







目录
1 HDFS参数调优概述
HDFS作为Hadoop生态系统的核心存储组件,其性能表现直接影响整个大数据平台的效率。在众多可调优参数中, dfs.replication(副本数)和 dfs.blocksize(块大小)是两个最基础也最关键的配置项。本文将深入探讨这两个参数对HDFS吞吐量的影响机制。
2 副本数(dfs.replication)调优
2.1 副本数对系统的影响
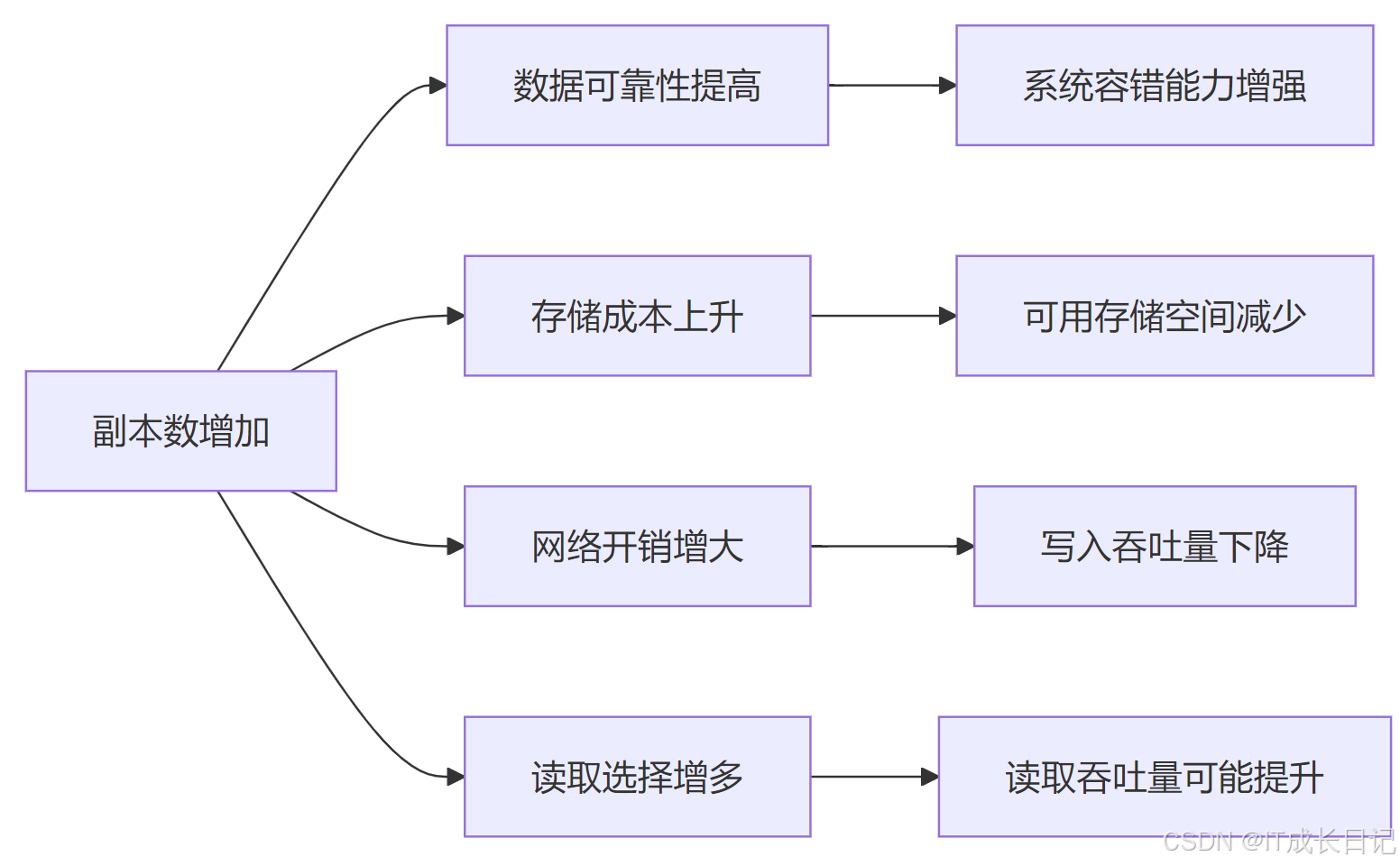
- 影响机制分析
正向影响:
- 数据可靠性随副本数增加呈指数级提升
- 读取操作可选择最近的副本,降低延迟
- 多副本为计算本地性提供更多可能
负面影响:
- 存储空间占用线性增长(副本数×原始数据量)
- 写入时需要跨节点传输更多数据副本
- 集群网络带宽压力显著增加
2.2 副本数设置建议
- 通用场景
<!-- hdfs-site.xml -->
<property>
<name>dfs.replication</name>
<value>3</value> <!-- 生产环境默认建议值 -->
</property>- 特殊场景调整
- 冷数据:可降为2副本+EC编码
- 热数据:可增至4-5副本提升读取性能
- 开发环境:可设为1副本节省资源
- 动态调整策略
# 修改已有文件的副本数
hdfs dfs -setrep -w 4 /user/data/file
# 查看当前副本分布
hdfs fsck / -files -blocks -locations3 块大小(dfs.blocksize)调优
3.1 块大小影响机制
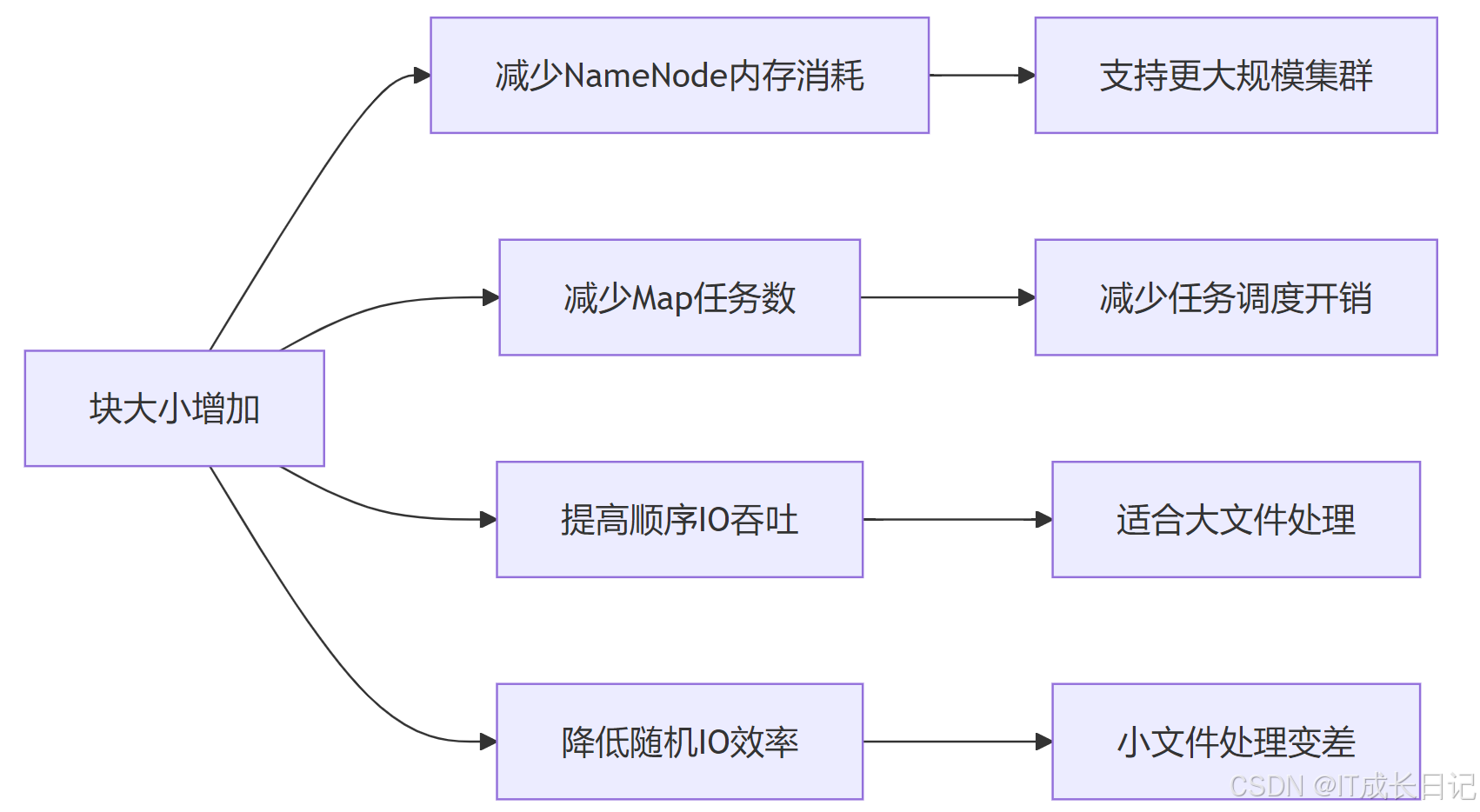
- 关键影响维度
- NameNode内存:每个块约占用150字节内存,块越大,总块数越少
- MapReduce性能:每个块通常对应一个Map任务,影响并行度
- I/O特性:大块适合顺序读写,小块适合随机访问
- 网络传输:大块减少网络连接数,但增加单次传输数据量
3.2 块大小与吞吐量关系
- 随着块增大,吞吐量先上升后略有下降
- 最佳平衡点通常在256-512MB之间
- 过大块导致数据局部性下降,反而降低吞吐
3.3 块大小设置策略
- 默认配置
<property>
<name>dfs.blocksize</name>
<value>268435456</value> <!-- 256MB -->
</property>- 按场景优化
- 海量小文件:64-128MB(减少存储浪费)
- 大文件处理:512MB-1GB(如视频、基因数据)
- 机器学习:128-256MB(平衡并行度和IO效率)
- 文件级覆盖设置
// 在写入代码中指定
FileSystem fs = FileSystem.get(conf);
FSDataOutputStream out = fs.create(path, true, bufferSize,
replication, blockSize, progress);4 参数组合调优实战
4.1 参数交互影响模型
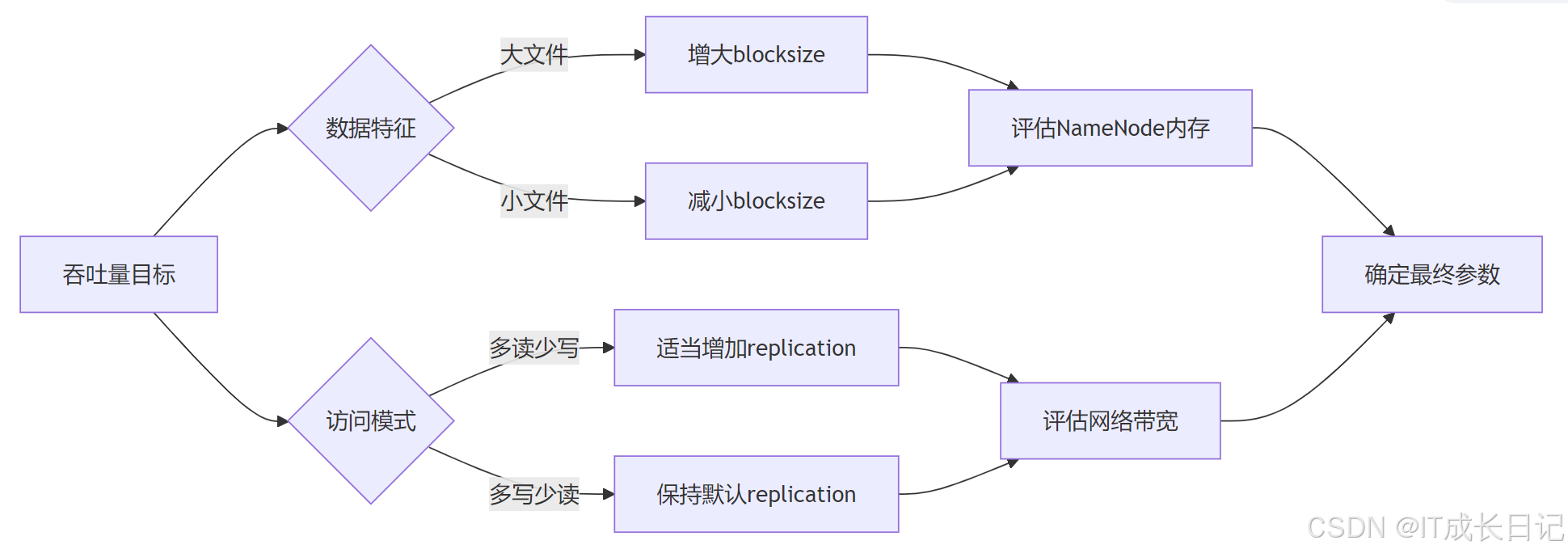
调优决策流程:
- 首先明确吞吐量优化目标(读/写/平衡)
- 分析数据特征(大小、类型、数量)
- 评估集群资源(内存、网络、磁盘)
- 构建参数组合矩阵进行测试
- 选择最优配置并监控调整
4.2 典型场景参数推荐
| 场景类型 | 块大小 | 副本数 | 预期吞吐增益 |
| 日志分析 | 256MB | 2 | 15-20% |
| 数据仓库 | 512MB | 3 | 25-30% |
| 实时流处理 | 128MB | 3 | 10-15% |
| 机器学习训练 | 256MB | 2 | 20-25% |
| 视频存储 | 1GB | 2+EC | 30-40% |
4.3 调优实施步骤
- 基准测试
# 测试写入性能
hadoop jar hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO \
-write -nrFiles 10 -fileSize 1GB
# 测试读取性能
hadoop jar hadoop-mapclient-jobclient-tests.jar TestDFSIO \
-read -nrFiles 10 -fileSize 1GB- 参数动态调整
# 不重启修改块大小(对新文件生效)
hdfs dfs -D dfs.blocksize=134217728 -put localfile /user/data/path- 监控指标
# 监控关键指标
hdfs dfsadmin -report
hdfs dfs -du -h /
hadoop fsck / -files -blocks -locations5 高级调优技巧
5.1 异构存储策略
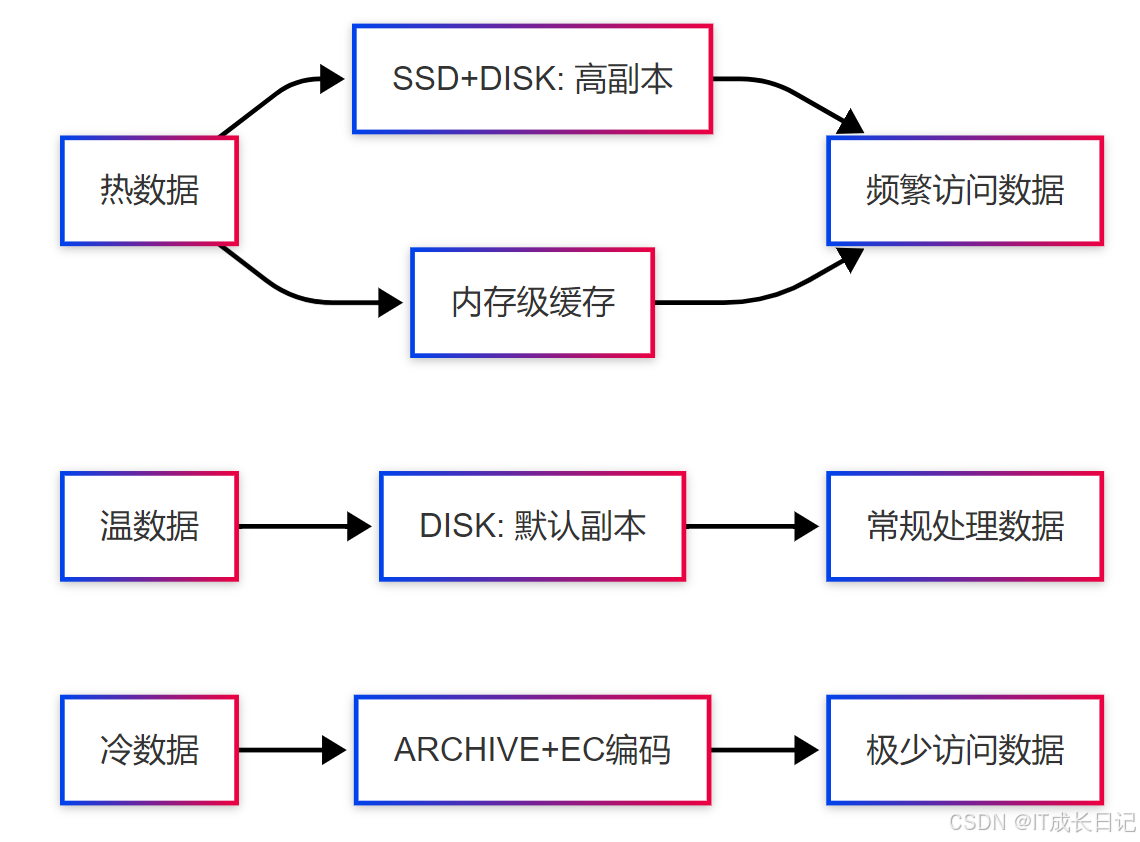
实施配置:
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[SSD]file:///ssd/0,[DISK]file:///disk/0</value>
</property>5.2 纠删码技术应用

- 配置示例
# 设置纠删码策略
hdfs ec -enablePolicy -policy XOR-2-1-64k
hdfs ec -setPolicy -path /cold_data -policy XOR-2-1-64k6 总结与监控建议
通过合理调整 dfs.replication和 dfs.blocksize参数,可以实现HDFS吞吐量的显著提升。在生产环境中:
- 建立参数变更的灰度发布机制
- 实施持续的性能监控:
hdfs dfsadmin -report | grep "Configured Capacity"hadoop fs -count -q /userdata/path
- 定期重新评估参数设置(特别是在数据特征或集群规模变化时)


















 145
145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











