






任务概览
本文记录了在学习和了解【书生大模型全链路开源体系】过程中的一些笔记。开源精神,YYDS!
目录
- 概述
- 数据
- 预训练
- 微调
- 部署
- 评测
- 应用
概述
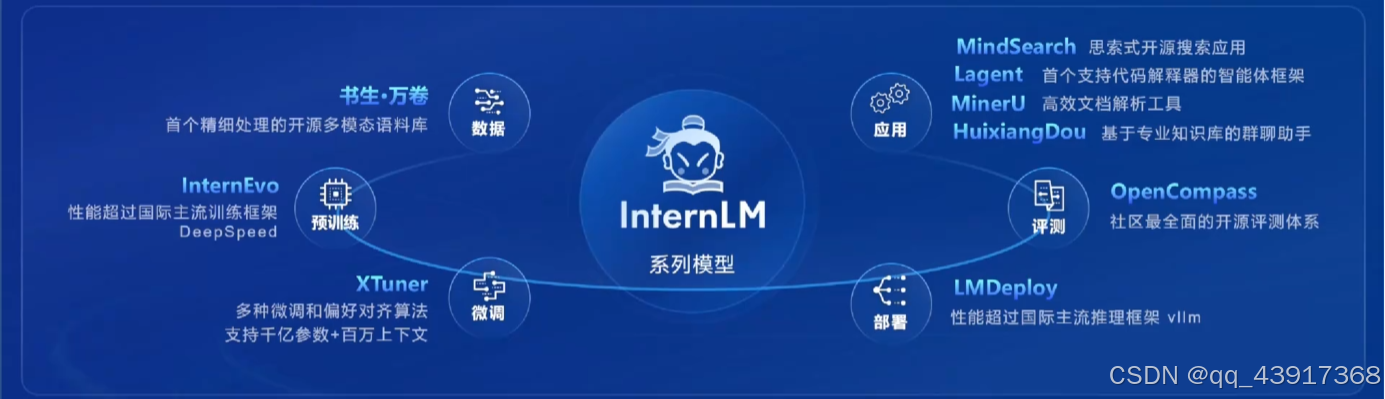
该体系涵盖了数据、预训练、微调、部署、测评和应用的全链路开源解决方案,几乎覆盖了大模型开发的整个过程。接下来,我们将依次介绍这些开源工具在各个阶段的应用。
数据
-
书生·万卷 1.0:这是书生·万卷多模态语料库的首个开源版本,包含三大数据集:文本数据集、图文数据集和视频数据集,总数据量超过2TB。该语料库基于大模型数据联盟构建,上海AI实验室对部分数据进行了细粒度清洗、去重和价值对齐,形成了书生·万卷1.0,具备以下四大特征:
- 多元融合:跨领域、多模态的数据融合。
- 精细处理:数据经过深度清洗,质量高。
- 价值对齐:优化数据集的价值,使其更具应用潜力。
- 易用高效:便捷的数据处理流程,帮助研究者快速上手。
预训练
-
InternEvo:InternEvo是一个轻量级的开源训练框架,旨在支持无需大量依赖关系的大模型预训练。它具有以下特点:
- 支持在具有上千GPU的大规模集群上进行预训练。
- 可在单个GPU上进行微调,同时实现显著的性能优化。
- 当在1024个GPU上进行训练时,InternEvo的加速效率接近90%。
传送门:InternEvo GitHub
微调
-
XTuner:XTuner是一个高效、灵活、全能的轻量化大模型微调工具库,具备以下特性:
- 高效:支持在8GB显存下微调7B模型,同时支持多节点跨设备微调更大模型(70B+)。支持自动分发高性能算子(如FlashAttention、Triton kernels等),加速训练吞吐。
- 灵活:兼容多种大语言模型(如InternLM、Mixtral-8x7B、Llama 2等),以及多模态图文模型(如LLaVA)。支持各种微调算法(如QLoRA、LoRA、全量参数微调等)。
- 全能:支持增量预训练、指令微调和Agent微调,且预定义了多个开源对话模版,支持与开源或训练所得模型进行对话。
传送门:XTuner GitHub
部署
-
LMDeploy:LMDeploy是由MMDeploy和MMRazor团队联合开发的全套轻量化、大规模模型部署解决方案,具备以下特点:
- 高效推理:支持持久化批处理、动态拆分与融合等特性,推理性能是vLLM的1.8倍。
- 可靠量化:支持权重量化和K/V量化,4bit模型的推理效率是FP16的2.4倍。
- 便捷服务:支持多模型在多机、多卡上的推理服务,并且支持有状态推理,缓存对话历史,显著提升长文本多轮对话的效率。
- 卓越兼容性:支持KV缓存量化、AWQ和自动前缀缓存同时使用。
传送门:LMDeploy GitHub
评测
-
OpenCompass:这是一个开源、高效且全面的大模型评测体系,提供了一个开放平台,支持大规模模型的评估。用户可以利用这个平台进行模型的全方位测评,确保其性能和可靠性。
传送门:OpenCompass 网站
GitHub:OpenCompass GitHub
应用
-
MindSearch:MindSearch是一个开源的思索式搜索应用,致力于提供精准高效的搜索体验。
-
Lagent:Lagent是一个轻量级的开源智能体框架,旨在帮助用户高效构建基于大语言模型的智能体,同时提供多种增强工具以提升模型能力。
传送门:Lagent GitHub
中文教程:Lagent 中文教程 -
AgentLego:AgentLego是一个多模态工具包,提供了丰富的API接口,用户可以像搭建乐高积木一样,快速构建自定义的智能体。
传送门:AgentLego GitHub
-
MinderU:MinderU是一个高效的文档解析工具,旨在帮助用户快速解析和处理各种类型的文档。
传送门:MinderU GitHub
-
HuixiangDou:HuixiangDou是基于专业知识库的群聊助手,能够提升团队沟通效率。

















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









