







查询改写概念
数据库中的查询改写(query rewrite)把一个 SQL 改写成另外一个更加容易优化的SQL。
1.基于规则的查询改写总是会把SQL往“好”的方向进行改写,从而增加该SQL的优化空间
2.基于规则的查询改写并不能总是把 SQL 往“好”的方向进行改写,所以 需要代价模型来判断
3.基于代价的改写之后可能又会重新触发基于规则的改写,所以整体上采用 迭代式的方式进行改写

基于规则的查询改写
基于规则的查询改写方式主要包括:
子查询相关改写
视图合并、子查询展开、ANY/ALL 使用 MAX/MIN 改写
外联接消除
简化条件改写
HAVING 条件消除、等价关系推导、恒真/假消除
非SPJ的改写
冗余排序消除、LIMIT 下压、DISTINCT 消除、MIN/MAX 改写

子查询相关改写
子查询改写的方式主要包括视图合并、子查询展开和将 ANY/ALL使用MAX/MIN改写等
优化器对于子查询一般使用嵌套执行的方式,也就是父查询每生成一行数据后,都需要执行一次子查询。使用这种方式需要多次执行子查询,执行效率很低。对于子查询的优化方式,一般会将其改写为联接操作,可大大提高执行效率,主要优点如下:
- 可避免子查询多次执行
- 优化器可根据统计信息选择更优的连接顺序和连接方法
- 子查询的连接条件、过滤条件改写为父查询的条件后,优化器可以进行进一步优化,比如条件下压等
子查询相关改写-视图合并
视图合并是指将代表一个视图的子查询合并到包含该视图的查询中,视图合并后,有助于优化器增加联接顺序的选择、访问路径的选择以及进一步做其他改写操作,从而选择更优的执行计划。
创建相关测试表 SQL_A 不进行改写,可选连接顺序有:
•t1, v(t2,t3)
•t1, v(t3,t2)
•v(t2,t3), t1
•v(t3,t2), t1
视图合并改写SQL_B后,可选连接顺序有:
•t1, t2, t3
•t1, t3, t2
•t2, t1, t3
•t2, t3, t1
•t3, t1, t2
•t3, t2, t1
子查询展开:子查询展开为semi-join/anti-join
子查询展开是指将 where 条件中子查询提升到父查询中,并作为连接条件与父
查询并列进行展开。 一般涉及的子查询表达式有 not in、in、not exist、exist、any、all。
两表结构:
t1 (c1 INT, c2 INT)t2 (c1 INT PRIMARY KEY, c2 INT)其中t2.c2 不具有唯一性,改为 semi join,改写后执行计划如下所示

子查询展开的方式如下:
改写条件使生成的联接语句能够返回与原始语句相同的行
展开为半联接(SEMI JOIN / ANTI JOIN)
子查询展开:子查询展开为内连接
子查询展开是指将 where 条件中子查询提升到父查询中,并作为连接条件与父查询并列进行展开。 一般涉及的子查询 表达式有 not in、in、not exist、exist、any、all。

外连接消除
外联接操作可分为左外联接、右外联接和全外联接。在联接过程中,由于外联接左右顺序不能变换,优化器对联接顺序的选择会受到限制。
外连接消除是指将外连接转换成内连接,从而可以提供更多可选择的连接路径,供优化器考虑。外连接消除需要存在 “空值拒绝条件”,即 where 条件中,存在当内表生成的值为 null 时,使得输出为 false 的条件。
SELECT t1.c1, t2.c2 FROM t1 LEFT JOIN t2 ON t1.c2 = t2.c2;

SELECT t1.c1, t2.c2 FROM t1 LEFT JOIN t2 ON t1.c2 = t2.c2 WHERE t2.c2 > 5;SELECT t1.c1, t2.c2 FROM t1 INNER JOIN t2 ON t1.c2 = t2.c2
WHERE t2.c2 > 5;
基于代价的查询改写
OceanBase目前只一种支持基于代价的查询改写 - 或展开(Or-Expansion)
或展开(Or-Expansion):把一个查询改写成若干个用union all组成的子查询,这个改写可能会给每个子查询提供更优的优化空间,但是也会导致多个子查询的执行,所以这个改写需要基于代价去判断
通常来说,Or-Expansion的改写主要有如下三个作用:
- 允许每个分支使用不同的索引来加速查询
- 允许每个分支使用不同的连接算法来加速查询,避免使用笛卡尔连接
- 允许每个分支分别消除排序,更加快速的获取top-k结果
允许每个分支使用不同的索引来加速查询

如上图所示 :查询 SQL_A会被改写成SQL_B 的形式,其中SQL_B中的谓 词LNNVL(t1.a = 1)保证了这两个子查询不会生成重复的结果
如果不进行改写,SQL_A一般来说会选择主表作为访问路径,对于SQL_B 来说,如果t1表上存在索引(a)和索引(b),那么该改写可能会让SQL_B中的每一个子查询选择索引作为访问路径。
允许每个分支使用不同的索引来加速查询
如果不进行OR-EXPANSION的改写,该查询只能使用主表访问路径,执行计划如下:

允许每个分支使用不同的联接算法来加速查询
被改写之后,每个子查询都使用了Hash Join,执行计划如下:
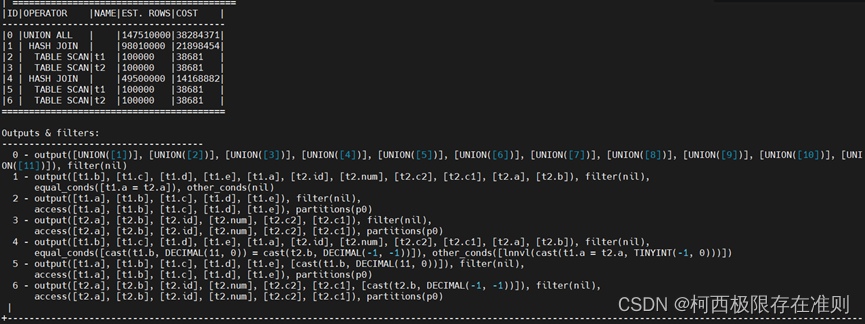
允许每个分支分别消除排序
CREATE TABLE t1(a INT, b INT, INDEX IDX_a(a, b));SQL_A:
SELECT * FROM t1
WHERE t1.a = 1 OR t1.a = 2
ORDER BY b LIMIT 10;SQL_B:
SELECT * FROM
(SELECT * FROM t1
WHERE t1.a = 1
ORDER BY b LIMIT 10
UNION ALL
SELECT * FROM t1
WHERE t1.a = 2
ORDER BY b LIMIT 10
) AS TEMP
ORDER BY temp.b LIMIT 10;
如上图所示,查询SQL_A会被改写成SQL_B
对于SQL_A来说,执行方式是只能把满足条件的行数找出来,然后进行排序,最终取TOP-10结果
对于SQL_B来说,如果存在索引(a,b), 那么SQL_B中的两个子查询都可以使用索引把排序消除,每个子查询取TOP-10结果,然后最终对这20行数据排序一次获取最终的TOP-10行。
因此每个分支分别消除排序,可以更加快速的获取TOP-K结果。
允许每个分支分别消除排序
不改写的话,需要排序最终获取TOP-K结果,执行计划如下:
EXPLAIN SELECT/*+NO_REWRITE()*/*FROM t1 WHERE t1.a = 1 OR t1.a = 2
ORDER BY b LIMIT 10;
允许每个分支分别消除排序
进行改写的话,排序算子可以被消除,最终获取 TOP-K 结果,执行计划如下:
EXPLAIN SELECT * FROM t1 WHERE t1.a = 1 OR t1.a = 2 ORDER BY b LIMIT 10;
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











