







- 在流转换为表时,如果使用了事件时间,那么水位线以及时间戳提取一定要在Stream中定义
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//设置并行度等于1,默认的并行度取得是当前计算机CPU核心数
//事件时间策略 一定要在流数据中定义好
SingleOutputStreamOperator<Event> operator = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.getTimeStamp();
}
})
);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
- sql parser Exception encounter table xxxxx
此异常大概率为sql字符串错误,需要检查sql中关键字之间是否缺少空格。
- 关键字异常
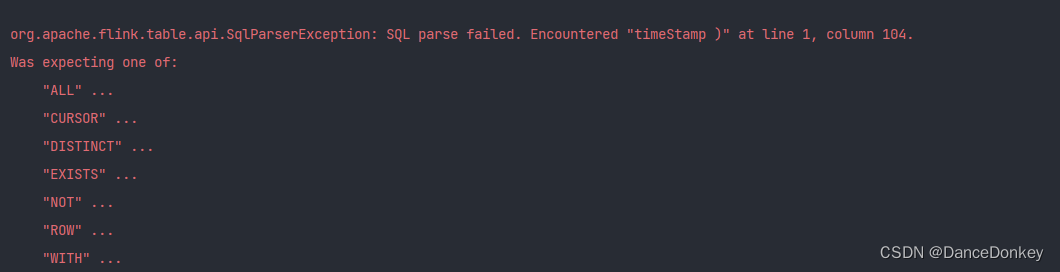
如果在sql中使用了一些关键字以及函数,也会抛出异常,例如timeStamp,table,select等,所以在编写时 一定要避开sql中自带的关键字信息。
- org.apache.flink.table.api.ValidationException: Field reference expression expected.
这个报错是字段引用错误,往往出现在给字段取别名时出现,如果为一个字段指定了事件属性又起了别名,则一定要先指定属性再起别名。
错误写法:
$("timeStamp").as("ts").rowtime()
正确写法:
$("timeStamp").rowtime().as("ts")
- org.apache.flink.table.api.ValidationException: SQL validation failed. From line 1, column 82 to line 1, column 91: Object ‘clickTable’ not found
此报错为没有将Table注册到表环境中,在直接引用到sql字符中会抛出此异常
将表注册到表环境中
tableEnv.createTemporaryView("clickTable",clickTable);
- 如果使用了row_number() 函数,则必须在where条件中使用条件判断来以保证结果有界。
错误写法:
SELECT ...
FROM (
SELECT ...,
ROW_NUMBER() OVER (
[PARTITION BY <字段 1>[, <字段 1>...]]
ORDER BY <排序字段 1> [asc|desc][, <排序字段 2> [asc|desc]...]
) AS row_num
FROM ...)
正确写法:
SELECT ...
FROM (
SELECT ...,
342
ROW_NUMBER() OVER (
[PARTITION BY <字段 1>[, <字段 1>...]]
ORDER BY <排序字段 1> [asc|desc][, <排序字段 2> [asc|desc]...]
) AS row_num
FROM ...)
WHERE row_num <= N [AND <其它条件>]















 1307
1307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









