







1.前言
本人大学期间自学了Python后,但是又因不是大数据相关专业,并且没有计划从事Python相关方向,之后就几乎没有怎么使用过Python了。今天,有同事问我怎么批量从Excel某一列字符串中提取中文。以前我都是百度Excel使用技巧或者函数之类的,但是这次没有很好的解决方案,都是说用TEXTJOIN(,,(IF(LENB(MID(A1,ROW(A1:A100),1))=2,MID(A1,ROW(A1:A100),1),"")))函数的,本人测试后发现效果并不好,而且只能wps使用。
由于office全家桶并不熟练,所以只能放弃。后来转念一想,能不能通过自己比较熟悉的方法来解决呢?没错,代码和函数!Python简洁又有强大的生态,是个好用的生产力工具。于是,我就想到用Python来处理Excel。
本篇只是简单记录win32com对Excel的读、改和遍历操作,这些操作可以应对基本的Excel操作。
2.关于Excel
首先,我们要操作Excel表格得清晰它的基本结构。Excel表格文档(wps的表格也是一样的)由单元格和sheet工作表三部分组成。
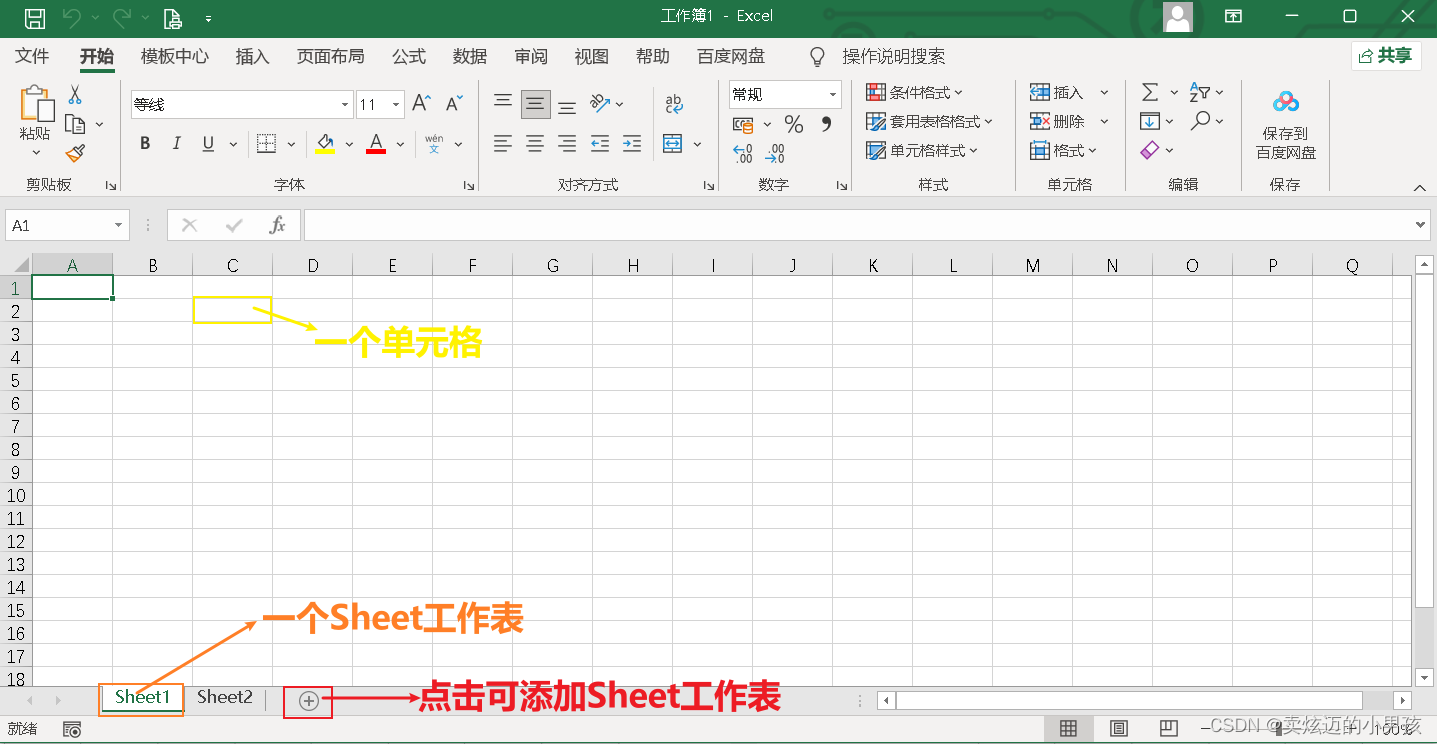
可能很多人,没有注意过Sheet工作表。一个Excel文档可由多个Sheet工作表组成。
然后还要知道的一点就是Excel的文件后缀有.xls和.xlsx两种。.xls是excel2003版本以前的格式,.xlsx是excel2007以后的版本,.xlsx是.xls的升级版本,更高效,而且.xlsx向下兼容.xls格式。当然,wps也可以处理这两种类型的文件,现在默认首选都是.xlsx格式了。
3.win32com库操作
Python操作Excel相关库有很多,详细可看:https://blog.csdn.net/weixin_43820813/article/details/124467183

根据上图所示,我发现有两个库比较全面,分别是xlwings和win32com。我选择使用win32com,不过,后来发现xlwings更专业,以后有机会试试。
到此我们清晰了Excel的结构以及要使用的库,那么怎么编码呢?程序就是数据结构和算法的构成。我们打开Excel文档,首先一定是先选择Sheet工作表然后再对里面的单元格进行操作的,所以抽象一下,我们可以认为一个Excel文档就是一个三维数组,然后每一个Sheet工作表就是一个二维数组。那么操作表格不就简化成操作一个二维数组了。下面按照操作顺序使用win32com操作Excel文档进行讲解。
(1)首先电脑必须要有Microsoft Excel或者WPS软件,我们使用绝对路径打开文档。
# 获取当前文件夹的绝对路径
def getCurrentFolderPath():
FolderPath = os.path.split(os.path.realpath(__file__))[0]
print(FolderPath)
return FolderPath
#选择打开的文件模板,win32com还可以操作Word文档,这里选择Excel
app = win32com.client.Dispatch('Excel.Application')
# 后台运行,不显示Excel,不弹出警告窗口
app.Visible = 0
app.DisplayAlerts = 0
# 使用绝对路径打开已存在表格
WorkBook = app.Workbooks.Open(getCurrentFolderPath() + "\\输入.xlsx")
print("当前文件夹目录:", getCurrentFolderPath())
(2)打开Excel文档后,我们还要选择Sheet工作表后才能对单元格进行操作。
# 选择Sheet1工作表,名字请按照文件左小角的名称进行更改
sheet = WorkBook.Worksheets('Sheet1')
我们现在可以操作里面的任一单元格,比如读取和修改(修改后要保存才生效):
# 获取第n行n列的单元格信息
cell_value = sheet.Cells(1, 1).Value
print("Value:Cells(1, 1)【即A1】的内容为:", cell_value)
# 修改A1(第一行第一列)表格信息
sheet.Cells(1, 1).Value = "这里写修改后的内容"
# 保存修改到原文件
WorkBook.Save()
然后,我们要对二维数组进行操作也就是遍历操作,那么我们必须要知道这个二维数组的行高(行数)和列宽(列数),然后一个for循环就行。这就需要用到UsedRange(使用区域)属性了。
#获取已使用区域的信息
print("所有行:", sheet.UsedRange.Rows)# 所有数据,包括中间空行,空行打印(None,)
print("所有行:", sheet.UsedRange.Columns)#打印结果和sheet.UsedRange.Rows一样
print("行数:", sheet.UsedRange.Rows.count)
print("列数:", sheet.UsedRange.Columns.count)
(3)遍历操作。每个Sheet工作表下都是一个二维数组,所以我们知道行数和列数后就能遍历每一个使用过的单元格了。在遍历的过程中我们就可以进行我们想要的操作。
# 打印每个单元格的内容
for i in range(sheet.UsedRange.Rows.count):
for j in range(sheet.UsedRange.Columns.count):
#注意单元格的下标是从1开始的
print(sheet.Cells(i+1, j+1).Value)
(3)保存操作。我们对Excel文档的操作后需要保存修改才能生效。保存分为两种:保存修改到源文件和另存为一个新的文件。
# 保存表格(保存修改到原文件)
WorkBook.Save()
# 或者另存为新的文件
# WorkBook.SaveAs(getCurrentFolderPath() + "\\输出.xlsx")
# 操作完毕后记得关闭表格和退出模板
WorkBook.Close()
app.Quit()
win32com库的Excel更多操作可以看一下这位博主的博客:
https://blog.csdn.net/Zhong____/article/details/119819890
4.问题解决
4.1.问题描述
将下面的表格(输入.xlsx)第一列中每个单元格中的中文字符提取出来放到第二列,也就是过滤掉非中文字符。

阿么我们可以遍历表格然后根据某个提取规则将第一列每个单元格提取后的字符放到第二列。
4.2.安装库
如果你没有安装win32com库,那么需要使用命令行进行安装:
pip install pypiwin32
后面提取中文字符串需要用到re库(正则匹配库),没有的话也一起安装了吧。
pip install re
4.3.编码与解决
经过前面的介绍,我们已经掌握win32com操作Excel完成读取、遍历、修改和保存操作了。现在问题的关键变成了,如何将一个字符串中的中文提取出来?
我们可以通过一种规则(算法)将字符串中符合条件的字符筛选出来,然后将他们拼接在一起存到第二列中。我们可以使用findall(pattern, str,)函数将一个字符串str中符合正则表达式pattern中的字符以列表的形式返回。正则表达式pattern可以写中文字符的范围,即Unicode编码的\u4e00-\u9fa5之间的字符。最后用join将列表中中文字符拼接起来即可。
将"输出.xlsx"放在程序所在当前文件夹下,运行如下代码:
import win32com
from win32com.client import Dispatch
import os
import re
# 获取当前文件夹的绝对路径
def getCurrentFolderPath():
FolderPath = os.path.split(os.path.realpath(__file__))[0]
print(FolderPath)
return FolderPath
def solve():
#选择打开的文件模板,win32com还可以操作Word文档,这里选择Excel
app = win32com.client.Dispatch('Excel.Application')
# 后台运行,不显示Excel,不弹出警告窗口
app.Visible = 0
app.DisplayAlerts = 0
# 使用绝对路径打开已存在表格
WorkBook = app.Workbooks.Open(getCurrentFolderPath() + "\\输入.xlsx")
print("当前文件夹目录:", getCurrentFolderPath())
# 选择Sheet1工作表
sheet = WorkBook.Worksheets('Sheet1')
print("遍历表格并处理:")
print("提取A列每一个表格中的中文字符,并将结果输出到B列每一个表格中!")
# 遍历第一列的每一个单元格
for i in range(sheet.UsedRange.Rows.count):
# 下标从1开始,所以i+1;将处理后的字符串放在第二列
sheet.Cells(i+1, 2).Value = ''.join(re.findall('[\u4e00-\u9fa5]',sheet.Cells(i+1, 1).Value))
print("处理完毕")
# 保存修改并另存为
WorkBook.SaveAs(getCurrentFolderPath() + "\\输出.xlsx")
# 关闭表格
WorkBook.Close()
app.Quit()
if __name__ == '__main__':
solve()
运行后生成"输出.xlsx"文件,这个文件内容如下:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









