







文章目录
前言
动态影像专家小组(英语:Moving Picture Experts Group,简称MPEG)为一源自ISO与IEC等国际组织的工作小组,用以制定影音压缩及传输的规格标准。MPEG的官方正式命名为ISO/IEC JTC 1/SC 29/WG 11 – Coding of moving pictures and audio (ISO/IEC Joint Technical Committee 1, Subcommittee 29, Working Group 11)。
一、MPEG相关标准
到目前为止,已有以下和视频相关的标准:
- MPEG-1:第一个官方的视讯音频压缩标准,随后在Video CD中被采用,其中的音频压缩的第三级(MPEG-1 Layer 3)简称MP3,成为比较流行的音频压缩格式。
- MPEG-2:广播质量的视讯、音频和传输协议。被用于无线数字电视-ATSC、DVB以及ISDB、数字卫星电视(例如DirecTV)、数字有线电视信号,以及DVD视频光盘技术中。
- MPEG-3:原本目标是为高清晰度电视(HDTV)设计,随后发现MPEG-2已足够HDTV应用,故MPEG-3的研发便中止。
- MPEG-4:2003年发布的视讯压缩标准,主要是扩展MPEG-1、MPEG-2等标准以支持视频/音频对象(video/audio “objects”)的编码、3D内容、低比特率编码(low bitrate encoding)和数字版权管理(Digital Rights Management),其中第10部分由ISO/IEC和ITU-T联合发布,称为H.264/MPEG-4 Part 10。
- MPEG-7:MPEG-7并不是一个视讯压缩标准,它是一个多媒体内容的描述标准。
- MPEG-21:MPEG-21是一个正在制定中的标准,它的目标是为未来多媒体的应用提供一个完整的平台。
二、MPEG工作原理
MPEG(通常指MPEG-1)影像编码是基于变换的有损压缩。光学信号线经过采样形成视频信号,视频信号基本的单位叫做帧,一个帧就是一个独立的图像,然后帧被分割成小块做变换编码,然后量化,最后进行熵编码。请参见MPEG-1
MPEG-1、MPEG-2、MPEG-4实际上采用了的动量估计和动量补偿技术。在利用了动量补偿的帧(图像)中,被编码的是经过动量补偿的参考帧与目前图像的差。与传统影像编码技术不同,MPEG并不是每格影像进行压缩,而是以一秒时段作为单位,将时段内的每一格影像做比较,由于一般视频内容都是背景变化小、主体变化大,MPEG技术就应用这个特点,以一幅影像为主图,其余影像格只记录参考资料及变化数据,更有效记录动态影像。从MPEG-1到MPEG-4,其核心技术仍然离不开这个原理,之间的分别主要在于比较的过程和分析的复杂性等。
MPEG只规定比特流的格式与解码精确度(即规定解码的方法),而任何人可依照MPEG标准以不同方式实现编码器(程序)。除了可减少因编码专利造成的商业利益纠纷外,MPEG标准的主要目的在于确保不同的编码器所产生的比特流可被其他解码器正确的解码,只要此比特流符合标准。

三、感知音频编码的设计思想
基本思想
➢ 分析信号,去掉不能被感知的部分
1. MPEG-I 心理声学模型
心理声学模型(Psychoacoustic model )
➢ 生理(Physiological )感知极限(传感极限)
➢ 心理 (Psychological )感知极限 (信号处理极限)
听觉阈值:

- 通过子带分析滤波器组使信号具有高的时间分辨率,确保在短暂冲击信号情况下,编码的声音信号具有足够高的质量
- 又可以使信号通过FFT运算具有高的频率分辨率,因为掩蔽阈值是从功率谱密度推出来的。
- 在低频子带中,为了保护音调和共振峰的结构,就要求用较小的量化阶、较多的量化级数,即分配较多的位数来表示样本值。而话音中的摩擦音和类似噪声的声音,通常出现在高频子带中,对它分配较少的位数
频域掩蔽域随声压级变化曲线:

2. 临界频带(Critical Band)
- 临界频带是指当某个纯音被以它为中心频率、且具有一定带
宽的连续噪声所掩蔽时,如果该纯音刚好被听到时的功率等
于这一频带内的噪声功率,这个带宽为临界频带宽度。 - 研究窄带噪声对纯音掩蔽量的规律时被发现的
➢ 使噪声的中心频率等于信号频率,只改变噪声的带宽同时保持噪声的功率谱密度不变,测试纯音听阈随掩蔽噪声带宽变化的特性
➢ 纯音的听阈随掩蔽噪声带宽的增大而增大,在带宽增大到某一特定值之后听阈保持恒定不变。 - 通常认为从20Hz到16kHz有25个临界频
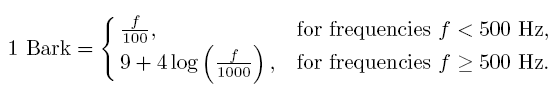
3. 人耳听觉系统
- 人类听觉系统大致等效于一个信号通过一组并联的不同中心频率的带通滤波器

- 掩蔽声对被掩蔽声的掩蔽效应,取决于两者的频率与强度的关系
- 掩蔽言语声和短声等宽频谱信号,则常用白噪声。因此,在听觉诱发反应测试中,往往在健侧耳施加白噪声作为掩蔽噪声
临界频带(Critical Band):

4. 时域/频域掩蔽

对信号的传统分析方法是波形分析。
表示信号的时间函数,包含了信号的全部信息量,信号的特性首先表现为它的时间特性。
可以显示,例如信号幅值对应的时间;同一形状的波形重复出现的周期长短;信号波形本身变化的速率(如脉冲信号的脉冲持续时间及脉冲上升和下降边沿陡直的程度)。
以时间函数描述信号的图象称为时域图,在时域上分析信号称为时域分析。
掩蔽效果具有加和的效果。
三、MPEG音频压缩
1. 多相滤波器组,用来分割子带
划分子带的方法有两种:线性划分和非线性划分
线性划分可能一个子带覆盖好几个临界频带,以Layer 1为例,先分成32个相等的子带。

2. 量化和编码
- 比例因子的取值和编码
- 比特分配及编码
掩噪比MNR = 信噪比SNR - 信掩比SMR - 子带样值的量化和编码

3. 数据帧包装

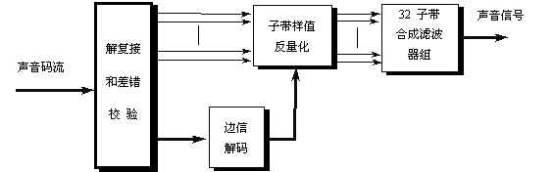
4. 解码
解码过程要求的计算能力比编码过程少得多。在第1层码的这个比例关系大约是1:2,第2层码是1:3。由于计算能力要求低和算法的直向结构,两层都可以很容易用一块专用ASIC实现。
四、代码分析以及实验结果
1. 分析示例音频
选择三个不同特性的音频文件
噪声(持续噪声、突发噪声)、音乐、混合

2. 打印代码更改
#if FRAME_TRACE
FILE* canshu;
canshu = fopen("canshu.txt", "a");
fprintf(canshu, "========== 基本信息 ==========\n");
fprintf(canshu, "输入文件:%s\n", inPath);
fprintf(canshu, "输出文件:%s\n", outPath);
fprintf(canshu, "采样频率:%.1f kHz\n", s_freq[header->version][header->sampling_frequency]);
fprintf(canshu, "输出文件码率:%d kbps\n", bitrate[header->version][header->bitrate_index]);
fclose(canshu);
#endif // FRAME_TRACE
3. 运行输出
首先进行测试的是混合音频:


========== 基本信息 ==========
输入文件:000_hunhe.wav
输出文件:111_hunhe.mp2
采样频率:48.0 kHz
输出文件码率:192 kbps
声道数:2
目前观测第 2 帧
本帧比特预算:4608 bits
========== 比例因子 ==========
------ 声道 1 ------
子带[ 1]: 18 17 16
子带[ 2]: 32 32 32
子带[ 3]: 32 32 32
子带[ 4]: 37 34 37
子带[ 5]: 36 38 37
子带[ 6]: 37 35 36
子带[ 7]: 35 36 38
子带[ 8]: 33 34 37
子带[ 9]: 37 37 36
子带[10]: 37 39 39
子带[11]: 37 39 38
子带[12]: 39 41 38
子带[13]: 39 38 38
子带[14]: 39 40 38
子带[15]: 37 39 39
子带[16]: 39 38 36
子带[17]: 37 39 38
子带[18]: 37 36 39
子带[19]: 36 38 36
子带[20]: 35 35 35
子带[21]: 38 36 35
子带[22]: 38 39 36
子带[23]: 36 39 35
子带[24]: 36 35 37
子带[25]: 35 34 35
子带[26]: 35 36 34
子带[27]: 33 33 33
------ 声道 2 ------
子带[ 1]: 18 15 15
子带[ 2]: 30 29 29
子带[ 3]: 32 31 30
子带[ 4]: 36 33 34
子带[ 5]: 35 37 33
子带[ 6]: 34 32 32
子带[ 7]: 33 36 35
子带[ 8]: 36 34 35
子带[ 9]: 36 34 36
子带[10]: 36 35 38
子带[11]: 38 38 38
子带[12]: 40 34 35
子带[13]: 37 38 36
子带[14]: 37 39 35
子带[15]: 37 38 36
子带[16]: 38 36 34
子带[17]: 35 36 36
子带[18]: 34 34 36
子带[19]: 36 34 32
子带[20]: 37 33 34
子带[21]: 35 35 34
子带[22]: 38 34 34
子带[23]: 36 35 36
子带[24]: 35 35 32
子带[25]: 34 32 32
子带[26]: 32 29 28
子带[27]: 32 33 31
========== 比特分配表 ==========
------ 声道 1 ------
子带[ 1]: 5
子带[ 2]: 4
子带[ 3]: 4
子带[ 4]: 6
子带[ 5]: 5
子带[ 6]: 6
子带[ 7]: 5
子带[ 8]: 4
子带[ 9]: 5
子带[10]: 5
子带[11]: 4
子带[12]: 6
子带[13]: 4
子带[14]: 5
子带[15]: 3
子带[16]: 4
子带[17]: 5
子带[18]: 4
子带[19]: 3
子带[20]: 2
子带[21]: 2
子带[22]: 1
子带[23]: 0
子带[24]: 0
子带[25]: 0
子带[26]: 0
子带[27]: 0
------ 声道 2 ------
子带[ 1]: 4
子带[ 2]: 4
子带[ 3]: 3
子带[ 4]: 6
子带[ 5]: 5
子带[ 6]: 6
子带[ 7]: 5
子带[ 8]: 4
子带[ 9]: 5
子带[10]: 5
子带[11]: 4
子带[12]: 6
子带[13]: 4
子带[14]: 5
子带[15]: 3
子带[16]: 4
子带[17]: 5
子带[18]: 4
子带[19]: 3
子带[20]: 2
子带[21]: 2
子带[22]: 1
子带[23]: 0
子带[24]: 0
子带[25]: 0
子带[26]: 0
子带[27]: 0
然后我们对音乐音频进行分析


========== 基本信息 ==========
输入文件:000_music.wav
输出文件:111_music.mp2
采样频率:44.1 kHz
输出文件码率:192 kbps
声道数:2
目前观测第 2 帧
本帧比特预算:5016 bits
========== 比例因子 ==========
------ 声道 1 ------
子带[ 1]: 55 31 28
子带[ 2]: 51 29 27
子带[ 3]: 50 28 24
子带[ 4]: 55 33 29
子带[ 5]: 54 31 28
子带[ 6]: 59 35 33
子带[ 7]: 62 34 33
子带[ 8]: 57 36 33
子带[ 9]: 57 44 33
子带[10]: 62 37 37
子带[11]: 62 41 34
子带[12]: 62 48 42
子带[13]: 62 58 56
子带[14]: 61 58 55
子带[15]: 62 58 57
子带[16]: 62 58 55
子带[17]: 62 59 57
子带[18]: 62 56 59
子带[19]: 62 57 55
子带[20]: 62 55 56
子带[21]: 62 58 57
子带[22]: 62 58 56
子带[23]: 62 58 58
子带[24]: 62 57 55
子带[25]: 62 59 55
子带[26]: 62 57 54
子带[27]: 62 59 58
子带[28]: 62 56 57
子带[29]: 62 58 58
子带[30]: 62 57 60
------ 声道 2 ------
子带[ 1]: 56 33 27
子带[ 2]: 50 30 27
子带[ 3]: 49 28 24
子带[ 4]: 60 34 28
子带[ 5]: 56 31 27
子带[ 6]: 59 34 32
子带[ 7]: 62 35 33
子带[ 8]: 59 35 32
子带[ 9]: 56 41 36
子带[10]: 62 40 36
子带[11]: 62 39 35
子带[12]: 62 51 46
子带[13]: 62 55 56
子带[14]: 60 57 59
子带[15]: 60 58 58
子带[16]: 60 57 55
子带[17]: 61 57 58
子带[18]: 62 57 57
子带[19]: 62 56 58
子带[20]: 62 57 56
子带[21]: 62 58 57
子带[22]: 62 56 58
子带[23]: 62 58 57
子带[24]: 62 57 55
子带[25]: 62 58 57
子带[26]: 62 57 53
子带[27]: 62 59 57
子带[28]: 62 57 59
子带[29]: 61 58 56
子带[30]: 60 57 59
========== 比特分配表 ==========
------ 声道 1 ------
子带[ 1]: 4
子带[ 2]: 4
子带[ 3]: 3
子带[ 4]: 6
子带[ 5]: 5
子带[ 6]: 4
子带[ 7]: 5
子带[ 8]: 4
子带[ 9]: 5
子带[10]: 5
子带[11]: 4
子带[12]: 5
子带[13]: 4
子带[14]: 4
子带[15]: 4
子带[16]: 5
子带[17]: 4
子带[18]: 4
子带[19]: 4
子带[20]: 3
子带[21]: 3
子带[22]: 3
子带[23]: 3
子带[24]: 1
子带[25]: 0
子带[26]: 1
子带[27]: 0
子带[28]: 0
子带[29]: 0
子带[30]: 0
------ 声道 2 ------
子带[ 1]: 4
子带[ 2]: 4
子带[ 3]: 3
子带[ 4]: 6
子带[ 5]: 5
子带[ 6]: 4
子带[ 7]: 5
子带[ 8]: 4
子带[ 9]: 5
子带[10]: 5
子带[11]: 4
子带[12]: 5
子带[13]: 4
子带[14]: 4
子带[15]: 4
子带[16]: 5
子带[17]: 4
子带[18]: 4
子带[19]: 4
子带[20]: 3
子带[21]: 3
子带[22]: 3
子带[23]: 3
子带[24]: 1
子带[25]: 0
子带[26]: 1
子带[27]: 0
子带[28]: 0
子带[29]: 0
子带[30]: 0
然后我们对噪音音频进行分析


========== 基本信息 ==========
输入文件:000_noise.wav
输出文件:111_noise.mp2
采样频率:48.0 kHz
输出文件码率:192 kbps
声道数:2
目前观测第 2 帧
本帧比特预算:4608 bits
========== 比例因子 ==========
------ 声道 1 ------
子带[ 1]: 63 63 63
子带[ 2]: 63 63 63
子带[ 3]: 63 63 63
子带[ 4]: 63 63 63
子带[ 5]: 63 63 63
子带[ 6]: 63 63 63
子带[ 7]: 63 63 63
子带[ 8]: 63 63 63
子带[ 9]: 63 63 63
子带[10]: 63 63 63
子带[11]: 63 63 63
子带[12]: 63 63 63
子带[13]: 63 63 63
子带[14]: 63 63 63
子带[15]: 63 63 63
子带[16]: 63 63 63
子带[17]: 63 63 63
子带[18]: 63 63 63
子带[19]: 63 63 63
子带[20]: 63 63 63
子带[21]: 63 63 63
子带[22]: 63 63 63
子带[23]: 63 63 63
子带[24]: 63 63 63
子带[25]: 63 63 63
子带[26]: 63 63 63
子带[27]: 63 63 63
------ 声道 2 ------
子带[ 1]: 62 63 62
子带[ 2]: 62 63 62
子带[ 3]: 62 63 62
子带[ 4]: 62 63 62
子带[ 5]: 62 63 62
子带[ 6]: 62 63 62
子带[ 7]: 62 63 62
子带[ 8]: 62 63 62
子带[ 9]: 62 63 62
子带[10]: 62 63 62
子带[11]: 62 63 62
子带[12]: 62 63 62
子带[13]: 62 63 62
子带[14]: 62 63 62
子带[15]: 62 63 62
子带[16]: 62 63 62
子带[17]: 62 63 62
子带[18]: 62 63 62
子带[19]: 62 63 62
子带[20]: 62 63 62
子带[21]: 62 63 62
子带[22]: 62 63 62
子带[23]: 62 63 62
子带[24]: 62 63 62
子带[25]: 62 63 62
子带[26]: 62 63 62
子带[27]: 62 63 62
========== 比特分配表 ==========
------ 声道 1 ------
子带[ 1]: 4
子带[ 2]: 4
子带[ 3]: 4
子带[ 4]: 5
子带[ 5]: 5
子带[ 6]: 6
子带[ 7]: 5
子带[ 8]: 4
子带[ 9]: 5
子带[10]: 5
子带[11]: 4
子带[12]: 4
子带[13]: 4
子带[14]: 5
子带[15]: 4
子带[16]: 3
子带[17]: 4
子带[18]: 4
子带[19]: 3
子带[20]: 3
子带[21]: 1
子带[22]: 1
子带[23]: 0
子带[24]: 0
子带[25]: 0
子带[26]: 0
子带[27]: 0
------ 声道 2 ------
子带[ 1]: 4
子带[ 2]: 4
子带[ 3]: 4
子带[ 4]: 6
子带[ 5]: 5
子带[ 6]: 6
子带[ 7]: 5
子带[ 8]: 4
子带[ 9]: 5
子带[10]: 5
子带[11]: 4
子带[12]: 4
子带[13]: 4
子带[14]: 5
子带[15]: 4
子带[16]: 3
子带[17]: 4
子带[18]: 4
子带[19]: 3
子带[20]: 3
子带[21]: 1
子带[22]: 1
子带[23]: 0
子带[24]: 0
子带[25]: 0
子带[26]: 0
子带[27]: 0
4. 代码分析以及相应代码的注释
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#include "common.h"
#include "encoder.h"
#include "musicin.h"
#include "options.h"
#include "audio_read.h"
#include "bitstream.h"
#include "mem.h"
#include "crc.h"
#include "psycho_n1.h"
#include "psycho_0.h"
#include "psycho_1.h"
#include "psycho_2.h"
#include "psycho_3.h"
#include "psycho_4.h"
#include "encode.h"
#include "availbits.h"
#include "subband.h"
#include "encode_new.h"
#include "m2aenc.h"
#include <assert.h>
#define FRAME_TRACE 1
FILE *musicin;
Bit_stream_struc bs;
char *programName;
char toolameversion[10] = "0.2l";
void global_init (void)
{
glopts.usepsy = TRUE;
glopts.usepadbit = TRUE;
glopts.quickmode = FALSE;
glopts.quickcount = 10;
glopts.downmix = FALSE;
glopts.byteswap = FALSE;
glopts.channelswap = FALSE;
glopts.vbr = FALSE;
glopts.vbrlevel = 0;
glopts.athlevel = 0;
glopts.verbosity = 2;
}
/************************************************************************
*
* main
*
* PURPOSE: MPEG II Encoder with
* psychoacoustic models 1 (MUSICAM) and 2 (AT&T)
*
* SEMANTICS: One overlapping frame of audio of up to 2 channels are
* processed at a time in the following order:
* (associated routines are in parentheses)
*
* 1. Filter sliding window of data to get 32 subband
* samples per channel.
* (window_subband,filter_subband)
*
* 2. If joint stereo mode, combine left and right channels
* for subbands above #jsbound#.
* (combine_LR)
*
* 3. Calculate scalefactors for the frame, and
* also calculate scalefactor select information.
* (*_scale_factor_calc)
*
* 4. Calculate psychoacoustic masking levels using selected
* psychoacoustic model.
* (psycho_i, psycho_ii)
*
* 5. Perform iterative bit allocation for subbands with low
* mask_to_noise ratios using masking levels from step 4.
* (*_main_bit_allocation)
*
* 6. If error protection flag is active, add redundancy for
* error protection.
* (*_CRC_calc)
*
* 7. Pack bit allocation, scalefactors, and scalefactor select
*headerrmation onto bitstream.
* (*_encode_bit_alloc,*_encode_scale,transmission_pattern)
*
* 8. Quantize subbands and pack them into bitstream
* (*_subband_quantization, *_sample_encoding)
*
************************************************************************/
int frameNum = 0;
int main(int argc, char** argv)
{
typedef double SBS[2][3][SCALE_BLOCK][SBLIMIT];
SBS* sb_sample;
typedef double JSBS[3][SCALE_BLOCK][SBLIMIT];
JSBS* j_sample;
typedef double IN[2][HAN_SIZE];
IN* win_que;
typedef unsigned int SUB[2][3][SCALE_BLOCK][SBLIMIT];
SUB* subband;
frame_info frame;
frame_header header;
char original_file_name[MAX_NAME_SIZE];
char encoded_file_name[MAX_NAME_SIZE];
short** win_buf;
static short buffer[2][1152];
static unsigned int bit_alloc[2][SBLIMIT], scfsi[2][SBLIMIT];
static unsigned int scalar[2][3][SBLIMIT], j_scale[3][SBLIMIT];
static double smr[2][SBLIMIT], lgmin[2][SBLIMIT], max_sc[2][SBLIMIT];
// FLOAT snr32[32];
short sam[2][1344]; /* was [1056]; */
int model, nch, error_protection;
static unsigned int crc;
int sb, ch, adb;
unsigned long frameBits, sentBits = 0;
unsigned long num_samples;
int lg_frame;
int i;
/* Used to keep the SNR values for the fast/quick psy models */
static FLOAT smrdef[2][32];
static int psycount = 0;
extern int minimum;
time_t start_time, end_time;
int total_time;
sb_sample = (SBS*)mem_alloc(sizeof(SBS), "sb_sample");
j_sample = (JSBS*)mem_alloc(sizeof(JSBS), "j_sample");
win_que = (IN*)mem_alloc(sizeof(IN), "Win_que");
subband = (SUB*)mem_alloc(sizeof(SUB), "subband");
win_buf = (short**)mem_alloc(sizeof(short*) * 2, "win_buf");
/* clear buffers */
memset((char*)buffer, 0, sizeof(buffer));
memset((char*)bit_alloc, 0, sizeof(bit_alloc));
memset((char*)scalar, 0, sizeof(scalar));
memset((char*)j_scale, 0, sizeof(j_scale));
memset((char*)scfsi, 0, sizeof(scfsi));
memset((char*)smr, 0, sizeof(smr));
memset((char*)lgmin, 0, sizeof(lgmin));
memset((char*)max_sc, 0, sizeof(max_sc));
//memset ((char *) snr32, 0, sizeof (snr32));
memset((char*)sam, 0, sizeof(sam));
global_init();
header.extension = 0;
frame.header = &header;
frame.tab_num = -1; /* no table loaded */
frame.alloc = NULL;
header.version = MPEG_AUDIO_ID; /* Default: MPEG-1 */
total_time = 0;
time(&start_time);
programName = argv[0];
if (argc == 1) /* no command-line args */
short_usage();
else
parse_args(argc, argv, &frame, &model, &num_samples, original_file_name,
encoded_file_name);
print_config(&frame, &model, original_file_name, encoded_file_name);
/* this will load the alloc tables and do some other stuff */
hdr_to_frps(&frame);
nch = frame.nch;
error_protection = header.error_protection;
while (get_audio(musicin, buffer, num_samples, nch, &header) > 0) {
if (glopts.verbosity > 1)
if (++frameNum % 10 == 0)
fprintf(stderr, "[%4u]\r", frameNum);
fflush(stderr);
win_buf[0] = &buffer[0][0];
win_buf[1] = &buffer[1][0];
adb = available_bits(&header, &glopts);
lg_frame = adb / 8;
if (header.dab_extension) {
/* in 24 kHz we always have 4 bytes */
if (header.sampling_frequency == 1)
header.dab_extension = 4;
/* You must have one frame in memory if you are in DAB mode */
/* in conformity of the norme ETS 300 401 http://www.etsi.org */
/* see bitstream.c */
if (frameNum == 1)
minimum = lg_frame + MINIMUM;
adb -= header.dab_extension * 8 + header.dab_length * 8 + 16;
}
{
int gr, bl, ch;
/* New polyphase filter
Combines windowing and filtering. Ricardo Feb'03 */
for (gr = 0; gr < 3; gr++)
for (bl = 0; bl < 12; bl++)
for (ch = 0; ch < nch; ch++)
WindowFilterSubband(&buffer[ch][gr * 12 * 32 + 32 * bl], ch,
&(*sb_sample)[ch][gr][bl][0]);
}
#ifdef REFERENCECODE
{
/* Old code. left here for reference */
int gr, bl, ch;
for (gr = 0; gr < 3; gr++)
for (bl = 0; bl < SCALE_BLOCK; bl++)
for (ch = 0; ch < nch; ch++) {
window_subband(&win_buf[ch], &(*win_que)[ch][0], ch);
filter_subband(&(*win_que)[ch][0], &(*sb_sample)[ch][gr][bl][0]);
}
}
#endif
#ifdef NEWENCODE
scalefactor_calc_new(*sb_sample, scalar, nch, frame.sblimit);
find_sf_max(scalar, &frame, max_sc);
if (frame.actual_mode == MPG_MD_JOINT_STEREO) {
/* this way we calculate more mono than we need */
/* but it is cheap */
combine_LR_new(*sb_sample, *j_sample, frame.sblimit);
scalefactor_calc_new(j_sample, &j_scale, 1, frame.sblimit);
}
#else
scale_factor_calc(*sb_sample, scalar, nch, frame.sblimit);
pick_scale(scalar, &frame, max_sc);
#if FRAME_TRACE
FILE* canshu;
canshu = fopen("canshu.txt", "a");
if (frameNum == 2) {
fprintf(canshu, "声道数:%d\n", nch);
fprintf(canshu, "目前观测第 %d 帧\n", frameNum);
fprintf(canshu, "本帧比特预算:%d bits\n", adb);
fprintf(canshu, "\n");
/* 比例因子 */
fprintf(canshu, "========== 比例因子 ==========\n");
for (ch = 0; ch < nch; ch++) // 每个声道单独输出
{
fprintf(canshu, "------ 声道%2d ------\n", ch + 1);
for (sb = 0; sb < frame.sblimit; sb++) // 每个子带
{
fprintf(canshu, "子带[%2d]:\t", sb + 1);
for (int gr = 0; gr < 3; gr++) {
fprintf(canshu, "%2d\t", scalar[ch][gr][sb]);
}
fprintf(canshu, "\n");
}
}
fprintf(canshu, "\n");
/* 比特分配表 */
fprintf(canshu, "========== 比特分配表 ==========\n"); //输出比特分配结果
for (ch = 0; ch < nch; ch++) {
fprintf(canshu, "------ 声道%2d ------\n", ch + 1); //按声道分配
for (sb = 0; sb < frame.sblimit; sb++) {
fprintf(canshu, "子带[%2d]:\t%2d\n", sb + 1, bit_alloc[ch][sb]);
}
fprintf(canshu, "\n");
}
}
fclose(canshu);
#endif // FRAME_TRACE
if (frame.actual_mode == MPG_MD_JOINT_STEREO) {
/* this way we calculate more mono than we canshu */
/* but it is cheap */
combine_LR(*sb_sample, *j_sample, frame.sblimit);
scale_factor_calc(j_sample, &j_scale, 1, frame.sblimit);
}
#endif
if ((glopts.quickmode == TRUE) && (++psycount % glopts.quickcount != 0)) {
/* We're using quick mode, so we're only calculating the model every
'quickcount' frames. Otherwise, just copy the old ones across */
for (ch = 0; ch < nch; ch++) {
for (sb = 0; sb < SBLIMIT; sb++)
smr[ch][sb] = smrdef[ch][sb];
}
}
else {
/* calculate the psymodel */
switch (model) {
case -1:
psycho_n1(smr, nch);
break;
case 0: /* Psy Model A */
psycho_0(smr, nch, scalar, (FLOAT)s_freq[header.version][header.sampling_frequency] * 1000);
break;
case 1:
psycho_1(buffer, max_sc, smr, &frame);
break;
case 2:
for (ch = 0; ch < nch; ch++) {
psycho_2(&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT)s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
}
break;
case 3:
/* Modified psy model 1 */
psycho_3(buffer, max_sc, smr, &frame, &glopts);
break;
case 4:
/* Modified Psycho Model 2 */
for (ch = 0; ch < nch; ch++) {
psycho_4(&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT)s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
}
break;
case 5:
/* Model 5 comparse model 1 and 3 */
psycho_1(buffer, max_sc, smr, &frame);
fprintf(stdout, "1 ");
smr_dump(smr, nch);
psycho_3(buffer, max_sc, smr, &frame, &glopts);
fprintf(stdout, "3 ");
smr_dump(smr, nch);
break;
case 6:
/* Model 6 compares model 2 and 4 */
for (ch = 0; ch < nch; ch++)
psycho_2(&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT)s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout, "2 ");
smr_dump(smr, nch);
for (ch = 0; ch < nch; ch++)
psycho_4(&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT)s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout, "4 ");
smr_dump(smr, nch);
break;
case 7:
fprintf(stdout, "Frame: %i\n", frameNum);
/* Dump the SMRs for all models */
psycho_1(buffer, max_sc, smr, &frame);
fprintf(stdout, "1");
smr_dump(smr, nch);
psycho_3(buffer, max_sc, smr, &frame, &glopts);
fprintf(stdout, "3");
smr_dump(smr, nch);
for (ch = 0; ch < nch; ch++)
psycho_2(&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT)s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout, "2");
smr_dump(smr, nch);
for (ch = 0; ch < nch; ch++)
psycho_4(&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT)s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout, "4");
smr_dump(smr, nch);
break;
case 8:
/* Compare 0 and 4 */
psycho_n1(smr, nch);
fprintf(stdout, "0");
smr_dump(smr, nch);
for (ch = 0; ch < nch; ch++)
psycho_4(&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT)s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout, "4");
smr_dump(smr, nch);
break;
default:
fprintf(stderr, "Invalid psy model specification: %i\n", model);
exit(0);
}
if (glopts.quickmode == TRUE)
/* copy the smr values and reuse them later */
for (ch = 0; ch < nch; ch++) {
for (sb = 0; sb < SBLIMIT; sb++)
smrdef[ch][sb] = smr[ch][sb];
}
if (glopts.verbosity > 4)
smr_dump(smr, nch);
}
#ifdef NEWENCODE
sf_transmission_pattern(scalar, scfsi, &frame);
main_bit_allocation_new(smr, scfsi, bit_alloc, &adb, &frame, &glopts);
//main_bit_allocation (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
if (error_protection)
CRC_calc(&frame, bit_alloc, scfsi, &crc);
write_header(&frame, &bs);
//encode_info (&frame, &bs);
if (error_protection)
putbits(&bs, crc, 16);
write_bit_alloc(bit_alloc, &frame, &bs);
//encode_bit_alloc (bit_alloc, &frame, &bs);
write_scalefactors(bit_alloc, scfsi, scalar, &frame, &bs);
//encode_scale (bit_alloc, scfsi, scalar, &frame, &bs);
subband_quantization_new(scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
*subband, &frame);
//subband_quantization (scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
// *subband, &frame);
write_samples_new(*subband, bit_alloc, &frame, &bs);
//sample_encoding (*subband, bit_alloc, &frame, &bs);
#else
transmission_pattern(scalar, scfsi, &frame);
main_bit_allocation(smr, scfsi, bit_alloc, &adb, &frame, &glopts);
if (error_protection)
CRC_calc(&frame, bit_alloc, scfsi, &crc);
encode_info(&frame, &bs);
if (error_protection)
encode_CRC(crc, &bs);
encode_bit_alloc(bit_alloc, &frame, &bs);
encode_scale(bit_alloc, scfsi, scalar, &frame, &bs);
subband_quantization(scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
*subband, &frame);
sample_encoding(*subband, bit_alloc, &frame, &bs);
#endif
/* If not all the bits were used, write out a stack of zeros */
for (i = 0; i < adb; i++)
put1bit(&bs, 0);
if (header.dab_extension) {
/* Reserve some bytes for X-PAD in DAB mode */
putbits(&bs, 0, header.dab_length * 8);
for (i = header.dab_extension - 1; i >= 0; i--) {
CRC_calcDAB(&frame, bit_alloc, scfsi, scalar, &crc, i);
/* this crc is for the previous frame in DAB mode */
if (bs.buf_byte_idx + lg_frame < bs.buf_size)
bs.buf[bs.buf_byte_idx + lg_frame] = crc;
/* reserved 2 bytes for F-PAD in DAB mode */
putbits(&bs, crc, 8);
}
putbits(&bs, 0, 16);
}
frameBits = sstell(&bs) - sentBits;
if (frameBits % 8) { /* a program failure */
fprintf(stderr, "Sent %ld bits = %ld slots plus %ld\n", frameBits,
frameBits / 8, frameBits % 8);
fprintf(stderr, "If you are reading this, the program is broken\n");
fprintf(stderr, "email [mfc at NOTplanckenerg.com] without the NOT\n");
fprintf(stderr, "with the command line arguments and other info\n");
exit(0);
}
sentBits += frameBits;
}
close_bit_stream_w(&bs);
if ((glopts.verbosity > 1) && (glopts.vbr == TRUE)) {
int i;
#ifdef NEWENCODE
extern int vbrstats_new[15];
#else
extern int vbrstats[15];
#endif
fprintf(stdout, "VBR stats:\n");
for (i = 1; i < 15; i++)
fprintf(stdout, "%4i ", bitrate[header.version][i]);
fprintf(stdout, "\n");
for (i = 1; i < 15; i++)
#ifdef NEWENCODE
fprintf(stdout, "%4i ", vbrstats_new[i]);
#else
fprintf(stdout, "%4i ", vbrstats[i]);
#endif
fprintf(stdout, "\n");
}
fprintf(stderr,
"Avg slots/frame = %.3f; b/smp = %.2f; bitrate = %.3f kbps\n",
(FLOAT)sentBits / (frameNum * 8),
(FLOAT)sentBits / (frameNum * 1152),
(FLOAT)sentBits / (frameNum * 1152) *
s_freq[header.version][header.sampling_frequency]);
if (fclose(musicin) != 0) {
fprintf(stderr, "Could not close \"%s\".\n", original_file_name);
exit(2);
}
fprintf(stderr, "\nDone\n");
time(&end_time);
total_time = end_time - start_time;
printf("total time is %d\n", total_time);
exit(0);
}
/************************************************************************
*
* print_config
*
* PURPOSE: Prints the encoding parameters used
*
************************************************************************/
void print_config(frame_info* frame, int* psy, char* inPath,
char* outPath)
{
frame_header* header = frame->header;
if (glopts.verbosity == 0)
return;
fprintf(stderr, "--------------------------------------------\n");
fprintf(stderr, "Input File : '%s' %.1f kHz\n",
(strcmp(inPath, "-") ? inPath : "stdin"),
s_freq[header->version][header->sampling_frequency]);
fprintf(stderr, "Output File: '%s'\n",
(strcmp(outPath, "-") ? outPath : "stdout"));
fprintf(stderr, "%d kbps ", bitrate[header->version][header->bitrate_index]);
fprintf(stderr, "%s ", version_names[header->version]);
if (header->mode != MPG_MD_JOINT_STEREO)
fprintf(stderr, "Layer II %s Psycho model=%d (Mode_Extension=%d)\n",
mode_names[header->mode], *psy, header->mode_ext);
else
fprintf(stderr, "Layer II %s Psy model %d \n", mode_names[header->mode],
*psy);
fprintf(stderr, "[De-emph:%s\tCopyright:%s\tOriginal:%s\tCRC:%s]\n",
((header->emphasis) ? "On" : "Off"),
((header->copyright) ? "Yes" : "No"),
((header->original) ? "Yes" : "No"),
((header->error_protection) ? "On" : "Off"));
fprintf(stderr, "[Padding:%s\tByte-swap:%s\tChanswap:%s\tDAB:%s]\n",
((glopts.usepadbit) ? "Normal" : "Off"),
((glopts.byteswap) ? "On" : "Off"),
((glopts.channelswap) ? "On" : "Off"),
((glopts.dab) ? "On" : "Off"));
if (glopts.vbr == TRUE)
fprintf(stderr, "VBR Enabled. Using MNR boost of %f\n", glopts.vbrlevel);
fprintf(stderr, "ATH adjustment %f\n", glopts.athlevel);
fprintf(stderr, "--------------------------------------------\n");
#if FRAME_TRACE
FILE* canshu;
canshu = fopen("canshu.txt", "a");
fprintf(canshu, "========== 基本信息 ==========\n");
fprintf(canshu, "输入文件:%s\n", inPath);
fprintf(canshu, "输出文件:%s\n", outPath);
fprintf(canshu, "采样频率:%.1f kHz\n", s_freq[header->version][header->sampling_frequency]);
fprintf(canshu, "输出文件码率:%d kbps\n", bitrate[header->version][header->bitrate_index]);
fclose(canshu);
#endif // FRAME_TRACE
}
/************************************************************************
*
* usage
*
* PURPOSE: Writes command line syntax to the file specified by #stderr#
*
************************************************************************/
void usage (void)
{ /* print syntax & exit */
/* FIXME: maybe have an option to display better definitions of help codes, and
long equivalents of the flags */
fprintf (stdout, "\ntooLAME version %s (http://toolame.sourceforge.net)\n",
toolameversion);
fprintf (stdout, "MPEG Audio Layer II encoder\n\n");
fprintf (stdout, "usage: \n");
fprintf (stdout, "\t%s [options] <input> <output>\n\n", programName);
fprintf (stdout, "Options:\n");
fprintf (stdout, "Input\n");
fprintf (stdout, "\t-s sfrq input smpl rate in kHz (dflt %4.1f)\n",
DFLT_SFQ);
fprintf (stdout, "\t-a downmix from stereo to mono\n");
fprintf (stdout, "\t-x force byte-swapping of input\n");
fprintf (stdout, "\t-g swap channels of input file\n");
fprintf (stdout, "Output\n");
fprintf (stdout, "\t-m mode channel mode : s/d/j/m (dflt %4c)\n",
DFLT_MOD);
fprintf (stdout, "\t-p psy psychoacoustic model 0/1/2/3 (dflt %4u)\n",
DFLT_PSY);
fprintf (stdout, "\t-b br total bitrate in kbps (dflt 192)\n");
fprintf (stdout, "\t-v lev vbr mode\n");
fprintf (stdout, "\t-l lev ATH level (dflt 0)\n");
fprintf (stdout, "Operation\n");
// fprintf (stdout, "\t-f fast mode (turns off psy model)\n");
// deprecate the -f switch. use "-p 0" instead.
fprintf (stdout,
"\t-q num quick mode. only calculate psy model every num frames\n");
fprintf (stdout, "Misc\n");
fprintf (stdout, "\t-d emp de-emphasis n/5/c (dflt %4c)\n",
DFLT_EMP);
fprintf (stdout, "\t-c mark as copyright\n");
fprintf (stdout, "\t-o mark as original\n");
fprintf (stdout, "\t-e add error protection\n");
fprintf (stdout, "\t-r force padding bit/frame off\n");
fprintf (stdout, "\t-D len add DAB extensions of length [len]\n");
fprintf (stdout, "\t-t talkativity 0=no messages (dflt 2)");
fprintf (stdout, "Files\n");
fprintf (stdout,
"\tinput input sound file. (WAV,AIFF,PCM or use '/dev/stdin')\n");
fprintf (stdout, "\toutput output bit stream of encoded audio\n");
fprintf (stdout,
"\n\tAllowable bitrates for 16, 22.05 and 24kHz sample input\n");
fprintf (stdout,
"\t8, 16, 24, 32, 40, 48, 56, 64, 80, 96, 112, 128, 144, 160\n");
fprintf (stdout,
"\n\tAllowable bitrates for 32, 44.1 and 48kHz sample input\n");
fprintf (stdout,
"\t32, 48, 56, 64, 80, 96, 112, 128, 160, 192, 224, 256, 320, 384\n");
exit (1);
}
/*********************************************
* void short_usage(void)
********************************************/
void short_usage (void)
{
/* print a bit of info about the program */
fprintf (stderr, "tooLAME version %s\n (http://toolame.sourceforge.net)\n",
toolameversion);
fprintf (stderr, "MPEG Audio Layer II encoder\n\n");
fprintf (stderr, "USAGE: %s [options] <infile> [outfile]\n\n", programName);
fprintf (stderr, "Try \"%s -h\" for more information.\n", programName);
exit (0);
}
/*********************************************
* void proginfo(void)
********************************************/
void proginfo (void)
{
/* print a bit of info about the program */
fprintf (stderr,
"\ntooLAME version 0.2g (http://toolame.sourceforge.net)\n");
fprintf (stderr, "MPEG Audio Layer II encoder\n\n");
}
/************************************************************************
*
* parse_args
*
* PURPOSE: Sets encoding parameters to the specifications of the
* command line. Default settings are used for parameters
* not specified in the command line.
*
* SEMANTICS: The command line is parsed according to the following
* syntax:
*
* -m is followed by the mode
* -p is followed by the psychoacoustic model number
* -s is followed by the sampling rate
* -b is followed by the total bitrate, irrespective of the mode
* -d is followed by the emphasis flag
* -c is followed by the copyright/no_copyright flag
* -o is followed by the original/not_original flag
* -e is followed by the error_protection on/off flag
* -f turns off psy model (fast mode)
* -q <i> only calculate psy model every ith frame
* -a downmix from stereo to mono
* -r turn off padding bits in frames.
* -x force byte swapping of input
* -g swap the channels on an input file
* -t talkativity. how verbose should the program be. 0 = no messages.
*
* If the input file is in AIFF format, the sampling frequency is read
* from the AIFF header.
*
* The input and output filenames are read into #inpath# and #outpath#.
*
************************************************************************/
void parse_args (int argc, char **argv, frame_info * frame, int *psy,
unsigned long *num_samples, char inPath[MAX_NAME_SIZE],
char outPath[MAX_NAME_SIZE])
{
FLOAT srate;
int brate;
frame_header *header = frame->header;
int err = 0, i = 0;
long samplerate;
/* preset defaults */
inPath[0] = '\0';
outPath[0] = '\0';
header->lay = DFLT_LAY;
switch (DFLT_MOD) {
case 's':
header->mode = MPG_MD_STEREO;
header->mode_ext = 0;
break;
case 'd':
header->mode = MPG_MD_DUAL_CHANNEL;
header->mode_ext = 0;
break;
/* in j-stereo mode, no default header->mode_ext was defined, gave error..
now default = 2 added by MFC 14 Dec 1999. */
case 'j':
header->mode = MPG_MD_JOINT_STEREO;
header->mode_ext = 2;
break;
case 'm':
header->mode = MPG_MD_MONO;
header->mode_ext = 0;
break;
default:
fprintf (stderr, "%s: Bad mode dflt %c\n", programName, DFLT_MOD);
abort ();
}
*psy = DFLT_PSY;
if ((header->sampling_frequency =
SmpFrqIndex ((long) (1000 * DFLT_SFQ), &header->version)) < 0) {
fprintf (stderr, "%s: bad sfrq default %.2f\n", programName, DFLT_SFQ);
abort ();
}
header->bitrate_index = 14;
brate = 0;
switch (DFLT_EMP) {
case 'n':
header->emphasis = 0;
break;
case '5':
header->emphasis = 1;
break;
case 'c':
header->emphasis = 3;
break;
default:
fprintf (stderr, "%s: Bad emph dflt %c\n", programName, DFLT_EMP);
abort ();
}
header->copyright = 0;
header->original = 0;
header->error_protection = FALSE;
header->dab_extension = 0;
/* process args */
while (++i < argc && err == 0) {
char c, *token, *arg, *nextArg;
int argUsed;
token = argv[i];
if (*token++ == '-') {
if (i + 1 < argc)
nextArg = argv[i + 1];
else
nextArg = "";
argUsed = 0;
if (!*token) {
/* The user wants to use stdin and/or stdout. */
if (inPath[0] == '\0')
strncpy (inPath, argv[i], MAX_NAME_SIZE);
else if (outPath[0] == '\0')
strncpy (outPath, argv[i], MAX_NAME_SIZE);
}
while ((c = *token++)) {
if (*token /* NumericQ(token) */ )
arg = token;
else
arg = nextArg;
switch (c) {
case 'm':
argUsed = 1;
if (*arg == 's') {
header->mode = MPG_MD_STEREO;
header->mode_ext = 0;
} else if (*arg == 'd') {
header->mode = MPG_MD_DUAL_CHANNEL;
header->mode_ext = 0;
} else if (*arg == 'j') {
header->mode = MPG_MD_JOINT_STEREO;
} else if (*arg == 'm') {
header->mode = MPG_MD_MONO;
header->mode_ext = 0;
} else {
fprintf (stderr, "%s: -m mode must be s/d/j/m not %s\n",
programName, arg);
err = 1;
}
break;
case 'p':
*psy = atoi (arg);
argUsed = 1;
break;
case 's':
argUsed = 1;
srate = atof (arg);
/* samplerate = rint( 1000.0 * srate ); $A */
samplerate = (long) ((1000.0 * srate) + 0.5);
if ((header->sampling_frequency =
SmpFrqIndex ((long) samplerate, &header->version)) < 0)
err = 1;
break;
case 'b':
argUsed = 1;
brate = atoi (arg);
break;
case 'd':
argUsed = 1;
if (*arg == 'n')
header->emphasis = 0;
else if (*arg == '5')
header->emphasis = 1;
else if (*arg == 'c')
header->emphasis = 3;
else {
fprintf (stderr, "%s: -d emp must be n/5/c not %s\n", programName,
arg);
err = 1;
}
break;
case 'D':
argUsed = 1;
header->dab_length = atoi (arg);
header->error_protection = TRUE;
header->dab_extension = 2;
glopts.dab = TRUE;
break;
case 'c':
header->copyright = 1;
break;
case 'o':
header->original = 1;
break;
case 'e':
header->error_protection = TRUE;
break;
case 'f':
*psy = 0;
/* this switch is deprecated? FIXME get rid of glopts.usepsy
instead us psymodel 0, i.e. "-p 0" */
glopts.usepsy = FALSE;
break;
case 'r':
glopts.usepadbit = FALSE;
header->padding = 0;
break;
case 'q':
argUsed = 1;
glopts.quickmode = TRUE;
glopts.usepsy = TRUE;
glopts.quickcount = atoi (arg);
if (glopts.quickcount == 0) {
/* just don't use psy model */
glopts.usepsy = FALSE;
glopts.quickcount = FALSE;
}
break;
case 'a':
glopts.downmix = TRUE;
header->mode = MPG_MD_MONO;
header->mode_ext = 0;
break;
case 'x':
glopts.byteswap = TRUE;
break;
case 'v':
argUsed = 1;
glopts.vbr = TRUE;
glopts.vbrlevel = atof (arg);
glopts.usepadbit = FALSE; /* don't use padding for VBR */
header->padding = 0;
/* MFC Feb 2003: in VBR mode, joint stereo doesn't make
any sense at the moment, as there are no noisy subbands
according to bits_for_nonoise in vbr mode */
header->mode = MPG_MD_STEREO; /* force stereo mode */
header->mode_ext = 0;
break;
case 'l':
argUsed = 1;
glopts.athlevel = atof(arg);
break;
case 'h':
usage ();
break;
case 'g':
glopts.channelswap = TRUE;
break;
case 't':
argUsed = 1;
glopts.verbosity = atoi (arg);
break;
default:
fprintf (stderr, "%s: unrec option %c\n", programName, c);
err = 1;
break;
}
if (argUsed) {
if (arg == token)
token = ""; /* no more from token */
else
++i; /* skip arg we used */
arg = "";
argUsed = 0;
}
}
} else {
if (inPath[0] == '\0')
strcpy (inPath, argv[i]);
else if (outPath[0] == '\0')
strcpy (outPath, argv[i]);
else {
fprintf (stderr, "%s: excess arg %s\n", programName, argv[i]);
err = 1;
}
}
}
if (header->dab_extension) {
/* in 48 kHz */
/* if the bit rate per channel is less then 56 kbit/s, we have 2 scf-crc */
/* else we have 4 scf-crc */
/* in 24 kHz, we have 4 scf-crc, see main loop */
if (brate / (header->mode == MPG_MD_MONO ? 1 : 2) >= 56)
header->dab_extension = 4;
}
if (err || inPath[0] == '\0')
usage (); /* If no infile defined, or err has occured, then call usage() */
if (outPath[0] == '\0') {
/* replace old extension with new one, 1992-08-19, 1995-06-12 shn */
new_ext (inPath, DFLT_EXT, outPath);
}
if (!strcmp (inPath, "-")) {
musicin = stdin; /* read from stdin */
*num_samples = MAX_U_32_NUM;
} else {
if ((musicin = fopen (inPath, "rb")) == NULL) {
fprintf (stderr, "Could not find \"%s\".\n", inPath);
exit (1);
}
parse_input_file (musicin, inPath, header, num_samples);
}
/* check for a valid bitrate */
if (brate == 0)
brate = bitrate[header->version][10];
/* Check to see we have a sane value for the bitrate for this version */
if ((header->bitrate_index = BitrateIndex (brate, header->version)) < 0)
err = 1;
/* All options are hunky dory, open the input audio file and
return to the main drag */
open_bit_stream_w (&bs, outPath, BUFFER_SIZE);
}
void smr_dump(double smr[2][SBLIMIT], int nch) {
int ch, sb;
fprintf(stdout,"SMR:");
for (ch = 0;ch<nch; ch++) {
if (ch==1)
fprintf(stdout," ");
for (sb=0;sb<SBLIMIT;sb++)
fprintf(stdout,"%3.0f ",smr[ch][sb]);
fprintf(stdout,"\n");
}
}
参考
总结
通过对资源的整合,完善了打印代码,实现了对音频采样率和目标码率的分析。同时准备了三种不同内容特点的音频,通过编码程序的分析,我们输出了这3中不同特点音频的不同数据帧的该帧所分配的比特数,该帧的比例因子和该帧的比特分配结果。















 94
94











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









