







python爬虫之scrapy框架详解
目录
1.认识scrapy
1.1三次握手
1.2爬虫的基本流程
1.3scrapy框架爬虫
2.scrapy项目实战学习
3.理解scrapy原理
4.学习scrapy的图片下载器
写在前面
今天是中秋节,为了记录前一段时间学习到的东西,或者说,为了在日后能够有印象学过scrapy,中秋节的时间比较充裕,所以今天就好好的将所学的scrapy知识记录下来,文章比较长,请耐心学习,希望能够帮到您。
1.认识scrapy
想要认识scrapy,首先还是得有一些爬虫的基础的,回忆一下基础爬虫,分为通用爬虫、聚焦爬虫、增量爬虫。爬虫就是模拟人的上网流程,让服务器以为是一个人在浏览网页并且获得其想要的数据。人浏览网页都是需要浏览器的,那么爬虫也就是模拟浏览器与服务器通信的过程,再加上一些数据处理的技巧和方法。
1.1三次握手
浏览器与服务器通信主要是通过Internet进行通信,也就是浏览器发起请求,服务器收到请求并发起一个收到请求通知给浏览器,浏览器收到服务器通知后,再次发出一份通知告知服务器,你的通知我已经收到了,等会要发送数据了,你下一次看到的就是我的数据了,无需要回复,服务器收到浏览器通知后,发出已经收到这一次通知了,你发数据请求就好,最后浏览器开始发起请求了。这就是三次握手大致的理解。
1.2爬虫的基本流程
- 发起请求
- 解析收到的响应数据
- 持久化需要的数据
- 关闭爬虫
1.3scrapy框架爬虫
scrapy是一个纯python编写的异步爬虫框架,既然是框架,就是集成好了基本爬虫的所有步骤,不然框架的意义也不大,因此变得非常的简单,而且是非常的灵活,能够按照自己的需求去爬取相应的数据,改写相应的类方法,就能够达到很好的效果。
随便在网上搜一下scrapy,都会看到讲解很对原理性的,本文主要面对的是初学者,那么我们就不摆出那副漂亮的图来迷惑大家了。实战为主,我觉得,从项目入手,然后再来讲解原理图。
2.scrapy项目实战学习
一切项目的源头都是需求,那么我们就以需求为主,这里主要是以无需要登录的百度新闻网为主,链接:http://news.baidu.com/首页看到的是非常多的新闻,我们就以抓取首页热点要闻为主,来认识一下scrapy爬虫。

首先你必须学会安装scrapy,但是这个不是本文的内容,所以请移步安装。本文所使用的平台为windows10、pycharm、python3.7,安装好了之后,开始学习我们的第一个命令:
- 创建一个爬虫项目:scrapy startproject baidunews 这条语句,如果是学习过Django框架的人很容易潜意识的发现非常类似。这里创建了一个scrapy项目,名字叫baidunews
- 打开文件目录
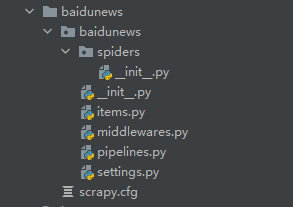
长成这样就是对的,初学者肯定不知道这些文件有什么作用,因为我们并没有讲解原理,直接干项目,也请你不要着急,耐心学习,就像我耐心的写下去一样。我们先分析一下这里的文件:
- scrapy.cfg 是一个部署文件,做过web项目的人应该都知道,最后成功的项目都需要进行部署,才能不要人工的去监护,最好理解
- spiders文件夹,中文意思叫做蜘蛛,不会的就百度翻译一下,传送门https://fanyi.baidu.com/?aldtype=16047#auto/zh,爬虫的本来意思就是一只蜘蛛在网页图上爬取数据,对吧,也就是说这里就是你要编写的爬虫文件,但是这里除了__init__.py 文件 什么也没有。所以我们得创建一个爬虫文件,首先需要进入spiders文件夹,在终端输入命令:scrapy genspider getnews www.xxx.com,这个与Django的创建app命令非常的相似,给爬虫项目创建了一个名为getnews 的爬虫文件,后面的域名可以先不管他,我们先看看效果。
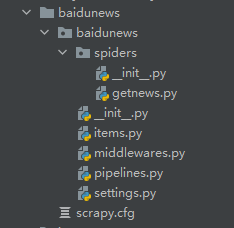
是不是多了一个 getnews.py文件 呢,进去里面看看,有什么东西:
import scrapy
class GetnewsSpider(scrapy.Spider):
name = 'getnews'
allowed_domains = ['www.xxxx.com']
start_urls = ['http://www.xxxx.com/']
def parse(self, response):
pass
看到了没有,这里面的东西好像认识一点英语单词的都能够猜得八九不离十,名字、允许域名、开始访问的URL,本文一概不会用到允许域名,所以将allowed_domains = ['www.xxxx.com']进行注释,现在已经完成爬虫文件的创建了。所有准备工作都已经完成了。
接下来,有点神奇,别眨眼,你把请求链接放进去,放在 start_urls 的列表里面,然后在parse函数里面,你把下面的代码放进去,等会给你解释。
response.xpath('//*[@id="pane-news"]/div/ul/li[1]//text()')
这里涉及到了xpath,若是未学习过xpath,请移步,不过一般学到了scrapy这一步了,xpath语法应该会有一点了解的,好了,print() 出来上述语句的结果,然后到终端,输入你要学习的第三条语句: scrapy crawl getnewws 按下确认键,得到了一堆你不想看到的结果:

这是一些日志,在 setting.py 里面配置一下,
LOG_LEVEL = "ERROR"
ROBOTSTXT_OBEY = False
上面配置了两个东西,一个是将终端的日志删去了,第二个是将robots协议关闭了,我觉得你应该会认识robots协议吧,毕竟都学习到了框架这一步,这里说一下,tobots协议在setting.py文件里面是已经存在的,默认为True。如果实在不认识robots协议,在谷歌浏览器打开一个网站,比如说百度,在其url后面加 /robots.txt 回车:https://www.baidu.com/robots.txt你就能够看到结果了
回过头来,设置好了上述两个,然后进行:scrapy crawl getnewws 见证奇迹的时候到了,是不是看到了你想要的结果,第一个标题的名字。
接下来我们将爬虫函数补充完整:
def parse(self, response):
li_list = response.xpath('//*[@id="pane-news"]/div/ul/li')
for li in li_list:
url = li.xpath('./strong/a/@href')
name = li.xpath('./strong/a//text()')
print(name,url)
运行结果为:

是不是有点像样子啦,然后我们还要更加深入的学习,这里是最基本的获取的数据并且解析出来了数据,感觉一下,会不会比你原始的爬虫好用点。到现在你并不知道scrapy 的原理,非常棒。
接下来,我们到了持久化存储这一步了,让你吃惊的还在下面,你要跟着我的步伐,一步步的操作,别走神。
学过爬取ajax的同学应该都知道,这个需要的是 json 的持久化存储,而 json 格式,很像我们的 dict 格式,这个是学习过 python 都知道的。字典形式这里回顾一下,跟着我走,下面:
item = {
'url':url,
'name':name
}
常规的字典就是这样,但是,就是因为是这样,所以scrapy将数据进行了存储,我们将刚刚的字典放在parse函数之下:
def parse(self, response):
li_list = response.xpath('//*[@id="pane-news"]/div/ul/li')
for li in li_list:
url = li.xpath('./strong/a/@href')
name = li.xpath('./strong/a//text()')
item = {
'url':url,
'name':name
}
yield item
最后的yield关键字一定要记住,这是scrapy固定格式,那么深入学习过python的都知道,这样形成一个迭代器的东西。你也可以将其翻译成 “提交” ,scrapy将item提交给了管道(pipelines.py),但是需要在items.py 上声明好变量,也就是item里面的key,这是scrapy的固定用法,在我看来,scrapy也就是只有这一点需要认真的去背诵的,声明的代码如下:
import scrapy
class BaidunewsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()
name = scrapy.Field()
既然都已经提交到了pipelines.py 那么我们就需要接收一下过来的数据吧。
首先看看pipelines.py里面是否真的接收到了数据。
class BaidunewsPipeline:
def process_item(self, item, spider):
print(item)
print("1212121212")
return item
这里需要郑重的声明一个事情,process_item 函数必须有return item,原因很简单,但是不去细想的话,可能想不到,我这里提示一下,记得parse函数中的yield关键字不,其实这里形成了一个闭环的流,到这才算是结束了一个轮回。我们运行一下,在运行之前,进入setting.py中进行打开pipelines。
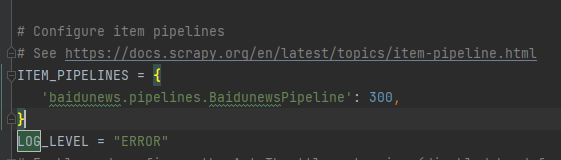
300代表的是优先级,数字越小,优先级越高,比如好几个pipelines,那么我们就可以设置优先级,去满足我们的需求。
开始运行:scrapy crawl getnews
可以看到结果啦:

完美,然后持久化,就是建立一个文件,将数据存储进去,我们新建一个txt文件
class BaidunewsPipeline:
def process_item(self, item, spider):
with open('baidunews.txt',mode='a+',encoding='utf-8') as fd:
fd.write(item['name'])
fd.write(item['url'])
fd.write('\n')
print('ok')
return item
这样就将数据保存到了txt,但是你们肯定会出现问题,知道为什么呢?因为不能将Selector对象写入到txt文件中,回到getnews.py中,将代码改一下:

到此为止,你已经将所有基础的scrapy爬虫技术做了一遍,非常不容易,为什么呢,我到现在已经差不多书写6000字进行讲述了。让我休息一下,一会,好了,我们进行下一步吧。
3.理解scrapy原理
回顾一下我们上述的流程,也许你忘记了,那你就拿着小本本,看着我,跟着我,我来写。我们首先建立了一个项目,这个项目是scrapy项目,我们使用的是一条语句:scrapy startproject baidunew,一个项目会有一个中心的点,叫做引擎,其实所有的框架都有一个支撑起全局的点,这个点非常的重要,有人称为内核。scrapy叫做引擎,管理着全局,这个是默认的点。然后我们通过一条response.xpath 语句进行了解析原始数据,得到我们想要的数据了。通过常规爬虫我们知道,这中间省略了很多步骤,首先是对目标网站发起请求,然后服务器拿到请求后,进行分析,打包响应数据,返回给请求对象。通过我们刚刚的操作,好像所有都省略看不到了,当然看到了就不叫框架了,对吧!!!
我们只是在爬虫文件中编写了我们所需要的解析代码,因此,scrapy项目中有一个重要的东西是爬虫文件,还记得叫啥不,我猜你可能不记得了,叫做spider。但是我们看不到不代表没有,因此我们猜测一下,还会有什么东西呢,网页是需要进行下载的,所有能不能少了下载呢?
答案是不能的,scrapy中还有下载器。
其实一开头我已经说了,scrapy是一个异步的爬虫框架,想到异步我们肯定会想到进程、线程、协程。如果没有,你的基础应该在打结实一点。因此,我们少不了进程之间的调度问题,因此还有调度器。所有的好像很齐全,再想想还有什么?
管道,持久化存储。

那么我们就可以进行流程分析了:首先一个项目我们一开始是从spider开始编写的吧,那么启动的时候,spider提交给引擎,然后引擎驱使调度器,开启一个程序进行调度,并生成Request对象给下载器,下载器收到后,到互联网进行下载,打包生成response,然后返回给引擎,引擎又给spider解析,spider解析完成后进行item生成,然后进行返回给引擎,最后引擎给了pipelines持久化存储。

好了到此为止,scrapy的基本原理你已经学明白了
4.学习scrapy的图片下载器
记得我们传统的爬虫对于下载图片吗?我猜你肯定忘了,因为你更本想不起来以前对于web的爬虫爬取图片的。相信你一定做过爬取豆瓣电影、糗事百科图片的相应的项目,那个是将所有的图片的链接下载下来本地,然后对于图片进行request请求,然后进行二进制数据的下载,到此你应该有点印象了是吧。还不行的话,我再出一篇爬取图片的文章,敬请关注吧。
scrapy是一个集成的框架,肯定不能够再让你去繁琐的发起请求,这样消耗的资源巨大,并且效率低下;还有一个问题就是,机器是不能够分辨出你是否重复爬取相同的图片的。scrapy提供了一套全新的爬取机制,这就是MediaPipeline,分为FilesPipeline和ImagesPipeline机制。看到没,这个是管道,管道,管道,也就是说是用来存储的。
同上面的套路一样,我们先用项目来做,就壁纸族那个吧。传送门:https://m.bizhizu.cn/
首先将start_urls 替换成上面的链接,然后将getnews.py代码替换成下面的。
import scrapy
from baidunews.items import BaidunewsItem
class GetnewsSpider(scrapy.Spider):
name = 'getnews'
# allowed_domains = ['www.xxxx.com']
start_urls = ['https://m.bizhizu.cn/shouji/']
def parse(self, response):
div_list = response.xpath('//*[@id="section"]/div/div[3]//div[@class="sec_block_content"]')
for div in div_list:
# # url = li.xpath('./strong/a/@href').extract_first()
# # name = li.xpath('./strong/a//text()').extract_first()
# filenames = div.xpath('./dl/dt/a//text()').extract()
file_urls = div.xpath('./dl/dd/a/img/@src').extract()
for image in file_urls:
item = BaidunewsItem()
print(image,111111)
item['filenames'] = image
yield item
这里没有什么特别的东西,就是加了一个循环而已,如果看不懂,可以留言,也可以来问我,下面有微信码,解释一下extract函数与extract_first()函数,第一个是用来抽取元素标签下面所有的东西(你想要的),第二个是只提取第一个,item变量是一个实例化,而这个类对象书写在Items.py文件里面。其他的没有什么好解释的。
然后给出items.py 代码:
import scrapy
class BaidunewsItem(scrapy.Item):
file_urls = scrapy.Field()
书写pepilines.py代码:
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
class BaidunewsPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
yield scrapy.Request(item['filenames'])
def item_completed(self, results, item, info):
return item
def file_path(self, request, response=None, info=None, *, item=None):
print(request.url.split("/")[-1])
imagname = request.url.split("/")[-1]
return imagname
里面的函数重写的,因为我们是继承ImagesPipeline类的,第一个get_media_requests函数,用来下载每一个提交过来的链接的,第二个item_completed是在get_media_requests函数下载完提交过来的一次链接运行的,与我们的原来的parse函数是一样的道理,也就是那张图的循环最后一步,算了我还是把图再放一遍吧。

最后一个函数是用来存储变量的位置的,我们必须在setting.py中声明一个位置:
IMAGES_STORE = './images'
那么我们的图片就会存储在根目录下的images目录中,然后保存的名字为请求的url的最后一个名字,但是这个名字可能会通过哈希加密算法进行压缩。
跑一下:scrapy crawl getnews
好了,到此,我们已经学习了scrapy的基本爬虫技能了,本文到此就是结束,本来还想讲一讲爬虫中间件和下载中间件的,但是呢!突然感觉那些都是进阶的内容,本文适合想学习scrapy的兄弟姐妹们,到此,本文已经书写10000字,码字不易,但是我以后还是会尽力去记录我得日常学习的,谢谢你看完了,能跟下来不容易呀,如果本文你还有什么疑问,请加我微信,备注好你的来意。

如果这篇文章对你有帮助,码字不易,码农更不易,请支持一下谢谢你:
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









