









爬取网易云音乐
2023-5-23
爬取网易云1.0
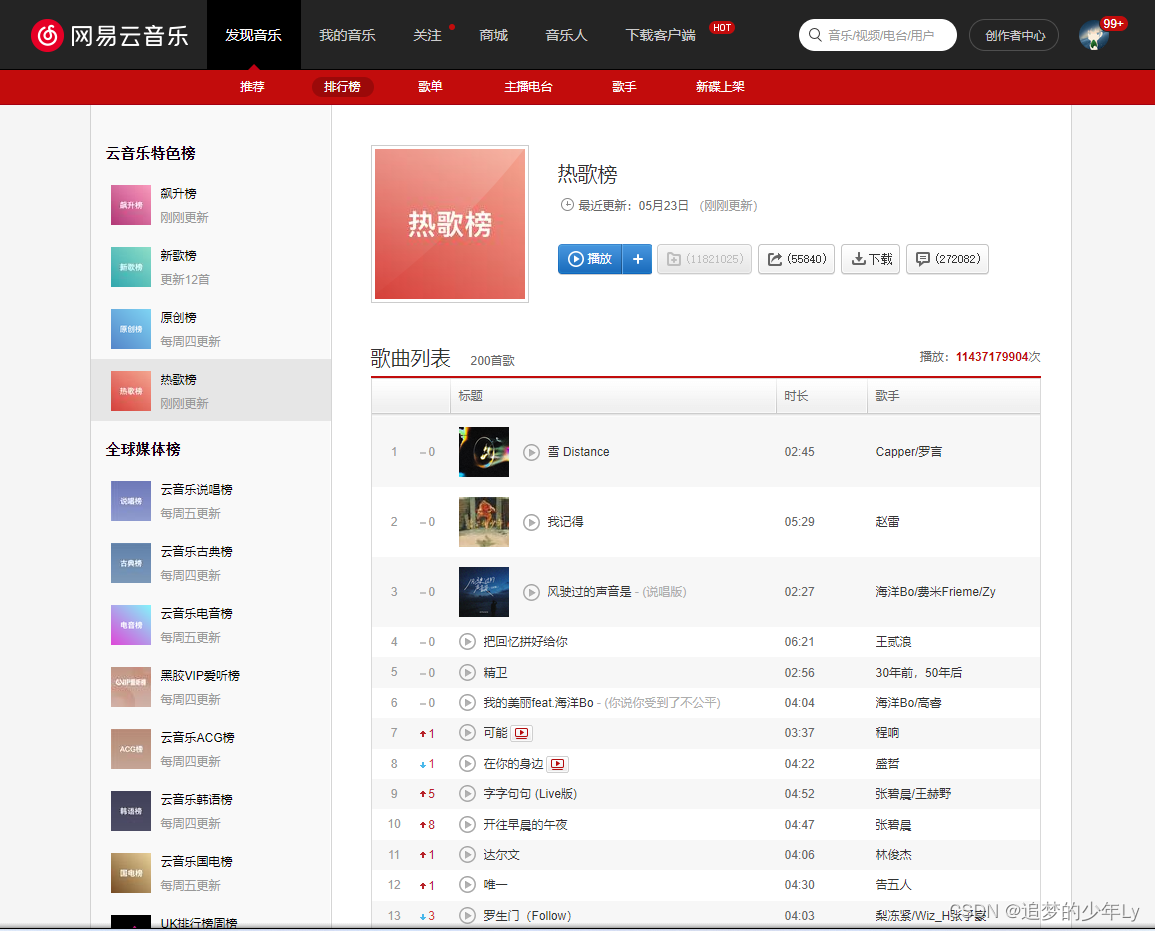
1.对https://music.163.com/#/discover/toplist?id=3778678中的音乐进行爬取,下载到本地文件夹中
图1:网站界面
import requests
from lxml import etree
from selenium import webdriver
import time
headers={
'User-Agent': "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"
}
url="https://music.163.com/#/discover/toplist?id=3778678"
# 浏览器驱动绝对路径
driver = webdriver.Chrome()
# 跳转网页
driver.get(url)
#最大化
driver.maximize_window()
time.sleep(1)
driver.switch_to.frame("contentFrame")
source_result = driver.page_source
html=etree.HTML(source_result)
time.sleep(1)
driver.quit()
#歌曲的音乐链接列表
song_list=html.xpath('/html/body/div[3]/div[2]/div/div[2]/div[2]/div/div[1]/table/tbody/tr/td[2]/div/div/div/span/a/@href')
#歌曲的名称列表
song_name_list=html.xpath('/html/body/div[3]/div[2]/div/div[2]/div[2]/div/div[1]/table/tbody/tr/td[2]/div/div/div/span/a/b/@title')
for i in range(len(song_list)):
music_id = song_list[i].split("=")[1]
# 拼接地址
music_url="https://music.163.com/song/media/outer/url?id="+music_id
#歌曲名称
music_name=song_name_list[i]
print("music_name:"+music_name+" music_url:"+music_url)
data=requests.get(music_url)
#如果正常反应
if data.status_code==200:
with open("./download/%s.mp3"%music_name,"wb") as file:
file.write(data.content)
爬取思路:
1.获取热歌榜中的音乐链接,切分出每首歌曲对应的id,拼接成外链。
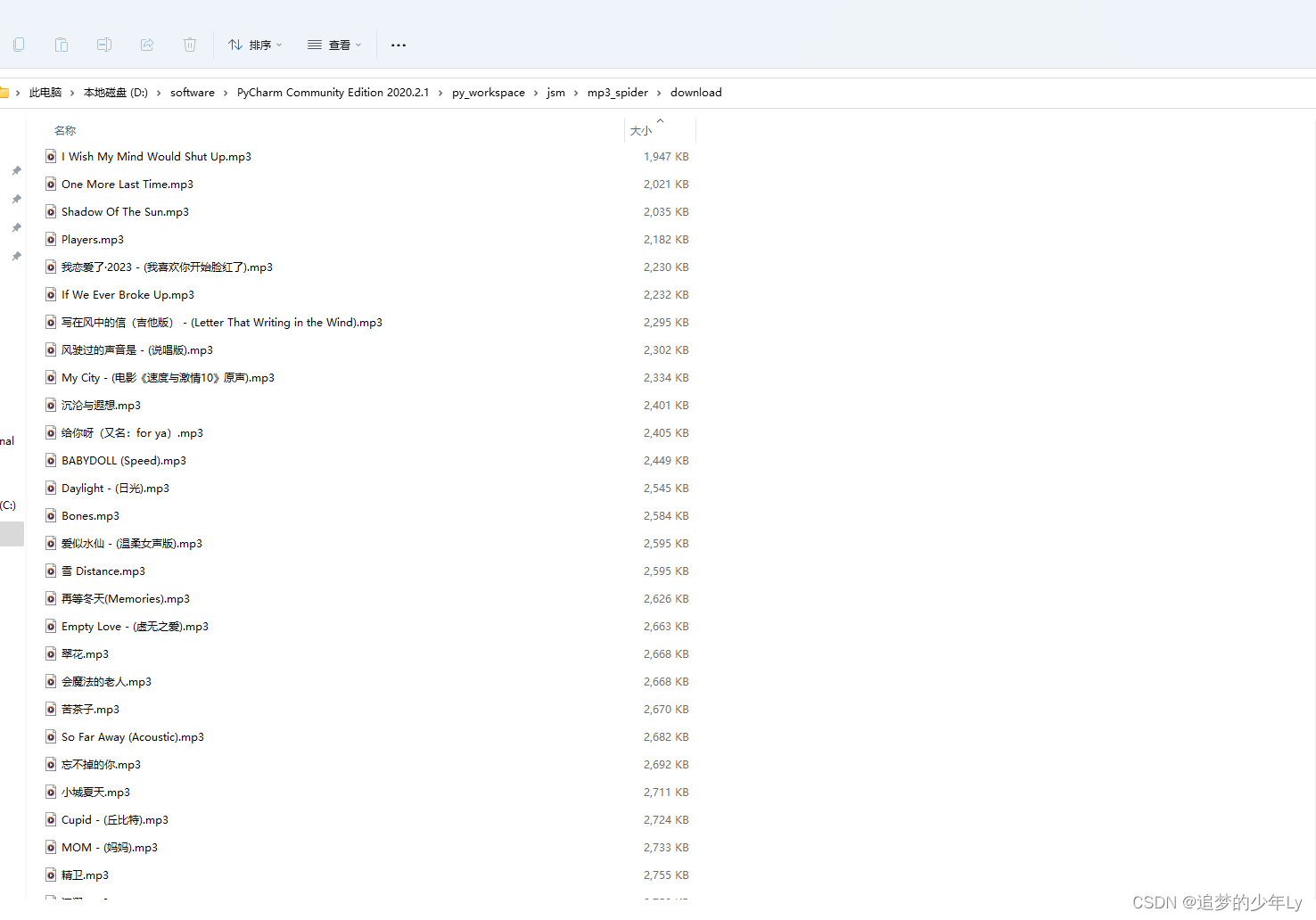
2.根据对应的外链,写到本地文件夹中。
图2:控制台

图3:实际情况:
难点总结:
1.刚开始获取网页源码,即page_source,获取到的内容不包含对应的热歌榜中的歌曲信息。在网页中用xpath插件定位也定位不了,换了class定位也不行。
2.观察了一下具体的网页源码,发现有个大的iframe框架。然后我就开始尝试着跳入iframe框架,再进行获取网页源码,这次发现获取到的源码包含了歌曲信息,good!这样我们就可以按部就班爬取了。
很早之前自己写的了,搬运一下的。

















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









