








首先我们看网络总的代码:
class UCTransNet(nn.Module):
def __init__(self, config,n_channels=3, n_classes=1,img_size=224,vis=False):
super().__init__()
self.vis = vis
self.n_channels = n_channels
self.n_classes = n_classes
in_channels = config.base_channel
self.inc = ConvBatchNorm(n_channels, in_channels)
self.down1 = DownBlock(in_channels, in_channels*2, nb_Conv=2)
self.down2 = DownBlock(in_channels*2, in_channels*4, nb_Conv=2)
self.down3 = DownBlock(in_channels*4, in_channels*8, nb_Conv=2)
self.down4 = DownBlock(in_channels*8, in_channels*8, nb_Conv=2)
self.mtc = ChannelTransformer(config, vis, img_size,
channel_num=[in_channels, in_channels*2, in_channels*4, in_channels*8],
patchSize=config.patch_sizes)
self.up4 = UpBlock_attention(in_channels*16, in_channels*4, nb_Conv=2)
self.up3 = UpBlock_attention(in_channels*8, in_channels*2, nb_Conv=2)
self.up2 = UpBlock_attention(in_channels*4, in_channels, nb_Conv=2)
self.up1 = UpBlock_attention(in_channels*2, in_channels, nb_Conv=2)
self.outc = nn.Conv2d(in_channels, n_classes, kernel_size=(1,1), stride=(1,1))
self.last_activation = nn.Sigmoid() # if using BCELoss
def forward(self, x):
x = x.float()
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x1,x2,x3,x4,att_weights = self.mtc(x1,x2,x3,x4)
x = self.up4(x5, x4)
x = self.up3(x, x3)
x = self.up2(x, x2)
x = self.up1(x, x1)
if self.n_classes ==1:
logits = self.last_activation(self.outc(x))
else:
logits = self.outc(x) # if nusing BCEWithLogitsLoss or class>1
if self.vis: # visualize the attention maps
return logits, att_weights
else:
return logits
输入图片x,尺寸为(1,3,224,224),经过self.inc,对应于ConvBatchNorm,n_channels对应于inchannel, in_channels对应于outchannel,x经过self.conv,self.norm,self.relu后尺寸变为(1,64,224,224)。
self.inc = ConvBatchNorm(n_channels, in_channels)class ConvBatchNorm(nn.Module):
"""(convolution => [BN] => ReLU)"""
def __init__(self, in_channels, out_channels, activation='ReLU'):
super(ConvBatchNorm, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1)
self.norm = nn.BatchNorm2d(out_channels)
self.activation = get_activation(activation)
def forward(self, x):
out = self.conv(x)
out = self.norm(out)
return self.activation(out)接着经过down1,调到downblock,其中in_channels, out_channels分别对应于in_channels, in_channels*2,首先经过卷积核为2的self.maxpool(2),大小变为(1,64,112,112)接着经过nconvs,跳到_make_nconv,在_make_nconv中,layers列表里有三个convbatchnorm,经过第一个大小变为(1,128,112,112),经过第二三个,大小仍为(1,128,112,112)。
self.down1 = DownBlock(in_channels, in_channels*2, nb_Conv=2)class DownBlock(nn.Module):
"""Downscaling with maxpool convolution"""
def __init__(self, in_channels, out_channels, nb_Conv, activation='ReLU'):
super(DownBlock, self).__init__()
self.maxpool = nn.MaxPool2d(2)
self.nConvs = _make_nConv(in_channels, out_channels, nb_Conv, activation)
def forward(self, x):
out = self.maxpool(x)
return self.nConvs(out)
def _make_nConv(in_channels, out_channels, nb_Conv, activation='ReLU'):
layers = []
layers.append(ConvBatchNorm(in_channels, out_channels, activation))
for _ in range(nb_Conv - 1):
layers.append(ConvBatchNorm(out_channels, out_channels, activation))
return nn.Sequential(*layers)同理经过第二个第三个第四个,尺寸变为(1,256,56,56),(1,512,28,28),(1,512,14,14)。
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4) self.down2 = DownBlock(in_channels*2, in_channels*4, nb_Conv=2)
self.down3 = DownBlock(in_channels*4, in_channels*8, nb_Conv=2)
self.down4 = DownBlock(in_channels*8, in_channels*8, nb_Conv=2)接着将生成的结果输入self.mtc中,调到channeltransformer中,其中参数patchsize对应于congfig文件中的 config.patch_sizes = [16,8,4,2],然后我们进入channeltransformer即CCT中。
x1,x2,x3,x4,att_weights = self.mtc(x1,x2,x3,x4)self.mtc = ChannelTransformer(config, vis, img_size,
channel_num=[in_channels, in_channels*2, in_channels*4, in_channels*8],
patchSize=config.patch_sizes)class ChannelTransformer(nn.Module):
def __init__(self, config, vis, img_size, channel_num=[64, 128, 256, 512], patchSize=[32, 16, 8, 4]):
super().__init__()
self.patchSize_1 = patchSize[0]
self.patchSize_2 = patchSize[1]
self.patchSize_3 = patchSize[2]
self.patchSize_4 = patchSize[3]
self.embeddings_1 = Channel_Embeddings(config,self.patchSize_1, img_size=img_size, in_channels=channel_num[0])
self.embeddings_2 = Channel_Embeddings(config,self.patchSize_2, img_size=img_size//2, in_channels=channel_num[1])
self.embeddings_3 = Channel_Embeddings(config,self.patchSize_3, img_size=img_size//4, in_channels=channel_num[2])
self.embeddings_4 = Channel_Embeddings(config,self.patchSize_4, img_size=img_size//8, in_channels=channel_num[3])
self.encoder = Encoder(config, vis, channel_num)
self.reconstruct_1 = Reconstruct(channel_num[0], channel_num[0], kernel_size=1,scale_factor=(self.patchSize_1,self.patchSize_1))
self.reconstruct_2 = Reconstruct(channel_num[1], channel_num[1], kernel_size=1,scale_factor=(self.patchSize_2,self.patchSize_2))
self.reconstruct_3 = Reconstruct(channel_num[2], channel_num[2], kernel_size=1,scale_factor=(self.patchSize_3,self.patchSize_3))
self.reconstruct_4 = Reconstruct(channel_num[3], channel_num[3], kernel_size=1,scale_factor=(self.patchSize_4,self.patchSize_4))
def forward(self,en1,en2,en3,en4):
emb1 = self.embeddings_1(en1)
emb2 = self.embeddings_2(en2)
emb3 = self.embeddings_3(en3)
emb4 = self.embeddings_4(en4)
encoded1, encoded2, encoded3, encoded4, attn_weights = self.encoder(emb1,emb2,emb3,emb4) # (B, n_patch, hidden)
x1 = self.reconstruct_1(encoded1) if en1 is not None else None
x2 = self.reconstruct_2(encoded2) if en2 is not None else None
x3 = self.reconstruct_3(encoded3) if en3 is not None else None
x4 = self.reconstruct_4(encoded4) if en4 is not None else None
x1 = x1 + en1 if en1 is not None else None
x2 = x2 + en2 if en2 is not None else None
x3 = x3 + en3 if en3 is not None else None
x4 = x4 + en4 if en4 is not None else None
return x1, x2, x3, x4, attn_weights
注意:在ChannelTransformer中的channel_num,patch_size是默认值,我们实例化后的值才是真实要用到的值。
这里的x1,x2,x3,x4对应于forward中的en1,en2,en3,en4。我们对他进行编码,en1经过patch_embeddings,即经过核大小为(16,16),步长为16的卷积,大小变为(1,64,14,14),接着展平(1,64,196),交换后两维(1,196,64),加上position_embedding,维度为(1,196,64)。
emb1 = self.embeddings_1(en1) self.embeddings_1 = Channel_Embeddings(config,self.patchSize_1, img_size=img_size, in_channels=channel_num[0])class Channel_Embeddings(nn.Module):
"""Construct the embeddings from patch, position embeddings.
"""
def __init__(self,config, patchsize, img_size, in_channels):
super().__init__()
img_size = _pair(img_size)
patch_size = _pair(patchsize)
n_patches = (img_size[0] // patch_size[0]) * (img_size[1] // patch_size[1])
self.patch_embeddings = Conv2d(in_channels=in_channels,
out_channels=in_channels,
kernel_size=patch_size,
stride=patch_size)
self.position_embeddings = nn.Parameter(torch.zeros(1, n_patches, in_channels))
self.dropout = Dropout(config.transformer["embeddings_dropout_rate"])
def forward(self, x):
if x is None:
return None
x = self.patch_embeddings(x) # (B, hidden. n_patches^(1/2), n_patches^(1/2))
x = x.flatten(2)
x = x.transpose(-1, -2) # (B, n_patches, hidden)
embeddings = x + self.position_embeddings
embeddings = self.dropout(embeddings)
return embeddingsen2经过channel_embedding,(1,128,112,112)经过核(8,8)步长为8的卷积结果为(1,128,14,14),展平(1,128,196),交换后两维,(1,196,128),加上位置编码(1,196,128)。
emb2 = self.embeddings_2(en2)self.embeddings_2 = Channel_Embeddings(config,self.patchSize_2, img_size=img_size//2, in_channels=channel_num[1])同理en3,(1,256,56,56)经过核(4,4)步长为4,变为(1,256,14,14),展平(1,256,196),交换(1,196,256),加上位置编码(1,196,256),同理en4,最后变为(1,196,512)。
将生成的结果(1,196,64),(1,196,128),(1,196,256),(1,196,512)输入进encoder。经过layerblock。layerblock又属于self.layer,self.layer空列表中添加了blockvit,所以就相当于输入进了layerblock,我们跳到blockvit中。
encoded1, encoded2, encoded3, encoded4, attn_weights = self.encoder(emb1,emb2,emb3,emb4) self.encoder = Encoder(config, vis, channel_num)class Encoder(nn.Module):
def __init__(self, config, vis, channel_num):
super(Encoder, self).__init__()
self.vis = vis
self.layer = nn.ModuleList()
self.encoder_norm1 = LayerNorm(channel_num[0],eps=1e-6)
self.encoder_norm2 = LayerNorm(channel_num[1],eps=1e-6)
self.encoder_norm3 = LayerNorm(channel_num[2],eps=1e-6)
self.encoder_norm4 = LayerNorm(channel_num[3],eps=1e-6)
for _ in range(config.transformer["num_layers"]):
layer = Block_ViT(config, vis, channel_num)
self.layer.append(copy.deepcopy(layer))
def forward(self, emb1,emb2,emb3,emb4):
attn_weights = []
for layer_block in self.layer:
emb1,emb2,emb3,emb4, weights = layer_block(emb1,emb2,emb3,emb4)
if self.vis:
attn_weights.append(weights)
emb1 = self.encoder_norm1(emb1) if emb1 is not None else None
emb2 = self.encoder_norm2(emb2) if emb2 is not None else None
emb3 = self.encoder_norm3(emb3) if emb3 is not None else None
emb4 = self.encoder_norm4(emb4) if emb4 is not None else None
return emb1,emb2,emb3,emb4, attn_weights
class Block_ViT(nn.Module):
def __init__(self, config, vis, channel_num):
super(Block_ViT, self).__init__()
expand_ratio = config.expand_ratio
self.attn_norm1 = LayerNorm(channel_num[0],eps=1e-6)
self.attn_norm2 = LayerNorm(channel_num[1],eps=1e-6)
self.attn_norm3 = LayerNorm(channel_num[2],eps=1e-6)
self.attn_norm4 = LayerNorm(channel_num[3],eps=1e-6)
self.attn_norm = LayerNorm(config.KV_size,eps=1e-6)
self.channel_attn = Attention_org(config, vis, channel_num)
self.ffn_norm1 = LayerNorm(channel_num[0],eps=1e-6)
self.ffn_norm2 = LayerNorm(channel_num[1],eps=1e-6)
self.ffn_norm3 = LayerNorm(channel_num[2],eps=1e-6)
self.ffn_norm4 = LayerNorm(channel_num[3],eps=1e-6)
self.ffn1 = Mlp(config,channel_num[0],channel_num[0]*expand_ratio)
self.ffn2 = Mlp(config,channel_num[1],channel_num[1]*expand_ratio)
self.ffn3 = Mlp(config,channel_num[2],channel_num[2]*expand_ratio)
self.ffn4 = Mlp(config,channel_num[3],channel_num[3]*expand_ratio)
def forward(self, emb1,emb2,emb3,emb4):
embcat = []
org1 = emb1
org2 = emb2
org3 = emb3
org4 = emb4
for i in range(4):
var_name = "emb"+str(i+1)
tmp_var = locals()[var_name] # 返回字典里键对应的值
if tmp_var is not None:
embcat.append(tmp_var)
emb_all = torch.cat(embcat,dim=2)
cx1 = self.attn_norm1(emb1) if emb1 is not None else None
cx2 = self.attn_norm2(emb2) if emb2 is not None else None
cx3 = self.attn_norm3(emb3) if emb3 is not None else None
cx4 = self.attn_norm4(emb4) if emb4 is not None else None
emb_all = self.attn_norm(emb_all)
cx1,cx2,cx3,cx4, weights = self.channel_attn(cx1,cx2,cx3,cx4,emb_all)
cx1 = org1 + cx1 if emb1 is not None else None
cx2 = org2 + cx2 if emb2 is not None else None
cx3 = org3 + cx3 if emb3 is not None else None
cx4 = org4 + cx4 if emb4 is not None else None
org1 = cx1
org2 = cx2
org3 = cx3
org4 = cx4
x1 = self.ffn_norm1(cx1) if emb1 is not None else None
x2 = self.ffn_norm2(cx2) if emb2 is not None else None
x3 = self.ffn_norm3(cx3) if emb3 is not None else None
x4 = self.ffn_norm4(cx4) if emb4 is not None else None
x1 = self.ffn1(x1) if emb1 is not None else None
x2 = self.ffn2(x2) if emb2 is not None else None
x3 = self.ffn3(x3) if emb3 is not None else None
x4 = self.ffn4(x4) if emb4 is not None else None
x1 = x1 + org1 if emb1 is not None else None
x2 = x2 + org2 if emb2 is not None else None
x3 = x3 + org3 if emb3 is not None else None
x4 = x4 + org4 if emb4 is not None else None
return x1, x2, x3, x4, weights在blockvit中,四个输入对应于emb1,emb2,emb3,emb4,将四个输入放进空列表中,然后按通道维度进行拼接。则emb_all的维度变为(1,196,960)。
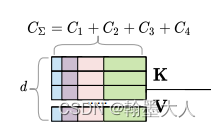
然后emb1分别经过self.attn_norm1,跳到layernorm。对通道维度进行layernorm。emb2,3,4,all同理。
self.attn_norm1 = LayerNorm(channel_num[0],eps=1e-6)生成的cx1,cx2,cx3,cx4,emb_all输入进self.channel_attn,进行注意力计算,跳到
self.channel_attn = Attention_org(config, vis, channel_num)class Attention_org(nn.Module):
def __init__(self, config, vis,channel_num):
super(Attention_org, self).__init__()
self.vis = vis
self.KV_size = config.KV_size
self.channel_num = channel_num
self.num_attention_heads = config.transformer["num_heads"]
self.query1 = nn.ModuleList()
self.query2 = nn.ModuleList()
self.query3 = nn.ModuleList()
self.query4 = nn.ModuleList()
self.key = nn.ModuleList()
self.value = nn.ModuleList()
for _ in range(config.transformer["num_heads"]):
query1 = nn.Linear(channel_num[0], channel_num[0], bias=False)
query2 = nn.Linear(channel_num[1], channel_num[1], bias=False)
query3 = nn.Linear(channel_num[2], channel_num[2], bias=False)
query4 = nn.Linear(channel_num[3], channel_num[3], bias=False)
key = nn.Linear( self.KV_size, self.KV_size, bias=False)
value = nn.Linear(self.KV_size, self.KV_size, bias=False)
self.query1.append(copy.deepcopy(query1))
self.query2.append(copy.deepcopy(query2))
self.query3.append(copy.deepcopy(query3))
self.query4.append(copy.deepcopy(query4))
self.key.append(copy.deepcopy(key))
self.value.append(copy.deepcopy(value))
self.psi = nn.InstanceNorm2d(self.num_attention_heads)
self.softmax = Softmax(dim=3)
self.out1 = nn.Linear(channel_num[0], channel_num[0], bias=False)
self.out2 = nn.Linear(channel_num[1], channel_num[1], bias=False)
self.out3 = nn.Linear(channel_num[2], channel_num[2], bias=False)
self.out4 = nn.Linear(channel_num[3], channel_num[3], bias=False)
self.attn_dropout = Dropout(config.transformer["attention_dropout_rate"])
self.proj_dropout = Dropout(config.transformer["attention_dropout_rate"])
def forward(self, emb1,emb2,emb3,emb4, emb_all):
multi_head_Q1_list = []
multi_head_Q2_list = []
multi_head_Q3_list = []
multi_head_Q4_list = []
multi_head_K_list = []
multi_head_V_list = []
if emb1 is not None:
for query1 in self.query1:
Q1 = query1(emb1)
multi_head_Q1_list.append(Q1)
if emb2 is not None:
for query2 in self.query2:
Q2 = query2(emb2)
multi_head_Q2_list.append(Q2)
if emb3 is not None:
for query3 in self.query3:
Q3 = query3(emb3)
multi_head_Q3_list.append(Q3)
if emb4 is not None:
for query4 in self.query4:
Q4 = query4(emb4)
multi_head_Q4_list.append(Q4)
for key in self.key:
K = key(emb_all)
multi_head_K_list.append(K)
for value in self.value:
V = value(emb_all)
multi_head_V_list.append(V)
# print(len(multi_head_Q4_list))
multi_head_Q1 = torch.stack(multi_head_Q1_list, dim=1) if emb1 is not None else None
multi_head_Q2 = torch.stack(multi_head_Q2_list, dim=1) if emb2 is not None else None
multi_head_Q3 = torch.stack(multi_head_Q3_list, dim=1) if emb3 is not None else None
multi_head_Q4 = torch.stack(multi_head_Q4_list, dim=1) if emb4 is not None else None
multi_head_K = torch.stack(multi_head_K_list, dim=1)
multi_head_V = torch.stack(multi_head_V_list, dim=1)
multi_head_Q1 = multi_head_Q1.transpose(-1, -2) if emb1 is not None else None
multi_head_Q2 = multi_head_Q2.transpose(-1, -2) if emb2 is not None else None
multi_head_Q3 = multi_head_Q3.transpose(-1, -2) if emb3 is not None else None
multi_head_Q4 = multi_head_Q4.transpose(-1, -2) if emb4 is not None else None
attention_scores1 = torch.matmul(multi_head_Q1, multi_head_K) if emb1 is not None else None
attention_scores2 = torch.matmul(multi_head_Q2, multi_head_K) if emb2 is not None else None
attention_scores3 = torch.matmul(multi_head_Q3, multi_head_K) if emb3 is not None else None
attention_scores4 = torch.matmul(multi_head_Q4, multi_head_K) if emb4 is not None else None
attention_scores1 = attention_scores1 / math.sqrt(self.KV_size) if emb1 is not None else None
attention_scores2 = attention_scores2 / math.sqrt(self.KV_size) if emb2 is not None else None
attention_scores3 = attention_scores3 / math.sqrt(self.KV_size) if emb3 is not None else None
attention_scores4 = attention_scores4 / math.sqrt(self.KV_size) if emb4 is not None else None
attention_probs1 = self.softmax(self.psi(attention_scores1)) if emb1 is not None else None
attention_probs2 = self.softmax(self.psi(attention_scores2)) if emb2 is not None else None
attention_probs3 = self.softmax(self.psi(attention_scores3)) if emb3 is not None else None
attention_probs4 = self.softmax(self.psi(attention_scores4)) if emb4 is not None else None
# print(attention_probs4.size())
if self.vis:
weights = []
weights.append(attention_probs1.mean(1))
weights.append(attention_probs2.mean(1))
weights.append(attention_probs3.mean(1))
weights.append(attention_probs4.mean(1))
else: weights=None
attention_probs1 = self.attn_dropout(attention_probs1) if emb1 is not None else None
attention_probs2 = self.attn_dropout(attention_probs2) if emb2 is not None else None
attention_probs3 = self.attn_dropout(attention_probs3) if emb3 is not None else None
attention_probs4 = self.attn_dropout(attention_probs4) if emb4 is not None else None
multi_head_V = multi_head_V.transpose(-1, -2)
context_layer1 = torch.matmul(attention_probs1, multi_head_V) if emb1 is not None else None
context_layer2 = torch.matmul(attention_probs2, multi_head_V) if emb2 is not None else None
context_layer3 = torch.matmul(attention_probs3, multi_head_V) if emb3 is not None else None
context_layer4 = torch.matmul(attention_probs4, multi_head_V) if emb4 is not None else None
context_layer1 = context_layer1.permute(0, 3, 2, 1).contiguous() if emb1 is not None else None
context_layer2 = context_layer2.permute(0, 3, 2, 1).contiguous() if emb2 is not None else None
context_layer3 = context_layer3.permute(0, 3, 2, 1).contiguous() if emb3 is not None else None
context_layer4 = context_layer4.permute(0, 3, 2, 1).contiguous() if emb4 is not None else None
context_layer1 = context_layer1.mean(dim=3) if emb1 is not None else None
context_layer2 = context_layer2.mean(dim=3) if emb2 is not None else None
context_layer3 = context_layer3.mean(dim=3) if emb3 is not None else None
context_layer4 = context_layer4.mean(dim=3) if emb4 is not None else None
O1 = self.out1(context_layer1) if emb1 is not None else None
O2 = self.out2(context_layer2) if emb2 is not None else None
O3 = self.out3(context_layer3) if emb3 is not None else None
O4 = self.out4(context_layer4) if emb4 is not None else None
O1 = self.proj_dropout(O1) if emb1 is not None else None
O2 = self.proj_dropout(O2) if emb2 is not None else None
O3 = self.proj_dropout(O3) if emb3 is not None else None
O4 = self.proj_dropout(O4) if emb4 is not None else None
return O1,O2,O3,O4, weights
注:在类中,因为是多头注意力机制,有4个头,所以query1,2,3,4,key,value遍历了四次。
cx1,cx2,cx3,cx4,emb_all对应于emb1,emb2,emb3,emb4, emb_all,首先emb1经过query1,生成Q1,emb2经过query2,生成Q3,emb3经过query3,生成Q3,emb4经过query4,生成Q4,emb_all经过key生成k,经过value生成v,其中query是一个线性层。然后将生成的结果添加到空列表中。
然后将列表进行stack操作,即在指定维度增加一个维度,则四个(1,196,64),四个(1,196,128),四个(1,196,256),四个(1,196,512),变为(1,4,196,64),(1,4,196,128),(1,4,196,256),(1,4,196,512),k,v由变为(1,4,196,960)。
接着Q1,2,3,4进行转置,变为(1,4,64,196),(1,4,128,196),(1,4,256,196),(1,4,512,196)分别于K进行矩阵相乘,维度变为(1,4,64,960),(1,4,128,960),(1,4,256,960),(1,4,512,960)。生成的结果attention_prob1,2,3,4除以根号下K,进行softmax,dropout。
然后v进行转置,(1,4,960,196),将attention_prob1,2,3,4与v进行相乘,维度变为(1,4,64,196),(1,4,128,196),(1,4,256,196),(1,4,512,196)。将一三维进行交换(1,196,64,4),(1,196,128,4),(1,196,256,4),(1,196,512,4)。接着对第三个维度进行求均值,维度变为(1,196,64),(1,196,128),(1,196,256),(1,196,512)[mean函数的高维用法参考之前写的mean函数高维用法]。
接着进行self.out1,2,3,4操作,还是进行nn.linear操作,维度不发生改变。再进行dropout操作。生成O1,O2,O3,O4, weights,其中weight是attention_probs1第一维求均值的结果,列表内有(1,64,960),(1,128,960),(1,256,960),(1,512,960)。
接着我们回到Block_ViT中生成的cx1,cx2,cx3,cx4,与原始的org1,2,3,4进行相加,生成cx1,cx2,cx3,cx4等于org1,org2,org3,org4。维度为(1,196,64),(1,196,128),(1,196,256),(1,196,512)。cx1,cx2,cx3,cx4再分别进行layernorm,mlp,生成x1,x2,x3,x4,维度不发生变换。再与org1,org2,org3,org4相加。最后生成x1, x2, x3, x4, weights。
cx1,cx2,cx3,cx4, weights = self.channel_attn(cx1,cx2,cx3,cx4,emb_all)class Mlp(nn.Module):
def __init__(self,config, in_channel, mlp_channel):
super(Mlp, self).__init__()
self.fc1 = nn.Linear(in_channel, mlp_channel)
self.fc2 = nn.Linear(mlp_channel, in_channel)
self.act_fn = nn.GELU()
self.dropout = Dropout(config.transformer["dropout_rate"])
self._init_weights()
def _init_weights(self):
nn.init.xavier_uniform_(self.fc1.weight)
nn.init.xavier_uniform_(self.fc2.weight)
nn.init.normal_(self.fc1.bias, std=1e-6)
nn.init.normal_(self.fc2.bias, std=1e-6)
def forward(self, x):
x = self.fc1(x)
x = self.act_fn(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
return x全部执行完毕后,就回到了encoder中,layerblock就是blockvit。其中x1, x2, x3, x4, weights对应于emb1,emb2,emb3,emb4, weights。将权重添加到attn_weights列表中。在分别进行layernorm生成 emb1,emb2,emb3,emb4, attn_weights。
emb1,emb2,emb3,emb4, weights = layer_block(emb1,emb2,emb3,emb4)encoder执行完毕!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
ChannelTransformer中生成的emb1,emb2,emb3,emb4, attn_weights对应于encoded1, encoded2, encoded3, encoded4, attn_weights。生成的结果分别进入self.reconstruct_函数中。
encoded1, encoded2, encoded3, encoded4, attn_weights = self.encoder(emb1,emb2,emb3,emb4)self.reconstruct_1 = Reconstruct(channel_num[0], channel_num[0], kernel_size=1,scale_factor=(self.patchSize_1,self.patchSize_1))class Reconstruct(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, scale_factor):
super(Reconstruct, self).__init__()
if kernel_size == 3:
padding = 1
else:
padding = 0
self.conv = nn.Conv2d(in_channels, out_channels,kernel_size=kernel_size, padding=padding)
self.norm = nn.BatchNorm2d(out_channels)
self.activation = nn.ReLU(inplace=True)
self.scale_factor = scale_factor
def forward(self, x):
if x is None:
return None
B, n_patch, hidden = x.size() # reshape from (B, n_patch, hidden) to (B, h, w, hidden)
h, w = int(np.sqrt(n_patch)), int(np.sqrt(n_patch))
x = x.permute(0, 2, 1)
x = x.contiguous().view(B, hidden, h, w)
x = nn.Upsample(scale_factor=self.scale_factor)(x)
out = self.conv(x)
out = self.norm(out)
out = self.activation(out)
return out
在Reconstruct中,h,w分别为196开方,(14,14),将(1,196,64),(1,196,128),(1,196,256),(1,196,512)转换后两维,(1,64,196),(1,128,196),(1,256,196),(1,512,196)。转换为(b,c,h,w)格式,
(1,64,14,14),(1,128,14,14),(1,256,14,14),(1,512,14,14)。接着对x进行上采样patchszie倍,分别为[16,8,4,2],新生成大小为(1,64,224,224),(1,128,112,112),(1,256,56,56),(1,512,28,28),接着进行一个
输入输出维度大小都相同的卷积,batchnorm,relu得到最终结果。
接着得到的结果加上self.mtc(x1,x2,x3,x4)中的x1,x2,x3,x4,输出x1, x2, x3, x4, attn_weights。ChannelTransformer执行毕!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
在UCTransNet中,self.mtc执行结束,接着跳到up函数,x4是skip_x,对x5进行上采样2倍(1,512,28,28),和x4共同输入(维度相同)进coatt函数,跳到CCA中。
x = self.up4(x5, x4)
x = self.up3(x, x3)
x = self.up2(x, x2)
x = self.up1(x, x1)self.up4 = UpBlock_attention(in_channels*16, in_channels*4, nb_Conv=2)class UpBlock_attention(nn.Module):
def __init__(self, in_channels, out_channels, nb_Conv, activation='ReLU'):
super().__init__()
self.up = nn.Upsample(scale_factor=2)
self.coatt = CCA(F_g=in_channels//2, F_x=in_channels//2)
self.nConvs = _make_nConv(in_channels, out_channels, nb_Conv, activation)
def forward(self, x, skip_x):
up = self.up(x)
skip_x_att = self.coatt(g=up, x=skip_x)
x = torch.cat([skip_x_att, up], dim=1) # dim 1 is the channel dimension
return self.nConvs(x)class CCA(nn.Module):
"""
CCA Block
"""
def __init__(self, F_g, F_x):
super().__init__()
self.mlp_x = nn.Sequential(
Flatten(),
nn.Linear(F_x, F_x))
self.mlp_g = nn.Sequential(
Flatten(),
nn.Linear(F_g, F_x))
self.relu = nn.ReLU(inplace=True)
def forward(self, g, x):
# channel-wise attention
# k=((x.size(2), x.size(3))),s = (x.size(2), x.size(3))
avg_pool_x = F.avg_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_x = self.mlp_x(avg_pool_x)
avg_pool_g = F.avg_pool2d( g, (g.size(2), g.size(3)), stride=(g.size(2), g.size(3)))
channel_att_g = self.mlp_g(avg_pool_g)
channel_att_sum = (channel_att_x + channel_att_g)/2.0
scale = torch.sigmoid(channel_att_sum).unsqueeze(2).unsqueeze(3).expand_as(x)
x_after_channel = x * scale
out = self.relu(x_after_channel)
return out在CCA中,x进行avgpool2d,维度变为(1,512,1,1),再输入到nn.Sequential( Flatten(), nn.Linear(F_x, F_x))先进行展平,维度变为(1,512),然后经过线性层,g进行avgpool2d,维度变为(1,512,1,1),再输入到nn.Sequential( Flatten(), nn.Linear(F_x, F_x))先进行展平,维度变为(1,512),然后经过线性层。将上面两个结果相加/2,经过sigmoid,然后增加第二第三个维度,重新变为
(1,512,1,1)。接着和x进行相乘,进行注意力计算。
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.size(0), -1)nn.Linear(F_x, F_x))CCA计算完毕!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
计算完CCA就计算完了self.coatt,生成的skip_x_att与上采样up按照通道维度进行拼接,再进行卷积,首先在layer空列表中添加卷积,接着再按顺序添加两次ConvBatchNorm。
def _make_nConv(in_channels, out_channels, nb_Conv, activation='ReLU'):
layers = []
layers.append(ConvBatchNorm(in_channels, out_channels, activation))
for _ in range(nb_Conv - 1):
layers.append(ConvBatchNorm(out_channels, out_channels, activation))
return nn.Sequential(*layers)将X5,X4生成的x作为下一次的输入,不断进行上采样,最终输入进一个1乘1卷积,sigmoid,根据类别数确定最终的n_classes,输出logits为最后的分割图。
if self.n_classes ==1:
logits = self.last_activation(self.outc(x))
else:
logits = self.outc(x) # if nusing BCEWithLogitsLoss or class>1UCTransNet搭建完成!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!















 5494
5494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









