数组合分布都各有特点,最困难也最关键的是首次训练,一旦有了成功经验,后续根据观察结果做些微调就能得到高性能模型了。如果原任务训练难度太高,可以先尝试做适当简化,待成功收敛后再逐渐恢复任务难度。比如要实现任务目标 A,必须满足条件 B,C,D…,可以先暂时去掉对 C,D,… 的要求,只保留 B,这样探索到 A 的概率就会显著提升,算法训练难度直线下降,待算法收敛并获得一定的经验后再逐步恢复所有条件。
**保持耐心。**DRL 训练本来就挺慢的,很多时候除了等待什么都不用做。除非你对相关 Domain 的算法训练流程已经很熟悉,否则不要轻易断定算法不收敛,可以等等再说。也不要整天一动不动地盯着屏幕发呆,既浪费时间,更浪费生命,间歇式检查一下就好。
3. 训练收敛后
当你发现 policy 已经可以如预期的那样完成任务了,先不要忙着喜形于色,你还需要做些检查和分析工作以确保 policy 性能达到了最优。以 A3C 为例,你至少应该:
3.1. 观察 Value 网络对 Returns 拟合的精度如何,value loss 是否还有进一步下降的空间?
Value 网络越精确,由其计算得到的 advantage 越有意义,也就越有利于 policy 的优化。注意精度和 loss 都是相对概念,与 reward 函数中各项的绝对值息息相关。一般说来,在 DRL 中对 reward 进行等比例缩放不会改变 policy 的最终特性,即 (+10,-2,-1,-0.5) 与(+100,-20,-10,-5)的作用是一样的,但体现在 value loss 上就差了 10 倍。对拟合精度更可靠的评估标准是 explained variance,计算公式是 1 − V a r ( r e t u r n − v a l u e ) / V a r ( r e t u r n ) 1-Var(return-value)/Var(return) 1−Var(return−value)/Var(return) ,取值区间 ( − ∞ , 1 ] (-∞,1] (−∞,1](-∞,1] ,该值越接近 1 说明拟合精度越高。建议训练过程中将该值实时打印到 tensorboard 中,并不断监测 Value 网络的质量。
3.2. 观察 entropy 是否处在合理范围内,相对于 action 维度是否过高或过低?
假如 policy 输出 10 维 categorical 分布,其 entropy 有两种极端情况:(1) 完全随机,每个维度概率均为 0.1,此时 entropy 最大等于 10*[-0.1*log(0.1)]=2.3;(2) 完全确定,其中一维为 1.0 其余都是 0.0,此时 entropy 最小等于 0。整个训练过程,entropy 从 2.3 开始逐渐下降,当训练收敛后,entropy 应该稳定在较低水平。如果太高则说明 policy 对决策信心不足,如果不是任务本身太复杂那就是 entropy 系数过大造成的,应该适当降低该系数增加 exploitation 的力度,很有可能继续提升模型性能。当然,entropy 很少能降到 0,除非是极其简单的任务。
4. 总结
经过前后近一个月零零星星的整理,这篇又臭又长的训练篇终于快要结束了,连我自己都觉得枯燥透顶,如果有哪位读者能坚持读到这里,我敬你是个勇士!我也时常怀疑写这些东西到底有没有意义,毕竟包括 DRL 在内的深度学习调参技巧往往琐碎而不成体系,很难总结得面面俱到,更何况新算法还在源源不断地涌现,旧的知识经验正在迅速 “贬值”,就像现在有了 Soft Actor-Critic,谁还用 DDPG 啊。最重要的是,假如读者不经过亲身实践,直接看这些干巴巴的总结,作用真心不大。
事实上,当你通过广泛阅读和动手实践,对各种 DRL 算法原理有了深入理解,对各种超参数的作用了然于胸,自然而然就会形成自己的调参方法论。只要算法收敛,性能达标,项目验收,调参的细节没那么重要。此外,调参工作毕竟只停留在 “术” 的层面,而我们应该追求的是算法之“道”,孰轻孰重每个人都要心里有数。祝愿每一个算法工程师最终都能做到“调尽千参,心中无参”。














 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









