







一、基本概念
- 数据:
①传感器采集到的各种物理、生物、化学指标等等各种可记录,可表征的数量,性质都是数据。
②现实中某种事物或事物间关系数量或性质的表征和记录,都称之为数据。
③信息的载体。 - 大数据
大数据(big data,mega data)或称巨量资料,指的是需要新处理模式才能具有更强的决策力、洞察力和流程优化能力的海量、高增长率和多样化的信息资产。----来自百度link
4V特点:
Ⅰ. 体量大(high Volume)
Ⅱ. 速度快而时效高(high Velocity)
Ⅲ. 类型繁多(high Variety)
Ⅳ. 价值密度低(high Veracity) - 数据科学
应用科学的方法、流程、算法和系统从多种形式的结构化或非结构化数据中提取知识和洞见的交叉学科。 -------维基百科
数据科学包括数据的搜集、存储、分类、处理、分析、呈现.
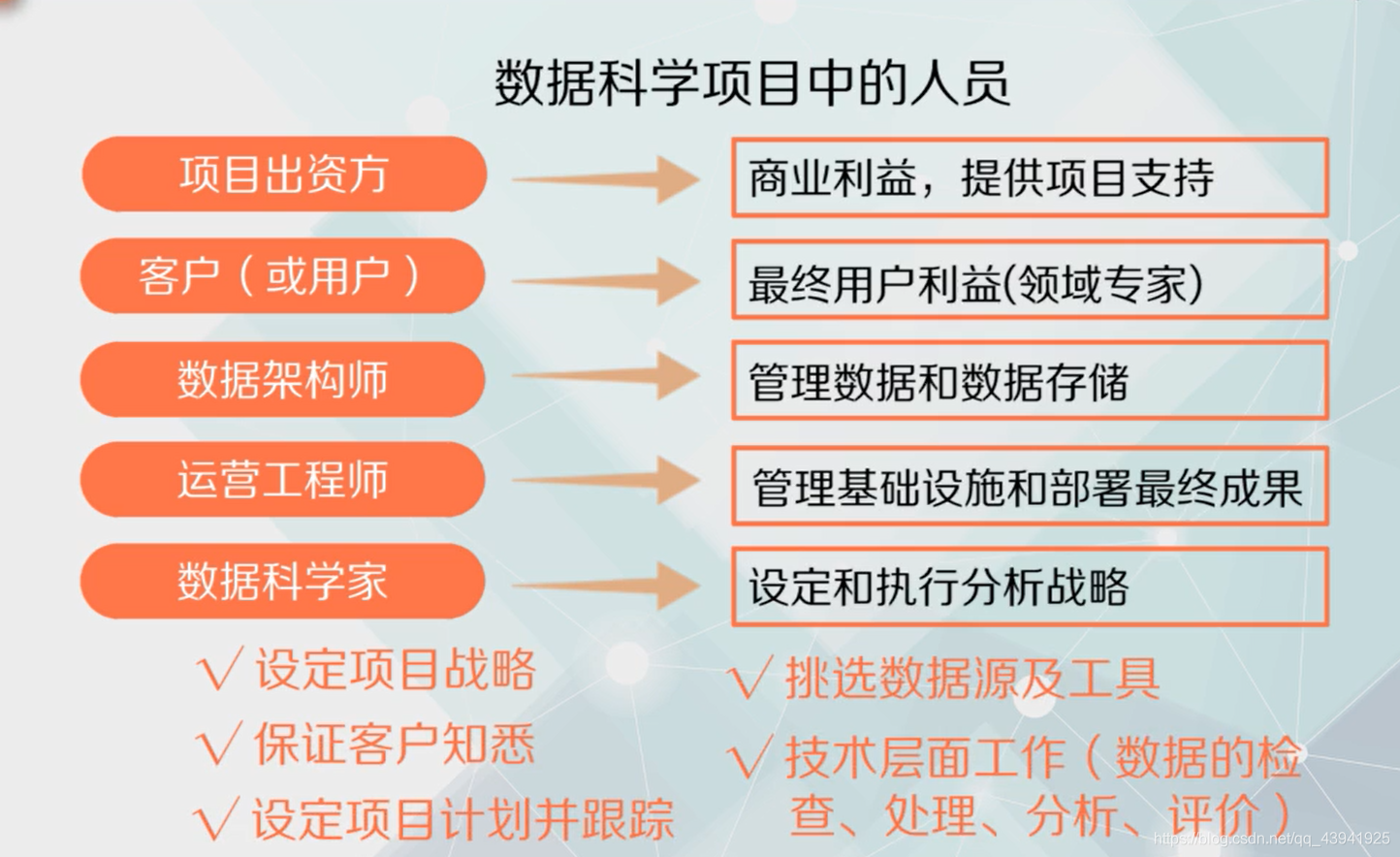
数据科学项目中的人员及其任务
二、项目流程
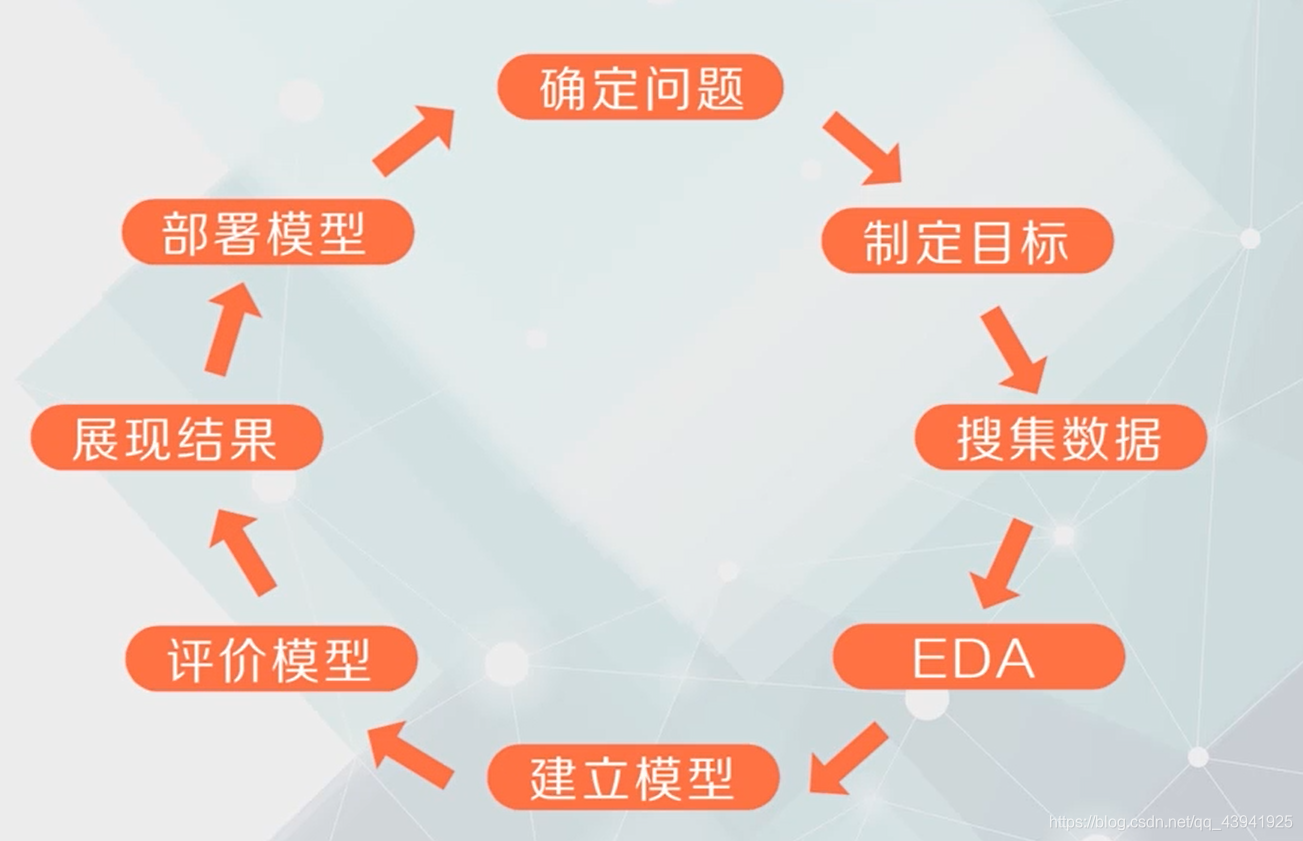
1.问题的确定
用户层面:需要考虑出资方的动机、需求。
数据科学层面:预测、分类、关联、特征化、聚类、打分或排名
2.制定目标
应用层面和数据科学层面都要做到明确、具体、可验证、可量化
3.收集数据
4.EDA(探索性数据分析)
初步了解数据特性,形成一些初步假设
拓展:EDA
概念:是指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。
作用:在统计学中,探索性数据分析(EDA)是一种分析数据集以概括其主要特征的方法,通常使用可视化方法。可以使用统计模型,但主要EDA是为了了解数据在形式化建模或假设测试任务之外能告诉我们什么。探索性数据分析是John Tukey提拔的鼓励统计学家的研究数据,并尽可能提出假设,尽可能生成新的数据收集和实验。EDA不同于初始数据分析(IDA),它更集中于检查模型拟合和假设检验所需的假设,以及处理缺少的值,并根据需要进行变量转换,EDA包含IDA。
5.建立模型
常见任务 + EDA结果 ====>选择并构建合适的模型
👇
预测
分类
关联
特征化
聚类
打分或排名
常见模型
1.统计学模型
2.回归(线性,Logistics)
3.贝叶斯分类器
4.神经网络
5.随机森林
6.评价模型
各类问题对应的指标也不一样。
分类问题------>混淆矩阵
特征提取------>ROC曲线和AUC
统计分析------>统计检验p值和置信区间
有效的数据科学模型----->评价指标需优于以往实现同类任务的模型所实现的指标
不了解以往工作的情况下----->至少要优于空模型的指标(空模型即最简单的模型)
7.展现结果
通过可视化的方法突出对象(出资方或者用户或者数据科学家)所关心的内容。
8.部署模型
测试
确保稳定运行
避免灾难性决策
此文章为学习完中国大学慕课中南京大学的探索数据的奥秘课程第一讲后所写,如需要观看可以访问下面的链接
link














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









