



目录
完成虚拟机环境(网络配置、免密登录、JDK 安装)后,下一步确实可以开始搭建 Hadoop 集群了。Hadoop 集群的搭建、部署与管理需要按步骤推进,以下是详细流程和关键操作,帮助你顺利完成.
一、前期准备确认(避免后续踩坑)
在正式安装 Hadoop 前,先检查以下配置是否到位(三台虚拟机node1、node2、node3均需确认):
1.网络与主机名
确保三台虚拟机的 IP 固定(如通过/etc/sysconfig/network-scripts/ifcfg-eth0配置静态 IP),且互相能 ping 通。
主机名与 IP 映射正确:/etc/hosts文件中需包含三台机器的 IP 和主机名,例如:
192.168.56.101 node1
192.168.56.102 node2
192.168.56.103 node3
关闭防火墙(或开放 Hadoop 所需端口,新手建议直接关闭):
systemctl stop firewalld # 临时关闭
systemctl disable firewalld # 永久关闭
2.JDK 环境
确认java -version能正常输出版本(推荐 JDK 8,Hadoop 3.x 兼容较好)。
环境变量JAVA_HOME已配置(在/etc/profile或~/.bashrc中),且三台机器一致。
3.免密登录
确保node1(建议作为主节点)能免密登录到node2、node3,同时节点间也能互相免密(ssh node2测试是否无需输入密码)。
二、Hadoop 集群搭建步骤
Hadoop 集群通常包含1 个主节点(NameNode/ResourceManager) 和2 个从节点(DataNode/NodeManager),这里建议:
node1:主节点(NameNode + ResourceManager)
node2、node3:从节点(DataNode + NodeManager)
步骤 1:下载并解压 Hadoop
选择 Hadoop 版本(推荐 3.x,如 3.3.4),在node1上下载:
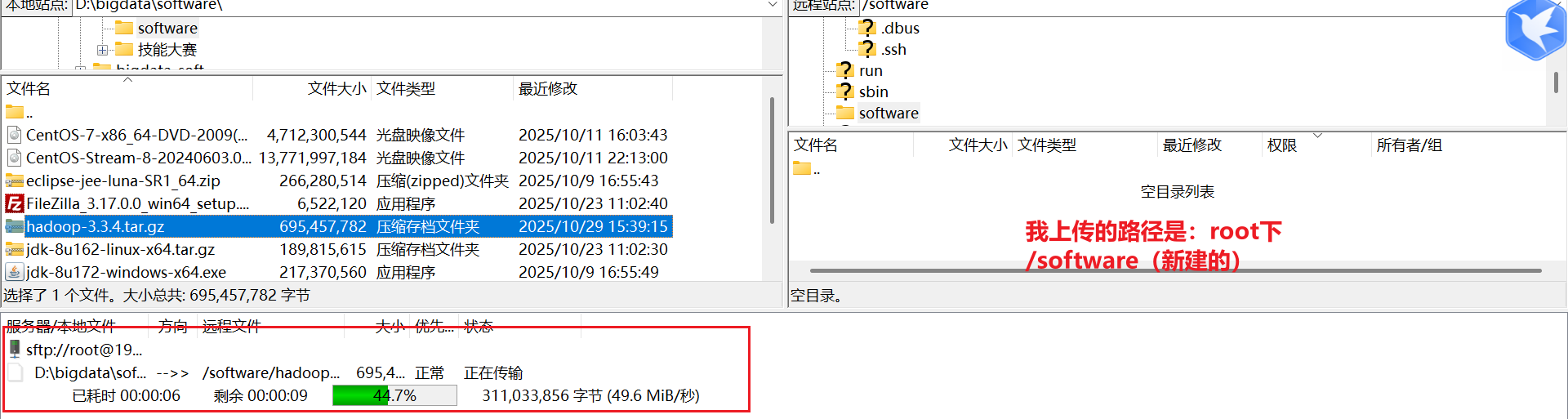
# 下面下载超级慢,建议直接迅雷下载到本地,如何通过FileZilla上传到虚拟机
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
解压到指定目录(如/opt/module,需先创建目录):
mkdir -p /opt/module
tar -zxvf hadoop-3.3.4.tar.gz -C /opt/module/
重命名(可选,方便操作):
mv /opt/module/hadoop-3.3.4 /opt/module/hadoop
步骤 2:配置 Hadoop 环境变量
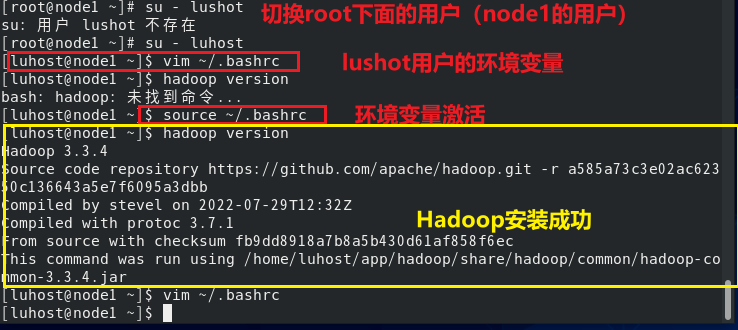
root下面的系统配置文件:/etc/profile root下面用户的配置文件~ /.bashrc 我们配置的jdk环境变量,以及hadoop集群配置的环境变量都推荐在各自用户下面的环境变量进行配置vim ~/.bashrc。当然在root下面的/etc/profile下面配置也能在用户中生效,但是不建议。
!!!按照上述配置的jdk hadoop在用户root下是不能够使用的!!!
在node1用户下面的个人环境变量文件(.bashrc)中添加 Hadoop 路径(三台机器最终都需要,后续可通过 scp 同步):
vim ~/.bashrc
# 添加以下内容
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
生效配置:
source /etc/profile
验证:hadoop version 能输出版本信息即成功。
步骤 3:修改 Hadoop 核心配置文件
Hadoop 配置文件位于$HADOOP_HOME/etc/hadoop/,需修改以下关键文件(仅在node1上先配置,后续同步到从节点):
(TODO) 遇到的问题是filezilla登录的是root用户才能上传文件,(不知道登录root下面的hadoop用户能不能也可以上传)另外因为是用的root用户,宿所以解压的时候用的也是root,下面的用户没有解压的权力,导致在修改配置文件的时候,用户也不能修改,如何解决(1.将文件上传至用户下面,2.修改用户对配置文件的读写操作)
1.hadoop-env.sh(指定 JDK 路径)
vi hadoop-env.sh
# 添加JDK路径(与系统JAVA_HOME一致)
export JAVA_HOME=/path/to/yours/jdk1.8.0 # 替换为你的JDK实际路径
2.core-site.xml(核心配置,指定 NameNode 地址和临时目录)
在修改HDFS 配置文件之前先在path/to/hadoop下面创建下面文件夹data
<configuration>
<!-- 指定NameNode的地址(主节点node1) -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<!-- Hadoop临时目录(需提前创建,如/opt/module/hadoop/data) -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data</value>
</property>
</configuration>
3.hdfs-site.xml(HDFS 配置,指定副本数和 NameNode/DataNode 数据目录)
在修改HDFS 配置文件之前先在path/to/hadoop/data/下面创建下面两个文件夹
- NameNode数据存储目录:/opt/module/hadoop/data/namenode
- DataNode数据存储目录:/opt/module/hadoop/data/datanode
<configuration>
<!-- 副本数量(建议与从节点数一致,这里2个) -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- NameNode数据存储目录(需要提前创建) -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop/data/namenode</value>
</property>
<!-- DataNode数据存储目录(需要提前创建) -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/module/hadoop/data/datanode</value>
</property>
<!-- 允许在WebUI上删除文件(可选) -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
要将三台虚拟机(假设主机名分别为 node1、node2、node3)都设置为 DataNode 节点,无需修改 hdfs-site.xml,而是通过 workers 配置文件(旧版本叫 slaves)指定所有 DataNode 节点的主机名。(见下面的6)
4.mapred-site.xml(MapReduce 配置,指定 YARN 为资源管理器)
<configuration>
<!-- 指定MapReduce运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.yarn-site.xml(YARN 配置,指定 ResourceManager 地址和节点管理器)
<configuration>
<!-- 指定ResourceManager的地址(主节点node1) -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!-- NodeManager上运行的附属服务(需与MapReduce配合) -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
6.workers(指定从节点,Hadoop 3.x 用workers,2.x 用slaves)
workers 文件默认存在于 $HADOOP_HOME/etc/hadoop/ 目录,无需手动创建,直接执行命令。
vi workers
# 清空默认内容,添加从节点主机名
node1(三个全部作为datanode节点,若不需要,则删除即可)
node2
node3
步骤 4:同步配置到从节点
将node1上配置好的 Hadoop 目录和环境变量同步到node2和node3:
1.同步 Hadoop 安装目录:
# 若提示请求被拒绝,说明node1的权限不够,可以在命令之前加一个sudo 然后按照提示输入root的密码。
scp -r /opt/module/hadoop node2:/opt/module/
scp -r /opt/module/hadoop node3:/opt/module/

2.同步环境变量配置(/etc/profile):
若在步骤 2:配置 Hadoop 环境变量是按照步骤2进行的则执行item 1。若是在root下面的/etc/profile里面配置的则执行item 2
~(波浪线)在 Linux 中是 当前用户家目录 的快捷符号,其对应的实际路径由用户的 home 目录决定:
luhost 用户的家目录默认是 /home/luhost(Linux 普通用户家目录统一存放在 /home/ 下,以用户名命名);
因此 ~/.bashrc 等价于 /home/luhost/.bashrc(. 开头的文件是隐藏文件,需用 ls -a 才能查看)
# item 1. ~/.bashrc == /home/luhost/.bashrc
scp /home/luhost/.bashrc node2:/home/luhost
scp /home/luhost/.bashrc node3:/home/luhost
或者
scp ~/.bashrc node2:/home/luhost
scp ~/.bashrc node3:/home/luhost
# item 2.
scp /etc/profile node2:/etc/
scp /etc/profile node3:/etc/
3.环境变量生效
在node2和node3上分别执行 item 1或者 item 2:
# item 1
source ~/.bashrc生效环境变量
# item 2
source /etc/profile
步骤 5:格式化 NameNode(仅首次执行)
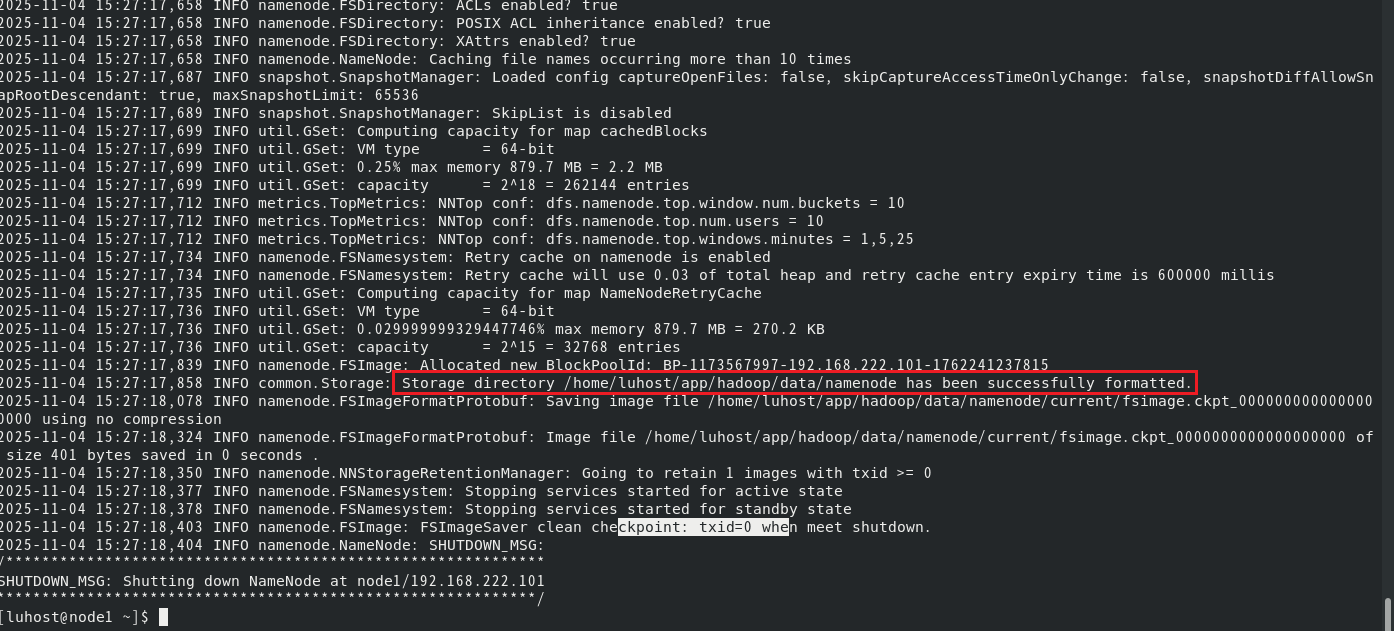
在主节点 node1上执行格式化(格式化会清空 HDFS 数据,仅第一次搭建时运行):
hdfs namenode -format
出现successfully formatted提示即成功。
步骤 6:启动 Hadoop 集群
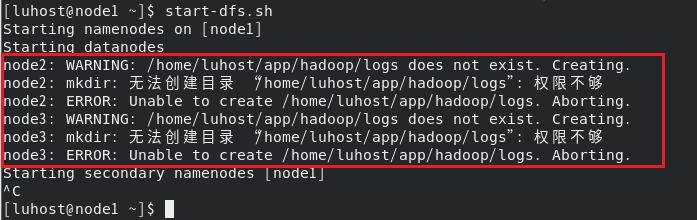
1.启动 HDFS(在 node1 上):
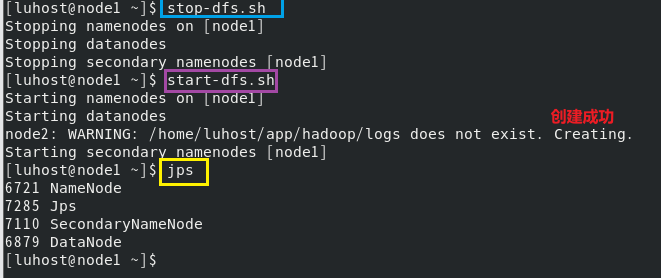
start-dfs.sh
启动后,jps命令查看进程:
node1 应包含:NameNode、SecondaryNameNode
node2、node3 应包含:DataNode
1.1 启动出错
当前 luhost 用户在 node2 和 node3 上对 /home/luhost/app/hadoop 目录没有足够的写入权限,导致创建日志目录失败,如下:
1.1.1. 分别登录 node2 和 node3 节点,修改目录权限
在 node2 上执行:
# 登录 node2
ssh node2
# 赋予 hadoop 安装目录的所有者权限(确保 luhost 是目录的所有者)
sudo chown -R luhost:luhost /home/luhost/app/hadoop
# 赋予目录读写执行权限(递归应用到子目录)
sudo chmod -R 755 /home/luhost/app/hadoop
# 登录 node3
ssh node3
# 赋予 hadoop 安装目录的所有者权限(确保 luhost 是目录的所有者)
sudo chown -R luhost:luhost /home/luhost/app/hadoop
# 赋予目录读写执行权限(递归应用到子目录)
sudo chmod -R 755 /home/luhost/app/hadoop
1.1.2 2. (可选)手动创建日志目录(如果权限修改后仍有问题)
在 node2 和 node3 上分别执行:
sudo mkdir -p /home/luhost/app/hadoop/logs
sudo chmod 755 /home/luhost/app/hadoop/logs
1.1.3x先停止HDFS再重新启动 HDFS
回到 node1 节点,重新执行启动命令:
stop-dfs.sh -> start-dfs.sh
2.启动 YARN(在 node1 上):
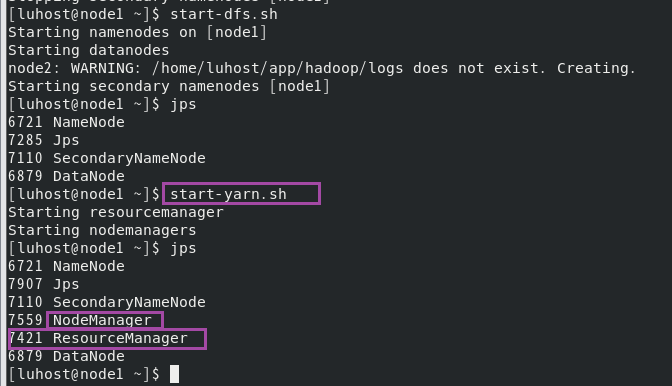
start-yarn.sh
启动后,jps查看进程:
node1 应包含:ResourceManager
node2、node3 应包含:NodeManager
三、验证集群是否正常运行
-
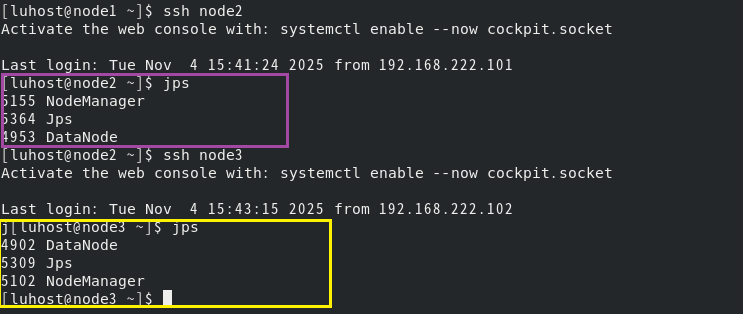
进程验证:三台机器执行jps,确保上述进程均正常启动(无缺失)。
-
切换node2&node3:
-
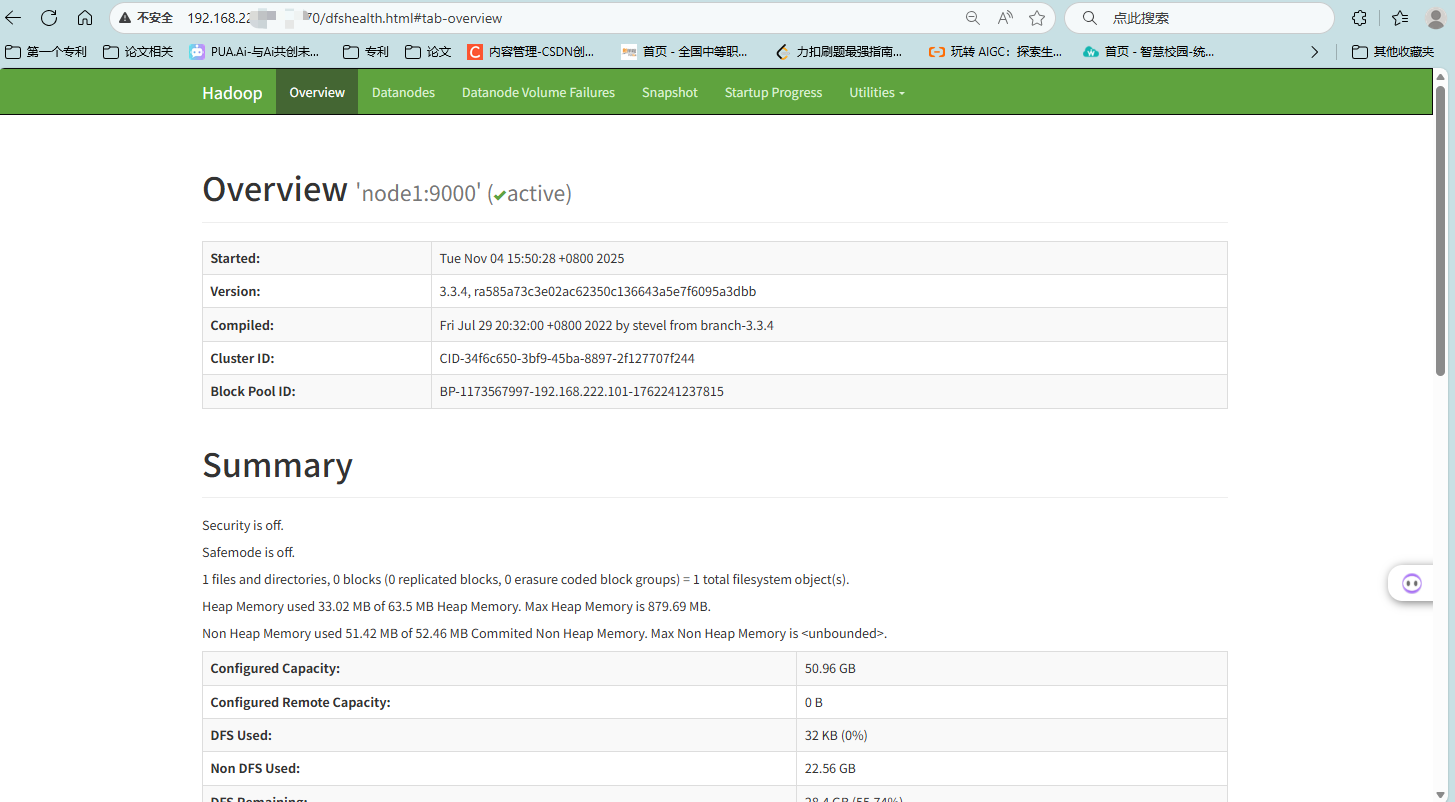
WebUI 验证:HDFS WebUI:访问http://node1的IP:9870,在Datanodes页面可看到 node2 和 node3。
-
YARN WebUI:访问http://node1的IP:8088,在Nodes页面可看到两个从节点。

-
功能测试:
- 创建 HDFS 目录:hdfs dfs -mkdir /test
- 上传文件:hdfs dfs -put /etc/profile /test
- 查看文件:hdfs dfs -ls /test

四、集群管理与日常操作
- 启停命令:
- 单独启停 HDFS:start-dfs.sh / stop-dfs.sh
- List item 单独启停 YARN:start-yarn.sh / stop-yarn.sh
- 启停所有服务:start-all.sh / stop-all.sh(不推荐生产环境,建议分开启停)
- 日志查看:Hadoop 日志默认在$HADOOP_HOME/logs/,启动失败时可查看对应进程的日志(如hadoop-root-namenode-node1.log)。
- 动态添加节点:后续如需扩展集群,只需新增虚拟机,配置免密和 JDK,同步 Hadoop 配置,修改workers文件,重启 YARN 即可。
如果在某个步骤遇到问题(如进程启动失败、WebUI 无法访问),可以重点检查配置文件的主机名、路径是否正确,以及日志中的错误信息。需要
五、出错的原因:
- 1.要根据错误的提示信息,找到对应的配置文件,提示中会写明hadoop-env.sh文件或core-site.xml文件或hdfs-site.xml文件…
- 2.注释部分格式不正确
比如:xml文件注释部分的正确格式:<!-- #备注的东西 -->。
错误:多了或者少了一个<or>,单词拼写错误… -
- 后续补充…


















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









