






我使用的是anaconda下的scrapy库进行的爬取,具体安装过程百度之。
创建项目过程(对我这样的小白才看的步骤):
1.在想创建项目的文件夹下 按住 SHIFT 后—>点击鼠标右键——>点击在此处打开Powershell窗口
2.输入 scrapy startproject 项目名,我使用的命令是 scrapy startproject car,此处就创建一个car的文件夹

3.点击car->再点击car->点击spiders,进入此文件夹后可按 1 步骤再开一个dos窗口
输入 scrapy genspider 名字 网址名(网址需为www开头,不需要http://,若加http://爬取时有的地方会报错)
我使用的命令是 scrapy genspider car_spider www.toutiao.com,创建的py文件如下

重点来了!!!
由于头条网页使用AJAX写的,头条的爬取不能直接解析原网址,需解析api(https://www.toutiao.com/api/search/content/?offset=0&keyword=汽车)下的接口。
观察此接口下的offset在改变,从0-80。
查看方法:我用的QQ浏览器,点击F12出现下面东西

选择Network -》 选择preview 即可查看下截图

首页image的url位于data下每一小项的large_image_ur下,下两张图片拼接看可得出url位置。
查看方法如上。


知道这些就可以写程序了。
使用spyder编译器对car_spider.py文件进行编辑
import scrapy
from car.items import carItem
from urllib.parse import urlencode
import json
class CarSpiderSpider(scrapy.Spider):
# 7,8行是创建之后自带的
name = "car_spider"
allowed_domains = ['www.toutiao.com']
# 开始的url
start_urls=['https://www.toutiao.com/api/search/content/?offset=0&keyword=汽车']
def parse(self,response):
contents = json.loads(response.text)
if contents:
dates = contents.get('data')#得到字典里的data值
if not(dates is None):
for date in dates:
large_image_url = date.get('large_image_url')
# if not(large_image_list is None):#有的没有image_list段,跳过
# for image in large_image_list:#image_list中的值不为一个,循环
if not(large_image_url is None):
# print(large_image_url)
## print(image_url)
it = carItem()
it['src']=[large_image_url]
yield it
# 返回当前url,获取offect后的值,进行字符拼接后抓取下一页
url = response.url
d = int(url.split("=")[1].split("&")[0])+20
params = {
'autoload': 'true',
'count': '20',
'en_qc': '1',
'cur_tab': '1',
'from': 'search_tab',
'pd': 'synthesis',
'timestamp': '1563782026489'
}
next_url = 'https://www.toutiao.com/api/search/content/?offset={0}&keyword=汽车'.format(d)+ urlencode(params)
if d <= 80:
try:
yield scrapy.Request(next_url,callback=self.parse,dont_filter=True)
except:
pass
编辑items.py文件
import scrapy
class CarItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class carItem(scrapy.Item):
# 在car_spider.py文件中会引用
src=scrapy.Field()
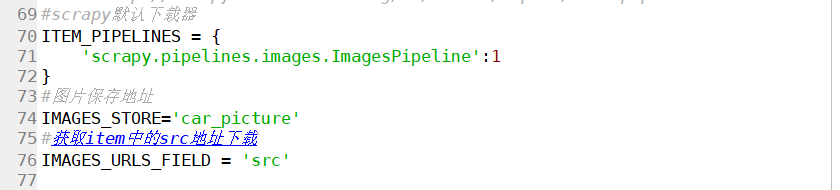
设置setting.py(在文件70行左右添加)
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline':1
}
#图片保存地址
IMAGES_STORE='car_picture'
#获取item中的src地址下载
IMAGES_URLS_FIELD = 'src'
示例:
再次在spider文件夹下打开 Powershell窗口,输入 scrapy crawl car_spider(这个名字必须是car_spider.py文件里的name,否则报错)即可进行爬取
若无报错则爬取成功。
爬取:

爬取成功:

简简单单实现此操作,没有对图片的改名操作,可使用自己编译的下载器对文件进行改名和更改下载位置。
我也是小白,写的不对的可以给留言呀,感谢观看。
运行时好像有少量报错,懒得调了,能爬取出图片来就可以了。















 1052
1052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









