







import numpy as np
import pandas as pd
import time
np.random.seed(2)#随机数种子
N_STATES=6 #多少种状态
ACTIONS=['left','right']#动作
EPSILON=0.9# 行为策略epsilon-greedy,用于收集经验(10%随机动作,90%最优动作)
ALPHA=0.1# 学习率
LAMBDA=0.9#折扣率(对将来奖励的折扣,lambda)
MAX_EPISODES=13# 训练回合数
FRESH_TIME=0.1#每走一步花费的时间
def build_q_table(n_states,actions):#初始化Q表格
table=pd.DataFrame(
np.zeros((n_states,len(actions))),
columns=actions,
)
# print(table)
return table
def choose(state,q_table):#选动作
state_action=q_table.iloc[state,:]
if (np.random.uniform()>EPSILON) or (state_action.all()==0):#大于0.9时,随机选择一个action(或者为初始情况,Q表格全为0)
action_name=np.random.choice(ACTIONS)
else:
action_name=state_action.idxmax()#小于0.9时,选择该状态这一行中,对应Q表格值最大的动作
return action_name
def get_env_feedback(S,A):#环境对当前状态s下action的反馈,
if A=='right':
if S==N_STATES-2:
S_='terminal'
R=1
else:
S_=S+1
R=0
else:
R=0
if S==0:
S_=S
else:
S_=S-1
return S_,R
def update_env(S,episode,step_counter):#环境,将环境呈现(不重要)
env_list=['-']*(N_STATES-1)+['T']
if S=='terminal':
interaction='Episode %s :total_steps= %s '%(episode+1,step_counter)
print('\r{}'.format(interaction),end='')
time.sleep(2)
print('\r ',end='')
else:
env_list[S]='o'
interaction=''.join(env_list)
print('\r{}'.format(interaction),end='')
time.sleep(FRESH_TIME)
def RL():#训练过程
q_table=build_q_table(N_STATES,ACTIONS)#初始化表格
for episode in range(MAX_EPISODES):
step_counter=0
S=0#agent初始位置
is_terminated=False
update_env(S,episode,step_counter)
while not is_terminated:#未到达终点
A=choose(S,q_table)#获取动作
S_,R=get_env_feedback(S,A)#执行动作,获得state+1和reward
q_predict=q_table.loc[S,A]
if S_!='terminal':
q_target=R+LAMBDA*q_table.iloc[S_,:].max()
else:
q_target=R
is_terminated=True
q_table.loc[S,A]+=ALPHA*(q_target-q_predict)
S=S_
update_env(S,episode,step_counter+1)
step_counter+=1
return q_table
if __name__=="__main__":
q_table=RL()
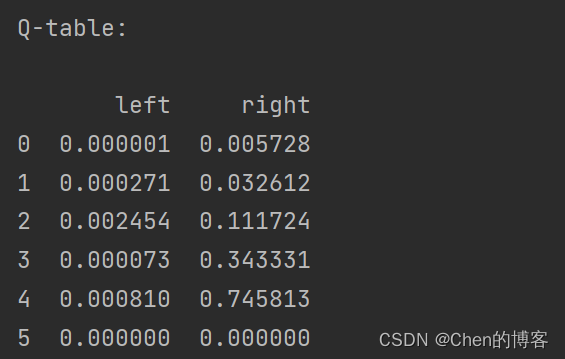
print('\r\nQ-table:\n')
print(q_table)

之所以最后步数一直跳到7是因为,我们choose函数会选择一个随机的动作
最后输出Q-learning学习完成的表格















 1065
1065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











