







一、apply
- apply作用就是迭代每一列的值
展示apply的作用
先读入文件
df = pd.read_csv('table.csv')
df.head()

- Series
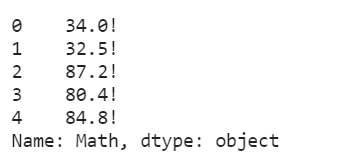
Q1:现在需要把Math这一列的所有值后面加上!
S:
这里的问题相当于是对Series求解,使用apply结合lambda迭代每一列的值
df['Math'].apply(lambda x: str(x)+'!').head()
- DataFrame
Q2: 现在给这个表的所有列均加上符号!
S:
df.apply(lambda x: x.apply(lambda x: str(x)+'!')).head()

小结1:
第一部分主要的知识点为学会运用apply并理解掌握;
记住给一个表的某一或几列的所有值加上特殊符号:变成str形式+特殊符号;
二、矢量化字符串
1、为何使用str属性?
我们使用的是文本数据,要想对每个元素进行操作,一般使用str属性,可方便使用操作;
2、举个栗子
我们先创建一个dataframe
index = pd.Index(data=["Tom", "Bob", "Mary", "James", "Andy", "Alice"], name="name")
data = {
"age": [18, 30, np.nan, 40, np.nan, 30],
"city": ["Bei Jing ", "Shang Hai ", "Guang Zhou", "Shen Zhen", np.nan, " "],
"sex": [None, "male", "female", "male", np.nan, "unknown"],
"birth": ["2000-02-10", "1988-10-17", None, "1978-08-08", np.nan, "1988-10-17"]
}
user_info = pd.DataFrame(data=data, index=index)
# 将出生日期转为时间戳
user_info["birth"] = pd.to_datetime(user_info.birth)
user_info

!!!强调apply作用:在对 Series 中每个元素处理时,我们可以使用apply 方法。
【关系】在对DataFrame单独取一列元素=Series
2.1 .str.lower
Q3:把city全部变成小写
S:
user_info.city.str.lower()

【回忆助记】
-
为啥这种写法可行user_info.city?来源是?
答:我们需要解决的是对这个表(DF型)的city列的所有值全部变成小写:那这种形式其实是Series,取Series的值,采用.value;
series获取属性,其实和java类似,都是以"."的方式获取属性和方法。
小结2:
对Series的元素转换大小写等字符串问题的,采取str属性;
df.city.str.lower
2.2 替换和分割
2.2.1 替换
使用.str属性不仅支持大小写转换求长度等,还支持替换和分割操作;
Q4: 把city这一列空字符串用_替换
S:
替换用str.replace(“old_string”,“new_string”);
user_info.city.str.replace(' ',"_")

- replace支持正则表达式
user_info.city.str.replace("^S.*"," ")

【拓展补充正则表达式】
一些常用术语
? 通配符匹配文件名中的 0 个或 1 个字符,而 * 通配符匹配零个或多个字符;
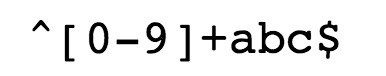
^ 为匹配输入字符串的开始位置。
[0-9]+匹配多个数字, [0-9] 匹配单个数字,+ 匹配一个或者多个。
abc$匹配字母 abc 并以 abc 结尾,$ 为匹配输入字符串的结束位置。
语法:
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为"元字符")组成的文字模式。
普通字符
- \s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。
- [\s\S] 表示匹配所有
- \w 表示匹配字母、数字、下划线。
特殊字符
- $: 匹配输入字符串的结尾位置。
- * : 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 *。
- +: 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 +。
- ?: 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 ?。
- ^: 匹配输入字符串的开始位置
2.2.2 分割
Python split() 通过指定分隔符对字符串进行切片
Q5:以空格分割city
S:
user_info.city.str.split(" ")

分割列表中的元素可以使用 get 或 [] 符号进行访问:
分割后的元素若想获取,可用get或[]进行访问
user_info.city.str.split(" ").str[1]
user_info.city.str.split(" ").str.get(1)

设置参数 expand=True 可以轻松扩展此项以返回 DataFrame。
user_info.city.str.split(" ",expand=True)

小结3:
str属性不仅支持大小写转换等还支持分割&替换;
- 替换用.str.replace(“old”,“new”);
- replace还支持正则表达式,熟悉常用的术语:\s\S,\w,.*?,^,$等
- 分割split()
- 若想获取分割后的元素,用get或[]获取
- 想以DF形式返回,则加上expand=True;















 3857
3857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









