






GoogLeNet 的设计理念
GoogLeNet原文
Abstract
We propose a deep convolutional neural network architecture codenamed Inception that achieves the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014( ILSVRC14 ). The main hallmark of this architecture is the improved utilization of the computing resources inside the network. By a carefully crafted design, we increased the depth and width of the network while keeping the computational budget constant. To optimize quality, the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing. One particular incarnation used in our submission for ILSVRC14 is called GoogLeNet, a 22 layers deep network, the quality of which is assessed in the context of classification and detection.
hallmark 标志,utilization 利用率,budget 预算。the intuition of …的直觉,incarnation 化身,is assessed in 被评估,in the context of 在…的背景中。
总结: GoogLeNet 提高了计算的利用率。
Introduction
In the last three years, our object classification and detection capabilities have dramatically improved due to advances in deep learning and convolutional networks [10].One encouraging news is that most of this progress is not just the result of more powerful hardware, larger datasets and bigger models, but mainly a consequence of new ideas, algorithms and improved network architectures. No new data sources were used, for example, by the top entries in the ILSVRC 2014 competition besides the classification dataset of the same competition for detection purposes. Our GoogLeNet submission to ILSVRC 2014 actually uses 12 times fewer parameters than the winning architecture of Krizhevsky et al [9] from two years ago, while being significantly more accurate. On the object detection front, the biggest gains have not come from naive application of bigger and bigger deep networks, but from the synergy of deep architectures and classical computer vision, like the R-CNN algorithm by Girshick et al [6].
dramatically 显著性,戏剧性;encouraging 令人鼓舞的;hardware 硬件,铁器,金属器具; a consequence of …的结果;synergy 协同作用。
总结: 与之前的模型比参数上更小,准确率更高,而在 detection 的任务中,不仅仅是 network 的深度的堆叠,更应该关注深度架构和经典计算机视觉的协同作用。
Another notable factor is that with the ongoing traction of mobile and embedded computing, the efficiency of our algorithms – especially their power and memory use – gains importance. It is noteworthy that the considerations leading to the design of the deep architecture presented in this paper included this factor rather than having a sheer fixation on accuracy numbers. For most of the experiments, the models were designed to keep a computational budget of 1.5 1.5 1.5 billion multiply-adds at inference time, so that the they do not end up to be a purely academic curiosity, but could be put to real world use, even on large datasets, at a reasonable cost.
notable 显著的,显目的,ongoing 不断地,前进的(形容词),前进,行为,举止(名词);traction 拖;with the ongoing traction of 随着…的不断发展;noteworthy 值得注意的;sheer 绝对的;fixation 固定的;budget 预算;inference 推理。
总结: 需要注重算法的效率。
In this paper, we will focus on an efficient deep neural network architecture for computer vision, codenamed Inception,which derives its name from the Network in network paper by Lin et al [12] in conjunction with the famous“we need to go deeper” internet meme [1]. In our case, the word “deep” is used in two different meanings: first of all, in the sense that we introduce a new level of organization in the form of the “Inception module” and also in the more direct sense of increased network depth. In general, one can view the Inception model as a logical culmination of [12] while taking inspiration and guidance from the theoretical work by Arora et al [2]. The benefits of the architecture are experimentally verified on the ILSVRC 2014 classification and detection challenges, where it significantly outperforms the current state of the art.
in conjunction with 与…结合;in the sense that 在某种意义上说;in the form of 形式为;inspiration 灵感,鼓舞;verified on 验证于;outperform 表现优于。
总结: 提出了 Inception 结构。
一言以蔽之,注重了算法的效率,提出了 Inception 结构。
Inception 结构的创新点
Inception v1:
为解决巨大的参数量带来的过拟合和大大增加的计算成本问题,提出了 Inception 结构:
- 对于inception结构而言:
1、密集成分来近似最优的局部稀疏结构。
2、使用 NIN (Network In Network) ,采用 1 × 1 1\times1 1×1 卷积进行降维,降低参数量。
- 对于整体结构而言:
1、显然 GoogLeNet 采用了模块化的结构,方便增添和修改;
2、网络最后采用了average pooling来代替全连接层,想法来自 NIN ,事实证明可以将 TOP1 accuracy 提高 0.6 % 0.6\% 0.6% 。但是,实际在最后还是加了一个全连接层,主要是为了方便以后大家 fine tune (微调);
3、虽然移除了全连接,但是网络中依然使用了 Dropout ;
4、为了避免梯度消失,网络额外增加了 2 个辅助的 softmax 用于向前传导梯度。文章中说这两个辅助的分类器的 loss 应该加一个衰减系数,但看 caffe( Convolutional Architecture for Fast Feature Embedding,卷积神经网络框架) 中的 model 也没有加任何衰减。此外,实际测试的时候,这两个额外的 softmax 会被去掉。
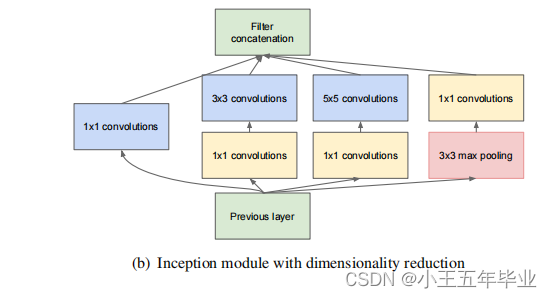
Inception v2:
(1)卷积核分解: 5 × 5 → 3 × 3 5\times5\to3\times3 5×5→3×3(类似于VGG的思想)
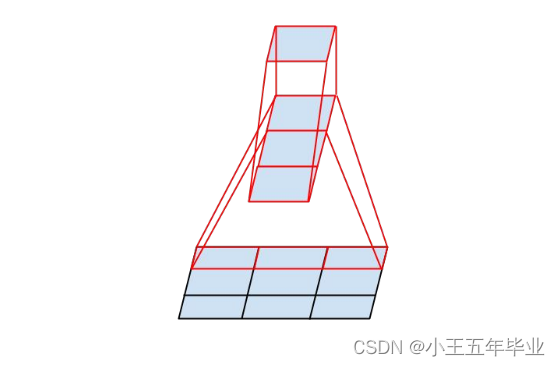
(2)继续分解: 3 × 3 → 1 × 3 + 3 × 1 3\times3\to1\times3+3\times1 3×3→1×3+3×1
3 × 1 c o n v + 1 × 3 c o n v 3\times1conv+1\times3conv 3×1conv+1×3conv 等价于一个 3 × 3 c o n v 3\times3conv 3×3conv 的视野范围,见图2;在输入和输出等同的情况下,参数降低 33 % 33\% 33% 。作为对比,将 3 × 3 3\times3 3×3 卷积核分解为两个 2 × 2 2\times2 2×2 卷积核,只是降低了 11 % 11\% 11% 。
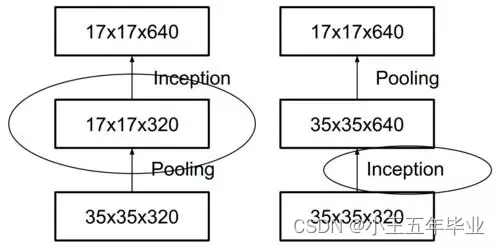
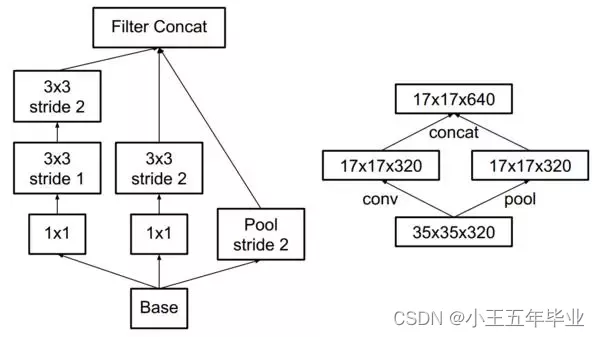
(3) Inception 和 Pooling 同时进行。
如果先进行 Pooling ,确实会减少参数,但是会丢失信息,采用图 4 中的方法可以解决这个问题。
Inception v3:
主要是进行了优化器的改进和采用了 Batch Normalization 。
VGG 的设计理念
VGG 原文
Abstract
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3×3) convolution filters, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16–19 weight layers. These findings were the basis of our ImageNet Challenge 2014 submission, where our team secured the first and the second places in the localisation and classification tracks respectively. We also show that our representations generalize well to other datasets, where they achieve state-of-the-art results. We have made our two best-performing ConvNet models publicly available to facilitate further research on the use of deep visual representations in computer vision.
investigate 调查;investigate 彻底;secure 安全,镇守。
一言以蔽之,提出了神经网络的深度的重要性,且通过堆叠多个 3 × 3 3\times3 3×3 的卷积核来替代大尺度卷积核(减少训练参数)。
VGG 的创新点
网络中的亮点:通过堆叠多个 3 × 3 3\times3 3×3 的卷积核来替代大尺度卷积核(减少训练参数)。
论文中提到,可以通过堆叠两个 3 × 3 3\times3 3×3 的卷积核替代 5 × 5 5\times5 5×5 的卷积核,堆叠三个 3 × 3 3\times3 3×3 的卷积核替代 7 × 7 7\times7 7×7 的卷积核。它们拥有相同的感受野。
ResNet 的设计理念
ResNet 的原文
Abstract
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers — 8 deeper than VGG nets [41] but still having lower complexity.
An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers. The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions 1 ^{1} 1, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization,COCO detection, and COCO segmentation.
comprehensive 综合的;empirical 经验。
一言以蔽之,提出了Residual,解决了很多梯度方面的问题。
ResNet 的创新点
1、相比传统的 VGG 网络,复杂度降低,所需的参数量下降。
2、网络深度更深,不会出现梯度消失现象。
3、由于使用更深的网络,分类准确度加深。
4、解决了深层次的网络退化问题。
HRNet 的设计理念
HRNet 的原文
Abstract
In this paper, we are interested in the human pose estimation problem with a focus on learning reliable high resolution representations. Most existing methods recover high-resolution representations from low-resolution representations produced by a high-to-low resolution network. Instead, our proposed network maintains high-resolution representations through the whole process.
high-resolution 高分辨率。
We start from a high-resolution subnetwork as the first stage, gradually add high-to-low resolution subnetworks one by one to form more stages, and connect the mutliresolution subnetworks in parallel. We conduct repeated multi-scale fusions such that each of the high-to-low resolution representations receives information from other parallel representations over and over, leading to rich high resolution representations. As a result, the predicted keypoint heatmap is potentially more accurate and spatially more precise. We empirically demonstrate the effectiveness of our network through the superior pose estimation results over two benchmark datasets: the COCO keypoint detection dataset and the MPII Human Pose dataset. In addition, we show the superiority of our network in pose tracking on the PoseTrack dataset. The code and models have been publicly available at https://github.com/leoxiaobin/deep-high-resolution-net.pytorch.
fusion 合成;potentially 有可能,潜在地;spatially 空间上地;empirically 凭经验地。
大多数现有方法从高分辨率到低分辨率网络产生的低分辨率表示中恢复高分辨率表示。相反,我们提出的网络在整个过程中保持高分辨率表示。通过多尺度融合,丰富高分辨率表示。
一言以蔽之,作者通过重复的多尺度融合,使得每个从高到低的分辨率表征一遍又一遍地接收来自其他并行表征的信息,从而产生丰富的高分辨率表征,从而预测关键点热图更加准确。
HRNet 的创新点
很明确,通过重复的多尺度融合,使得每个从高到低的分辨率表征一遍又一遍地接收来自其他并行表征的信息,从而产生丰富的高分辨率表征,从而预测关键点热图更加准确。
了解到,HRNet v2 是用于分割的,其中简单的 add 操作改为了 concat 。















 383
383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









