







为了解决这个bug耽误了一天的时间,这里记录一下踩坑日记。
在运行代码时候出现RuntimeError: CUDA error: an illegal memory access was encountered上网找了找解决方案:
1:减小batchsize大小,我设置的为8,我想tesla v100不可能连batchsize=8都跑不了吧,反手把batchsize设置为4,发现还是报错,排除。
2:检查model是否在CUDA上,经过检查确实在cuda上。

3:我的错误很奇怪,是模型训练了一个batch就停止了,把batchsize设置为4后训练五个batch停止了,看了看错误提示:316行 optimizer.step(),于是我搜了一下optimizer.step(),发现我的optimizer.step()放在lr_scheduler.step()后面,于是调整他俩的前后顺序。再次运行还是错误,搜了搜发现这个错误是并没有指定哪一行,相当于只报错,不告诉位置。

于是又找了找,发现在代码的前面添加一行os.environ[‘CUDA_LAUNCH_BLOCKING’] = '1’可以告诉指定位置错误(有时候用cpu运行也可以告诉具体的错误,而GPU不会,但是cpu有时在还没有告诉错误之前就已经因为内存不足被killed了)。

再次运行,出现新的错误,谢天谢地终于不是抓瞎了。
RuntimeError: fractional_max_pool2d_backward_out_cuda failed with error code 0
继续搜索,在GitHub的issue中发现同样的错误:
解决方案一:降低pytorch版本
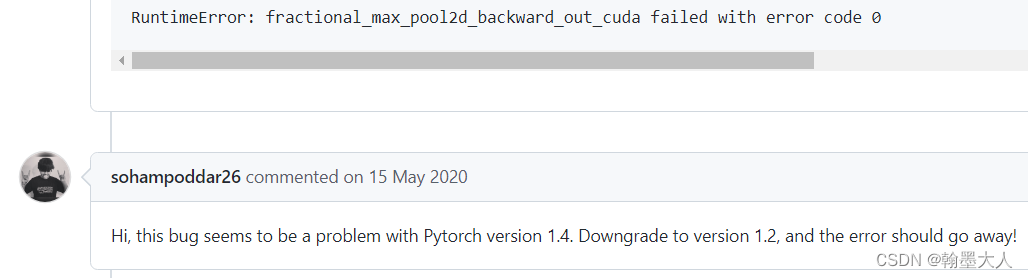
解决方案二:降低pytorch版本,用更大的池化维度,即maxpool1d有问题,为什么不是maxpool2d呢?因为我在代码中根本没用到maxpool2d。这应该是代码本身的bug(我猜的)。
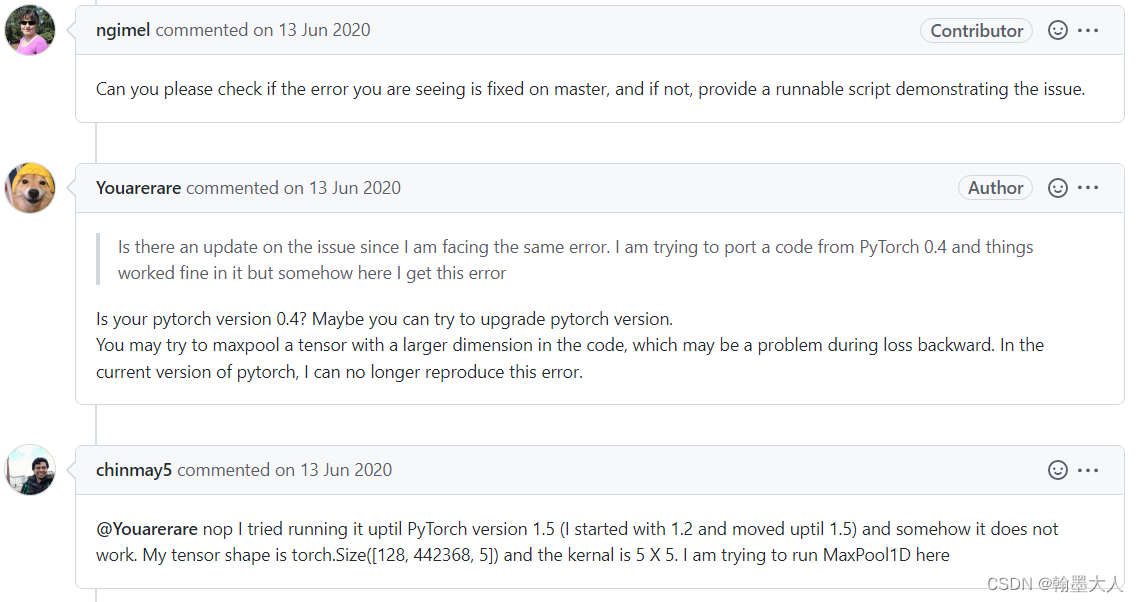
经过我检查代码中F.maxpool1d发现并没有错误,因此不得不面对降低pytorch版本,就将我本身的1.3.1的版本卸载掉,重新安装1.2.0版本,但是我感觉肯定和和1.3版本的一些包,驱动什么的不匹配,但是只能硬着头皮改了。
经过千辛万苦,下载好了1.2版本,运行发现不报上面的错了,但是由新的错误,
can’t import OneCycleLR from torch.optim.lr_scheduler
这个完全是版本冲突导致的!!!,pytorch作者已经将OneCycleLR 加入了pytorch中。所以降低版本就会导致新的错误!!!

最后我重新修改了代码,将原来的F.maxpool1d用F.maxpool2d重写,重新运行就可以了。














11-28
 5676
5676
5676
06-23
3万+
3万+
07-29
1万+
1万+
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









