







话不多说,先给出网页地址豆瓣电影 Top 250,进入后我们按F12打开开发者工具查看网页信息,然后随便右键点击一张电影封面查看元素如图: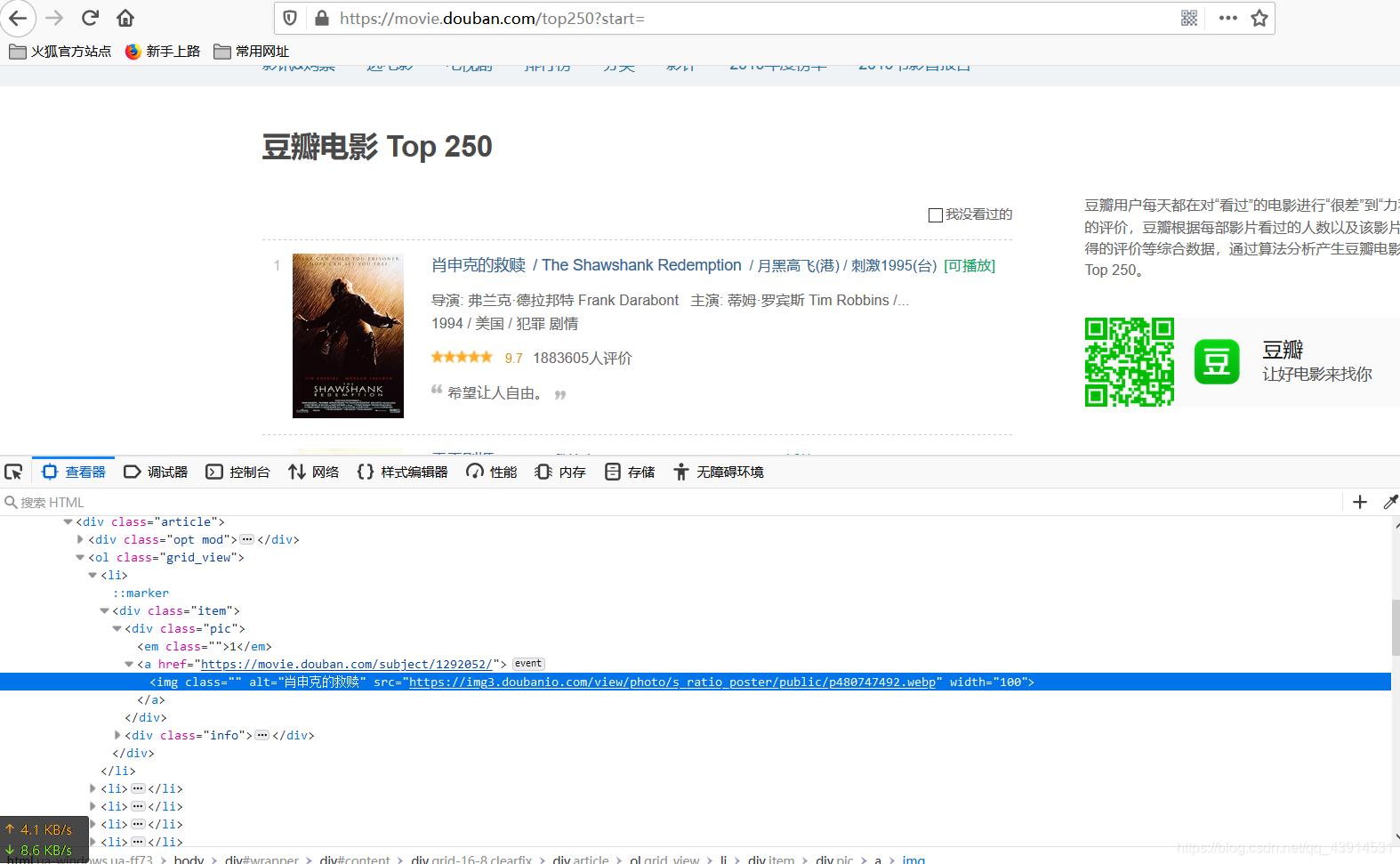
容易看出我们所需要的封面地址在img这个标签下的src属性当中,因此接下来我们就可以用xpath语法去获取我们想要获得的信息了,获取到目的信息后使用request下的urlretrieve函数将图片保存在指定的路径下,代码如下:
def get_img(lis):
for li in lis:
global num #计数变量
title = li.xpath('.//span[@class="title"]/text()')[0] #获取影片标题
img_url = li.xpath('.//img/@src')[0] #获取封面地址
file_name = 'E:/douban/' + title + str(num) + '.jpg'
urllib.request.urlretrieve(img_url,filename=file_name) #保存到本地文件中
num += 1
其中获取了影片的标题title并且加入了计数变量num,这些都是为使保存在E:\douban 路径下的封面图片信息更加完整。
接下来我们为了将10页(一页中有25部)所以影片信息获取,只需要在首页url地址稍作改动即可,最终完整代码如下:
import urllib.request
import requests
from lxml import html
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
}
def get_html(url):
response = requests.get(url,headers=headers).text
element = html.etree.HTML(response)
lis = element.xpath('//ol[@class="grid_view"]')[0]
return lis
def get_img(lis):
for li in lis:
global num #计数变量
title = li.xpath('.//span[@class="title"]/text()')[0] #获取影片标题
img_url = li.xpath('.//img/@src')[0] #获取封面地址
file_name = 'E:/douban/' + title + str(num) + '.jpg'
urllib.request.urlretrieve(img_url,filename=file_name) #保存到本地文件中
num += 1
def main():
global num
num = 1
for i in range(10):
url = 'https://movie.douban.com/top250?start=' + str(25 * i)
ht = get_html(url)
get_img(ht)
i += 1
main()
`代码也是比较简单的,这里就不全做解释了,给大家看一下运行后的成果:
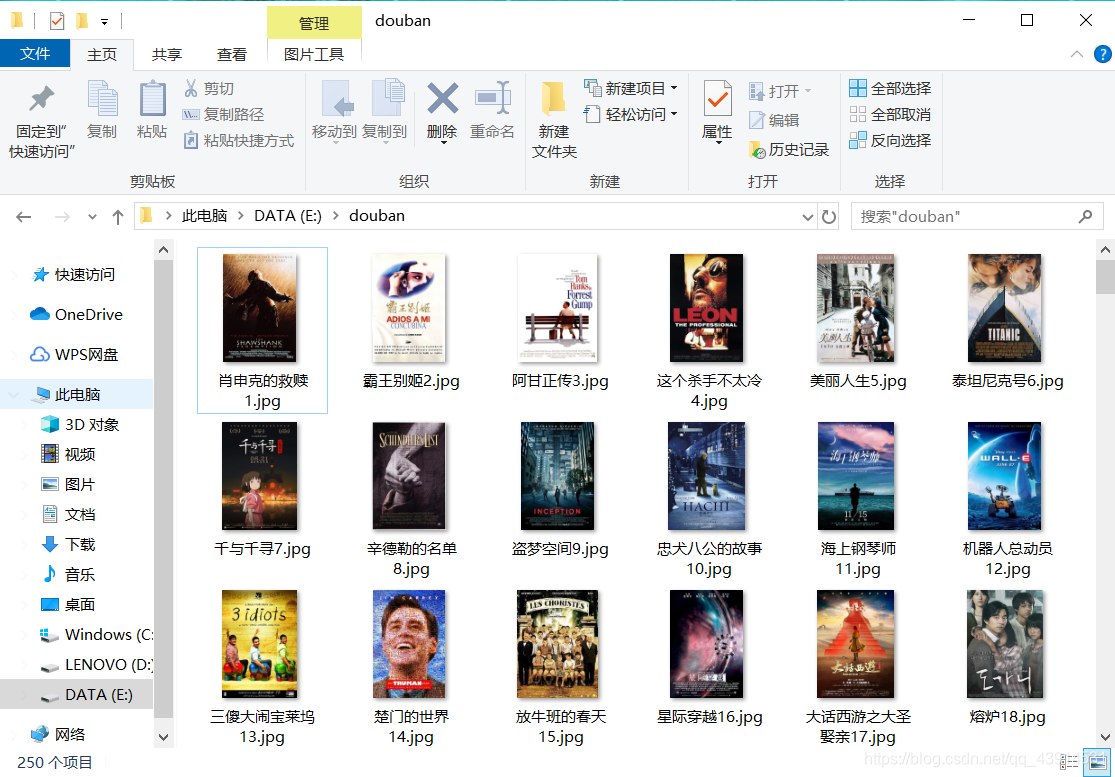
可以清楚的看到我们想要的内容就都在指定的文件路径下了。当然爬取其他类似静态网页如妹子图网之类的也是如此哦。














 3562
3562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









