 KNN算法实战
KNN算法实战




KNN原生代码时实现实验
1、题目分析
设计思路:
对未知类别属性的数据集中的每个点依次执行以下操作:
1、计算已知类别数据集中的点与当前点之间的距离(采用欧式距 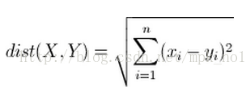 离公式 )
2、按照距离递增次序排序
3、选取与当前点距离最小的K个点
4、确定前K个点所在类别出现的频率
5、返回前k个点出现频率最高的类别作为当前点的预测分类
2、算法构造
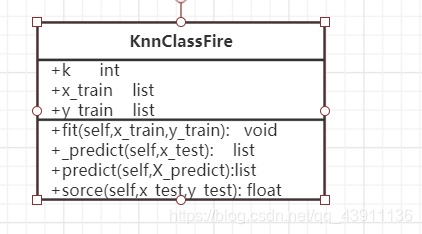
self.k=k k近邻数
self.x_train=x_train 训练特征集
self.y_train=y_train 训练标签集
#训练函数
def fit(self,x_train,y_train):
#预测函数
def _predict(self,x_test):
#正确率函数
def sorce(self,x_test,y_test):
#文件打开,数据预处理
def open_file(file_address):
数据分隔
def dataset_split(dataset, label):
#加载数据,返回测试集,训练集
def load_data(firename):
3、算法实现
对未知类别属性的数据集中的每个点依次执行以下操作:
1、计算已知类别数据集中的点与当前点之间的距离
2、按照距离递增次序排序
3、选取与当前点距离最小的K个点
4、确定前K个点所在类别出现的频率
5、返回前k个点出现频率最高的类别作为当前点的预测分类
import numpy as np
import pandas as pd
from collections import Counter
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn import preprocessing #数据预处理
class KnnClassFire:
def init(self,k):
self.k=k
self.x_train=x_train
self.y_train=y_train
#训练函数
def fit(self,x_train,y_train):
self.x_train=x_train
self.y_train=y_train
#预测函数
def _predict(self,x_test):
#欧氏距离
d = [np.sqrt(np.sum((x_i - x_test) ** 2)) for x_i in self.x_train]
#将欧氏距离递增排序
neard=np.argsort(d)
#选取最近的k个点
top_k=[self.y_train[i] for i in neard[:self.k]]
#判断k个点中,类别最多的那一类
#计数,将每个类出现的概率
votes=Counter(top_k)
return votes.most_common(1)[0][0] #显示前1个最多的元素
def predict(self,X_predict):
y_predict=[self._predict(x1) for x1 in X_predict]
return np.array(y_predict)
#正确率函数
def sorce(self,x_test,y_test):
y_predict = self.predict(x_test)
return sum(y_predict == y_test)/ len(x_test)
#文件打开,数据预处理
def open_file(file_address):
data = pd.read_csv(file_address, encoding=‘utf-8’)
# 类别做标签
data.loc[data.species == ‘Iris-setosa’, ‘species’] = 0
data.loc[data.species == ‘Iris-versicolor’, ‘species’] = 1
data.loc[data.species == ‘Iris-virginica’, ‘species’] = 2
dataset = data.loc[:, (“sepal_length”, “sepal_width”,
“petal_length”, “petal_width”)]
label = data.loc[:, (“species”)]
dataset = np.array(dataset) # 转成numpy
label = np.array(label)
Num = len(dataset)
return dataset, label, Num
# 数据分隔
def dataset_split(dataset, label):
x_train, x_test, y_train, y_test = train_test_split(dataset, label,
test_size=0.3, random_state=0)
return x_train, x_test, y_train, y_test
#加载数据,返回测试集,训练集
def load_data(firename):
# 获取数据和标签
dataset, label, Num = KnnClassFire.open_file(firename)
x_train, x_test, y_train, y_test = KnnClassFire.dataset_split(dataset,label)
return x_train,x_test,y_train,y_test
if name == ‘main’:
#加载Iris数据集
x_train, x_test, y_train, y_test = KnnClassFire.load_data(“Iris.csv”)
myknn = KnnClassFire(11)
myknn.fit(x_train,y_train)
myknn.predict(x_test)
#正确率
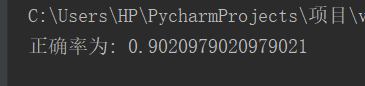
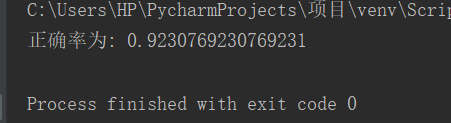
print(“正确率为:”,myknn.sorce(x_test,y_test))
4、测试、运行结果
测试:
数据集的加载:
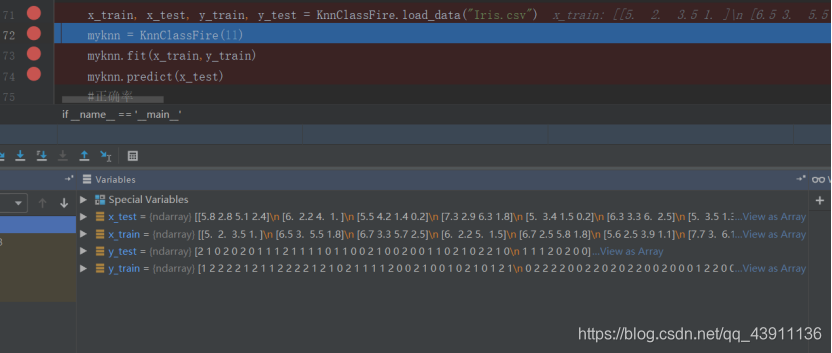
训练集的传入:
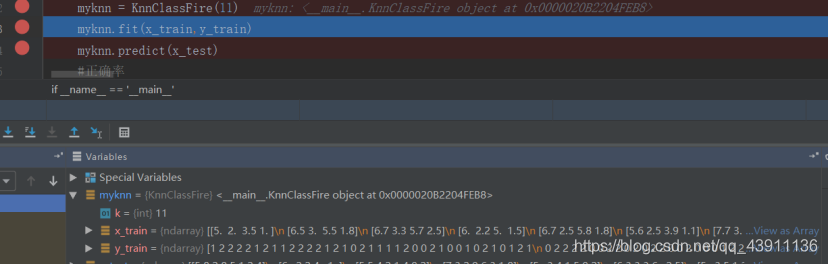
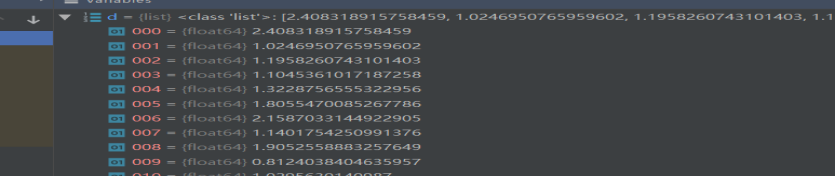
d值:
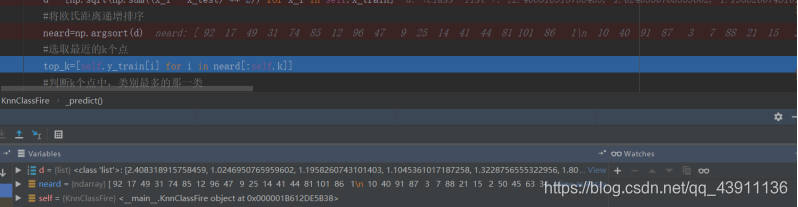
排序:
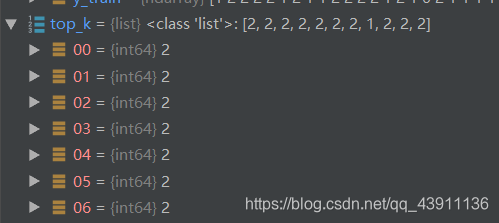
选取最近的k个点:
计数:
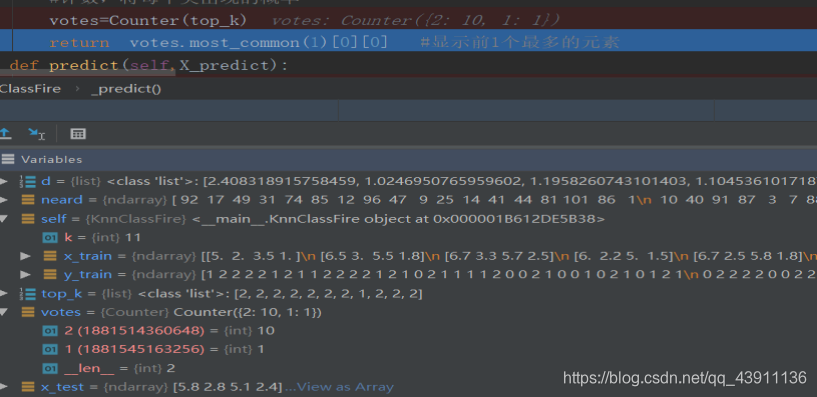
y的预测:
运行结果:
K=2时:
K=4时:
5、经验归纳
1>欧氏距离的计算公式:,计算每个x,y间的距离平方之和。
2>利用大量的列表推导式简化代码:
例如:d = [np.sqrt(np.sum((x_i - x_test) ** 2)) for x_i in self.x_train],利用np.sum()求和,用for循环取出每个位置的x值,x值接下来递增排序,用np.argsort()排序。
3>利用列表的分割来求取距离最大的k个分类,接着用counter()函数统计每个类别出现的次数,然后返回出现最多的类别。
4>求取准确率,利用sum函数,对两个列表各个位上的数进行判断。
5>两个可迭代的序列可以直接对对应位上的数据进行处理。

















 2590
2590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









