







本文图片出自https://github.com/ImagineAILab/ai-by-hand-excel.git
一、Transformer
Transformer 是近年来深度学习领域最重要的突破之一,彻底改变了自然语言处理(NLP)和其他序列建模任务的范式。
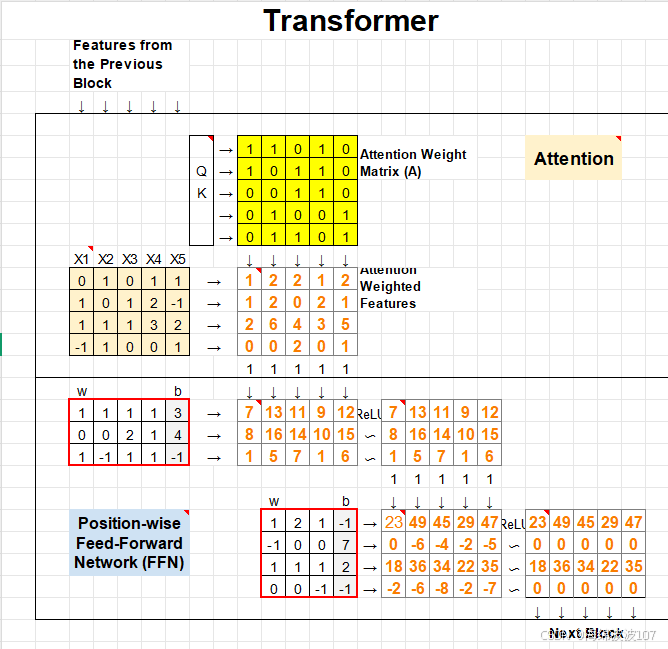
FFN由两层全连接层 + ReLU激活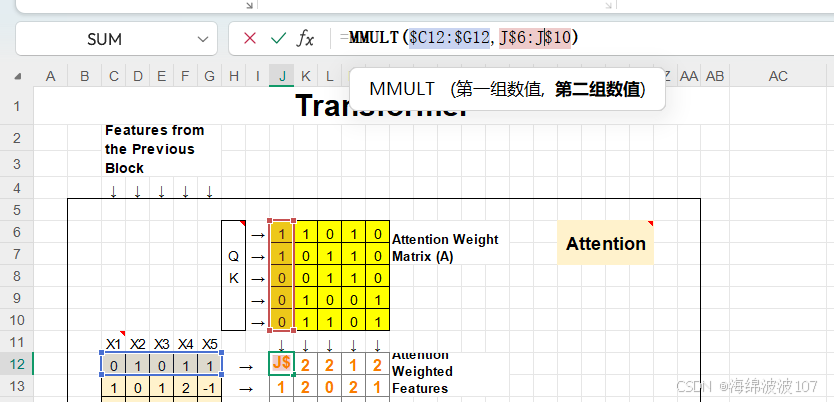
1. Transformer 的核心思想
核心目标:解决传统RNN/LSTM的长程依赖和并行化训练问题。
关键创新:
-
自注意力机制(Self-Attention):直接建模序列中任意两个元素的关系,无论距离多远。
-
全并行化架构:摒弃递归,完全基于矩阵运算,极大加速训练。
-
位置编码(Positional Encoding):注入序列位置信息,弥补无递归的缺陷。
2. Transformer 的架构分解
Transformer 由 编码器(Encoder) 和 解码器(Decoder) 堆叠而成,以下是其核心组件:
2.1 输入表示
-
词嵌入(Word Embedding):将词映射为稠密向量(如
d_model=512)。 -
位置编码(Positional Encoding):
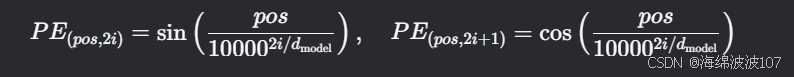
-
pos:词的位置,i:维度索引。 -
通过正弦/余弦函数编码位置,使模型能学习相对位置关系。
-
2.2 编码器层(Encoder Layer)
每层包含两个子模块:
-
多头自注意力(Multi-Head Self-Attention)
-
将输入拆分为
h个头(如h=8),分别计算注意力后拼接。 -
公式(单头):
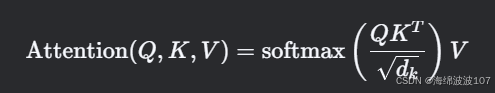
-
Q(Query),K(Key),V(Value) 由输入线性变换得到。 -
√d_k缩放防止点积过大导致梯度消失。
-
-
-
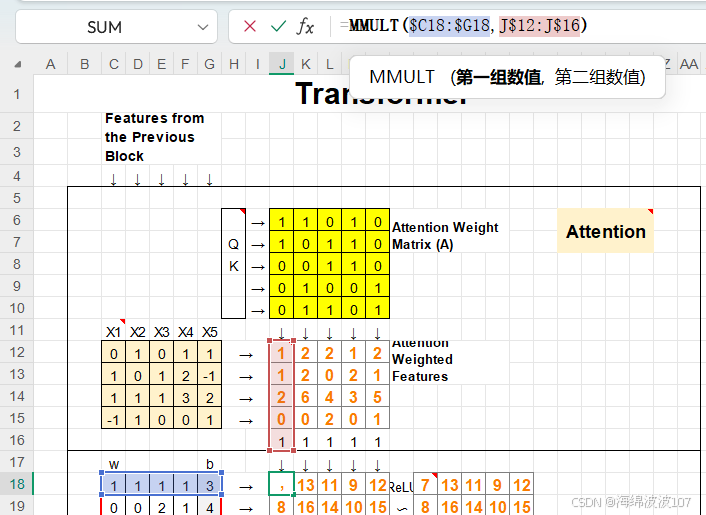
前馈神经网络(Feed-Forward Network, FFN)
(1)FFN 的结构与尺寸
Transformer中的FFN通常由两个全连接层(Linear Layer)组成,结构如下:
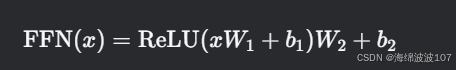
关键点:
第一层将维度从 d_model 扩展到更大的 d_ff(如512→2048)。
第二层将维度从 d_ff 压缩回 d_model(2048→512)。
ReLU激活函数仅作用于第一层的输出。
为什么这样设计?
(1)扩展维度(512 → 2048)
-
增强表达能力:在高维空间(如2048)进行非线性变换(ReLU),可以学习更复杂的特征组合。
-
类比“宽网络”:类似于计算机视觉中先用
1x1卷积扩展通道数,再压缩回去(如ResNet的Bottleneck)。
(2)压缩回原始维度(2048 → 512)
-
保持一致性:确保FFN的输出与输入维度相同,便于残差连接(
x + FFN(x))。 -
控制参数量:若直接保持高维(如2048),后续层的计算量会爆炸式增长。
(3)为什么是4倍扩展?
原始论文(《Attention Is All You Need》)中采用modeldff=4×dmodel(如512→2048),这是经验性选择:
-
平衡模型容量和计算效率。
-
实验表明,扩展倍数小于4可能导致性能下降,大于4则收益递减。
2.3 解码器层(Decoder Layer)
比编码器多一个 掩码多头注意力(Masked Multi-Head Attention):
-
掩码机制:防止解码时看到未来信息(训练时用三角矩阵掩码)。
-
编码器-解码器注意力:解码器的
Q来自上一输出,K/V来自编码器输出。
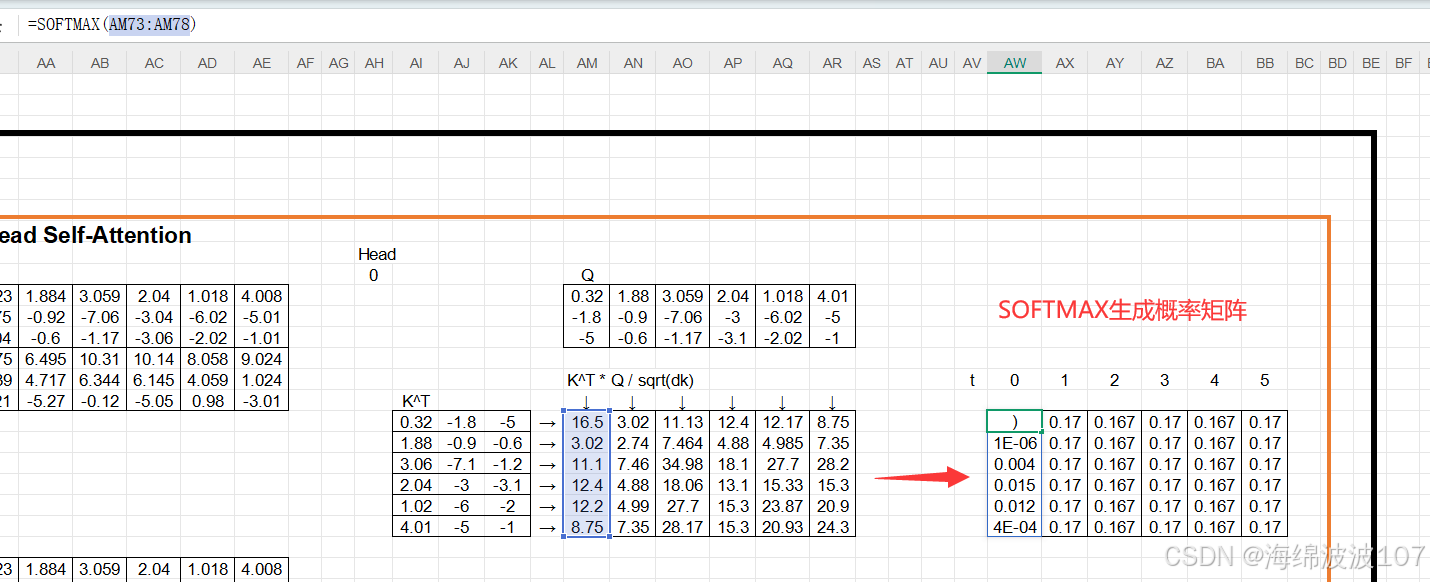
3. 关键数学细节
3.1 自注意力的计算步骤
-
线性变换生成
Q,K,V: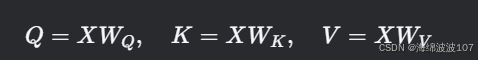
-
计算注意力分数并缩放:
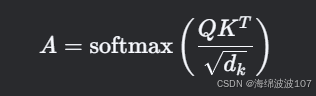
-
加权求和:

3.2 多头注意力的实现
-
将
Q/K/V拆分为h个头(维度d_k = d_model / h),分别计算后拼接:
其中,
head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)。
4. 代码实现(PyTorch 简化版)
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model=512, h=8):
super().__init__()
self.d_k = d_model // h
self.h = h
self.W_Q = nn.Linear(d_model, d_model)
self.W_K = nn.Linear(d_model, d_model)
self.W_V = nn.Linear(d_model, d_model)
self.W_O = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
# x: [batch_size, seq_len, d_model]
Q = self.W_Q(x) # [batch_size, seq_len, d_model]
K = self.W_K(x)
V = self.W_V(x)
# Split into heads
Q = Q.view(-1, Q.size(1), self.h, self.d_k) # [batch_size, seq_len, h, d_k]
K = K.view(-1, K.size(1), self.h, self.d_k)
V = V.view(-1, V.size(1), self.h, self.d_k)
# Scaled dot-product attention
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn = torch.softmax(scores, dim=-1)
output = torch.matmul(attn, V) # [batch_size, seq_len, h, d_k]
# Concatenate and project
output = output.transpose(1, 2).contiguous().view(-1, output.size(1), self.h * self.d_k)
return self.W_O(output)
class TransformerLayer(nn.Module):
def __init__(self, d_model=512, h=8, d_ff=2048):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, h)
self.ffn = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
# Self-attention + residual
attn_output = self.self_attn(x, mask)
x = self.norm1(x + attn_output)
# FFN + residual
ffn_output = self.ffn(x)
return self.norm2(x + ffn_output)5. Transformer 的变体与改进
-
BERT:仅用编码器,通过掩码语言模型预训练。
-
GPT:仅用解码器,自回归生成文本。
-
Efficient Transformers:
-
Sparse Attention(如 Longformer)降低计算复杂度。
-
Performer 用线性近似替代 Softmax。
-
6. 为什么 Transformer 如此强大?
-
全局依赖性建模:自注意力直接捕获任意距离的关系。
-
并行化优势:适合 GPU 加速,训练速度远超 RNN。
-
可扩展性:通过堆叠层数(如 GPT-3 有 96 层)处理复杂任务。
二、Transformer-Full-Stack全栈架构
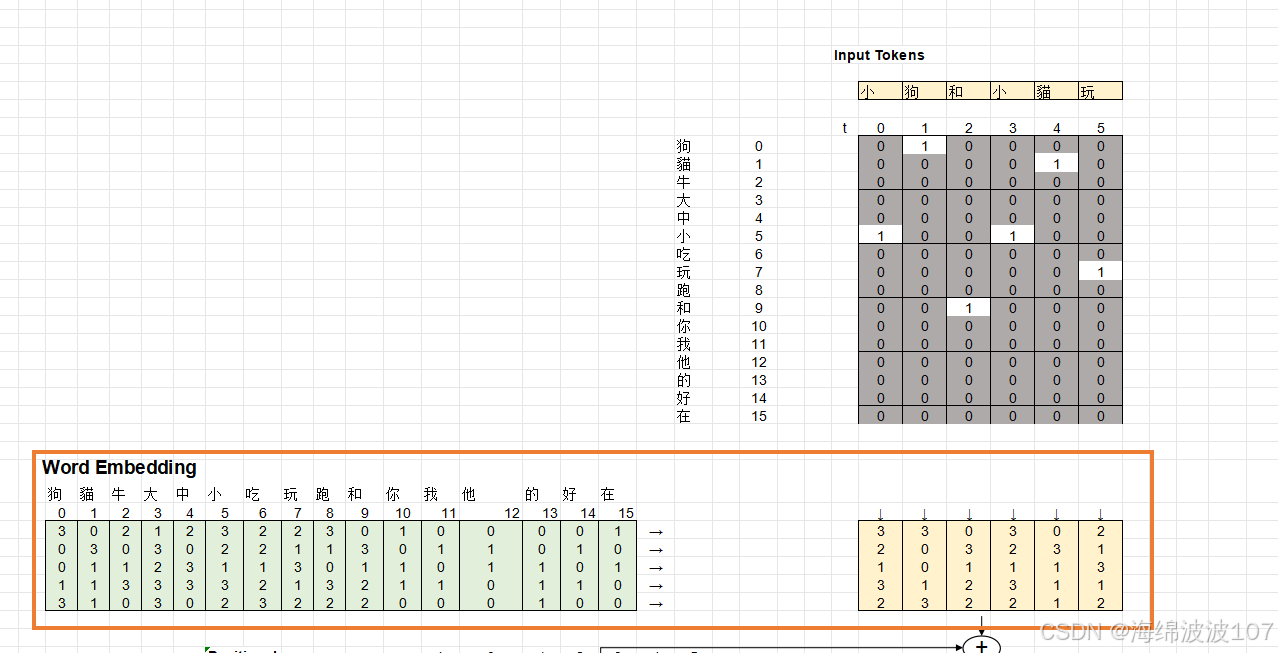
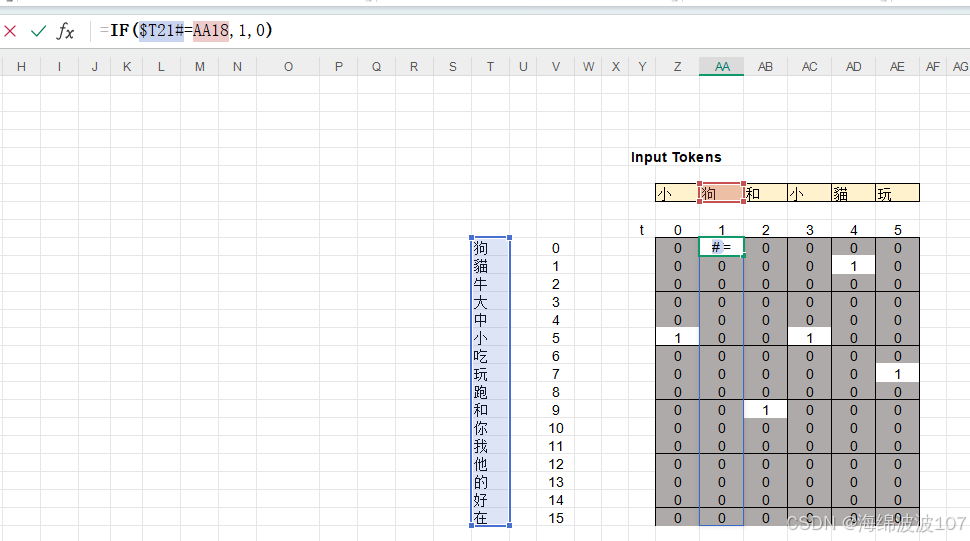
1. 输入处理
-
Token Embedding
-
输入:
[batch_size, seq_len](词ID序列) -
输出:
[batch_size, seq_len, d_model](如512维) -
作用:将离散词ID映射为连续向量。
-

-
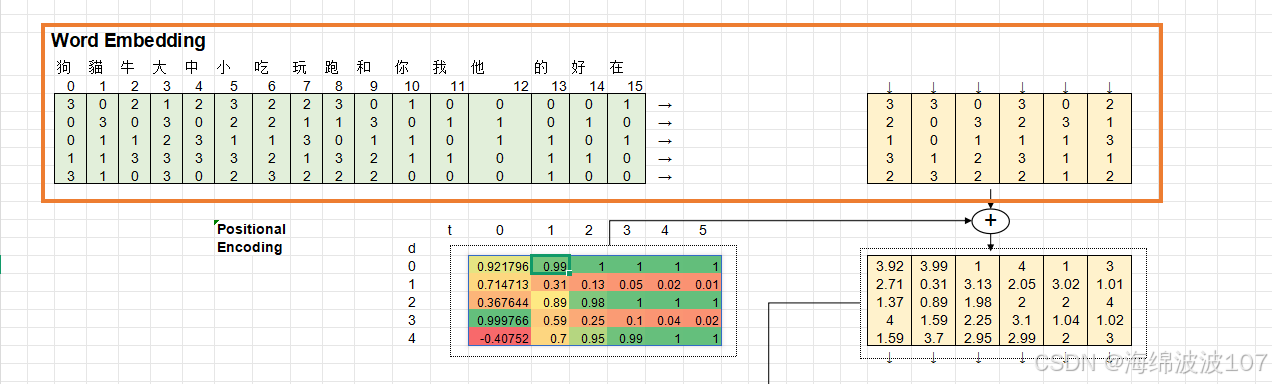
Positional Encoding
-
公式:
PE(pos,2i)=sin(pos/10000^(2i/d_model)) -
输出:与词嵌入相加,维度不变。
-
作用:为模型提供序列位置信息。
-
2. 编码器(Encoder)
-
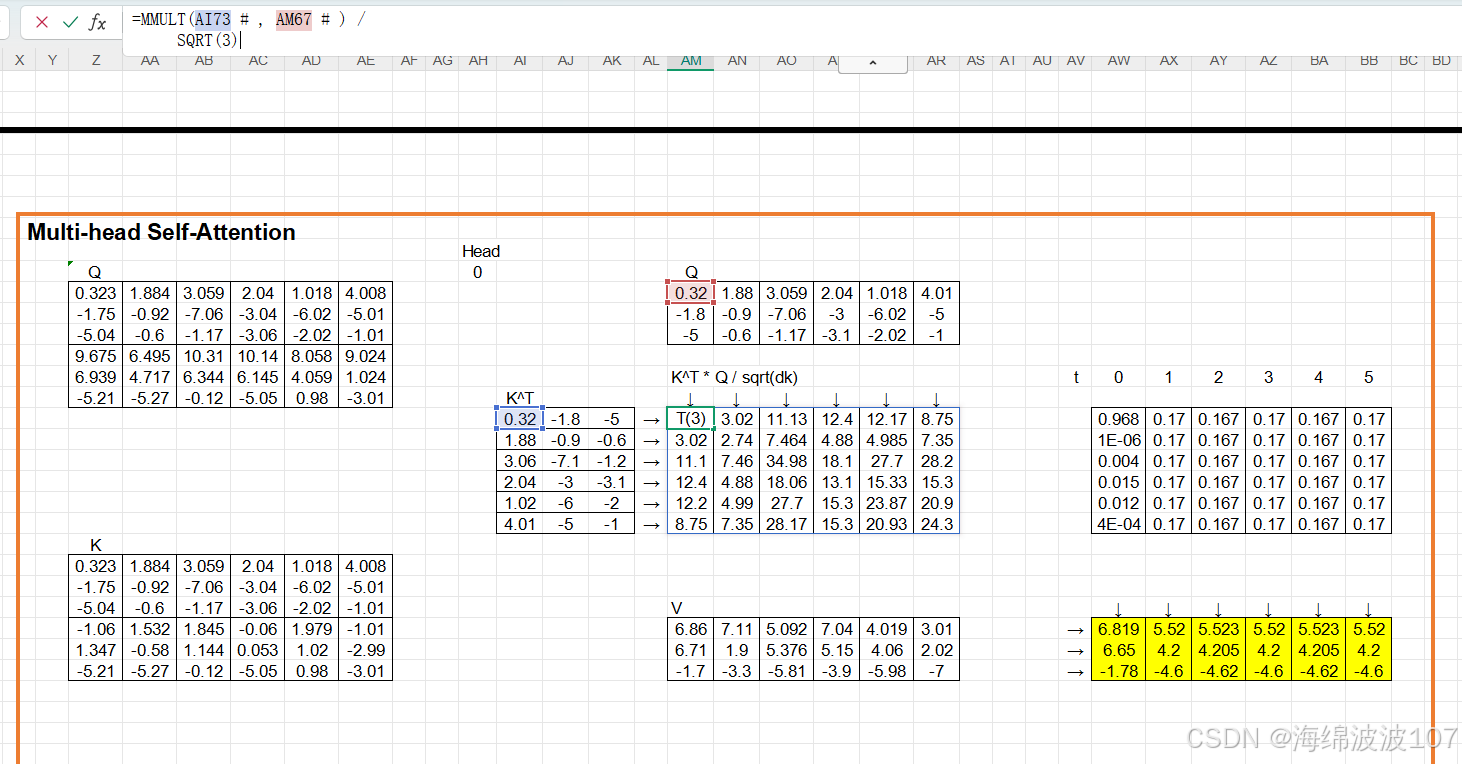
Multi-Head Attention
-
输入:
Q, K, V(均来自上一层输出) -
过程:
-
拆分为
h个头(如8头 → 每个头维度d_k = d_model/h = 64)。 -
计算缩放点积注意力:
softmax(QK^T/√d_k)V。 -
拼接多头输出并通过
W_O投影。
-
-
输出维度:与输入一致
[batch_size, seq_len, d_model]。
-
-
Feed-Forward Network (FFN)
-
结构:
Linear(d_model→d_ff) → ReLU → Linear(d_ff→d_model) -
典型尺寸:
d_ff = 4*d_model(如2048)。
-

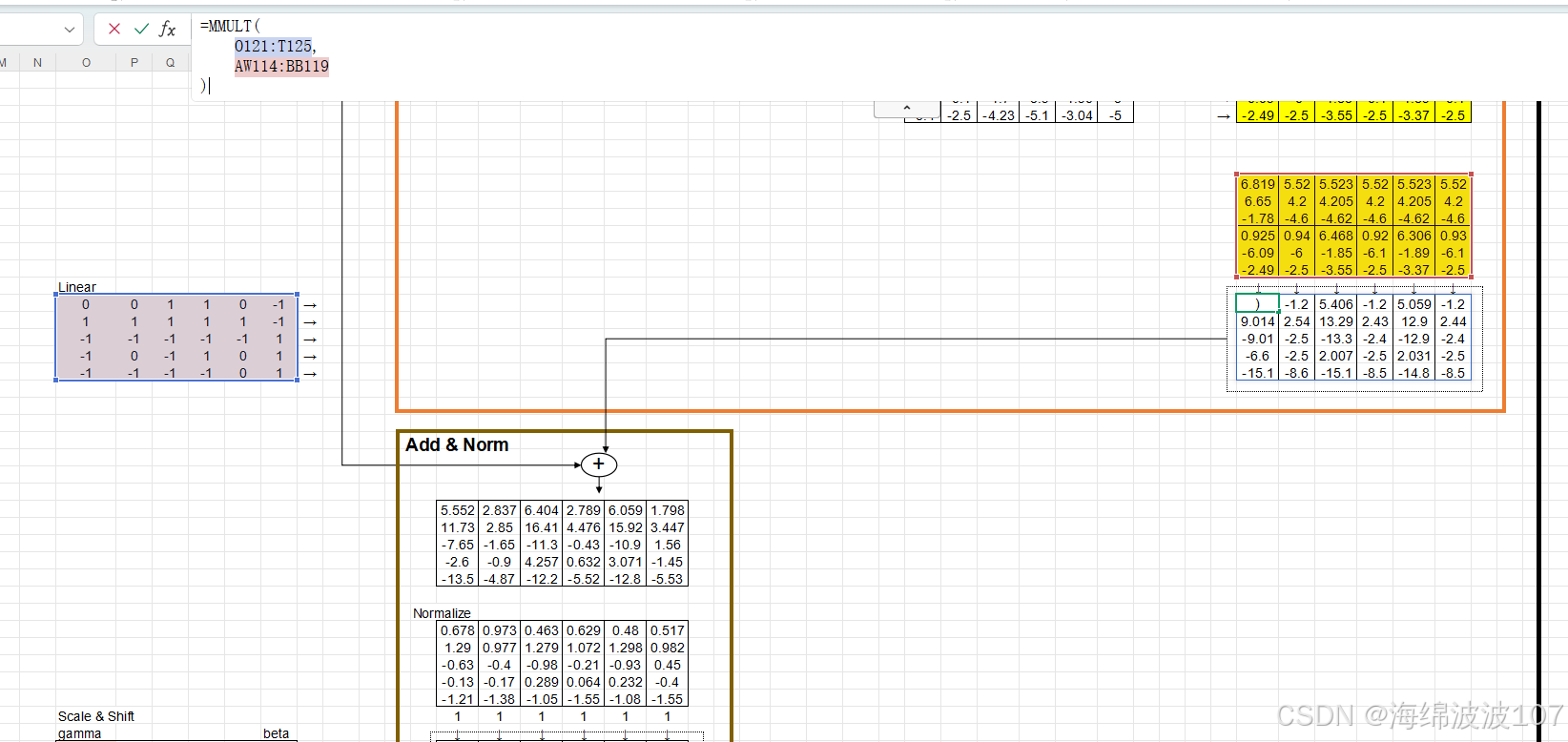 在Transformer中,Add & Norm(残差连接与层归一化)是每个子层(如自注意力、前馈神经网络)后的标准操作,其核心目的是稳定深层网络的训练并加速收敛。
在Transformer中,Add & Norm(残差连接与层归一化)是每个子层(如自注意力、前馈神经网络)后的标准操作,其核心目的是稳定深层网络的训练并加速收敛。
1. Add & Norm 的组成
-
Add(残差连接):
将子层(如Self-Attention或FFN)的输入x 和输出 Sublayer(x) 直接相加: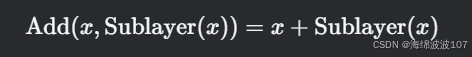
-
Norm(层归一化):
对相加后的结果进行层归一化(Layer Normalization):
3. 解码器(Decoder)
-
Masked Multi-Head Attention
-
区别:在Softmax前添加下三角掩码(
mask=-inf),防止看到未来信息。
-
-
Encoder-Decoder Attention
-
Q:来自解码器上一层的输出。 -
K, V:来自编码器的最终输出。
-
解码器使用了中文输入的英文表示,再走一遍刚刚编码器的流程
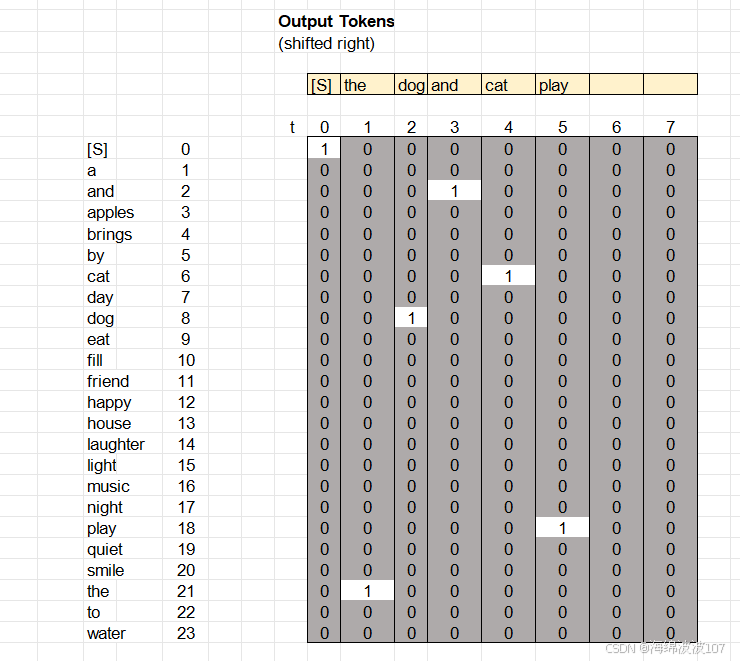
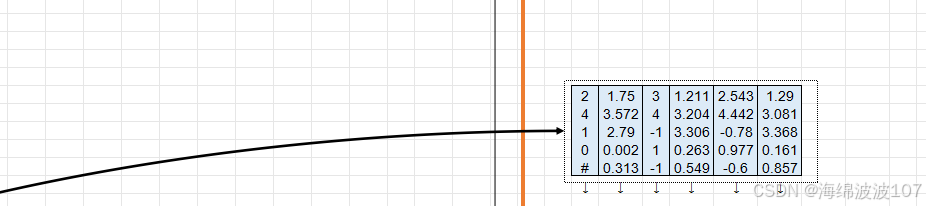
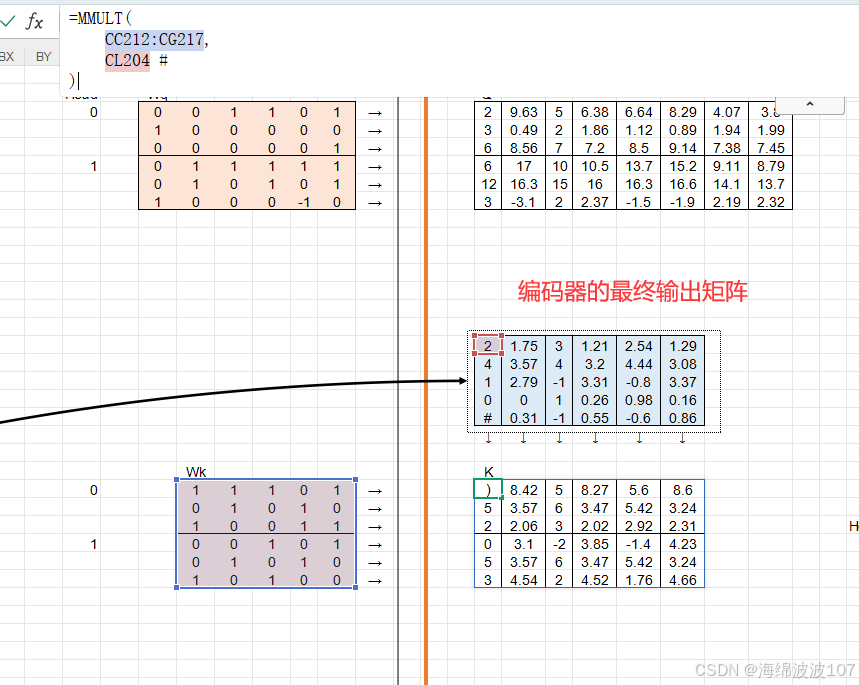
编码器的最终输出会作为Key(K)和Value(V)传递给解码器的“编码器-解码器注意力”层
在Transformer的解码器中,编码器的最终输出会作为Key(K)和Value(V)传递给解码器的“编码器-解码器注意力”层(即第二个多头注意力子层),而Query(Q)来自解码器自身的当前状态。这种设计是为了实现跨序列的信息融合,让解码器能够动态关注编码器输出的相关部分。以下是详细解释:
1. 核心目的:信息桥接
编码器的输出(通常称为“记忆”)包含了输入序列的全局编码信息(如源语言的语义特征)。解码器需要根据这些信息生成目标序列(如翻译结果)。通过将编码器输出作为K和V,解码器可以:
-
动态检索输入序列的关键内容(通过Q与K的匹配)。
-
避免重复编码(解码器无需重新学习输入序列的表示)。
2. 为什么这样设计?
(1)解耦生成与检索
-
解码器自身(通过Q)专注于已生成序列的状态管理。
-
编码器输出(K/V)专注于提供输入序列的全局信息库。
-
类比:就像人类翻译时,先理解原文(编码器),再根据已翻译的部分(Q)查找原文中需要的信息(K/V)。
(2)处理不等长序列
-
输入(源序列)和输出(目标序列)长度通常不同(如翻译任务)。通过分离Q和K/V,模型可以灵活处理这种差异。
(3)避免信息冗余
-
如果解码器自行重新编码输入序列,会导致参数浪费和训练低效。直接复用编码器输出更高效。
这种设计是Transformer能够高效处理序列到序列任务的核心机制之一!
3. 典型应用场景
-
机器翻译:解码器生成目标语言时,动态参考编码器对源语言的编码。
-
文本摘要:解码器生成摘要时,关注输入文章的关键部分。
-
语音识别:解码器输出文本时,对齐音频编码特征。
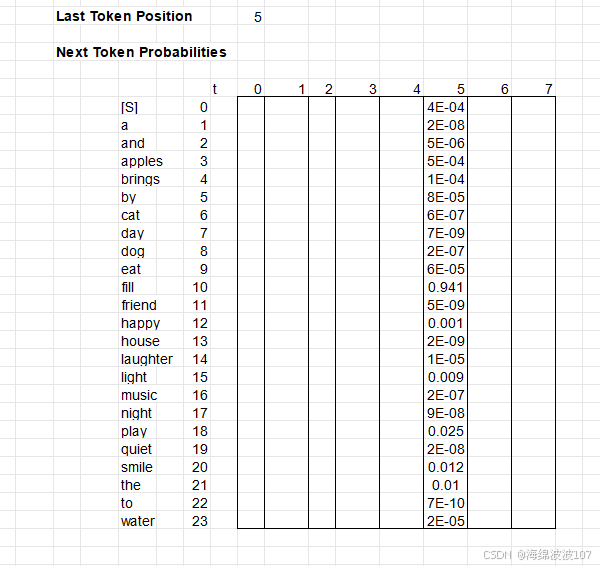
4. 输出生成
-
Linear + Softmax
-
线性层:将
d_model维映射到词表大小vocab_size。 -
Softmax:生成每个位置的词概率分布。
-
三、AlphaFold
AlphaFold 是 DeepMind 开发的突破性 AI 算法,用于预测蛋白质的三维结构。它的出现解决了生物学领域长达 50 年的“蛋白质折叠问题”,被《科学》杂志评为 2020 年十大科学突破之首。以下从多个维度深入解析其核心原理和技术创新:
一、蛋白质折叠问题的挑战
-
生物学意义:蛋白质的功能由其 3D 结构决定,但实验测定(如X射线衍射、冷冻电镜)成本高且耗时。
-
计算复杂度:一个典型蛋白质的构象空间可达 1030010300 种,传统计算方法(如分子动力学)难以穷举。
二、AlphaFold 的技术演进
AlphaFold1(2018)
-
核心思想:将结构预测转化为空间约束优化问题。
-
关键技术:
-
使用残基间距离矩阵(distance matrix)作为预测目标。
-
结合进化信息(MSA,多序列比对)和几何约束。
-
通过梯度下降优化损失函数。
-
-
局限:依赖离散的距离区间分类,精度有限。
AlphaFold2(2020)
-
颠覆性创新:端到端的几何深度学习框架。
-
核心模块:
-
Evoformer(进化信息处理):
-
输入:MSA + 模板信息 → 通过自注意力机制提取协同进化信号。
-
输出:残基对(pair)和单残基(single)的特征表示。
-
-
Structure Module(结构生成):
-
基于 SE(3)-等变网络(SE(3)-equivariant transformer),直接预测原子坐标。
-
通过迭代优化(48次循环)逐步修正结构。
-
-
损失函数:
-
结合 FAPE(Frame-Aligned Point Error)和立体化学约束(键长/键角)。
-
-
三、关键技术创新
-
几何深度学习:
-
使用 SE(3)-等变网络处理三维旋转/平移对称性,避免数据冗余。
-
示例:原子坐标更新时保持物理一致性(如 Cα 骨架的刚性运动)。
-
-
注意力机制的进化:
-
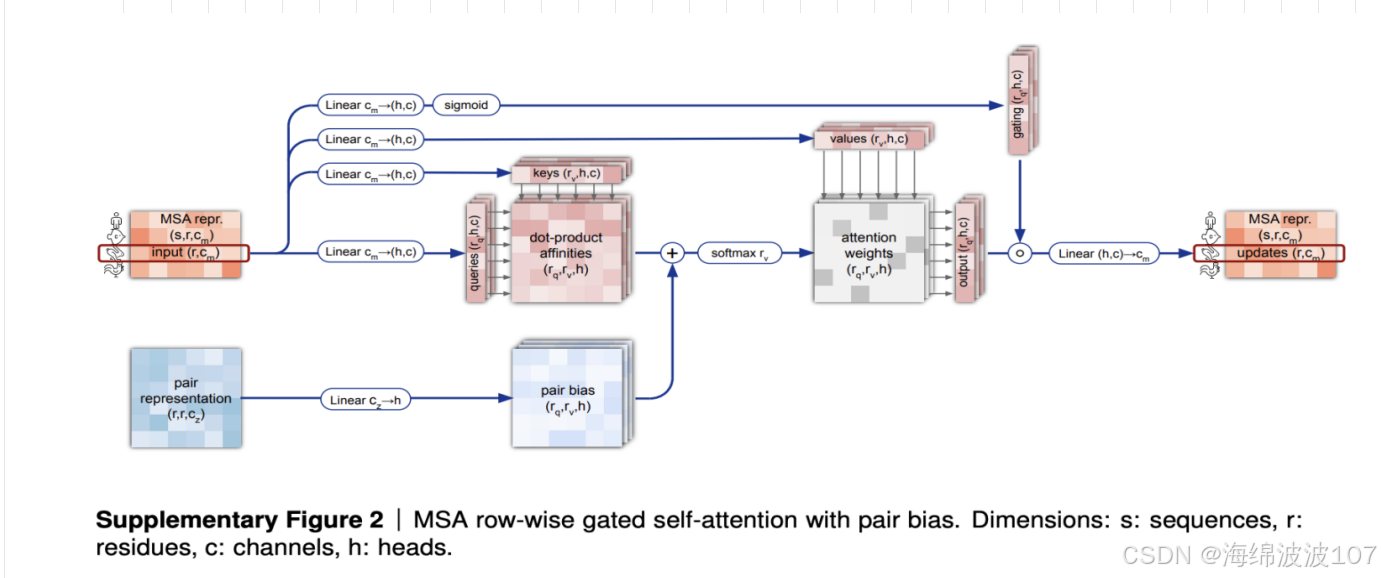
MSA 行注意力(捕捉同源序列关系) + 列注意力(捕捉残基间相互作用)。
-
在AlphaFold等蛋白质结构预测模型中,Pair Representation(配对表示) 是一种关键的数据结构,用于编码蛋白质序列中残基对(residue pairs)之间的相互作用和空间关系。它是模型理解蛋白质3D结构的核心特征之一。
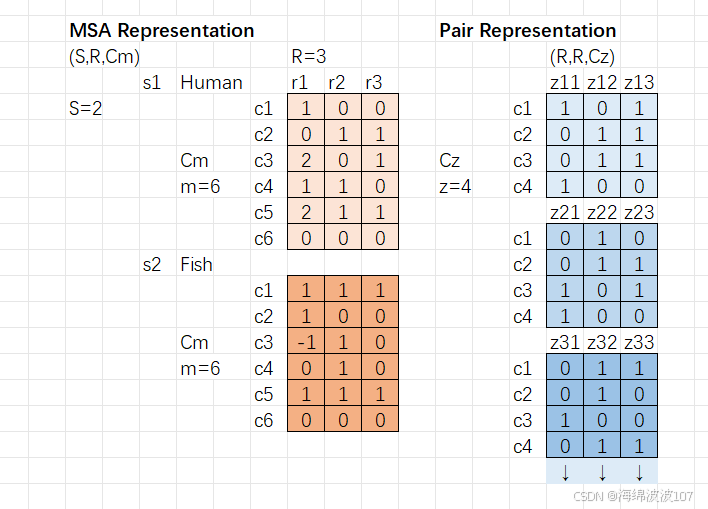
2. 三角注意力(triangular attention)处理残基对的特征更新。
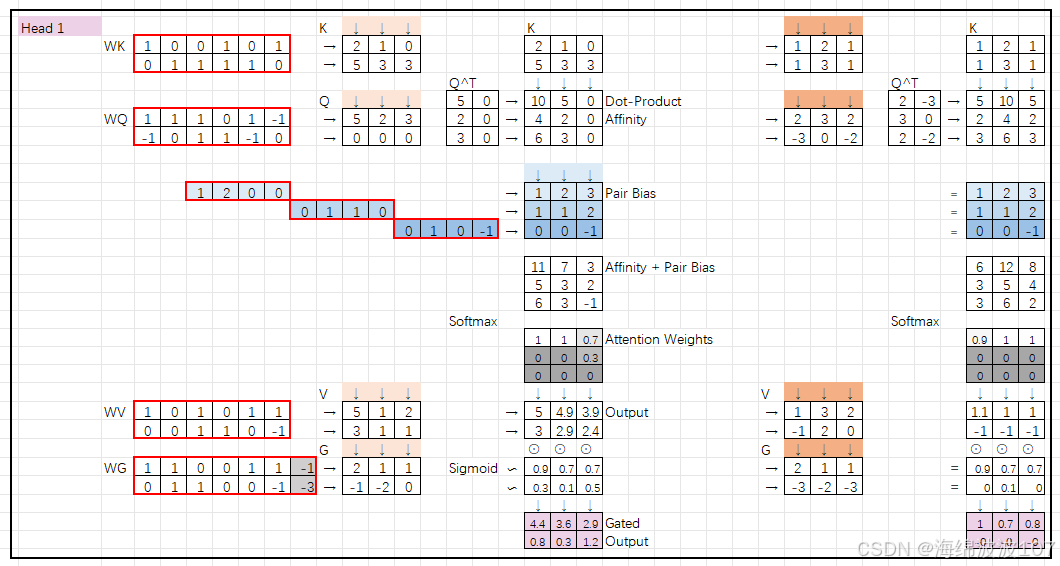
1. 多头注意力机制(Multi-Head Attention)
多头注意力是Transformer的核心组件,通过并行运行多个独立的注意力头,从不同角度捕捉输入数据的不同特征。
-
每个头(head):是一个独立的注意力计算单元,拥有自己的权重矩阵(Query、Key、Value)。
-
作用:允许模型同时关注输入的不同子空间或不同特征模式(如局部/全局关系、不同语义层次等)。
公式表示:

其中,每个头的计算为:
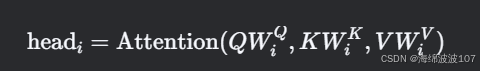
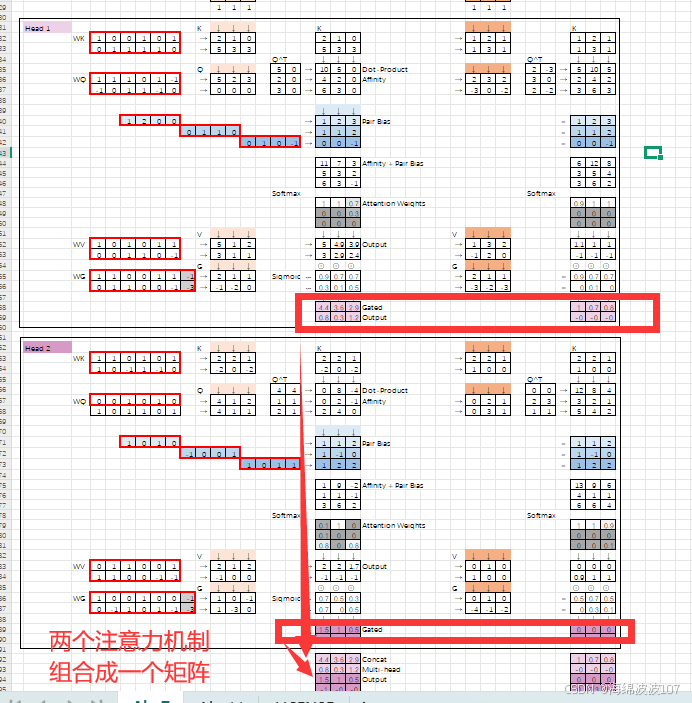
2. head1、head2 的具体含义
-
head1:第一个注意力头,可能专注于某种特定模式(如蛋白质序列中的局部相互作用)。
-
head2:第二个注意力头,可能捕捉另一种模式(如全局拓扑约束)。
在AlphaFold中,不同头可能分别关注:-
残基间的物理距离
-
进化共变信号
-
氢键网络
-
3. 为什么需要多头?
-
并行捕捉多样性:单一注意力头可能无法同时建模复杂关系(如蛋白质中并存的局部和长程相互作用)。
-
增强表达能力:类似卷积神经网络中的多通道滤波。
-
可解释性:不同头可能学习到有明确物理意义的模式(需事后分析验证)。
可学习权重矩阵(Learnable Weight Matrices)
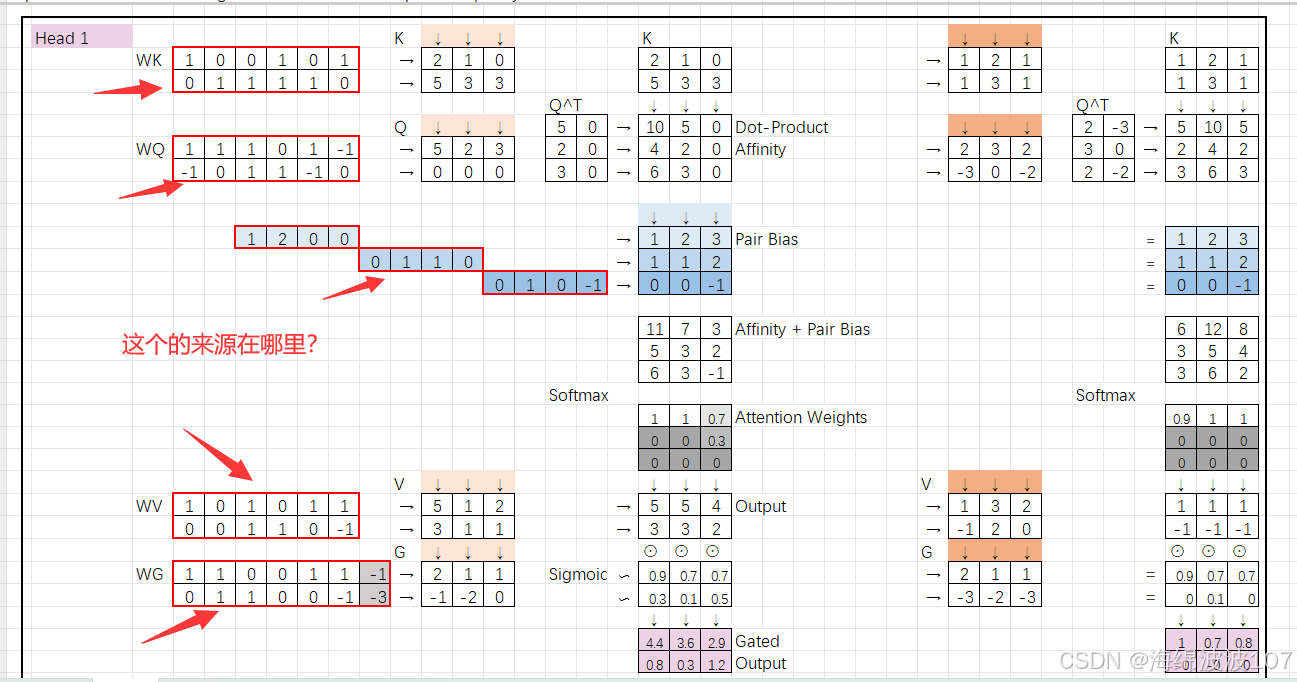
在深度学习和Transformer架构中(包括AlphaFold),WK、WQ、WV、WG 是注意力机制中的可学习权重矩阵(Learnable Weight Matrices),用于将输入特征映射到不同的子空间,以便计算注意力分数或生成输出。它们不是原始特征,而是模型训练中优化的参数。以下是详细解释:
1. 基本定义
这些权重矩阵属于注意力机制的核心组件,作用如下:
| 符号 | 全称 | 作用 | 维度示例 |
|---|---|---|---|
| WQ | Query Weight Matrix | 将输入映射到查询(Query)空间,用于计算注意力分数。 | [D_input, D_q] |
| WK | Key Weight Matrix | 将输入映射到键(Key)空间,与Query匹配生成相似性分数。 | [D_input, D_k] |
| WV | Value Weight Matrix | 将输入映射到值(Value)空间,生成注意力加权后的输出特征。 | [D_input, D_v] |
| WG | Gate Weight Matrix | (可选)门控机制中的权重,控制信息流动(如AlphaFold中的门控注意力)。 | [D_input, D_g] |
-
输入维度:
D_input(例如,AlphaFold中MSA嵌入的1280维)。 -
输出维度:
D_q、D_k、D_v通常相同(如64维)。
总结
-
WK、WQ、WV、WG 是模型参数,用于特征变换和注意力计算,而非输入特征。
-
它们在AlphaFold中实现:
-
进化信息的动态筛选(通过Q/K)。
-
结构约束的逐步满足(通过V)。
-
冗余信息的过滤(通过WG)。
-
-
理解这些权重的作用是剖析Transformer类模型(包括AlphaFold)的关键。
模型参数通过训练过程逐步调整
WK、WQ、WV、WG 等模型参数 正是通过训练过程逐步调整的,模型通过不断学习数据中的规律(如蛋白质的进化关系、结构约束等),最终使这些参数能够捕捉到输入特征的本质特点。
1. 模型参数的核心作用
这些权重矩阵的本质是 “可学习的特征变换器”:
-
动态投影:将输入特征(如氨基酸序列的嵌入向量)映射到更适合任务的空间(如关注结构相互作用的子空间)。
-
模式提取:通过训练自动学习哪些特征组合对预测蛋白质结构关键(例如共进化信号 vs 物理化学属性)。
类比:
想象教一个孩子识别动物:
-
初始时,孩子随机关注动物的颜色或形状(类似初始化的随机权重)。
-
通过反复观察(训练数据),他学会“耳朵形状”比“尾巴长度”更能区分猫和狗(类似权重收敛到重要特征)。
2. 参数如何学习?
(1) 训练过程
-
前向传播:用当前参数计算预测结构(如原子坐标)。
-
损失计算:比较预测与真实结构的误差(如FAPE损失)。
-
反向传播:通过梯度下降调整参数,降低误差。
(2) 参数更新示例(简化)
假设损失函数为 L,学习率 η:
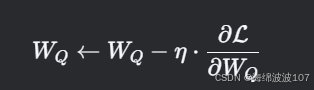
(3) AlphaFold中的特殊优化
-
混合损失:同时优化结构误差(坐标偏差)和物理合理性(键长/键角)。
-
等变约束:确保 WQ/WK/WV 的更新不破坏SE(3)-等变性(如旋转输入时输出同步旋转)。
3. 学习到的“事物特点”示例(AlphaFold)
通过训练后,参数会编码生物学规律:
| 参数 | 可能学习到的模式 | 生物学对应 |
|---|---|---|
| WQ | 哪些残基应作为“查询”关注其他残基 | 活性位点残基的强相互作用倾向 |
| WK | 哪些残基可能作为“键”响应查询 | 共进化残基对的协同信号 |
| WV | 如何将注意力分数转化为结构更新信息 | 氢键网络的几何规则 |
| WG | 何时抑制不可靠的注意力头(如低质量MSA区域) | 无序区域的噪声过滤 |
4. 与人类学习的对比
| 步骤 | 人类学习 | 模型训练 |
|---|---|---|
| 初始状态 | 随机猜测 | 参数随机初始化 |
| 反馈信号 | 老师纠正错误 | 损失函数计算预测偏差 |
| 调整方式 | 强化正确记忆 | 梯度下降更新权重 |
| 最终能力 | 掌握识别规则 | 参数固化,捕捉数据规律 |
四、性能与局限
-
准确性:
-
CASP14 竞赛中 Median GDT_Score 达 92.4(>90 可视为实验精度)。
-
对部分膜蛋白和动态构象预测仍不理想。
-
-
速度:预测单个蛋白质仅需分钟级(GPU加速)。
-
开源影响:AlphaFold DB 已公开数百万种物种的预测结构。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











