







proc sort排序
基本格式:
proc sort data=<dataset> (out=<newset>) (nodupkey);
by (descending) <varname1> (descending) <varname2>……;
run;
proc sort过程将数据集dataset按照varname的值进行升序或者降序,输出为数据集newset,关键词nodupkey表示去掉重复值(需要注意的是,nodupkey根据by变量剔重);
by语句是指按照varname1进行排序,值相同时按照varname2进行排序,以此类推;
descending即降序排列,默认ascending升序;
补充
关键词nodupkey
关键词nodupkey表示删除具有相同by变量的观测,若指定dupout=选项,则sas将删除的观测输出到指定的数据集中
proc sort data=a out=b nodupkey dupout=c;
by name age;
run;
该proc步表示将数据集a按照姓名和年龄排序,并删除具有相同姓名和年龄的观测,把未删除且排序后的数据集输出到数据集b中,把删除的观测输出到数据集c中。
更改字符数据的排序顺序
z/OS 操作环境默认的排序序列是EBCDIC,其他大多数操作环境的默认排序序列是ASCII。字符数据从低到高的基本排序顺序为:
| 排序序列 | ||||
|---|---|---|---|---|
| ASCII | 空格 | 数字 | 大写字母 | 小写字母 |
| EBCDIC | 空格 | 小写字母 | 大写字母 | 数字 |
语义排序
默认情况下,大小写字母是分开排序的(如上表所示)。若想生成更直观的排序,可以使用“SORTSEQ=LINGUISTIC”选项带有的“STRENGTH=PRIMARY”子选项,可忽略大小写。
proc sort data=a out=b
sortseq=linguistic(strength=primary);
当对字符数据中的数字进行排序时,默认情况下“10”会在“2”的前面,可以使用子选项“NUMERIC_COLLATION=0N”,将数字等同于数值进行排序处理。
proc sort data=a out=b
sortseq=linguistic(numeric_collation=on);
proc transpose转置
长表转宽表,基本格式
proc transpose data=<dataset> (out=<newset> name=<name> label=<label>);
by <by1> <by2>……;
var <var>;
id <id>;
idlabel <idlabel>;
run;
name:用来定义var的新变量 的变量名(显示在表格中);
label:用来定义var的标签的新变量 的变量名(显示在表格中);
id:即取id中的值 生成新的变量(显示在表格中);
idlabel:即取idlabel中的值 生成新变量的标签(不显示在表格中);
var:var的值作为 id中的值生成新变量 的值(显示在表格中)
by:被保留的变量,控制变量的先后顺序,变量需要提前被sort,notsorted 指允许不排序;
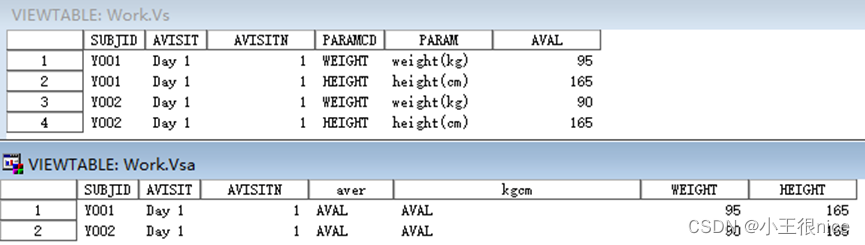
/*长表vs转宽表vsa */
proc sort data=vs;
by subjid avisit avisitn;
run;
proc transpose data=vs out=vsa name=a label=b;
/*out指定输出数据集,若无指定,自动将转制后的数据集命名为data1、data2...不会覆盖原有数据集*/
/*name,label 存储 var 变量值的变量名和标签*/
by subjid avisit avisitn; /*仍然需要保留为变量,包含在转置数据集中,但他们本身并不转置*/
var aval; /*需要转置其值的变量 <var>的变量值会成为Id语句生成的新变量的值; 在转置后的数据集中作为值的变量*/
id paramcd; /*ID变量的值会变成新变量名;转置后按照值生成多个变量的变量*/
idlabel param; /*idlabel变量的值会变成新变量的标签*/
run;
宽表转长表,基本格式
proc transpose data=<dataset> out=<newset> prefix=<prefix> name=<name> label=<label>);
by <by1> <by2>……;
var <var1> <var2>……;
run;
prefix:为var1、var2的值指定新的变量名前缀;
name:为存储var1、var2变量名的新变量;
by:by1、by2变量可复制成多条观测,需要提前sort(注意,sort的by语句的变量是哪些,此处的变量就是哪些);
var:var1、var2指定需要转变的变量名
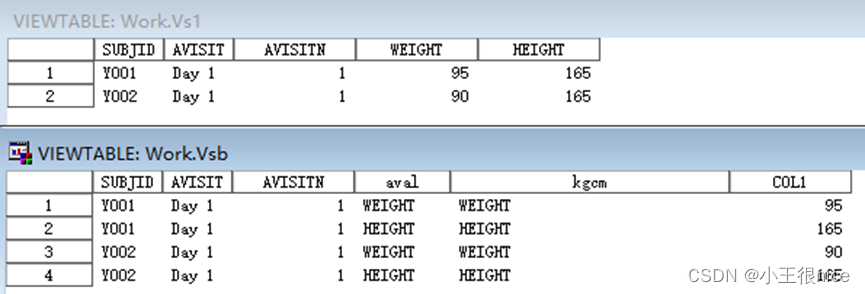
/*宽表vs1转长表*vsb/
proc sort data=vs1;
by subjid avisitn avisit;
run;
proc transpose data=vs1 out=vsb /*prefix=st*/ name=param label=paramcd; /*Name: <name>为存储<var1> <var2>变量名的新变量*/
by subjid avisitn avisit;
var weight height; /*由变量变为观测值,其变量下的值转置,由宽转长*/
run;















 864
864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









