






 ImageBind是一种利用图像模态建立多模态联合嵌入空间的方法,能在不需所有模态配对数据的情况下实现模态间的对齐。通过Transformer架构编码不同模态数据,如图像、文本、音频等,训练后能展现出新兴的零样本(Emergentzero-shot)能力,进行未见过的模态对齐任务。实验表明,ImageBind在音频和文本的检索、分类任务中表现出色,且具有良好的泛化性能。
ImageBind是一种利用图像模态建立多模态联合嵌入空间的方法,能在不需所有模态配对数据的情况下实现模态间的对齐。通过Transformer架构编码不同模态数据,如图像、文本、音频等,训练后能展现出新兴的零样本(Emergentzero-shot)能力,进行未见过的模态对齐任务。实验表明,ImageBind在音频和文本的检索、分类任务中表现出色,且具有良好的泛化性能。
1. 本文方法
本篇文章提出了对六种模态(图像、文本、音频、depth、thermal、IMU)建立一个联合嵌入空间的方法——ImageBind,该方法的亮点在于利用了图像的捆绑属性,以图像模态为桥梁,构建起两两模态之间的联系。
模型在训练的时候,只需用到配对的(I,M)数据,I指图像模态数据,M指剩下其他五个模态数据中的任意一个模态数据,也就是说只需要用到五种模态配对数据即可达到下图两两模态相互对齐的效果。模型训练好之后,已对齐的模态数据对之间的zero-shot能力能够迁移到新的模态数据对上(比如(I,M_1)对齐,(I,M_2)对齐,训练好的模型会出现(M_1,M_2)对齐的行为,这意味着不需要使用配对的(M_1,M_2)数据来训练模型就能够执行M_1和M_2模态上的zero-shot任务。本文将这种模型在没有看到过的两个模态对齐所新产生的zero-shot能力成为Emergent zero-shot,以此来区分CLIP和Audio CLIP中的zero-shot。)。后续通过实验验证ImageBind强大的Emergenet zero-shot能力。
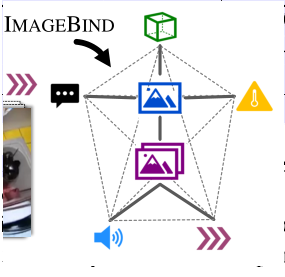
Naturally Aligned表示训练所用的对齐数据;Emergent Alignment表示模型训练后,新出现的对齐关系。
2. 方法实现
该方法的目标是使用图像模态将所有模态信息绑定在一起,学习一个单一的联合嵌入空间,将每一种模态嵌入和图像模态嵌入对齐。最终得到的结果嵌入空间会出现一种新的行为,该行为自动将没有在训练数据中出现的模态对联系起来。如下图所示:

2.1 编码实现
所有模态编码器均使用Transformer架构。文本编码器使用CLIP模型的文本编码器。图像模态使用Vision Transformer模型。音频转换为频谱图,使用ViT进行编码。热图像、深度图像可以看作为只有一个通道的图像,也使用ViT模型进行编码。IMU数据使用Transformer模型进行编码。因此一共有六种编码器(图像和视频使用相同的编码器)。每一个编码器上加入一个特定的线性映射头,获得一个固定大小的d为嵌入向量,嵌入向量用到InfoNCE损失函数中。(所有模态都使用transformer编码器的设置可以允许某些模态的编码器使用预训练模型的编码器来进行初始化,比如说使用CLIP模型和OpenCLIP模型的图像、文本编码器。)
I指文本模态,M指其他模态,给一张图片和其对应的模态数据
f和g是深度神经网络,使用InfoNCE损失函数进行优化
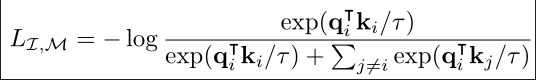
3. 实验
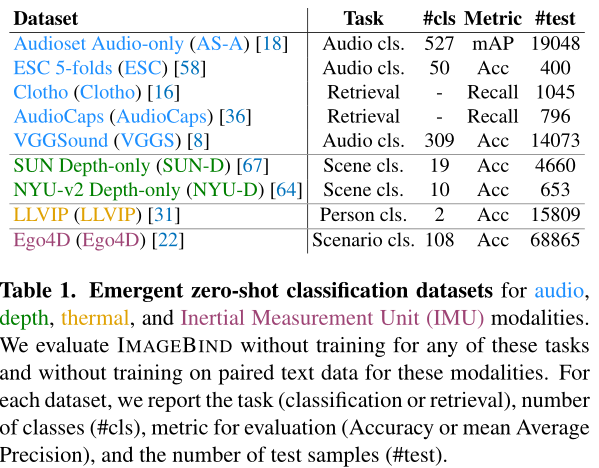
3.1 训练用到的数据集
larget-scale web data(image,text)
Audioset(video,audio)
SUN RGB-D(image,depth)
LLVIP(image,thermal)
Ego4D(video,IMU)
本文实验中用是OpenCLIP模型中的图像和文本编码器。audio模态使用ViT-B,thermal和depth模态使用ViT-S,IMU数据使用普通的Transformer编码器。在训练的过程中,图像和文本编码器参数固定,训练其他模态的编码器和线性映射器。
评估ImageBind方法所用到的数据集:
3.2 Emergent zero-shot classification
使用文本模态数据(即text prompt templates)来评估ImageBind新出现的文本模态到其他模态数据的zero-shot分类能力。实验结果如下图所示,每一个任务衡量了ImageBind将文本模态和其他模态数据联系起来的能力。

3.3 Comparison to prior work
(1)zero-shot的文本到音频的检索和分类任务
与ImageBind不同,先前的工作使用配对的文本和音频训练模型,如AudioCLIP和AVFIC。将AudoCLIP和AVFIC模型的zero-shot能力和ImageBind的zero-shot能力进行比较。比较结果如下图所示:
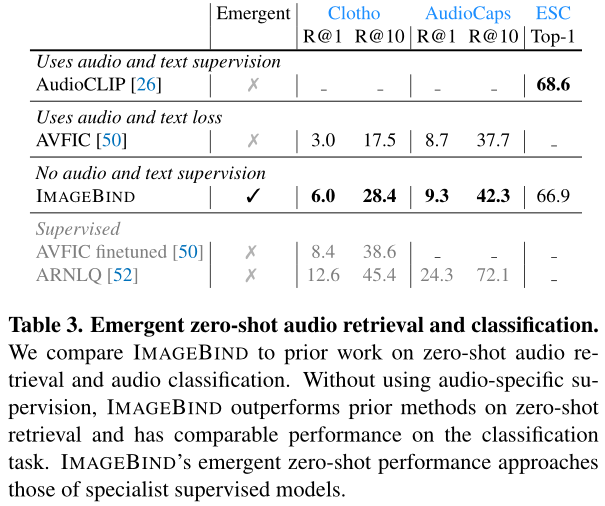
在zero-shot检索任务上,没有使用(text,audio)数据进行训练的ImageBind效果优于AVFIC模型。与监督的AudioCLIP模型相比,ImageBind取得了可以比较的性能。三个数据集上的强大表现验证了ImageBind使用图像模态作为中间桥梁对齐文本数据和音频数据方法的有效性。
(2)文本到音频和视频的检索
实验结果如下所示:
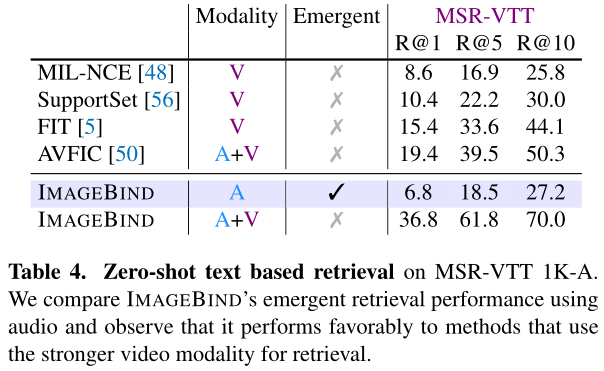
ImageBind中,使用text检索音频的性能好于MIL-NCE视频检索的性能。将音频特征和视频特征结合起来作为检索的目标模态,提升了ImageBind的性能,表现出ImageBind学习到的特征的实用性。
3.4 few-shot分类实验
本小节实验使用ImageBind中的audio编码器和depth编码器评估few-shot性能。对于≥1-shot的实验,训练线性分类器。比较模型为在Audioset数据集上的自监督AudioMAE模型和在音频分类任务中微调的监督AudioMAE模型。两个基线使用和ImageBind相同大小的ViT-B音频编码器。实验结果如下所示:

在≤4 shots的设置之前,ImageBind的性能优于AudioMAE 40%左右;≥1 shot设置之后,imageBind性能优于或者是匹配Supervised的性能。
对于few-shot的depth分类任务,比较模型为在图像,深度和语义分割数据上训练的MultiMAE ViT-B/16。从右图可以看到,在所有的设置中,ImageBind的性能优于MultiMAE。
上述在ImageBind两个编码器上的实验,显示了使用图像作为中间桥梁沟通其他模态的方式所训练出来的模型,其得到的audio和depth特征具有强大的泛化性能。
3.5 该方法带来的优势
(1)可以对不同的模态信息进行组合,下图显示了将图像和音频信息结合在一起的图像检索任务,这意味着在ImageBind的嵌入空间中可以进行不同模态特征的组合,合成来自不同模态的语义内容,实现丰富多样的合成任务。

(2)不需要重新更新,现有视觉模型可直接使用ImageBind其他模态的编码器
Detic,一个预训练的基于文本的检测模型,将文本嵌入替换成ImageBind的音频嵌入,无须重新训练,Detic就能够变为基于音频检测的模型。实验结果如下图所示:

将DALL-2中的文本嵌入替换为音频嵌入,不需要重新训练,DALL-2就变为了基于音频的扩散模型,可以根据音频生成相应的图像。实验结果如下图所示:

3.6 消融实验
文中进行了各种各样的消融实验,如变换图像编码器的大小,变换对比损失函数的超参数,将线性映射头更改为MLP,变换训练epoch数量,是否对图像采用数据增强等方面,探究影响ImageBind性能的因素。
4. 总结
正如作者在最后一节所说的那样,ImageBind是一种简单的方法,没有用到复杂高深的技术,该方法所用的模型都为transformer模型,除了IMU模态数据之外,其他模态数据所用的编码器都是Vision Transformer模型,在训练的时候直接可以加载过来预训练好的Vision Transformer模型。
ImageBind的巧妙之处在于利用了图像的捆绑性,即许多模态的信息和图像模态可以产生联系,利用图像模态作为连接各个模态之间的桥梁,从而达到训练数据涉及的模态两两联系的效果(模态联系图成为一个两两联系的无向完全图)。正因为训练之后的模型使得每两个模态之间产生了联系,所以在未见过的模态对数据集上可以达到好的性能效果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









