










2022年6月3日22:07:35
[地址]: https://www.geetest.com/demo/slide-popup.html
如下是返混淆的js
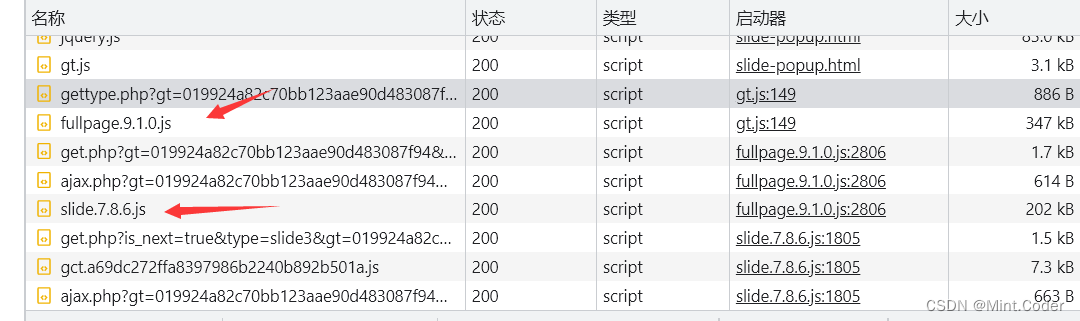
以9.10为例子
返混淆前 6771行代码
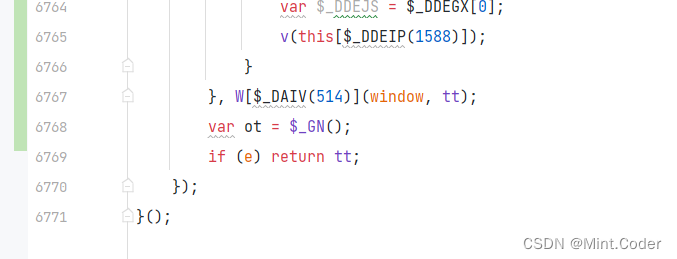
反混淆后
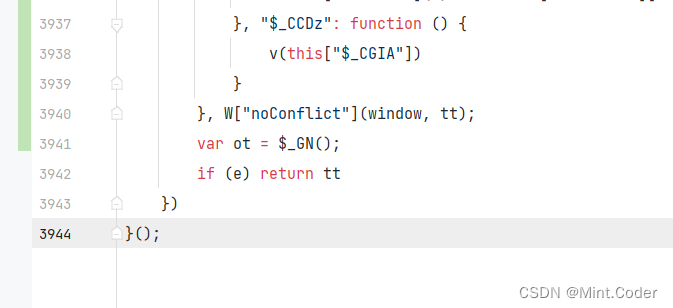
返混淆流程大概就这样:(好像不能直接贴代码,不然过不了)
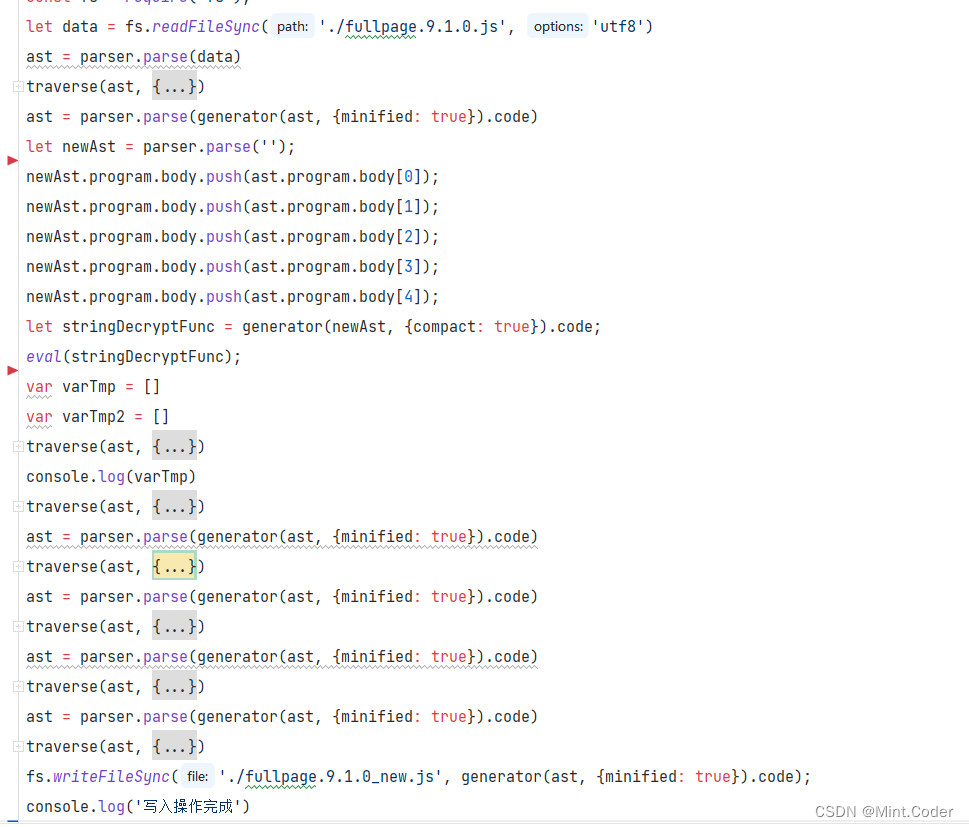
剩下的流程大概就是找加密位置,扣代码咯。
w1:
 w2:
w2:

长度和浏览器计算的一样,就是请求的时候需要模拟鼠标点击,和点击时间,这应该就是所谓的风控,一些浏览器的值也加入了计算,如果指纹少了,node和浏览器计算的长度不一样。
w3:
自己摸索。算法一样。网上挺多的。
首先是图片还原:
还原前图片
 还原后的图片
还原后的图片

图片还原代码javascript版本:
const {createCanvas, loadImage} = require('canvas')
const webp = require("webp-converter");
const fs = require('fs');
function bg_image_path(input_path, out_path, bg_path) {
const webp = require('webp-converter');
const result = webp.dwebp(input_path, out_path, "-o", logging = "-v");
result.then((response) => {
const canvas1 = createCanvas(312, 160)
const canvas2 = createCanvas(260, 160)
const o = canvas1.getContext('2d')
const s = canvas2.getContext('2d')
loadImage(out_path).then(image => {
o.drawImage(image, 0, 0)
let Ut = [
39, 38, 48, 49, 41, 40, 46, 47, 35, 34, 50, 51, 33, 32, 28, 29,
27, 26, 36, 37, 31, 30, 44, 45, 43, 42, 12, 13, 23, 22, 14, 15, 21, 20, 8,
9, 25, 24, 6, 7, 3, 2, 0, 1, 11, 10, 4, 5, 19, 18, 16, 17
]
for (var a = 80, _ = 0; _ < 52; _ += 1) {
var c = Ut[_] % 26 * 12 + 1, u = 25 < Ut[_] ? a : 0, l = o.getImageData(c, u, 10, a);
s.putImageData(l, _ % 26 * 10, 25 < _ ? a : 0)
}
const buffer = canvas2.toBuffer('image/png')
fs.writeFileSync(bg_path, buffer)
})
});
return bg_path
}
bg_image_path('./bg.webp', './bg.jpg', './bg.png')
图片还原python版本(这是网上的)
# -*- coding: utf-8 -*-
# @Time : 2022/5/21 18:20
# @Author : Mint..lv
# @Site :
# @File : imgCover.py
# @Software: PyCharm
# -*- coding: utf-8 -*-
import io
from pathlib import Path
from PIL import Image
def parse_bg_captcha(img, im_show=False, save_path=None):
"""
"""
if isinstance(img, (str, Path)):
_img = Image.open(img)
elif isinstance(img, bytes):
_img = Image.open(io.BytesIO(img))
else:
raise ValueError(f'输入图片类型错误, 必须是<type str>/<type Path>/<type bytes>: {type(img)}')
# 图片还原顺序, 定值
_Ge = [39, 38, 48, 49, 41, 40, 46, 47, 35, 34, 50, 51, 33, 32, 28, 29, 27, 26, 36, 37, 31, 30, 44, 45, 43,
42, 12, 13, 23, 22, 14, 15, 21, 20, 8, 9, 25, 24, 6, 7, 3, 2, 0, 1, 11, 10, 4, 5, 19, 18, 16, 17]
w_sep, h_sep = 10, 80
# 还原后的背景图
new_img = Image.new('RGB', (260, 160))
for idx in range(len(_Ge)):
x = _Ge[idx] % 26 * 12 + 1
y = h_sep if _Ge[idx] > 25 else 0
# 从背景图中裁剪出对应位置的小块
img_cut = _img.crop((x, y, x + w_sep, y + h_sep))
# 将小块拼接到新图中
new_x = idx % 26 * 10
new_y = h_sep if idx > 25 else 0
new_img.paste(img_cut, (new_x, new_y))
if im_show:
new_img.show()
if save_path is not None:
save_path = Path(save_path).resolve().__str__()
new_img.save(save_path)
return new_img
if __name__ == '__main__':
parse_bg_captcha("./test.webp", im_show=True, save_path='bg.jpg')
使用cv2 识别一下缺口:
# -*- coding: utf-8 -*-
# @Time : 2022/5/21 23:33
# @Author : Mint..lv
# @Site :
# @File : identify_gap.py
# @Software: PyCharm
import cv2
def identify_gap(bg, tp, out):
"""
:param bg: 背景图片
:param tp: 缺口图片
:param out: 输出图片
:return:
"""
# 读取背景图片和缺口图片
bg_img = cv2.imread(bg) # 背景图片
tp_img = cv2.imread(tp) # 缺口图片
# 识别图片边缘
bg_edge = cv2.Canny(bg_img, 100, 200)
tp_edge = cv2.Canny(tp_img, 100, 200)
# 转换图片格式
bg_pic = cv2.cvtColor(bg_edge, cv2.COLOR_GRAY2RGB)
tp_pic = cv2.cvtColor(tp_edge, cv2.COLOR_GRAY2RGB)
# 缺口匹配
res = cv2.matchTemplate(bg_pic, tp_pic, cv2.TM_CCOEFF_NORMED)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) # 寻找最优匹配
# 绘制方框
th, tw = tp_pic.shape[:2]
tl = max_loc # 左上角点的坐标
br = (tl[0] + tw, tl[1] + th) # 右下角点的坐标
cv2.rectangle(bg_img, tl, br, (0, 0, 255), 2) # 绘制矩形
cv2.imwrite(out, bg_img) # 保存在本地
# 返回缺口的X坐标
return tl, br
if __name__ == '__main__':
print(identify_gap('./origin.jpg', './key.png', './result.jpg'))
结果:

以上仅为初次实战ast反混淆的记录,仅为个人观点。

















 5108
5108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









