







研究背景
常用的生成模型
下表总结了现在常用的生成模型的架构、参数量、尺寸和开源地址。其中参数量基本为亿万级别,以decoder的架构为主,模型尺寸在500MB以上。
| 模型名称 | 架构 | 尺寸 | 层数 | 参数量(Billion) | 开源地址 | 备注 |
|---|---|---|---|---|---|---|
| GPT-2 | decoder | 548 MB | 48 | 1.5B | https://huggingface.co/gpt2/tree/main | 相对较小的生成模型 |
| GPT-Neo-2.7B | decoder | 10.7 GB | 32 | 2.7B | https://huggingface.co/EleutherAI/gpt-neo-2.7B/tree/main | |
| pythia-160M | decoder | 375 MB | 12 | 160Million | https://huggingface.co/EleutherAI/pythia-160m/tree/main | 等价于GPT-Neo 125M, OPT-125M |
| Pythia-12B | decoder | 23.85 GB | 36 | 12B | https://huggingface.co/EleutherAI/pythia-12b/tree/main | 256 40G A100 |
| OPT-1.3B | decoder | 2.63 GB | 24 | 1.3B | https://huggingface.co/facebook/opt-1.3b | |
| OPT-66B | decoder | $\sim$150 GB | 64 | 66B | https://huggingface.co/facebook/opt-66b/tree/main | |
| BLOOM-560M | decoder | 1.12 GB | 24 | 560Million | https://huggingface.co/bigscience/bloom-560m | |
| BART-base | encoder-decoder | 558 MB | 6 | - | https://huggingface.co/facebook/bart-base/tree/main | |
| BART-large | encoder-decoder | 1.02 GB | 12 | - | https://huggingface.co/facebook/bart-large/tree/main | |
| Flan-T5-base | encoder-decoder | 990 MB | 12 | 250Million | https://huggingface.co/google/flan-t5-base/tree/main |
选取了在huggingface上下载最多的
CHATGPT 宕机
ChatGPT自发布以来受到了广大用户的好评,认为该模型已能够帮助自己工作。但是,作为一个巨大参数量的模型,多用户同时使用往往无法及时响应,网络错误是时常发生的。近期chatgpt已出现宕机的行为:
-
时常宕机:从 1 月 9 号到 10 号的这两天就有 5 次,停机时间最短几十分钟,最长 14 个小时。
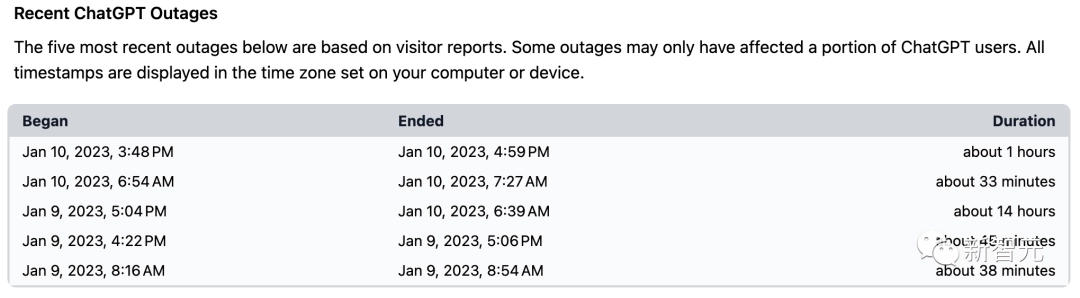
-
大规模宕机:在2023年3月20号ChatGPT大规模宕机,12小时后OpenAI才修复。后续很长一段时间也只恢复了部分功能。
-
ChatGPT Plus停售:2023/4/15,OpenAI宣布因无法满足高需求,ChatGPT PLUS付费版本暂停。
归根结底是ChatGPT的运作需要大量的算力支撑,即使微软提供了上万张英伟达A100组成的专用超算,也无法满足多用户使用带来的高计算需求。现在除了CahtGPT,也涌现了其他的生成模型(如上表所示)。
面临的挑战
内存消耗过大
亿万级别的参数量显然需要高显存量的设备支持,1块NVIDIA A100 80GB显卡算是比较少的要求。例如,GPT-3模型包含 175B 参数,消耗至少 350GB 的内存来存储和运行在 FP16 中,需要 8×48GB A6000 GPU 或 5×80GB A100 GPU 仅用于推理。
Ref:
[1] G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models.” arXiv, Feb. 14, 2023. doi: 10.48550/arXiv.2211.10438.
[2]https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
已经有过许多针对encoder的模型压缩研究,比如BERT模型,常用方法有量化、剪枝、知识蒸馏、低秩分解和参数共享等。随着生成式预训练模型的兴起,这些方法在生成模型也有应用的趋势:
以往模型压缩方法应用的困难
首先需要明确BERT和GPT的架构最大的不同之处为:BERT模型采用双向Transformer,GPT系列模型为单向。
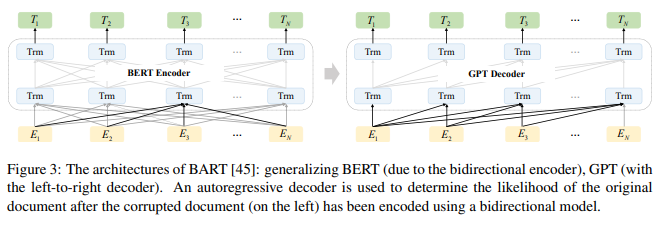
Ref: [1] C. Zhou et al., “A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT.” arXiv, Mar. 30, 2023. doi: 10.48550/arXiv.2302.09419.
以往的模型压缩方法主要针对于双向BERT模型,其直接应用于GPT系列生成模型会产生一些问题。
-
量化的主要面临问题为:1)量化导致的词嵌入层分布集中;2)不同层的权重分布不一,且存在异常值干扰;3)激活值量化的异常值更加突出,不够平滑,更加难以量化。
-
剪枝面临的问题主要是:现有的剪枝方法通常需要对模型进行大量重新训练以恢复准确性,对于大模型来说重复训练过于昂贵。
下面展示这些问题的细节研究:
- 量化导致的词嵌入层分布集中
生成式模型的词嵌入层同质化程度低,token之间的高度依赖,模型的嵌入层向量分散且可区分。经典量化方法使用后导致模型的嵌入层向量分布集中,如下图:
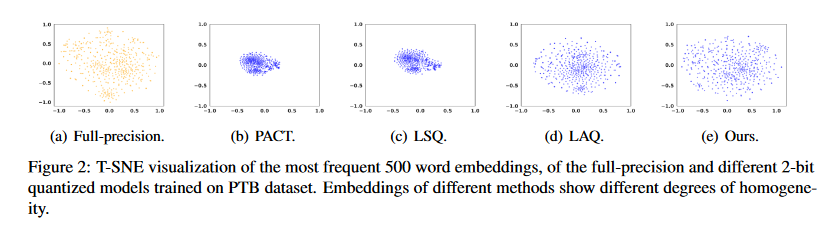
为什么这些量化方法在BERT中使用没有问题?
BERT是token同时建模,但是GPT等是单向建模,单向的建模会导致误差的累计。
Ref: [1] C. Tao et al., “Compression of Generative Pre-trained Language Models via Quantization.” arXiv, Jul. 16, 2022. doi: 10.48550/arXiv.2203.10705.
- 动态的激活值范围
下图绘制了 GPT-3350M 不同Transformer层每次激活值的token(即每个token的隐藏状态)范围。可以看出,不同的token具有截然不同的激活值范围。例如,最后一层的最大范围约为 35,但最小范围接近 8。
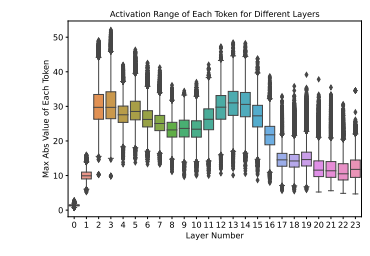
激活值范围内的这种较大方差使得很难对所有token使用固定的量化范围(通常是最大值)来保持预测精度,因为小范围token的有限表示能力会损害准确性性能。
Ref: [1] Z. Yao, R. Y. Aminabadi, M. Zhang, X. Wu, C. Li, and Y. He, “ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers.” arXiv, Jun. 03, 2022. doi: 10.48550/arXiv.2206.01861.
- 权重中的神经元范围不同
下图中绘制了 GPT-3350M 的注意力输出矩阵 (Wo) 的逐行(即输出维度)权重范围。不同行的最大量级之间存在 10 倍的差异,这导致 INT8 权重 PTQ 的生成性能较差。这也使得在应用 INT4 量化时非常具有挑战性,因为 INT4 只有 16 个数字,而 10 倍的小范围会导致这些较小范围行的表示 2(或 3)个数字。
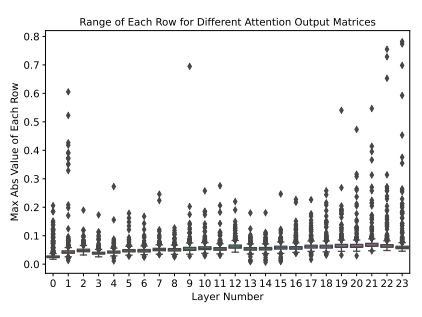
Ref: [1] Z. Yao, R. Y. Aminabadi, M. Zhang, X. Wu, C. Li, and Y. He, “ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers.” arXiv, Jun. 03, 2022. doi: 10.48550/arXiv.2206.01861.
因为同层不同模块的权重分布不一,所以难以使用固定的缩放函数。下图显示12 层全精度 GPT-2 的权重分布与异常值高度偏斜。
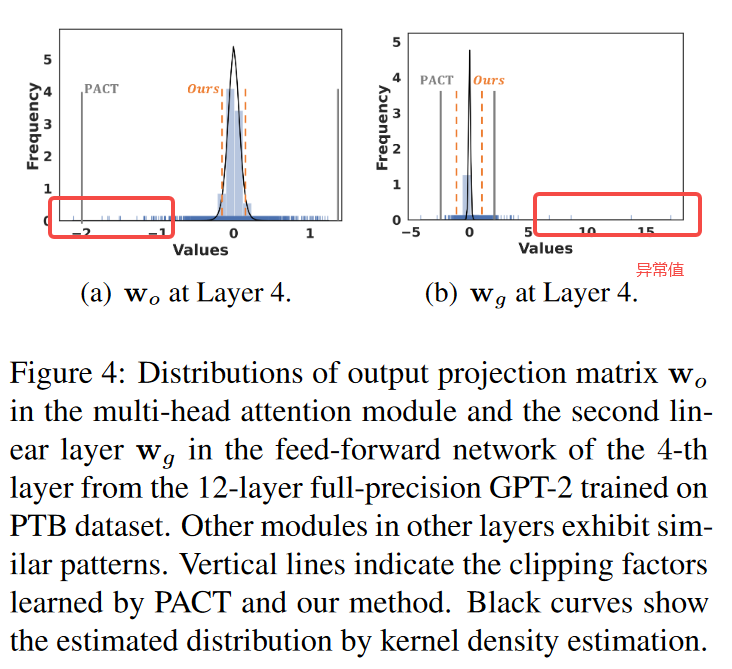
Ref: [1] C. Tao et al., “Compression of Generative Pre-trained Language Models via Quantization.” arXiv, Jul. 16, 2022. doi: 10.48550/arXiv.2203.10705.
- 训练成本巨大
现有的剪枝方法通常需要对模型进行大量重新训练以恢复准确性,对于大模型来说重复训练过于昂贵。
Ref: [1] E. Frantar and D. Alistarh, “SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot.” arXiv, Mar. 22, 2023. doi: 10.48550/arXiv.2301.00774.
近期工作
针对生成式模型压缩与加速的工作如下表所示:目前主要在研究量化和剪枝的可用性。
此外,还有对推理期间效率提升的研究,例如FlexGen,通过卸载推理的token到cpu和SSD中缓解GPU显存压力。还有一些针对训练加速的方法,例如DeepSpeedZero通过数据并行加速大模型训练。还有参数微调的方法(PEFT),只需要微调插入的外部参数,而不是整个训练模型,就能获得不错的性能。
| 方法 | 代表工作 | 简介 | conference | 开源工作 |
|---|---|---|---|---|
| 量化 | SmoothQuant | 往往activation的outlier比较突出,难以量化。而weight分布比较平均,很容易量化。SmoothQuant转移部分activation量化压力到Weight,以减少activation量化难度。实现 W8A8 的量化,减小的模型大小使用一半的 GPU(16 到 8 个)就有相似性能,500B的模型可以在单个节点 (8×A100 80GB GPU)运行使用。 | https://github.com/mit-han-lab/smoothquant | |
| GPTQ | GPTQ,一种基于近似二阶信息的新型单次权重量化方法。具体来说,GPTQ 可以在大约4个 GPU 小时内量化 1750 亿个参数的GPT 模型,将位宽减少到每个权重 3 或 4 位。 | |||
| 量化+蒸馏 | Compression of Generative Pre-trained Language Models via Quantization | 量化在生成式模型出现因词嵌入层聚集而丢失信息的现象以及权重分布不同的问题。本文利用1)对比学习进行token级别的蒸馏,2)设计模块级的动态缩放方法。实现了14x的压缩率,相当的模型性能. | ACL2022 | 暂无 |
| ZeroQuan | 提出了一种PTQ量化方法来压缩基于Transformer 的大模型,具有三个主要组件:(1) 用于权重和激活的细粒度硬件友好量化方案; (2) 一种新颖的负担得起的逐层知识蒸馏算法 (LKD),可以在无法访问原始训练数据情况下使用; (3) 高度优化的量化系统后端支持,以消除量化/反量化开销。 | |||
| 剪枝+量化 | SparseGPT | 性能最佳的剪枝方法需要对模型进行大量重新训练以恢复准确性。对于 GPT 规模的模型来说是极其昂贵的。虽然存在一些准确的一次性修剪方法(不重新训练的情况下压缩模型),但是应用于具有数十亿个参数的模型时,也会变得非常昂贵。 | ||
| 提高吞吐量 | FlexGen | 通过卸载计算到CPU内存、SSD,实现延迟-吞吐量平衡。利用块block调度来重用权重并将I/O与计算重叠。 | https://github.com/FMInference/FlexGen |
FUTURE
- 缺少细粒度的量化方法的实现。
- 如何有效地实现奇比特精度也具有挑战性。有研究证明了通过将所有 3 位数字打包在连续内存空间中,在生成阶段实现更好的吞吐量。但是,此方法不是最佳的,因为反量化步骤需要连接来自不同字节的位。实现奇数位(例如 5 位)的一种可能方法是使用带有 INT4 和 INT1 的两个整数矩阵。在去量化阶段,我们将两个矩阵耦合在一起。
- 如何将 PTQ 与其他轻量级压缩技术(例如训练后修剪)相结合,是进一步降低内存消耗和计算成本的方向。
Ref 1-3: [1] Z. Yao, C. Li, X. Wu, S. Youn, and Y. He, “A Comprehensive Study on Post-Training Quantization for Large Language Models.” arXiv, Mar. 16, 2023. doi: 10.48550/arXiv.2303.08302.
















 848
848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











