







文章目录
一、关系数据库理论
关系数据库的规范化理论
(1)函数依赖——核心,是模式分解和设计的基础
(2)范式 ——模式分解的标准
(3)模式设计
 -----
-----
一个好的关系模式应该具备以下四个条件:
(1)尽可能少的数据冗余;
(2)没有插入异常;
(3)没有删除异常;
(4)没有更新异常。
二、函数依赖
2.1 定义
关系模式中的各属性之间相互依赖、相互制约的联系称为数据依赖。
其中包含函数依赖和多值依赖。
函数依赖(FD,Functional Dependency)是关系模式中属性之间的一种逻辑依赖关系。
函数依赖的定义
设关系模式R(U,F),U是属性全集,F是 U上的函数依赖所构成的集合,X和Y是U的子集,如果对于R(U)的任意一个可能的关系r,对于X的每一个具体值,Y都有唯一的具体值与之对应,则称X决定函数Y, 或Y函数依赖于X,记作X→Y。我们称X为决定因素,Y为依赖因素。当Y不函数依赖于X时,记作:X →Y(→上要加一个左斜杆,打不上去)。当X→Y且Y→X时,则记作:X↔Y。
例子:
U={SNo,SN,Age,Dept,MN,CNo,Score}
F={SNo→SN,SNo→Age,SNo→Dept, (SNo,CNo)→Score}
函数依赖的逻辑蕴涵定义
设F是在关系模式R(U)上成立的函数依赖集合,X,Y是属性集U的子集,X→Y是一个函数依赖。如果从F中能够推导出X→Y,即如果对于R的每个满足F的关系r也满足X→Y,则称X→Y为F的逻辑蕴涵(或F逻辑蕴涵X→Y),记为F|=X→Y 。
闭包(Closure)的定义
设F 是函数依赖集,被F 逻辑蕴涵的函数依赖的全体构成的集合,称为函数依赖集F 的闭包(Closure),记为F +。即:F +={ X→Y | F |=X→Y }
函数依赖的推理规则及正确性
设有关系模式R(U),U是关系模式R 的属性集,F 是R上成立的只涉及U 中属性的函数依赖
集。X,Y,Z,W 均是U 的子集,r 是R 的一个实例。
Armstrong 公理及正确性
A1:自反律(Reflexivity)
如果Y X U,则X→Y在R上成立。即一组属性函数决定它的所有子集。如:(SNo,CNo)→SNo
A2:增广律(Augmentation)
若X→Y在R上成立,且Z U,则XZ→YZ在R上也成立。如: SNo→Age, (Sno,SN)→(Age,SN)
A3:传递律(Transitivity)
若X→Y和Y→Z在R上成立,则X→Z在R上也成立。如: SNo→Dept, Dept→MN,SNo →MN
定理:如果X →Y是从F用Armstrong公理推理导出,那么X →Y在F+中。
Armstrong 公理推论及正确性
合并律(Union rule) 若X→Y和X→Z在R上成立,则X→YZ在R上也成立。
伪传递律(Pseudotransitivity rule) 若X→Y和YW→Z在R上成立,则XW→Z在R上也成立。
分解律(Decomposition rule) 若X→Y和Z Y在R上成立,则X→Z在R上也成立。
函数依赖的推理规则及正确性
定理:如果A1A2…An是关系模式R的属性集,那么X →A1A2…An成立的充分必要条件是X →Ai(i=1,2,…n)成立。
复合律(Composition) 若X→Y和W→Z在R上成立,则XW→YZ在R上也成立
函数依赖推理规则的完备性
正确性:从函数依赖集F使用推理规则推出的函数依赖必定在F+中
完备性:F+中的函数依赖都能从F集使用推理规则集推出
2.2 完全函数依赖于部分函数依赖
完全函数依赖定义:

只有当决定因素是组合属性时,讨论部分函数依赖才有意义;
当决定因素是单属性时,只能是完全函数依赖。
传递函数依赖定义:

2.3 属性集的闭包及其算法
定义:
设有关系模式R(U),U是属性集,F是R上的函数依赖集,X是U的子集(X U),用函数依赖推理规则可从F推出函数依赖X→A中所有A的集合,称为属性集X关于F的闭包,记为X+。
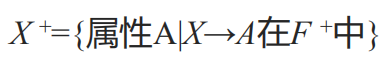
定理:

 -----
----- 
2.4 候选码的求解和算法
候选码的定义:
设关系模式R的属性集是U,X是U的一个子集,F是在R上成立的函数依赖集。
如果X→U在R上成立(即X→U在F+中),那么称X是R的一个超码。
如果X→U在R上成立,但对X的任一真子集X′都有X′→U不成立(即X′→U不在F+中,或者X → U),那么称X是R上的一个候选码。
快速求解候选码的一个充分条件
对于给定的关系模式R(A1…,An)和函数依赖集F,可将其属性分为四类:L类 R类 N类 LR类
定理
(1)若X(X∈R)是L类属性,则X必为R的任一候选码的成员。
(2)若X(X∈R)是L类属性,且X+包含了R的全部属性,则X必为R的唯一候选码
(3)若X(X∈R)是R类属性,则X不在任何候选码中
(4)若X(X∈R)是N类属性,则X必为R的任一候选码的成员。
(5)若X(X∈R)是R的N类和L类属性组成的属性集, (5) 且X+包含了R的全部属性,则X是R的唯一候选码。
(6)若X(X∈R)是LR类属性,则X可能为R的任一候选码的成员,也可能不为R的任一候选码的成员。
多属性函数依赖集候选码的求解算法
设有关系模式R,F是R上的函数依赖集,求R的所有候选码
输入:关系模式R及其函数依赖集F
输出:关系模式R的所有候选码
(1)属性分类(L、R、N和LR),X代表L 类和N类属性,Y代表LR类属性。
(2)若X+包含了R的全部属性,转(5);否则, 转(3)。
(3)在Y中取一个属性A,求(XA)+,若它包含了R的全部属性,则转(4);否则,调换一属性反复进行这一过程,直到试完所有Y中的属性。
(4)如果已找出所有候选码,则转(5);否则在Y中依次取两个属性、三个属性、…,求它们的属性集的闭包,直到其闭包包含R的全部属性。
(5)停止,输出结果。
例:设有关系模式R(A,B,C,D,E)与它的函数依赖集F={A → BC, CD →E, B →D,E →A},求R 的所有候选码。
属性A、B、C、D、E 都是LR类属性
依次取一个属性求解属性集闭包A+=ABCDE,B+=BD,C+=C,D+=D,E+=ABCDE
取出两个属性计算属性集闭包(BC)+=ABCDE,(CD)+=ABCDE,(BD)+=BD
R 的候选码为A、E、BC 和CD
2.5 函数依赖集的等价、覆盖和最小函数依赖集
等价、覆盖
定义:
关系模式R(U)的两个函数依赖集F和G,如果满足F+= G+ ,则称F和G是等价的函数依赖集。作:F≡G。如果F和G等价,就说F覆盖G,或G覆盖F。
依赖集
定义:
设F是属性集U上的函数依赖集,X→Y是F中的函数依赖。函数依赖中无关属性、无关函数依赖的定义如下:
(1)如果A∈X,且F逻辑蕴涵(F-{X→Y}) ∪ {(X-A) →Y},则称属性A是X→Y左部的无关属性。
(2)如果A∈X,且(F-{X→Y}) ∪ {X→(Y-A)}逻辑蕴涵F,则称属性A是X→Y右部的无关属性。
(3)如果X→Y的左右两边的属性都是无关属性,则函数依赖X→Y称为无关函数依赖
定义:
设F是属性集U上的函数依赖集。如果Fmin是F的一个最小函数依赖集,那么Fmin应满足下列四个条件:
(1)Fmin+=F+;
(2)每个函数依赖的右边都是单属性;
(3)Fmin中没有冗余的函数依赖(即在Fmin中不存在这样的函数依赖X→Y,使得Fmin与Fmin-{X→Y}等价),即减少任何一个函数依赖都将与原来的F不等价;
(4)每个函数依赖的左边没有冗余的属性(即Fmin中不存在这样的函数依赖X→Y,X有真子集W使得Fmin- {X→Y} ∪ {W→Y}与Fmin等价),减少任何一个函数依赖左部的属性后,都将与原来的F不等价。
算法——计算函数依赖集F的最小函数依赖集G
(1)对F中的任一函数依赖X→Y,如果Y=Y1,Y2,…,Yk (k≥2)多于一个属性,就用分解律,分解为X→Y1,X→Y2,…,X→Yk,替换X→Y,得到一个与F等价的函数依赖集G,G中每个函数依赖的右边均为单属性。
(2)去掉G中各函数依赖左部多余的属性。即一个一个检查G左边是非单属性的依赖。如,XY→A,现在要判断Y是否为多余的,则以X→A代替XY→A是否等价?只要在G中求X+,若X+包含A,则说明X→A可以代替XY→A,即Y是多余的属性;否则,Y不是多余的属性。
(3)在G中消除冗余的函数依赖。具体做法是:从第一个函数依赖开始,在G中去掉它(假设该函数依赖是X→Y ),然后在剩下的函数依赖中求X+,看X+是否包含Y,若是,则去掉X→Y;若不包含Y,则不能去掉X→Y。依次进行下去。



三、关系模式的分解
定义:
设有关系模式R(U),R1,R2,…,Rk都 是R 的子集(此处把关系模式看成是属性的集合),R=R1∪R2∪…∪Rk,关系模式的集合用ρ表示,ρ={R1,R2,…,Rk}。用 ρ代替R 的过程称为关系模式的分解。这里ρ称为R 的一个分解,也称为数据库模式。
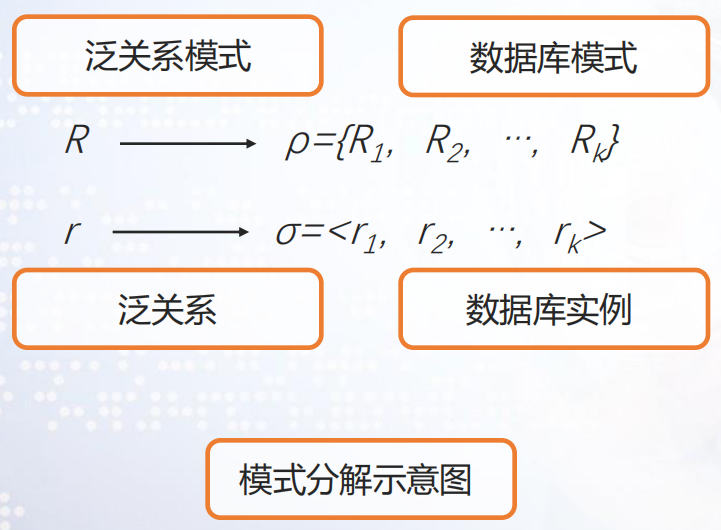 -----
-----
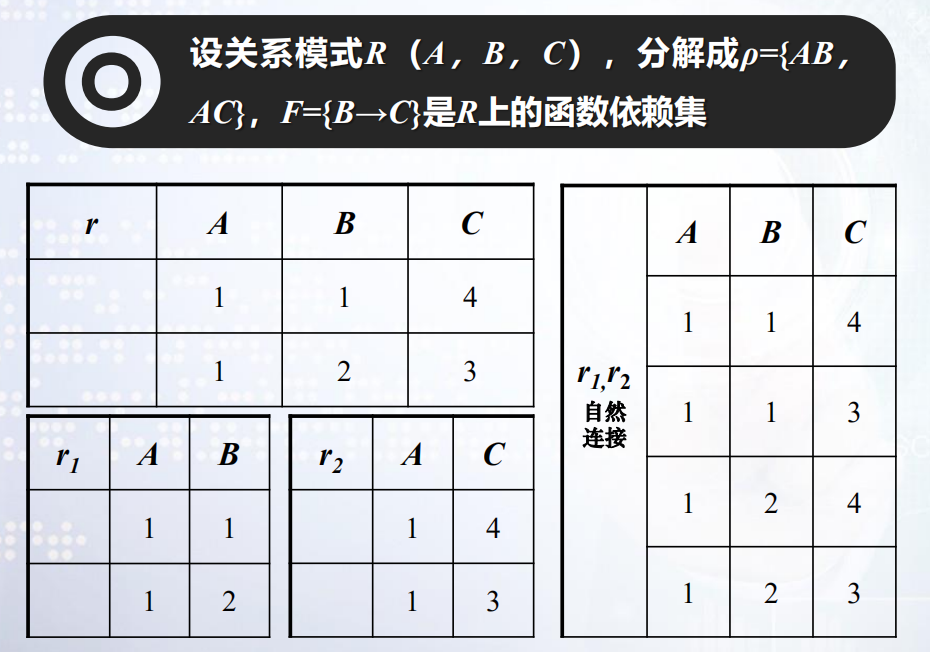
3.1 无损连接的分解
定义
设有关系模式R,F是R上的函数依赖集, ρ={R1,R2,…,Rk}。如果对R中满足F的每一个关系r,有r =ΠR1®∞ΠR2®∞…∞ΠRk®,那么就称分解ρ相对于F是“无损连接分解”;否则称为“损失分解”。
 -----
-----
3.2 无损分解测试算法
无损分解测试算法
输入:关系模式R(A1,A2,…,An ),F 是R上的函数依赖集, R的一个分解ρ={R1, R2,…,Rk}。
输出:判断ρ相对于F是否为无损连接分解
构造一个k行n列的表格Rρ,表中每一列对应一个属性Aj ( 1≤j≤n ),每 一 行 对 应 一 个 模 式 Ri (1≤i≤k)。如果Aj在Ri 中,则在表中的第i行第j列处填上符号aj,否则填上 bij。
把表格看成模式R的一个关系,根据F中的每个函数依赖,修改表中元素的符号,其方法如下。
对F中的某个函数依赖X→Y,在表中寻找X分量上相等的行,把这些行的Y分量也都改成一致。具体做法是分别对Y分量上的每一列做修改。
如果列中有一个是aj,那么这一列上(X相同的行)的元素都改成aj;
如果列中没有aj,那么这一列上(X相同的行)的元素都改成bij(下标ij取i最小的那个)。
对F中所有的函数依赖,反复地执行上述的修改操作,一直到表格不能再修改为止(这个过程
称为“追踪” 过程)。
若修改到最后,表中有一行全为a,即a1a2…an,那么称 ρ 相对于 F 是无损连接分解。
[例]
设有关系模式R(A,B,C,D),R分解成 ρ={AB,BC,CD},如果在R上成立的函数依赖集F={B→A,C→D},那么 ρ 相对于 F 是否为无损连接分解?

3.3 保持函数依赖的分解
定义:
设有关系模式R(U ),F 是R(U )上的函数依赖集,Z 是属性集U上的一个子集,ρ={R1, R2,…,Rk}是R 的一个分解。

一个无损连接分解不一定是保持函数依赖的;
一个保持函数依赖的分解也不一定是无损连接的。
四、关系模式的范式

4.1 第一范式
定义:如果关系模式R所有的属性均为原子属性,即每个属性都是不可再分的,则称R属于第一范式,简称1NF,记作R∈1NF。
1NF是关系模式应具备的最起码的条件。
第一范式可能具有大量的数据冗余,存在插入异常、删除异常和更新异常等弊端。
如关系模式SCD属于1NF,它既存在完全函数依赖,又存在部分函数依赖和传递函数依赖 。
克服这些弊端的方法是用投影运算将关系分解,去掉过于复杂的函数依赖关系,向更高一级的范式进行转换。
4.2 第二范式
如果关系模式R∈1NF,且每个非主属性都完全函数依赖于R的主码,则称R属于第二范式,简称2NF,记作R∈2NF 。
例子1:关系模式TC(T,C):主码→(T,C);主属性→ T、C
不存在非主属性对主码的部分函数依赖,因此TC∈2NF。
例子2:在关系模式SCD中:SNO,CNO为主属性;AGE,DEPT,SN,MN,SCORE均为非主属性;
由SCD分解的三个关系模式S,D,SC,其中S的主码为SNO,D的主码为DEPT,都是单属性,不可能存在部分函数依赖。
从1NF关系中消除非主属性对主码的部分函数依赖,则可得到2NF关系;
如果R的主码为单属性,或R的全体属性均为主属性,则R∈2NF。
2NF规范化:
2NF规范化是指把1NF关系模式通过投影分解,转换成2NF关系模式的集合。 [例] 将SCD(SNo,SN,Age,Dept,MN,CNo,Score)规范为2NF。
例子:SNO→SN, SNO→AGE, SNO→DEPT,(SNO,CNO)→ SCORE

2NF的缺点:
数据冗余:每个系名和系主任的名字存储的次数等于该系的学生人数
插入异常:当一个新系没有招生时,有关该系的信息无法插入
删除异常:某系学生全部毕业而没有招生时,删除全部学生的记录也随之删除了该系的有关信息
更新异常:更换系主任时,仍需改动较多的学生记录
4.3 第三范式
定义:
如果关系模式R∈2NF,且每个非主属性都不传递函数依赖于R的主码,则称R属于第三范式,简称3NF,记作R∈3NF。

3NF的规范化
算法1 把一个关系模式分解为3NF,使它具有保持函数依赖性。
输入:关系模式R和R的最小函数依赖集Fmin
输出:R的一个保持函数依赖的分解ρ={R1,R2,…,Rk},每个Ri相对于ΠR1(Fmin)是3NF模式。
(1)如果Fmin中有一函数依赖X→A,且XA=R,则输出ρ={R},转(4)。
(2)如果R中某些属性与Fmin中所有依赖的左部和右部都无关,则将它们构成关系模式,从R中将它们分出去,单独构成一个模式。
(3)对于Fmin中的每一个函数依赖X→A,都单独构成一个关系子模式XA。若Fmin中有X→A1,X→A2,…,X→An,则可以用模式XA1A2…An取代n个模式XA1,XA2,…,XAn。
(4)停止分解,输出ρ
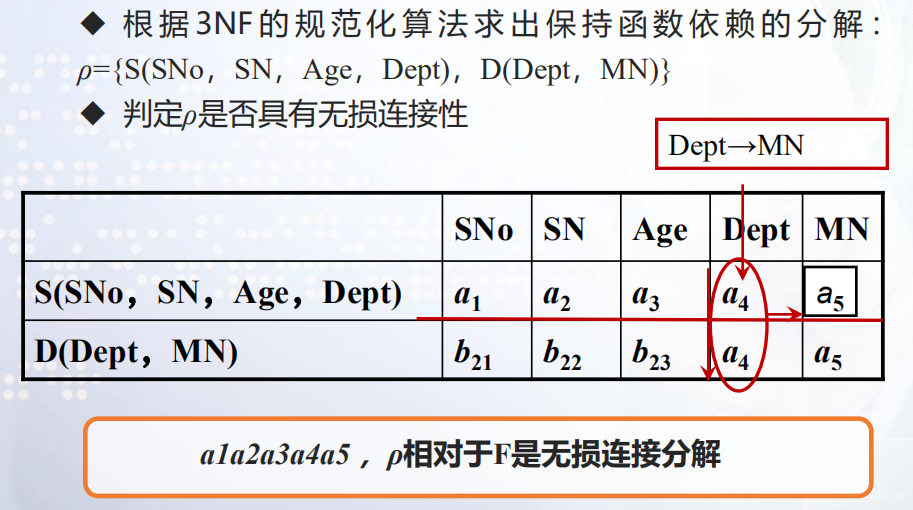
[例]将SD(SNo,SN,Age,Dept,MN)规范到3NF且具有保持函数依赖性。
求出关系模式SD的最小函数依赖集Fmin={SNo →SN,SNo→Age,SNo →Dept,Dept →MN}
根据算法中(1),F中没有满足条件的函数依赖
根据算法中(2),F中没有满足条件的函数依赖
根据算法中(3),将R分解为S={SNo,SN,Age,Dept},D={Dept,MN}
算法2 把一个关系模式分解为3NF,使它既具有无损连接性又具有保持函数依赖性。
输入:关系模式R和R的最小函数依赖集Fmin
输出:R的一个分解ρ={R1,R2,…,Rk},Ri为3NF, ρ具有无损连接性和保持函数依赖性
(1)根据3NF规范化算法求出保持函数依赖的分解:ρ={R1, R2,…,Rk}。
(2)判定ρ是否具有无损连接性,若是,转(4)。
(3)令ρ=ρ∪{X}={R1,R2,…,Rk,X},其中X是R的候选码。
(4)输出ρ
[例]将SD(SNo,SN,Age,Dept,MN)规范到3NF。
3NF解决了2NF中存在的四个问题:
(1)数据冗余降低了
(2)不存在插入异常
(3)不存在删除异常
(4)不存在更新异常
4.4 BC 范式
定义
如果关系模式R∈1NF,且所有的函数依赖X→Y(Y∉X),决定因素X都包含了R的一个候选码,则称 R 属于 BC 范式 ,记作R∈BCNF。
BCNF 具有如下性质 :
如果R∈BCNF,则R也是3NF 。如果R∈3NF,则R不一定是BCNF 。

算法 把一个关系模式分解为BCNF
输入:关系模式R和R的函数依赖集F
输出:R的一个无损连接分解ρ={R1,R2,…,Rk},每个Ri相对于ΠRi(F)是BCNF模式。
(1)令ρ={R}。
(2)如果ρ中所有模式都是BCNF,则转(4)。
(3)如果ρ中有一个关系模式S不是BCNF,则S中必能找到一个函数依赖X→A且X不是S的候选码, 且A不属于X,设S1=XA,S2=S-(A-X),用分解{S1, S2}代替S,转(2)。
(4)分解结束,输出ρ。
[例] 将SNC(SNo,SN,CNo,Score)规范到BCNF。
候选码:(SNo,CNo)和(SN,CNo)
函数依赖:F={SNo→SN,SN→SNo,(SNo,CNo)→Score,(SN,CNo)→Score}
(1)令ρ={SNC(SNo,SN,CNo,Score)}。
(2)经过前面分析可知,ρ中关系模式不属于BCNF。
(3)用分解{S1(SNo,SN),S2(SNo,CNo,Score)}代替SNC。
(4)分解结果为:S1(SNo,SN)描述学生实体;S2(SNo,CNo,Score)描述学生与课程的联系
五、 关系模式的规范化
一个低一级范式的关系模式,通过模式分解转化为若干个高一级范式的关系模式的集合,这种分解过程叫作关系模式的规范化。
关系模式规范化的目的和原则:
规范化的目的就是使结构合理,消除存储异常,使数据冗余尽量小,便于插入、删除和更新。
规范化的基本原则就是遵循“一事一地”的原则。
关系模式规范化的步骤:

关系模式规范化的要求:
保证分解后的关系模式与原关系模式是等价的
等价的三种标准:
分解要具有无损连接性;——保证不丢失信息
分解要具有函数依赖保持性;———减轻或解决各种异常情况
分解既要具有无损连接性,又要具有函数依赖保持性。















 772
772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









