






异构信息网络上的对抗性学习
摘要
网络嵌入是一种在低维空间中表示网络数据的方法,在异构信息网络分析中得到广泛应用。虽然现有的HIN嵌入方法在一定程度上实现了性能的提升,但仍存在一些不足之处。最重要的是,它们通常采用负抽样的方法从网络中随机选择节点,而不去学习底层的分布以获得更好的鲁棒嵌入。受到生成对抗网络(GAN)的启发,我们为HIN嵌入开发了一个新的框架HeGAN,它在极小极大游戏中训练识别器和生成器。与现有HIN嵌入方法相比,我们的生成器可以学习节点分布,生成更好的负样本。与同构网络上的GANs相比,我们的鉴别器和生成器被设计成关系感知的,以捕获HINs上丰富的语义。此外,为了更有效和更高效的采样,我们提出了一种广义生成器,它直接从连续分布中对“潜在”节点进行采样,而不像现有方法那样局限于原始网络中的节点。
简介
网络结构在现实世界的应用中是无处不在的,从社会和生物网络到交通和电信系统。因此,网络分析对于解决社交网络上的个性化用户推荐、生物网络上的疾病基因识别等关键问题越来越重要。这些问题往往表现为对网络数据进行节点聚类、节点分类和链路预测等,从根本上依赖于一种有效的网络表示形式。近年来,网络嵌入已成为无监督学习节点表示的一个有前途的方向,其目的是将网络节点投射到低维空间中,同时保持原网络的结构特性。
虽然早期的网络嵌入工作已经取得了相当大的成功,但他们只能处理所谓的同构网络(例如以论文为例于在同构网络中与论文a有关的可能是论文b,c等等只包含论文这一个类型)。然而,在实际场景中,节点自然地对不同类型的实体建模,这些实体通过多种关系相互交互。这种网络被称为异构信息网络(HIN)如图1(a)所示 。如图1(b-1)所示现有的HIN嵌入方法从根本上归结为两个取样器,以p2为例选择p2有关的节点作为正样本,并且利用负抽样(随机选择网络中的存在的节点)作为负样本,然后在这些样本上训练一个损失函数来优化节点表示。虽然这样取得了一些性能上的改进,但也存在严重的局限性,首先它们因为利用负抽样,因此,它们的负样本不仅不是任意的,而且也局限于原始的网络。其次,它们主要关注于在HIN上捕获丰富的语义,而不注意节点的底层分布,因此对于一般的HIN上述方法缺乏健壮性。第三它们依赖适当的路径来匹配期望的语义,这通常需要领域知识,而这些知识有时是主观的,而切通常获取起来很昂贵。
考虑现有方法的上述局限性,因此我们利用在对抗性设置下HIN的异构性然而我们需要解决两个主要挑战。
1.如何捕获更多类型节点和关系的语义?在现有的方法中真假节点仅由网络结构区分因此,设计新型的鉴别器和生成器,对各种关系中涉及的语义丰富的真假节点区分和建模是必须的。
2.如何高效地生成虚假样本?在现有的方法中,生成器学习网络学习网络中节点的有限离散分布。因此他们经常需要计算棘手的softmax函数,并最终诉诸于近似。此外,它们本质上是根据学习到的分布从原始网络中选择一个现有节点,而不具备泛化到“不可见”节点的能力。毫不奇怪,它们不会生成最具代表性的假节点,因为这样的节点甚至可能不会出现在网络中。因此,设计一个能有效生成潜在假样本的生成器是非常重要的。
为了解决上述挑战,我们提出了HEGAN特别地,我们提出了一种新的鉴别器和发生器的形式,如图1(b-2)所示,对第一个挑战我们的鉴别器和发生成器被设计成关系感知的,以便区分不同关系连接的节点。对于任何关系鉴别器都可以分辨出节点是真是假,而生成器可以模拟真节点对生成假节点对。而一个节点对如何被区分为真的则有两个依据1.它是基于网络拓扑的正对,2.这个节点对是在正确的关系下形成的。对于第二个挑战,我们设计了一个广义生成器,它能够直接从连续分布中抽取潜在节点这样的好处是1.不需要进行softmax计算,2.虚假样本不局限于现有节点。
图一:

初步工作
图二:

在本文中,我们将形式化HIN的嵌入问题,图2总结了主要的符号。我们的研究重点是异构信息网络其定义如下:
异构信息网络(HIN):
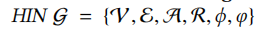
我们的工作受到了GANs最近成功的启发,GANs可以被看作是两个玩家之间的极大极小博弈,即生成器G和鉴别器D。
定义如下:
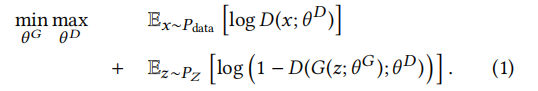
对于此函数的解释可以参考这两个资料:
GAN:原始损失函数详解
GAN的白板推导
GAN的损失函数
HeGAN
如图1(c)所示,我们的框架主要由两个相互竞争的参与者组成,鉴别器和生成器。对于给定的节点,生成器尝试生成与给定节点相关联的伪样本,以提供给鉴别器,而鉴别器则尝试使其参数化,以将伪样本与实际连接到给定节点的真实样本分离开来。经过更好训练的鉴别器会迫使发生器产生更好的假样本,然后重复这个过程。在这样的迭代过程中,发生器和鉴别器都接收到相互的正强化。虽然这种设置可能看起来与以前基于gan的网络嵌入的工作类似,但是我们采用了两个主要的新颖之处来解决在HINs上进行对抗性学习的挑战。
首先,现有的研究只是利用GAN来区分一个节点到给定节点的结构连接是真实的还是虚假的,而没有考虑到HIN的异质性。例如,对于给定的纸张p2,它们将节点a2、a4视为实节点,而仅根据图1(a)中HIN的拓扑结构将节点a1、a3视为假节点。但是,az和a4连接到p2的原因不同:a2只写p2,而a4只查看p2。因此,他们错过了HINs所承载的有价值的语义,无法区分a2和a4,尽管它们扮演不同的语义角色。在语义保持嵌入方面,我们引入了一个关系感知的鉴别器和生成器来区分节点间不同类型的语义关系。在我们的HIN中,给定一张纸p2和一个关系,比如write/written,我们的鉴别器能够区分az和a4,我们的生成器将尝试生成更类似a2而不是a4的假样本。
其次,现有的研究无论是在有效性还是效率上都局限于样本的生成。他们通常使用某种形式的softmax对原始网络中的所有节点进行节点分布建模。在有效性方面,他们的虚假样本被限制在网络的节点上,而最具代表性的虚假样本可能位于嵌入空间的现有节点之间。例如,给定一张纸p2,他们只能从V中选择假样本,比如a1和a3。然而,两者可能与a2等实际样本并不完全相似。为了更好地生成样本,我们引入了一个广义的生成器,它可以生成潜在节点,如图1(c)中所示的a’,其中a’ 不存在于网络v中,并且可能是a1和a3的“平均值”,并且更类似于实际样本a2。在效率方面,softmax函数的计算开销很大,而我们的生成器可以直接对假节点进行抽样,而不需要使用softmax。
HeGAN的鉴别器与生成器
鉴别器
由于HIN的特殊性,在HIN上必须区分给定关系下的真节点和假节点。因此,我们的关系感知识别器: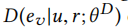 其中u属于HIN中的给定结点,r为HIN中给定的节点间关系ev为样本节点v的嵌入(它可能为真也可能为假)
其中u属于HIN中的给定结点,r为HIN中给定的节点间关系ev为样本节点v的嵌入(它可能为真也可能为假)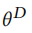 为D的模型参数(本人认为实际上就是D中其它参数的一个并集),本质上,D输出了样本v在关系r下与u连接的概率,我们将这个概率量化为:
为D的模型参数(本人认为实际上就是D中其它参数的一个并集),本质上,D输出了样本v在关系r下与u连接的概率,我们将这个概率量化为:
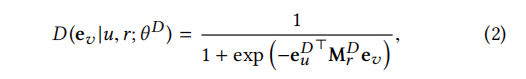
当然,当一个正的样本与u和r相关时,概率应该是高的,当它是一个负的样本时,概率应该是低的。通常情况下,一个样本v与给定的u和r一起形成一个三元组(u, v, r),并且就其极性而言,每个三元组都属于下面三种情况中的一种。每一种情况也有助于一部分鉴别家的损失。
情形1:
给定关系下的连通。也就是说,节点u和v确实通过HIN 图上正确的关系r连接。如图1(a)所示(a2, p2, write)。这样的三元组被认为是积极的,可以通过下面的损失来建模: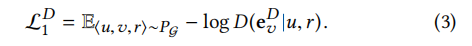
对于此公式:D是判断v节点是否在图中被关系r正确地连通着所以D的输出应该是一个0~1之间数针对此情况我们希望D输出的值越来越接近1这样损失会越来越接近零
情形2:
连接的关系不正确。也就是说,u和v在HIN中的连接关系是错误的r’ 不等于r,例如(a2, p2, view)。鉴别器也会将它们标记为负,因为它们的连通性不符合给定关系r所承载的期望语义。我们将损失的这一部分定义如下:
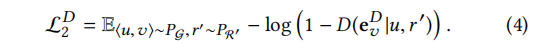
对于此公式:针对此情况我们希望鉴别器鉴别出这个三元组的负性因此我们希望D的输出越来越接近0这样损失会越来越接近0
案例3:
来自关系感知生成器的伪节点。即给定一个节点u(u在图中),它可以与生成器生成的节点进行某种连接如图1©中的(a’,p2, write)。生成器它试图产生一个假的节点的嵌入,模仿真正的节点连接到u r下正确的关系。同样,鉴频别器的目的是确定这三元组为负性,损失可定义如下:
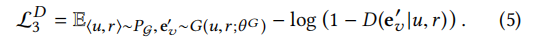
对于此公式:针对此情况我们希望鉴别器鉴别出这个三元组的负性因此我们希望D的输出越来越接近0这样损失会越来越接近0
我们将以上三个部分进行整合,来训练鉴别器: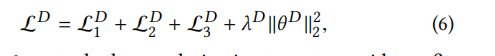
其中,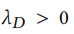 控制正则化项,以避免过拟合。来最小化
控制正则化项,以避免过拟合。来最小化 可以对鉴别器的参数
可以对鉴别器的参数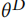 进行优化。
进行优化。
值得注意的是:这三种情况都加个负号而原本的gan网络损失函数中是没有负号的这是因为原本的gan是使D最大化而我们则希望最小化D,因为log1=0但是对于原来的gan的鉴别器损失来说它们是负数即模型越差损失函数的值越小最大为0,当损失函数的值=0我们便得到了一个理想化的模型,对于HeGAN我们在鉴别器的损失函数中加一个正则化(它的值为正)在我看来如果按照之前gan的损失函数定义如果我们的模型没有达到很好的效果因此我们得到一个负数但由于正则项的关系它们会使损失变小从而影响我们的判断。
感知关系的广义生成器。
我们的生成器G的目标是生成模拟真实样本的伪样本。一方面,G是感知关系的,就像鉴别器一样。因此,给定一个节点u和一个关系r ,生成器机G的目的是在关系r的上下文中生成一个可能连接到u的伪节点v。换句话说,v应该尽可能接近一个真实的节点。另一方面,我们的生成器是广义的,这意味着假节点v可以是潜在的,而不是在v中发现的。为了满足这两个需求,我们的生成器还应该使用关系特定的矩阵(用于关系感知),并从底层的连续分布生成样本(用于泛化)。特别地,我们利用以下高斯分布:
对于 σ的某些选择,它是一个平均值为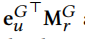 和协方差为
和协方差为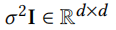 的高斯分布。直观地说,均值表示一个可能通过关系r与u连接的伪节点,协方差表示潜在偏差。一种简单的方法是直接从N中生成样本。然而,由于神经网络对复杂结构建模能力较强,我们将多层感知器(MLP)集成到生成器中,以增强伪样本的表达。因此,我们的生成器达式如下:
的高斯分布。直观地说,均值表示一个可能通过关系r与u连接的伪节点,协方差表示潜在偏差。一种简单的方法是直接从N中生成样本。然而,由于神经网络对复杂结构建模能力较强,我们将多层感知器(MLP)集成到生成器中,以增强伪样本的表达。因此,我们的生成器达式如下:
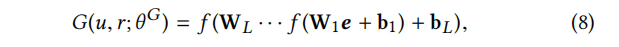
我们从分布公式(7)中得到e。其中W、b分别表示各层的权重矩阵和偏置向量,f为激活函数。如前所述,生成器希望通过生成接近真实的虚假样本来欺骗鉴别器,从而使鉴别器给它们打高分。
对于生成器的损失定义如下:
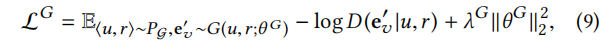
对于此公式:我们希望生成器可以生成以假乱真的节点来使鉴别器失效注意:gan网络中所有的损失都是在鉴别器处产生的。因此我们希望次公式中的D越接近1越好,这里的负号和鉴别器中的负号类似
其中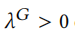 控制正则化项。通过最小化
控制正则化项。通过最小化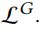 ,可以对生成器的参数
,可以对生成器的参数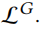















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









