







书生通用大模型体系
文章目录
书生大模型全链路开源体系报告
引言
随着人工智能技术的飞速发展,大模型已经成为推动AI领域进步的关键力量之一。书生大模型作为一款先进的语言模型,在开源社区中扮演着重要角色。本报告将详细介绍书生大模型的全链路开源体系,包括其发展历程、技术特点、开源生态系统以及社区支持等关键方面。
开源历程
发展时间线
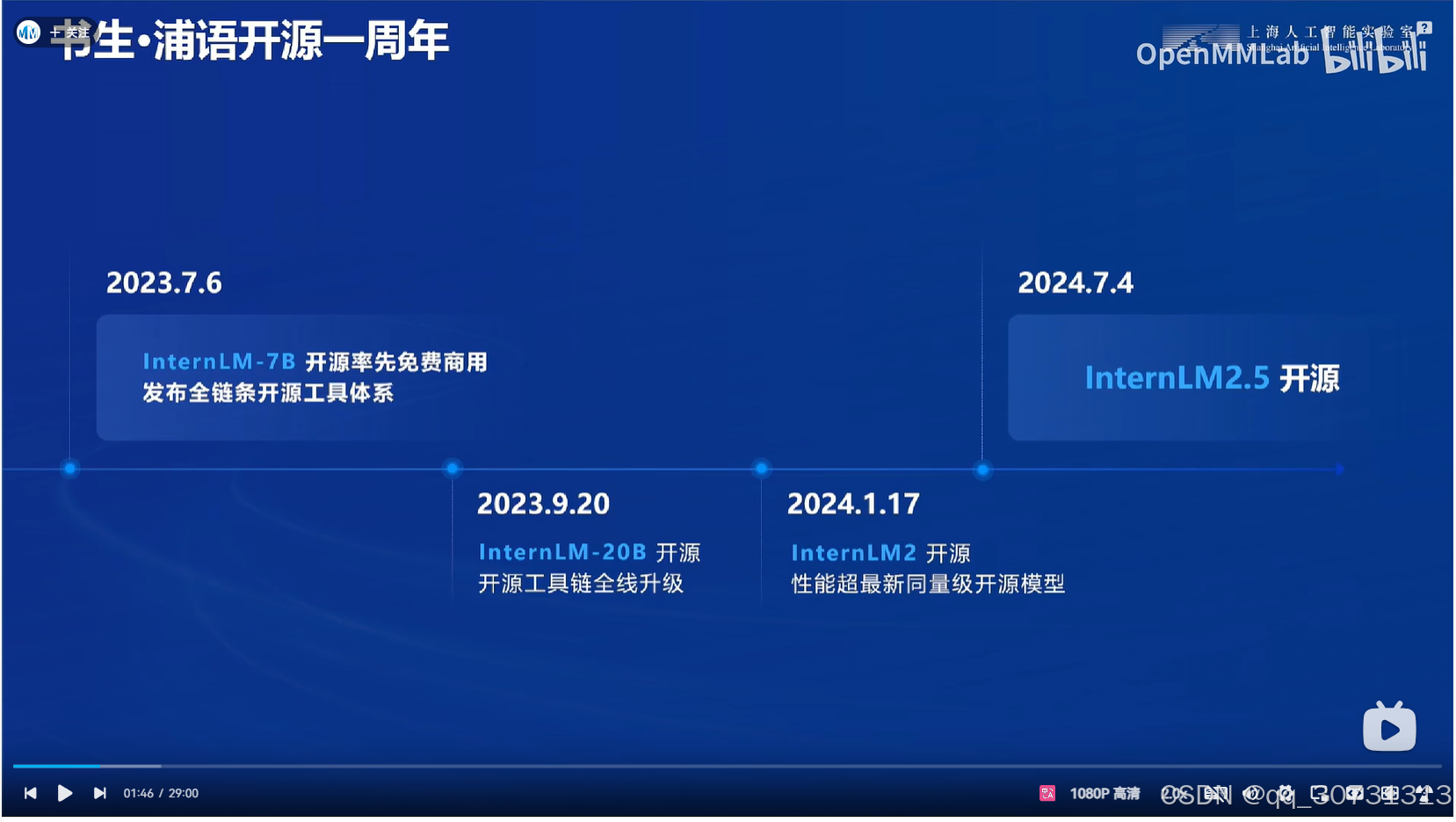
- 2023年7月6日: 7B模型首次开源并投入商用。
- 2023年9月底: 20B模型正式发布。
- 2024年1月: INTURNLM2.0版本开源。
- 2024年7月初: INTURNLM2.5版本开源。
版本迭代与升级
每个版本的更新都标志着书生大模型在性能和技术上的重大突破。从最初的7B模型到最新的INTURNLM2.5,每一次迭代都带来了更强大的计算能力和更高的准确率。
技术特点

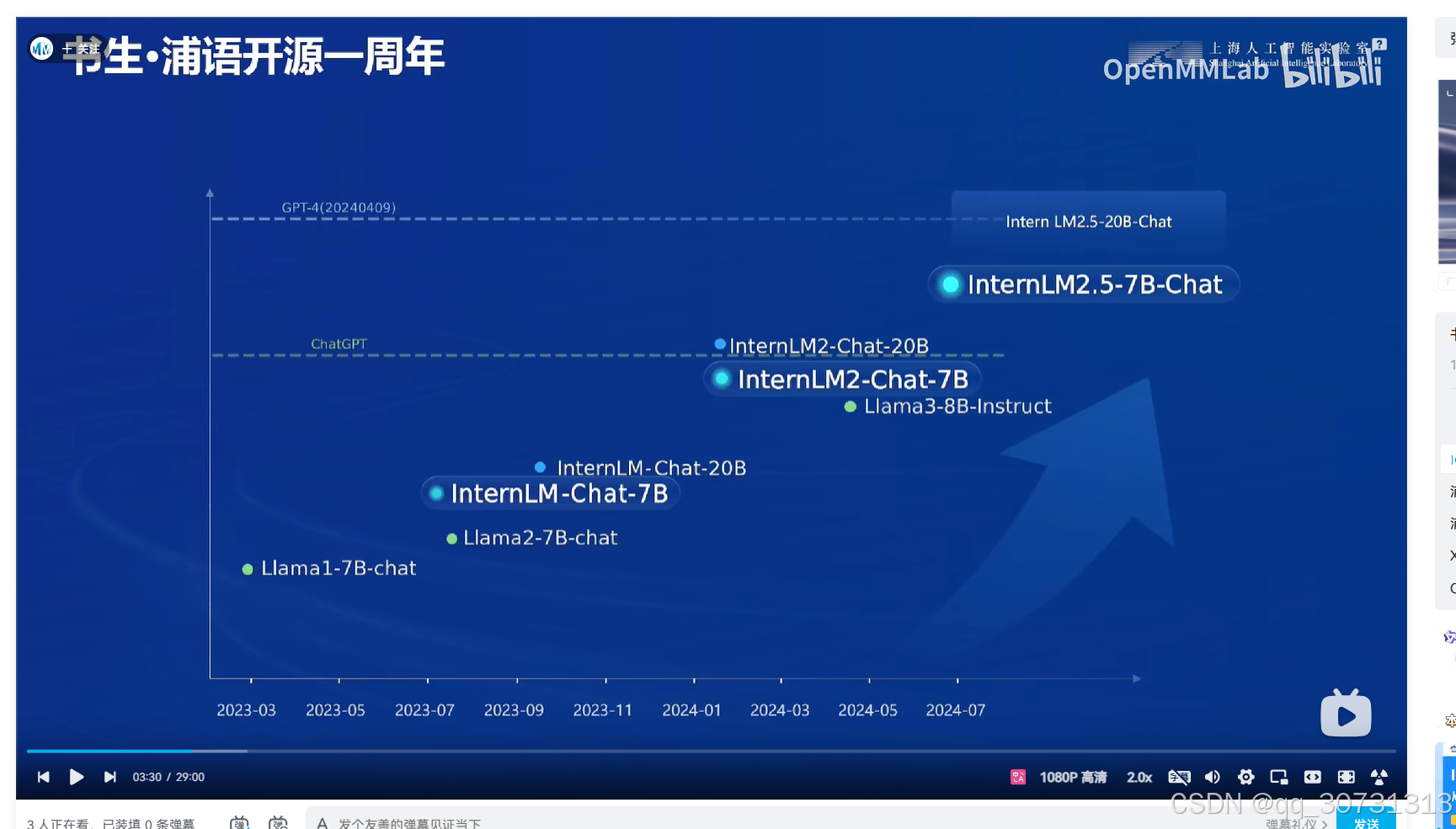
性能提升
- INTURNLM2.5推理能力提升20%:新版本在推理速度上做出了显著优化,能够显著减少响应时间,使得系统在处理用户请求时更加高效。这一性能提升得益于多项技术创新,包括算法优化、硬件适配和并行计算的加强。通过这些优化,书生大模型在高负载情况下依然能够稳定运行,进一步增强了系统的实用性和可靠性。
- 上下文容量可达100万tokens:这一特性大大扩展了书生大模型在大规模文本处理中的能力,能够在处理超长文本时保持高精度和高效性。书生大模型支持将大量上下文信息引入到推理过程中,提升了模型在复杂语境中的理解能力,特别是在法律、医学等领域,模型能够充分理解并处理跨越多个话题和上下文的内容。
功能增强
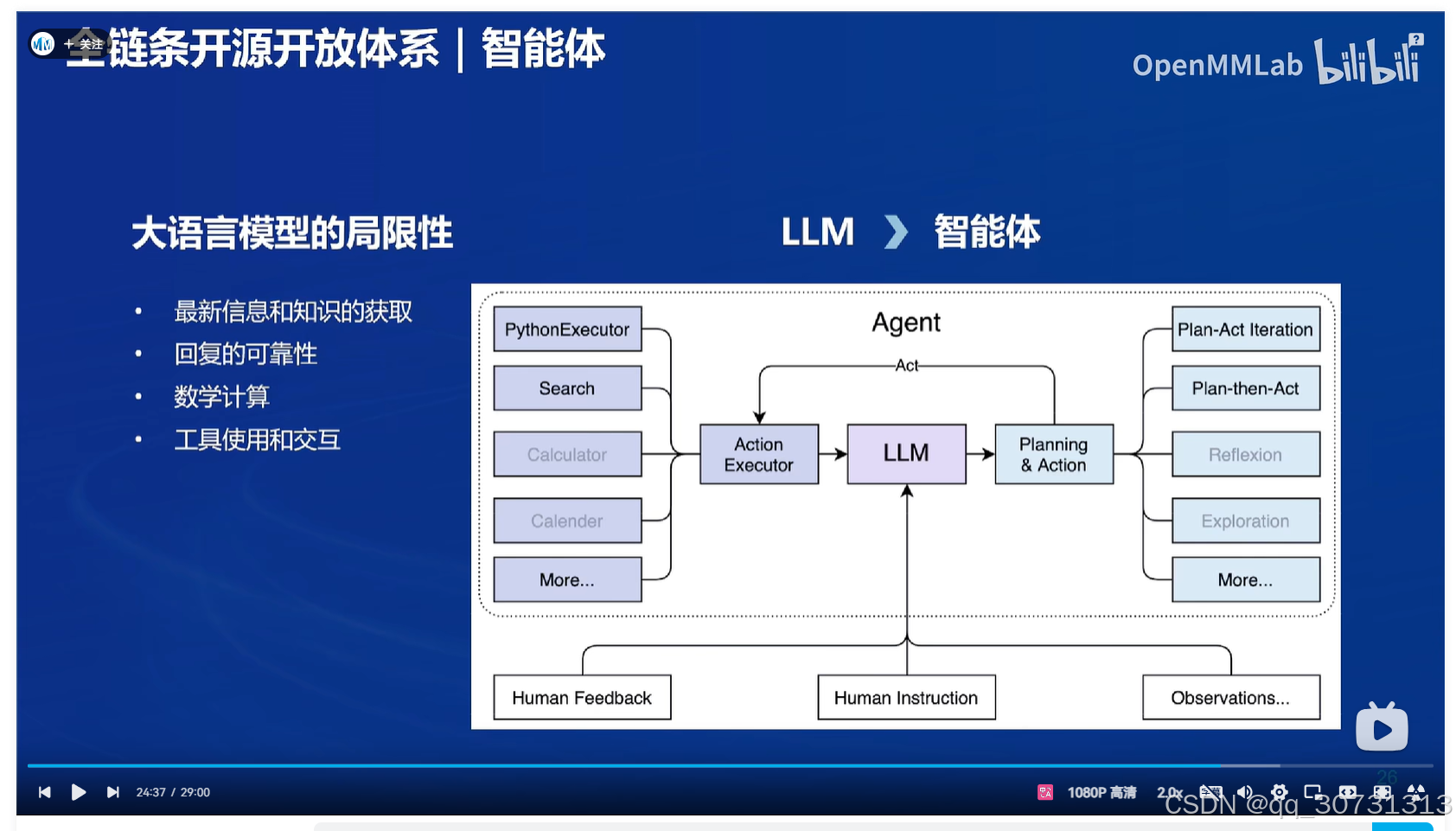
- 大规模上下文处理:书生大模型采用先进的算法架构,使其能够处理数百万tokens的上下文,这对于一些需要分析庞大数据集、长篇文章或跨越多个领域的任务尤为重要。模型可以在海量信息中迅速提取相关内容,帮助用户做出更为精准的决策。无论是在客户支持、内容创作还是科研分析中,书生大模型的上下文处理能力都能大幅提升效率和准确度。
- 自主规划和搜索复杂任务能力:通过强化学习和深度学习算法的结合,书生大模型具有自主规划和执行复杂任务的能力。这使得它能够自动识别任务流程、确定最优路径并高效执行。无论是解决复杂的计算问题,还是执行跨学科的任务,书生大模型都能够准确完成并优化任务执行过程,节省了大量人工干预的时间。
开源生态系统
数据收集和准备
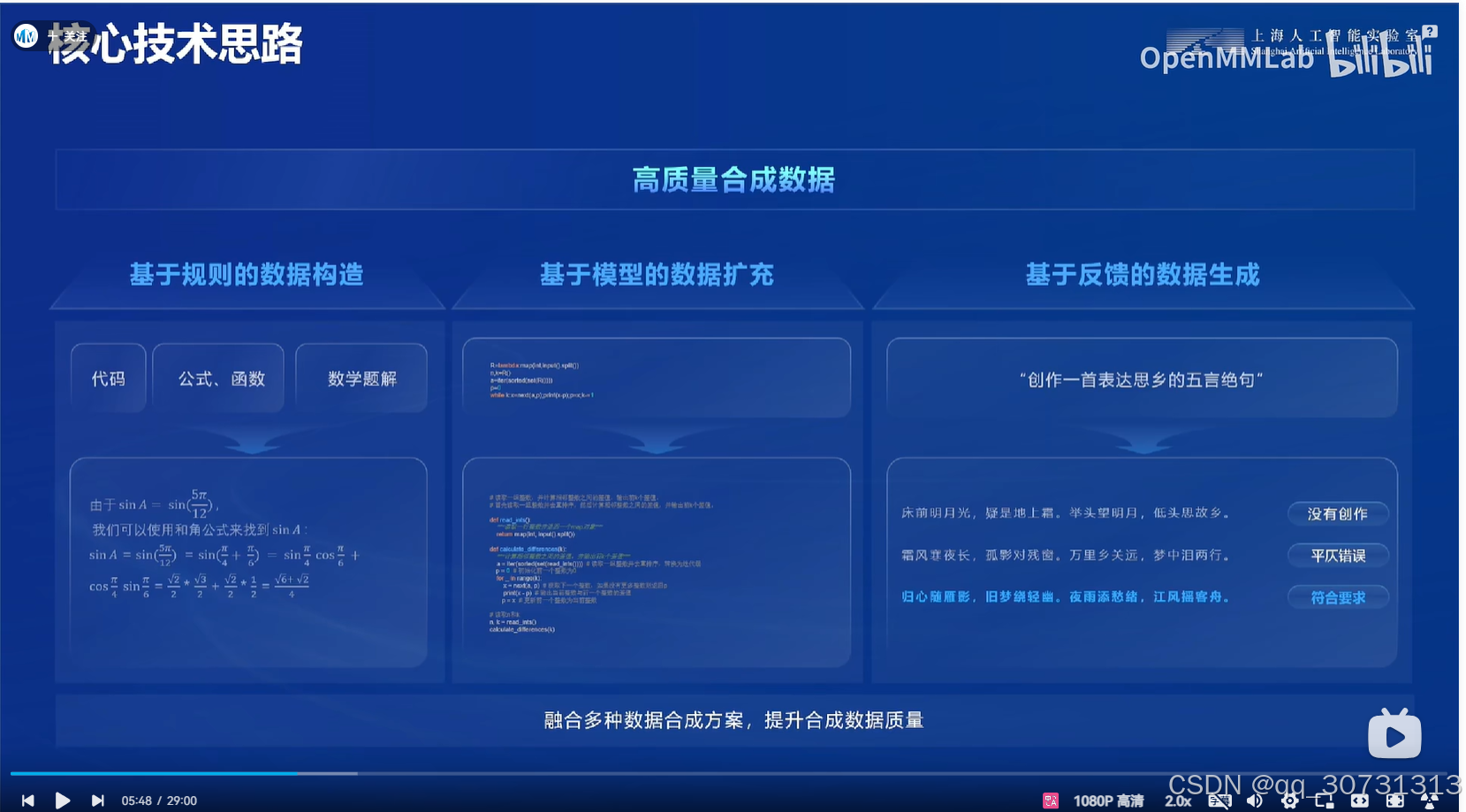
- 高质量数据策略:书生团队通过严格的筛选机制,确保模型训练使用的数据具有高质量和高代表性。每一份数据都经过仔细审核,去除无关信息和噪声,从而提高模型的泛化能力和准确性。为了确保数据的多样性,书生团队还从多个领域收集数据,并且为特定领域的应用场景准备了专业化的数据集。
- 规则基数据构造:结合专家知识和机器学习技术,书生团队采用规则基方法生成高质量的训练数据。通过定义规则和样本生成策略,团队能够高效构建符合模型需求的数据集,同时确保数据的质量和一致性。
技术栈
- 数据管理: 书生大模型采用了一系列强大的数据管理工具,如MINORU、LABELLLM和OPENCOMPASS等,确保数据在整个生命周期内的安全性、完整性和可用性。MINORU专注于大数据的存储与管理,LABELLLM为标注工作提供了高效的支持,而OPENCOMPASS则保证了大模型测试的公正性和透明性。这些工具的组合为整个系统提供了稳定的技术支撑。
- 模型架构: 书生大模型的架构包含了多个组件,如INTURNEvil、INTRUNComposer和INTRUNMath等,这些组件能够根据不同的需求和任务场景灵活组合,提供多样化的建模选择。无论是在文本生成、语义理解,还是在复杂的数学推理中,书生大模型都能展现出强大的能力。
应用实例
-
RAG (文档解析和查询系统):书生大模型被应用于文档解析和查询系统中,可以快速有效地从海量文档中提取相关信息并给出准确的回答。通过结合RAG技术,书生大模型能够理解文档中的隐性信息,并根据查询要求快速定位相关内容。例如,在一个知识问答系统中,RAG能够识别文档中的关键点,并结合上下文提供更为准确的答案。
在今年暑假,我参加了中兴捧月全球精英挑战赛,负责开发一个基于RAG的知识问答系统。系统中经常会遇到一些数学问题,可能因为数字细微的错误导致模型给出错误的答案。刚好INTURNLM2.5开源了,我立即尝试了它,并参考了官方文档的实现。经过测试,我发现模型在处理数学推理时非常精准,直接提升了系统的回答准确率约2%,对我的项目帮助巨大。
-
MINSEARCH (AI驱动的搜索引擎):结合自然语言处理技术和搜索引擎技术,书生大模型为MINSEARCH提供了强大的支持。该搜索引擎能够理解复杂的查询并返回相关性高的结果。与传统搜索引擎不同,MINSEARCH不仅能够解析关键词,还能够理解语义和用户意图,从而提供更加精准和个性化的搜索结果。
-

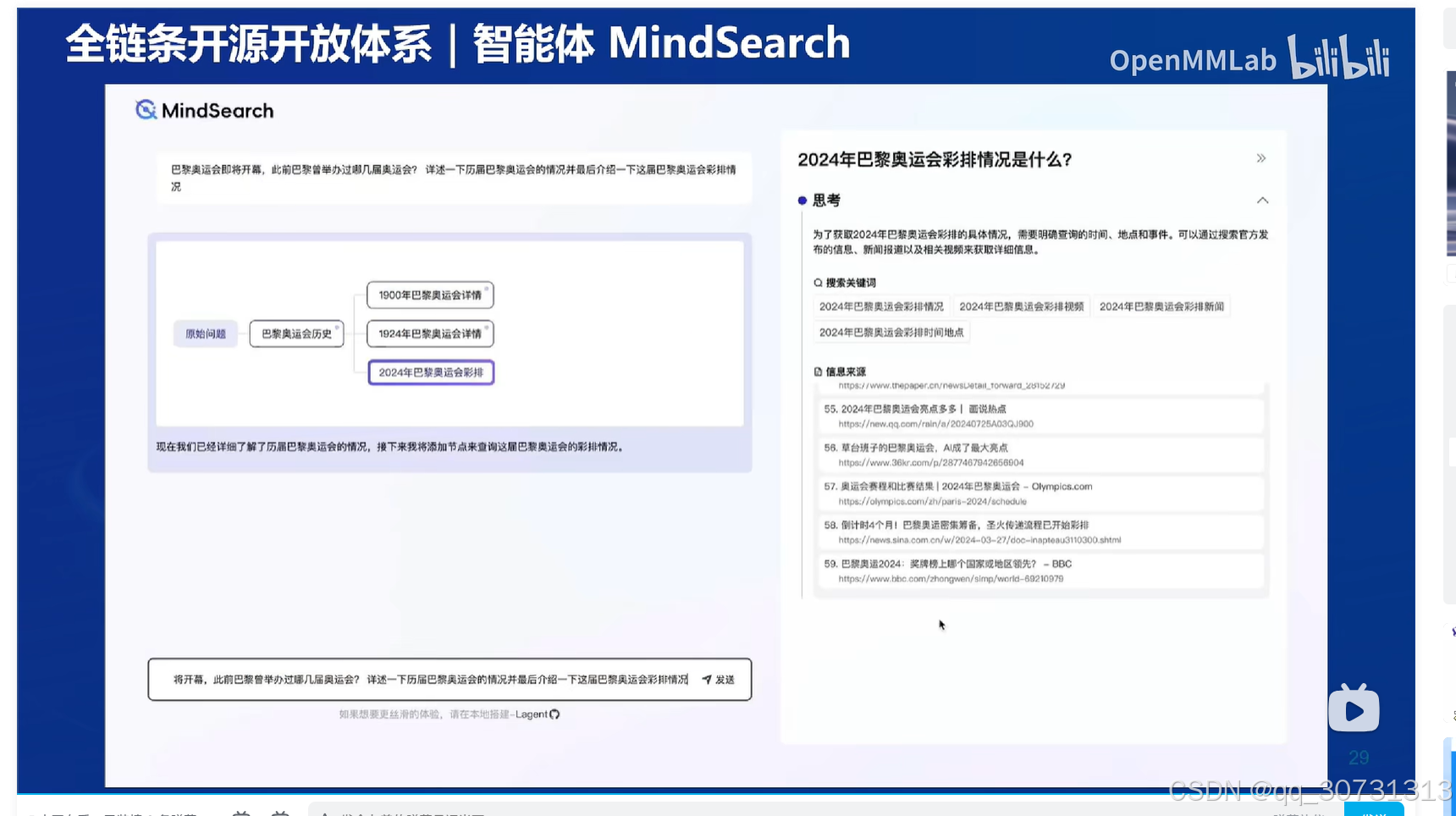
社区贡献和支持
标注项目
- LabelLLM项目:LabelLLM旨在简化自然语言处理任务中的数据标注工作,降低开发者的技术门槛。通过这个项目,开发者可以轻松创建高质量的标注数据集,帮助模型更好地进行训练。LabelLLM结合了专家系统和机器学习方法,能够根据上下文自动标注文本内容,极大提高了数据标注的效率和准确度。
测试标准
- OpenCompass平台:OpenCompass平台提供了一个公正透明的环境,用于对大模型进行全面的性能评估。该平台的设计考虑了各类模型的不同特点,能够对模型的推理速度、准确度、计算资源消耗等多方面进行评测,帮助开发者了解模型的真实表现。OpenCompass的公开标准促进了不同团队之间的合作和技术交流,也为用户选择合适的模型提供了科学依据。
结论
书生大模型凭借其创新的开源体系和强大的技术能力,推动了从基础研究到实际应用的全面发展。其不仅在性能、功能和技术栈方面不断突破,还通过一系列优秀的应用实例展现了其在实际场景中的巨大潜力。未来,我们期待书生大模型继续引领行业的技术潮流,推动更多创新应用,为全球用户提供更加智能、精准的服务。
参考视频:https://www.bilibili.com/video/BV1CkSUYGE1v/?vd_source=88133e3279675c5e5f784b0ee6270751


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









