







目录
1 Hive查询处理架构概览
1.1 Hive核心组件体系
Hive的查询执行过程涉及多个协同工作的组件,形成了一套完整的SQL-on-Hadoop解决方案:
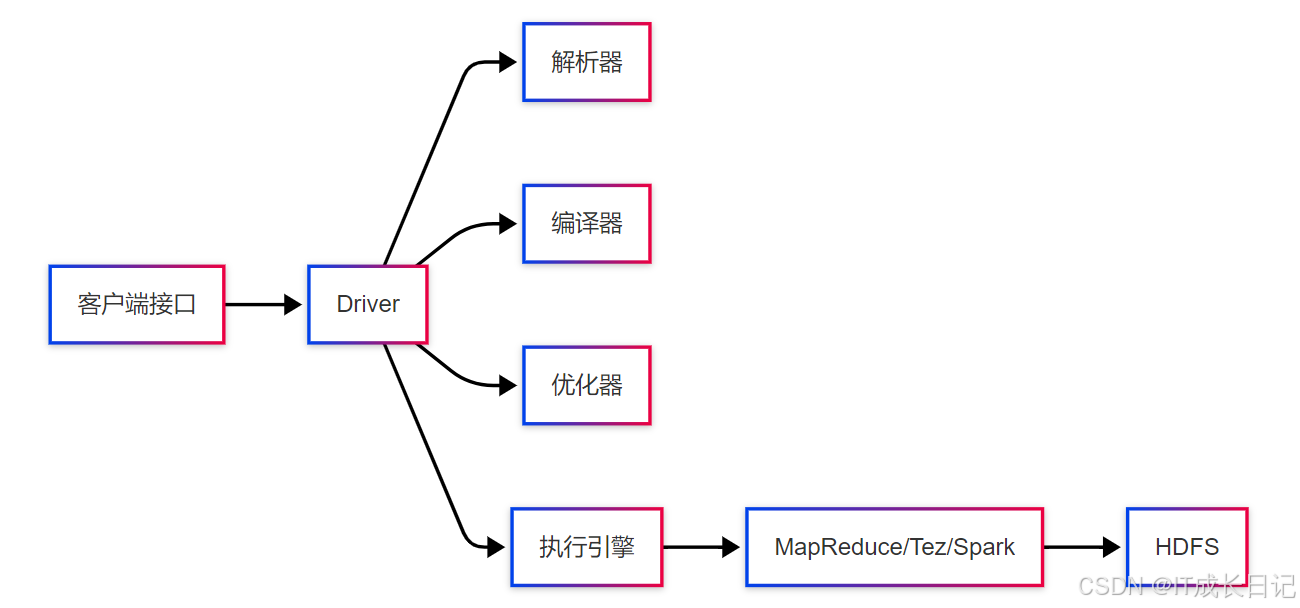
组件职责分解:
- 客户端接口:CLI、JDBC、ODBC等接入方式
- Driver:查询执行的协调者,控制整个生命周期
- 解析器(Parser):SQL文本→抽象语法树(AST)
- 编译器(Compiler):AST→逻辑执行计划→物理执行计划
- 优化器(Optimizer):应用各种优化规则
- 执行引擎(Execution Engine):执行优化后的计划
- 计算框架:MapReduce/Tez/Spark等实际执行引擎
- 存储系统:HDFS、HBase等数据存储位置
1.2 查询执行阶段划分
Hive查询处理可划分为三个主要阶段:
| 阶段 | 输入 | 输出 | 关键操作 |
| 前端处理 | SQL查询字符串 | 逻辑执行计划 | 语法解析、语义分析、逻辑优化 |
| 中间处理 | 逻辑执行计划 | 物理执行计划 | 优化转换、任务生成 |
| 后端执行 | 物理执行计划 | 查询结果 | 任务调度、执行、结果收集 |
2 SQL到MapReduce的转换过程
2.1 语法解析阶段

词法分析:将SQL字符串拆分为token序列
- 识别关键字:SELECT、FROM、WHERE等
- 识别标识符:表名、列名
- 识别常量:字符串、数字
语法分析:根据Hive语法规则构建AST
- 检查SQL语法正确性
- 构建树形结构表示查询逻辑
语义分析:
- 验证表/列是否存在
- 检查数据类型兼容性
- 解析*通配符为具体列
- 函数参数校验
2.2 逻辑计划生成

典型逻辑运算符:
- TableScanOperator:表数据扫描
- SelectOperator:列选择和投影
- FilterOperator:WHERE条件过滤
- GroupByOperator:GROUP BY分组
- JoinOperator:表连接操作
- FileSinkOperator:结果输出
2.3 物理计划生成
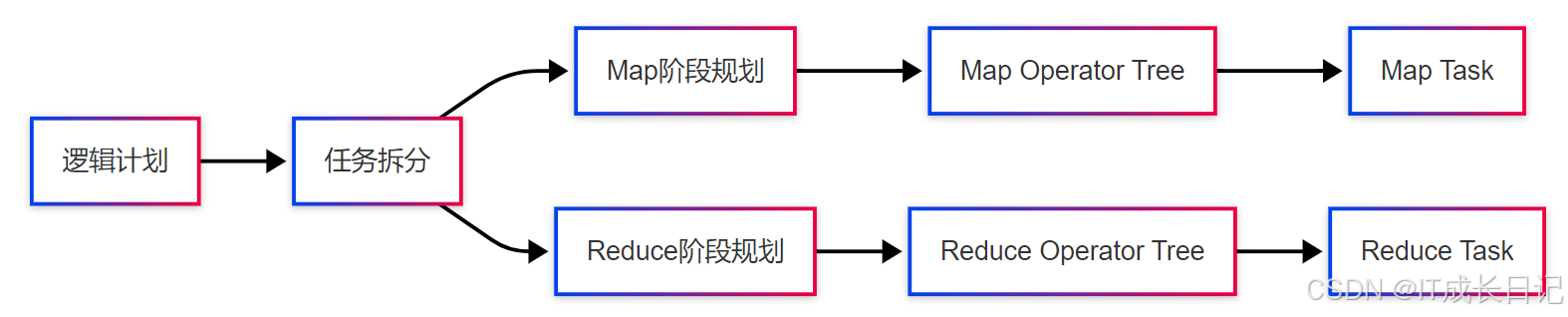
转换规则示例:
- 表扫描 → TableScanOperator → Map输入
- WHERE过滤 → FilterOperator → Map阶段
- GROUP BY聚合 → GroupByOperator → Reduce阶段
- 表连接 → JoinOperator → 根据连接策略分配
Join实现策略:
- Common Join:标准Reduce端连接
- Map Join:小表广播连接
- SMB Join:排序合并桶连接
- Skew Join:倾斜数据优化连接
3 执行引擎工作流程
3.1 MapReduce执行模型

Map阶段:
- 输入分片(InputSplit)处理
- 执行MapOperator树
- 输出键值对收集
Shuffle阶段:
- Map端排序和合并(combine)
- 分区数据网络传输
- Reduce端数据归并
Reduce阶段:
- 执行ReduceOperator树
- 最终结果输出
3.2 运算符执行细节
- Map任务处理流程:

- Reduce任务处理流程:

TableScanOperator:
- 调用InputFormat获取数据
- 使用RecordReader逐行读取
- 转换为内部行格式
FilterOperator:
- 应用WHERE条件表达式
- 实现谓词下推优化
- 行级别过滤
GroupByOperator:
- Map阶段:部分聚合(哈希聚合)
- Reduce阶段:最终聚合
- 处理聚合函数(COUNT,SUM等)
4 查询优化机制详解
4.1 逻辑优化规则

- 常用优化规则:
| 优化类型 | 优化规则 | 效果描述 |
| 投影裁剪 | ColumnPruner | 消除不需要的列减少数据量 |
| 谓词下推 | PredicatePushDown | 尽早过滤减少后续处理数据 |
| 分区裁剪 | PartitionPruner | 只扫描相关分区数据 |
| 连接重排序 | JoinReorder | 优化多表连接顺序 |
| 子查询处理 | SubqueryProcessing | 转换子查询为连接或半连接 |
| 常量折叠 | ConstantPropagate | 预先计算常量表达式 |
4.2 物理优化策略
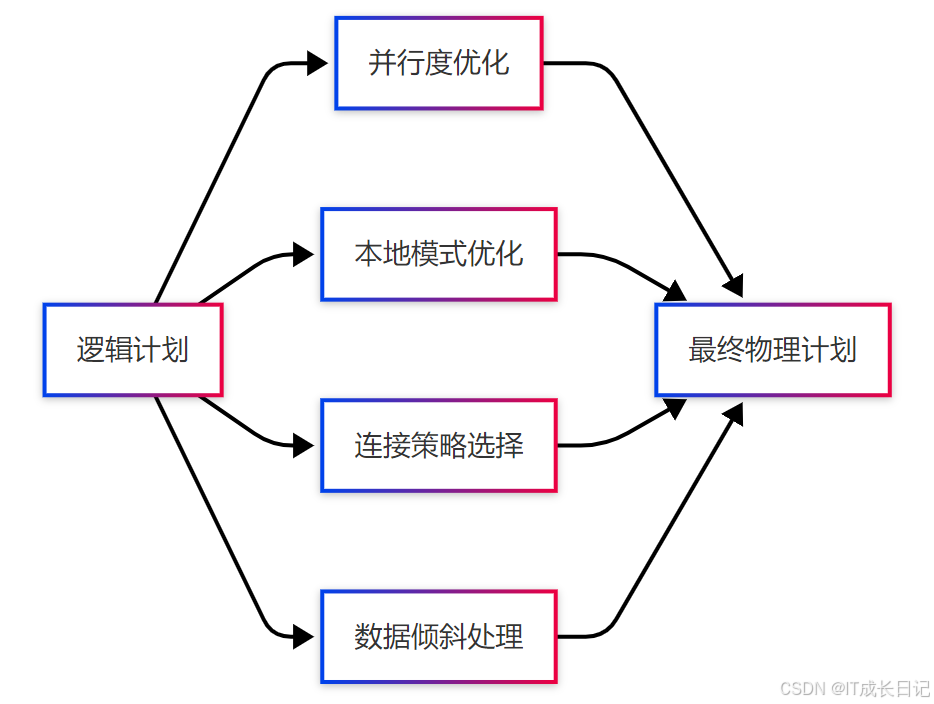
关键优化技术:
- MapJoin优化:
-- 自动转换判断条件
SET hive.auto.convert.join=true;
SET hive.auto.convert.join.noconditionaltask=true;
SET hive.auto.convert.join.noconditionaltask.size=10000000;- 并行执行优化:
-- 设置Reduce任务数
SET mapreduce.job.reduces=10;
-- 启用阶段并行
SET hive.exec.parallel=true;
SET hive.exec.parallel.thread.number=8;- 倾斜数据优化:
-- 分组聚合倾斜处理
SET hive.groupby.skewindata=true;
-- 连接倾斜处理
SET hive.optimize.skewjoin=true;
SET hive.skewjoin.key=100000;4.3 基于成本的优化
- CBO(Cost-Based Optimization)架构:
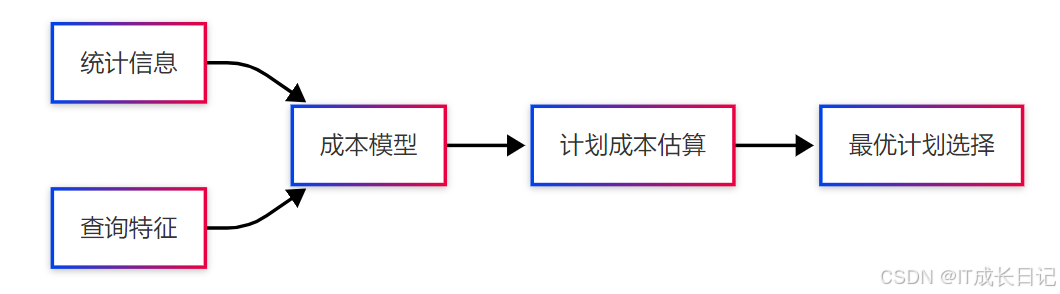
- 统计信息收集:
-- 分析表统计信息
ANALYZE TABLE employee COMPUTE STATISTICS;
-- 分析列统计信息
ANALYZE TABLE employee COMPUTE STATISTICS FOR COLUMNS name, salary;
-- 查看统计信息
DESCRIBE FORMATTED employee;- CBO配置参数:
-- 启用CBO
SET hive.cbo.enable=true;
SET hive.compute.query.using.stats=true;
-- 设置成本模型
SET hive.stats.fetch.column.stats=true;
SET hive.stats.fetch.partition.stats=true;5 执行性能监控与调优
5.1 性能监控指标
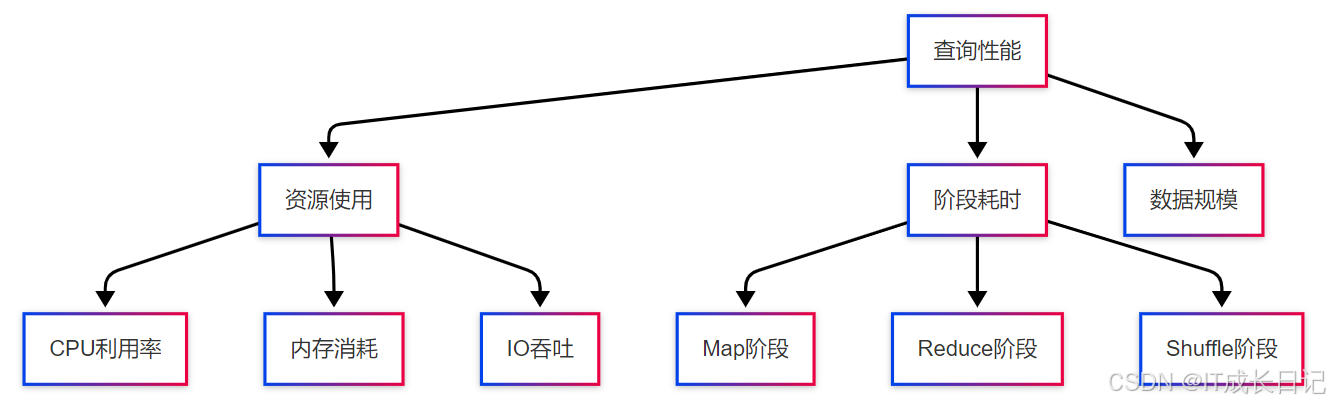
- 监控命令示例:
-- 查看执行计划
EXPLAIN [EXTENDED|DEPENDENCY|AUTHORIZATION] query;
-- 查看任务计数器
SET hive.exec.counters.pull.interval=1000;5.2 常见性能瓶颈
| 瓶颈类型 | 表现特征 | 解决方案 |
| Map倾斜 | 部分Map任务耗时过长 | 调整split大小,增加mapper数 |
| Reduce倾斜 | 部分Reduce任务数据过多 | 优化分组键,增加reducer数 |
| Shuffle瓶颈 | 网络传输成为瓶颈 | 压缩中间数据,调整缓冲区 |
| 存储格式 | 读取效率低下 | 使用ORC/Parquet列式存储 |
| 计算模式 | 单机处理能力不足 | 考虑Tez/Spark引擎 |
5.3 调优参数大全
- 核心调优参数:
-- Map阶段优化
SET mapreduce.task.io.sort.mb=300; -- 排序缓冲区大小(MB)
SET mapreduce.map.memory.mb=2048; -- Map任务内存
SET mapreduce.map.java.opts=-Xmx1800m; -- Map JVM参数
-- Reduce阶段优化
SET mapreduce.reduce.memory.mb=4096; -- Reduce任务内存
SET mapreduce.reduce.java.opts=-Xmx3600m; -- Reduce JVM参数
SET mapreduce.reduce.shuffle.parallelcopies=20; -- 并行拷贝数
-- 执行引擎优化
SET hive.exec.reducers.bytes.per.reducer=256000000; -- 每个Reducer处理数据量
SET hive.exec.dynamic.partition=true; -- 动态分区
SET hive.vectorized.execution.enabled=true; -- 向量化执行6 执行引擎演进与对比
6.1 MapReduce执行引擎
架构特点:
- 批处理模型
- 高可靠性保证
- 适合大规模离线处理
- 中间数据落盘
适用场景:
- 超大规模数据批处理
- 高可靠性要求的场景
- 与Hadoop生态深度集成
6.2 Tez执行引擎
- 优化改进:
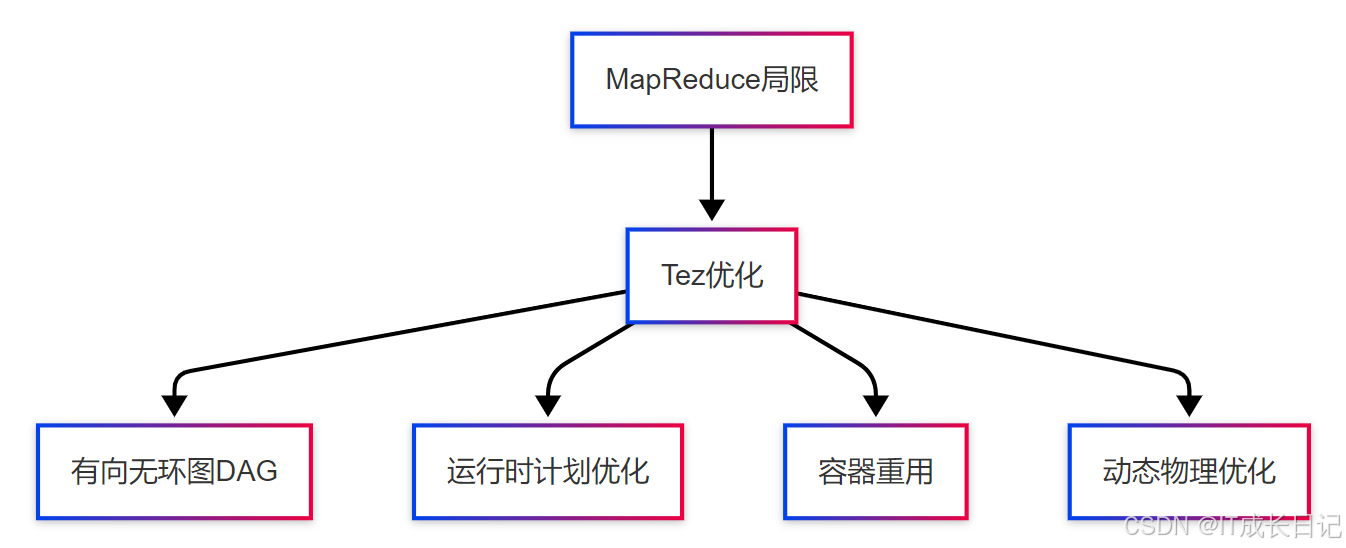
核心优势:
- 减少中间数据落盘
- 更灵活的任务调度
- 更快的查询响应
- 更好的资源利用率
6.3 Spark执行引擎
技术特点:
- 内存计算优先
- 丰富的算子库
- 统一批流处理
- 高级API支持
- 性能对比:
| 指标 | MapReduce | Tez | Spark |
| 延迟 | 高 | 中 | 低 |
| 吞吐量 | 高 | 高 | 非常高 |
| 内存使用 | 低 | 中 | 高 |
| 适用场景 | 离线批处理 | 交互查询 | 实时分析 |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











