






def validate(model, valid_loader, device, cameras, confusion_matrices,
modality, loss_function_valid, logs, ckpt_dir, epoch,
loss_function_valid_unweighted=None, add_log_key='',
debug_mode=False):
valid_split = valid_loader.dataset.split + add_log_key
print(f'Validation on {valid_split}')
# we want to track how long each part of the validation takes
validation_start_time = time.time()
cm_time = 0 # time for computing all confusion matrices
forward_time = 0
post_processing_time = 0
copy_to_gpu_time = 0
# set model to eval mode
model.eval()
# we want to store miou and ious for each camera
miou = dict()
ious = dict()
# reset loss (of last validation) to zero
loss_function_valid.reset_loss()
if loss_function_valid_unweighted is not None:
loss_function_valid_unweighted.reset_loss()
# validate each camera after another as all images of one camera have
# the same resolution and can be resized together to the ground truth
# segmentation size.
for camera in cameras:
with valid_loader.dataset.filter_camera(camera):
confusion_matrices[camera].reset_conf_matrix()
print(f'{camera}: {len(valid_loader.dataset)} samples')
for i, sample in enumerate(valid_loader):
torch.cuda.empty_cache()
# copy the data to gpu
copy_to_gpu_time_start = time.time()
if modality in ['rgbd', 'rgb']:
image = sample['image'].to(device)
if modality in ['rgbd', 'depth']:
depth = sample['depth'].to(device)
if not device.type == 'cpu':
torch.cuda.synchronize()
copy_to_gpu_time += time.time() - copy_to_gpu_time_start
# forward pass
with torch.no_grad():
forward_time_start = time.time()
prediction = model(image, depth)
if not device.type == 'cpu':
torch.cuda.synchronize()
forward_time += time.time() - forward_time_start
# compute valid loss
post_processing_time_start = time.time()
loss_function_valid.add_loss_of_batch(
prediction,
sample['label'].to(device)
)
if loss_function_valid_unweighted is not None:
loss_function_valid_unweighted.add_loss_of_batch(
prediction, sample['label'].to(device))
# this label is not preprocessed and therefore still has its
# original size
label = sample['label_orig']
_, image_h, image_w = label.shape
# resize the prediction to the size of the original ground
# truth segmentation before computing argmax along the
# channel axis
prediction = F.interpolate(prediction,(image_h, image_w),mode='bilinear',align_corners=False)
prediction = torch.argmax(prediction, dim=1)
# ignore void pixels
mask = label > 0
label = torch.masked_select(label, mask)
prediction = torch.masked_select(prediction,
mask.to(device))
# In the label 0 is void, but in the prediction 0 is wall.
# In order for the label and prediction indices to match we
# need to subtract 1 of the label.
label -= 1
# copy the prediction to cpu as tensorflow's confusion
# matrix is faster on cpu
prediction = prediction.cpu()
label = label.numpy()
prediction = prediction.numpy()
post_processing_time += \
time.time() - post_processing_time_start
# finally compute the confusion matrix
cm_start_time = time.time()
confusion_matrices[camera].update_conf_matrix(label,
prediction)
cm_time += time.time() - cm_start_time
if debug_mode:
# only one batch while debugging
break
# After all examples of camera are passed through the model,
# we can compute miou and ious.
cm_start_time = time.time()
miou[camera], ious[camera] = \
confusion_matrices[camera].compute_miou()
cm_time += time.time() - cm_start_time
print(f'mIoU {valid_split} {camera}: {miou[camera]}')
# confusion matrix for the whole split
# (sum up the confusion matrices of all cameras)
cm_start_time = time.time()
confusion_matrices['all'].reset_conf_matrix()
for camera in cameras:
confusion_matrices['all'].overall_confusion_matrix += \
confusion_matrices[camera].overall_confusion_matrix
# miou and iou for all cameras
miou['all'], ious['all'] = confusion_matrices['all'].compute_miou()
cm_time += time.time() - cm_start_time
print(f"mIoU {valid_split}: {miou['all']}")
validation_time = time.time() - validation_start_time
# save the confusion matrices of this epoch.
# This helps if we want to compute other metrics later.
with open(os.path.join(ckpt_dir, 'confusion_matrices',
f'cm_epoch_{epoch}.pickle'), 'wb') as f:
pickle.dump({k: cm.overall_confusion_matrix
for k, cm in confusion_matrices.items()}, f,
protocol=pickle.HIGHEST_PROTOCOL)
# logs for the csv logger and the web logger
logs[f'loss_{valid_split}'] = \
loss_function_valid.compute_whole_loss()
if loss_function_valid_unweighted is not None:
logs[f'loss_{valid_split}_unweighted'] = \
loss_function_valid_unweighted.compute_whole_loss()
logs[f'mIoU_{valid_split}'] = miou['all']
for camera in cameras:
logs[f'mIoU_{valid_split}_{camera}'] = miou[camera]
logs['time_validation'] = validation_time
logs['time_confusion_matrix'] = cm_time
logs['time_forward'] = forward_time
logs['time_post_processing'] = post_processing_time
logs['time_copy_to_gpu'] = copy_to_gpu_time
# write iou value of every class to logs
for i, iou_value in enumerate(ious['all']):
logs[f'IoU_{valid_split}_class_{i}'] = iou_value
return miou, logs
1:首先获得验证集的数据集文件。在valid loader的’val’文件夹下。
2:计算各种时间,前向传播时间,复制到GPU时间等。
3:设置模型为eval格式。
4:定义miou和iou为空字典。
5:重置损失。
5.1:首先定义验证损失为:
loss_function_valid_unweighted = \
utils.CrossEntropyLoss2dForValidDataUnweighted(device=device)
5.2:在utils文件中:
class CrossEntropyLoss2dForValidDataUnweighted:
def __init__(self, device):
super(CrossEntropyLoss2dForValidDataUnweighted, self).__init__()
self.ce_loss = nn.CrossEntropyLoss(
weight=None,
reduction='sum',
ignore_index=-1
)
self.ce_loss.to(device)
self.nr_pixels = 0
self.total_loss = 0
def add_loss_of_batch(self, inputs, targets):
targets_m = targets.clone()
targets_m -= 1
loss = self.ce_loss(inputs, targets_m.long())
self.total_loss += loss
self.nr_pixels += torch.sum(targets_m >= 0) # only non void pixels
def compute_whole_loss(self):
return self.total_loss.cpu().numpy().item() / self.nr_pixels.cpu().numpy().item()
def reset_loss(self):
self.total_loss = 0
self.nr_pixels = 0
5.2.1:将输入和target计算交叉熵损失,计算总的像素数目,进行累加。
5.2.2:whole_loss返回总损失除以总像素数目。
5.2.3:reset_loss即将总损失和像素数目置0.
6:遍历valid_loader,
6.1:首先清空缓存
6.2:获取image和depth,通过sample[‘key’]取值,由__getitem__方法获得。
6.3:将image和depth输入到model中,获得模型的输出,即前向传播,并计算前向传播时间。
6.4:计算验证损失,
6.4.1:将输出和标签共同输入到CrossEntropyLoss2dForValidDataUnweighted类的add_loss_of_batch函数下。计算损失。验证集的损失不参与反向传播,否则就是train了。
6.5:获得标签label。将输出上采样到原图大小。
6.6:通过torch.argmax沿着通道维度获得最大值的索引。
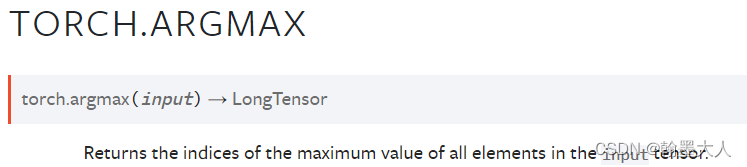
6.6.1:忽略掉小于0的像素(label的类别就是对应的像素值)。
通过比较返回一个布尔矩阵。
比如:
tensor([[False, False, False, False],
[False, True, True, True],
[False, False, False, True]])
6.6.2:通过torch.masked_select函数,选择label中大于0的像素点。
将mask矩阵覆盖到label上,只选择true对应的像素点。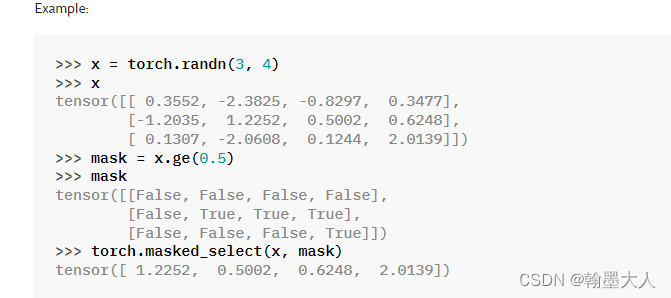
同理对经过argmax之后的predict也进行选择。predict是一个1D的HxW矩阵,每一个点都是一个索引,进过select之后会将0索引过滤掉。0对应的是背景。
6.6.3:标签中0是空,但是预测中0是墙,所以将标签减1.标签的1减去1变为0,和预测的0就对应起来了。
7:将预测和标签都转换为numpy格式,计算混淆矩阵。根据混淆矩阵再计算miou和iou。















 2964
2964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









