









0:前言
作者是ABAP新手 之前只学过C / JAVA等语言,所以笔记类型偏向于把ABAP的本质知识和C以及JAVA串联起来,在学习的基础上加了一些自己的理解,故希望读者具有C和面向对象的基础,才能更好的学习各项语言。
1:SAP开发工具
工具名:SAP GUI
常用 T-code (事务码)
se38 创建程序、ABAP 编辑器
se80 abap工作台
SE84 访问 ABAP 资源库信息系统(在 SAP 轻松访问菜单中,选择工具 → ABAP 工作台 → 概览 → 信息系统)
SE11 ABAP 字典(显示、更改、创建)
SE12 ABAP 字典(仅显示)
SE51 屏幕绘制器
SE41 菜单绘制器
SE37 功能构建器
SE24 类构建器
SM30 数据库表维护视图
/o GUI新开窗口
/n GUI当前窗口
常用系统变量
SY-SUBRC: 系统执行某指令后,表示执行成功与否的变量,0表示成功
SY-DBLNT: 被处理过的记录的笔数
SY-UNAME: 当前使用者登入SAP的USERNAME
SY-DATUM: 当前系统日期
SY-UZEIT: 当前系统时间
SY-TCODE: 当前执行程序的Transaction code
SY-REPID: 当前程序名称
SY-INDEX : 当前LOOP循环过的次数
SY-TABIX: 当前处理的是internal table 的第几笔
SY-TMAXL: Internal table的总笔数
SY-SROWS: 屏幕总行数
SY-SCOLS: 屏幕总列数
SY-MANDT: 當前系統編號(CLIENT NUMBER)
SY-VLINE: 画竖线
SY-ULINE: 画横线
SY-PAGNO: 当前页号
SY-LINSZ: 当前报表宽度
SY-LINCT: 当前报表长度
SPACE: 空字符串
SY-LSIND: 列表索引页
SY-LISTI: 上一个列表的索引
SY-LILLI: 绝对列表中选定行的行号
SY-CUROW: 屏幕上的行
SY-CUCOL: 光标列
SY-CPAGE: 列表的当前显示页
SY-STARO:真实行号
SY-LISEL: 选择行的内容,长度为255
SY-LANGU:当前系统语言
SY-LINNO: 当前行
SY-SUBRC:语句执行后的返回值,0表示成功
SY-DATUM:当前服务器日期
SY-UZEIT:当前服务器时间
SY-ULINE:255长度的水平线
SY-VLINE:垂直线
SY-INDEX:循环说执行的次数
SY-TABIX:内表循环的次数
SY-DYNNR:当前Screen号
SY-MANDT:当前登录的Client号
SY-STEPL:返回当前操作的屏幕行号(Table Control)
SY-LOOPC:当前表格控件在屏幕中的总行数(Table Control)
SY-UCOMM:PAI所出发的功能代码
SY-DYNNR:当前屏幕号
SY-MSGID:Message Class
SY-MSGNR:Message Number
SY-MSGTY:Message Type
SY-MSGV1~4:Message Variant
SY-LINCT:REPROT语句中设定的LINE-COUNT
SY-LINSZ:REPROT语句中设定的LINE-SIZE
SY-SROWS:当前窗口的列表行数
SY-SCOLS:当前窗口的列表栏目数
SY-PAGNO:当前页的页码
SY-LINNO:当前选定行的行号
SY-COLNO:当前选定列的列号
SY-LSIND:当前列表索引,第一级列表为1
SY-LILLI:选择某行时光标行位置
SY-CUROW:选择某行时光标列位置
- 程序命名
- 定制化程序 Z开头
- 自己测试使用 不开放给用户 Y开头
- 对程序设
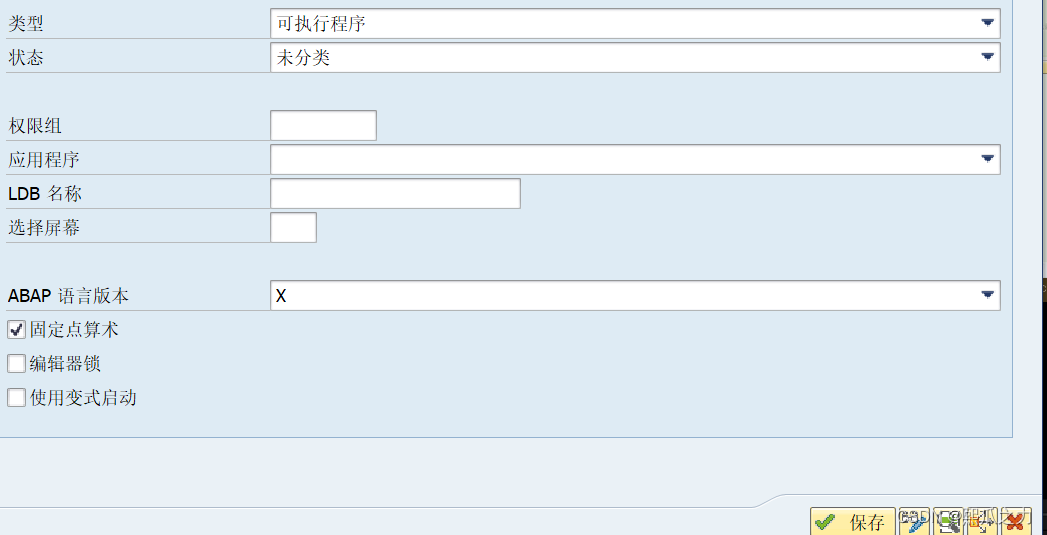
程序类型一般是 可执行程序
2:数据类型
2.1:ABAP基本数据类型
2.1.1:数据类型分类
-
数据类型 Data Type
-
ABAP基本数据类型
-
系统内部定的数据类型
-
类型 初始长度 可变长度 初始值 意义 I 4 4 0 整型 F 8 8 0 浮点型 P 8 1-16 0 高精度小数 C 1 1-65535 ‘…’ 文本字段 D 8 8 ‘00000000’ YYYYMMDD N 1 1-65535 ‘0…0’ 数字字符串 T 6 6 ‘000000’ HHMMSS X 1 1-65535 X’0…0’ 十六进制字段 -
三种数字类型
-
整数型 I :非整型运算进行四舍五入 ,
-
小数型 P :允许小数位 可用1~16位 小数位最大14位 小数点1位 高精度 存什么就展示什么 不存在精度丢失(其实也是字符串来表示小数)
-
必须设置程序属性为 Fixed point arithmetic(即定点算法,一般默认选中),若不选,类型P将失效为整数类型
DATA gv_p(16) TYPE P. "可变长度,指定变量长度,如果不指定 默认为8B 此时16是指32位的数字 可以有31个数字" DATA gv_p TYPE P DECIMALS 2."指定小数位为2位,最多可以14位" -
此类型两个数字的大小为1B,默认8B:可以表示一个15位的大数字,小数点占一个位置,一共是16个位,总共占8B。
-
-
浮点型 F :定义指数 ,需要调用”FLTP_CHAR_CONVERSION“函数把其转换位其他类型数据后才可以输出。
- F转换二进制时会发生进位误差。
- 数值较大或者是不需要进行四舍五入时可以使用类型F,取近似值时使用
-
创建程序时候没有选择 Fixed point arithmetic ,那么使用P类型时小数点会被忽略 只忽略小数点 例如 :1.1会变成11。
-
-
四种字符串类型:
-
C:定义文字,数字,特殊字符
-
N:用于显示C类型的数字,以字符串的方式显示整数
- 类型I:与变量长度无关,输出变量自身值。
- 变量N:变量值长度不足,前面补0补足位数,length位补够。并以字符串形式显示数值。
-
D:日期类型
*日期类型和时间类型 DATA: gv_date TYPE d. gv_date = sy-datum."获取当前的日期" WRITE :/ gv_date. gv_date = gv_date + 3."以日为计算基础 结果还是日期" WRITE :/ gv_date. DATA: gv_time TYPE t. gv_time = sy-uzeit."获取当前的时刻 093859 HHMMSS" WRITE :/ gv_time. gv_time = gv_time - 60."以秒为计算基础" WRITE :/ gv_time. -
T:时间类型
-
系统变量
sy-datum 和 sy-datlo 都表示系统日期
前面表示是SAP系统时间,后面表示是用户机的时间。
sy-uzeit 和 sy-timelo 都表示系统时间
-
-
-
-
局部数据类型
- 存在于程序内部
-
全局数据类型
- 存在于数据字典中
- 所有的程序都可以使用的数据类型
- SE11创建ABAP数据字典对象
-
-
数据变量 Data Variable
TYPES dtype[TYPE type|Like dobj]"关键词 TYPES"
DATA var[TYPE type|Like dobj]
TYPES: ty_char TYPE c LENGTH 11, "长度11的文本
ty_date TYPE d, "日期"
ty_float TYPE f, "浮点型"
ty_int TYPE i, "整数"
ty_num TYPE n, "数字文本"
ty_packed TYPE p LENGTH 10 DECIMALS 3,"压缩号"
ty_time TYPE t, "时间"
ty_x TYPE x, "十六进制"
ty_xstring TYPE xstring, "十六进制"
2.1.2:声明数据类型 TYPE/LIKE
方法一:参照基本数据类型定义变量
ABAP提供的基本类型定义变量
DATA:gv_num TYPE i,
gv_deci TYPE F,
变量名 TYPE 类型名,(最后一句要加句号 英文.)
方法二:参照局部数据类型定义变量
将程序中常用的数据以及结构声明为一个数据类型(自定义数据类型),但是此类数据类型只能在该程序内部使用
TYPES:BEGIN OF t_struct, "相当于是C语言的结构体"
col1 TYPE c,
col2 TYPE i,
col3 TYPE d,
END OF t_struct.
DATA:gs_struct TYPE t_struct,
gv var LIKE gs struct_col1.
方法三:参照全局数据类型定义变量
利用ABAP数据字典定义变量的方法,此数据类型在所有程序都可以使用。
DATA:gv_carrid TYPE s_carr_id,"数据字典类型"
gv_connid TYPE sflight-carrid, "数据字典类型"
gv_var TYPE c LENGTH 20. "全局数据类型"
LIKE:参考目标类型来声明
2.1.3:DATA语句
DATA 语句用于定义数据变量。
变量名包括了 “_”,最长可定义30位。
-
TYPE 变量类型名
DATA:gv_num1 TYPE i, gv_id TYPE i.冒号 使得一个命令从逗号开始执行,直达遇到句号结束
用一个冒号就可以避免重复使用相同命令
-
LIKE num
num 代表任何类型的变量,gv_num2可以定义成与gv_num1相同类型的变量。
DATA:gv_num2 LIKE gv_num1 -
VALUE int
设置变量的初始值
如果使用VALUE IS INITIAL (初始化),变量的初始值为所参照的数据类型的初始值,是可省略的。
DATA:gv_num TYPE i VALUE 123, gv_flag VALUE 'X', gv_idx LIKE sy-tabix VALUE 45. -
LENGTH n
指定字段长度,仅适用于C,N,P,X类型。
DATA:gv_num TYPE n LENGTH 2. -
DECIMALS n
仅适用于 P类型,n是指定1~14位的小数。
DATA:gv_num TYPE p DECIMALS 3.
2.1.4:ABAP基本语法
-
程序使用句号. 表示一个语句的结束。
-
注释分两种
1: *这是一个行注释 2: "这是一个右注释 -
字符串使用单引号 ‘this is string’ 显示。
gv_val = 'Enjoy ABAP'. -
各个命令用空格分开
gv_val = 'Enjoy'. 正确写法 各命令符号之间有空格
2.1.5:命名规则
SAP规定:
- ABAP 数据字典的程序以及数据对象后命名时,要以Z或Y开头
- 不能使用INSERT/APPEND 等关键字
- 允许定义变量名长度最大为30位,其中包含“_”。
- 变量前2位表示范围以及类型。
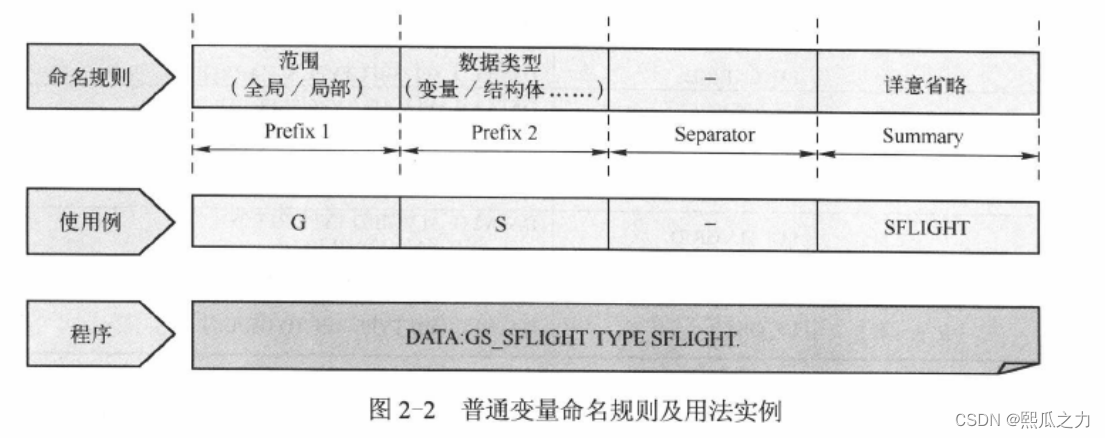
1:定义全局变量(Global Variable)
全局变量在程序激活状态下,一直占用内存地址。
定义全局变量时候要以G开头
具体数据定义方法:
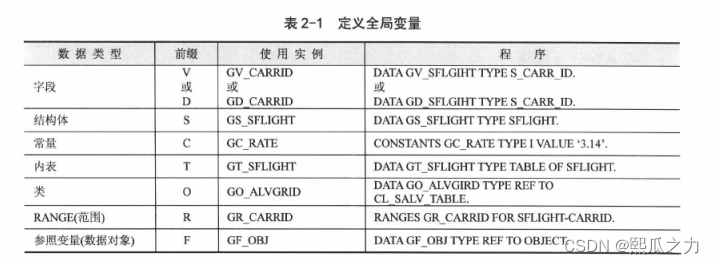
前缀长度设置是3位。
1:范围
2:数据类型
3:数据类型
例如:GVF_CARRID 意思是全局 字段 浮点型
2:局部变量
abap里面的局部变量和Java不同 abap局部变量不会自动清空 只是不能用于其他块内 局部变量在块内计算后会保持数据 再次调用该块 局部变量需要手动CLEAR才会清空局部变量的值
程序模块内的有效变量
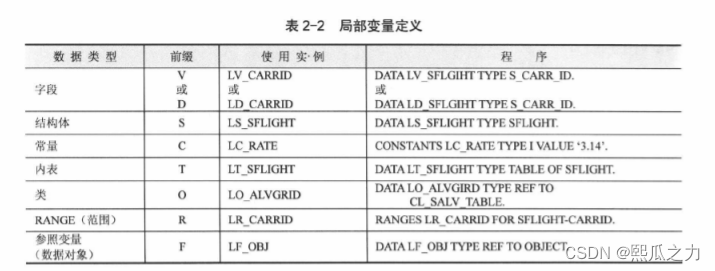
2.1.6:数字运算符(演算子)
数字类型 F 、I 、P可使用
| 符号 | 用法 | 作用相同关键字 |
|---|---|---|
| + | A + B | ADD A TO B |
| - | A - B | SUBTRACT B FROM A |
| * | A * B | MULTIPLY A BY B |
| / | A / B | DIVIDE A BY B |
| DIV | A DIV B | 取整 |
| MOD | A MOD B | 取余 |
| ** | A ** B | 乘幂 |
数字运算用函数
| 函数 | 说明 | 用法 |
|---|---|---|
| ABS | 返回绝对值 | ABS(-100) 返回100 |
| SIGN | 返回符号 | 负数 -> -1;0-> 0; 正数-> +; |
| CEIL | 返回不小于该值的最小整数 | ceil(1,3),ceil(1.7) 都返回2 |
| FLOOR | 与CEIL相反 | floor(1,3),floor(1.7) 返回1 |
| TRUNC | 取得整数部分 | trunc(1,3)返回1 |
| FRAC | 取得小数部分 | frac(‘2.9’) 返回0.9 |
Floating-Point函数
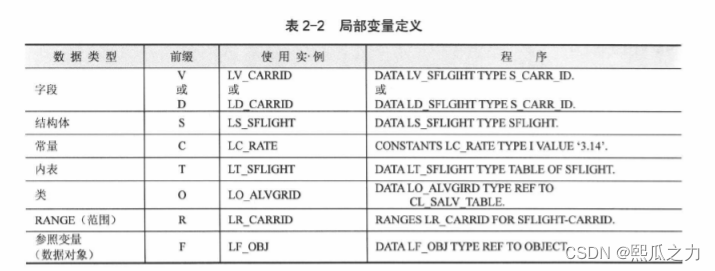
2.1.7:字符类型
字符字段,有以下四种类型
- C:用于定义文字,数字,特殊文字。
- N:用于显示C类型的数字,以字符串形式显示整数。
- D:日期类型。
- T:时间类型。
DATA gv_fd.
DATA gv_fd TYPE c.
DATA gv_fd(1) TYPE c. "直接指定C类型长度"
DATA gt_fd TYPE c LENGTH 1. "指定C,N,X,P的长度"
*以上四句语法执行效果一样
DATA gv_f0.
DATA gv_f1 TYPE C.
DATA gv_f2(1) TYPE C.
DATA gv_f3(2) TYPE C.
DATA gv_f4 TYPE C LENGTH 2.
DATA gv_f5(5).
DATA gv_len TYPE i.
MOVE: 'CHINA' TO gv_f0,
'CHINA' TO gv_f1,
'CHINA' TO gv_f2,
'CHINA' TO gv_f3,
'CHINA' TO gv_f4,
'CHINA' TO gv_f5.
WRITE :/ gv_f0,
/ gv_f1,
/ gv_f2,
/ gv_f3,
/ gv_f4,
/ gv_f5.
gv_len = STRLEN( gv_f5 ).
WRITE / gv_len."write / 代表换行"
2.1.8:不定长ABAP基本数据类型 string
最具代表的有:String 类型
程序执行时,才生成动态内存
| 命令语句 | 说明 | 用法 |
|---|---|---|
| FIND | 串内存在X字母时,sy-subrc变量(系统变量)返回值是0 | FIND P IN TEXT |
| REPLACE | 把F中的G 部分用P来替换掉 | REPLACE G IN F WITH INTO P |
| TRANSLATE | 大小写的替换 | TRANSLATE A TO LOWER/UPPER CASE |
| SHIFT | 左移位符号,所有字符向左移动一位 | SHIFT A |
| CONDENSE | 去掉串左边的空格实现左对齐 | CONDENSE A NO-GAPS |
| NO-GAPS | 去掉串内的空格配合condense使用 | |
| OVERPLAY | 填充Y前n个字符到串X内的首次检测到的n个连续空格中 | OVERPLAY X WITH Y |
| CONCATENATE | 连接两个串A,B,并存到C | CONCATENATE A B INTO C. |
| SPLIT | 以X为分隔符分割字符串S为A,B,C | SPLIT S AT ‘X’ INTO A,B,C |
| COUNT | 匹配指定字符串substring或正则式regex出现的子串次数,返回的类型为i整型类型 | count( val = TEXT {sub = substring} {regex = regex}) |
| MATCH | 返回的为匹配到的字符串。注:每次只匹配一个。occ:表示需匹配到第几次出现的子串。如果为正,则从头往后开始计算,如果为负,则从尾部向前计算 | match( val = TEXT REGEX = REGEX occ = occ) |
| STERLEN | String类型的尾部空格会计入字符个数中,但C类型的变量尾部空格不会计算入 | strlen(arg) |
`test space ` ===> 结果是“test space ” "可以完全识别空格"
'test space ' ===> 结果是“test space” "会把多余的空格给去掉"
2.1.9:Hexadecimal类型 十六进制类型 X类型
1B 8字节 => 4个字节为一个十六进制的码位
在ABAP 中主要用于印刷和图片处理部分
2.1.10:DESCRIBE
2.1.10.1:DESCRIBE FIELD
DESCRIBE FIELD DATA1
[TYPE typ [COMPONENTS com]] "运行结果是data1的类型被存储在typ1变量里,com1则存放了data1里面有几个子元素。"
[LENGTH ilen IN { BYTE | CHARACTER } MODE] "运行的结果是data1定义的长度存在了ilen里。"
[DECIMALS dec] "运行的结果是如果data1是小数,dec则存放了小数点后的位数。"
[OUTPUT-LENGTH olen] "运行的结果是data1的输出长度存在了olen里。"
[HELP-ID hlp]
[EDIT MASK mask].
2.1.10.2:DESCRIBE TABLE
DESCRIBE TABLE itab [KIND knd] [LINES lin] [OCCURS n] "判断内表itab的某些属性并把它们指定到指定的变量中。不同的选项使你能够判断表类型,当前字段行数 和 初始化需要的内存大小。"
2.1.10.3:DESCRIBE DISTANCE
DESCRIBE DISTANCE BETWEEN dobj1 AND dobj2 INTO dst
IN {BYTE|CHARACTER} MODE.
"这个语句把数据对象dobj1和dobj2的起始位置的距离赋给i类型的数据对象dst。如果是复杂数据类型,被参照的数据类型是不相关的除了内部参照的位置(对于字符串和内表)或者参考变量。Dobj1和dobj2以哪种顺序被指定并不重要。"
2.1.11:字符串表达式
String Template字符模板:字符串模板在 | … | 之间定义,主要分为两部分,固定文本和变量
变量只能在 { … } 内使用,大括号之外的所有字符均作为固定文本使用,空格始终不会被忽略
在使用变量时,可以通过控制语句来指定数据的显示格式,如例1,将日期用系统格式输出
在固定文本中,如果出现 | ,{ } 或 \ 等特殊字符时,需要使用转义符 \,如例2
"1 将日期转换为系统格式
"这里date= environment是用来格式化日期的,将日期转换成系统格式。
DATA(lv_string) = |Today is { sy-datum DATE = ENVIRONMENT }|.
"2 当有特殊符号时,在前面增加“\”,如:| 、{ } 或 \
data(lv_vbeln1) = conv vbeln('123').
lv_vbeln1 = |\\\|{ lv_vbeln1 }\}7|.
使用&或&&将多个字符模板串链接起来,可以突破255个字符的限制
|...| & |...|
|...| && |...|
"上面两行代码效果一样"
"在没有没有变量表达式或控制字符\r \n \t的时候 不需要使用字符模板也可以连接 但是如果有控制字符时不加字符模板将会失去控制效果"
`...` && `...` "忽略尾部空格
2.2:局部数据类型
2.2.1:声明类型
在程序中声明的数据类型视为局部数据类型,利用关键字TYPES 声明。
*局部数据类型
TYPES t_char10(10) TYPE c.
DATA gv_val1 TYPE t_char10.
DATA gv_val2 LIKE gv_val1.
gv_val1 = '1234567890'.
WRITE / gv_val1.
gv_val2 = '1234567890'.
WRITE / gv_val2.
*结构体--------------------------->start.
*声明结构体
TYPES: BEGIN OF t_ren,
name TYPE c LENGTH 20,
country TYPE c LENGTH 15,
city TYPE c LENGTH 10,
END OF t_ren.
*定义结构体变量
DATA gs_people1 TYPE t_ren.
gs_people1-name = 'JANG JONG SUK'.
gs_people1-country = 'CHINA'.
gs_people1-city = 'Beijing'.
WRITE :/ gs_people1-name,
gs_people1-country,
gs_people1-city.
*嵌入--嵌入结构体类型
TYPES: BEGIN OF t_info.
INCLUDE TYPE t_ren as ren.
TYPES: phone TYPE c LENGTH 10,
END OF t_info.
DATA gs_people2 TYPE t_info.
gs_people2-ren-name = 'JANG JONG SUK'.
gs_people2-ren-country = 'CHINA'.
gs_people2-ren-city = 'Beijing'.
gs_people2-phone = '123456789'.
WRITE :/ gs_people2-ren-name,
gs_people2-ren-country,
gs_people2-ren-city,
gs_people2-phone.
*直接定义结构体变量
DATA: BEGIN OF gs_people3,
name TYPE c LENGTH 20,
country TYPE c LENGTH 15,
city TYPE c LENGTH 10,
END OF gs_people3.
gs_people3-name = 'WW SUK'.
gs_people3-country = 'CHINA'.
gs_people3-city = 'Beijing'.
WRITE :/ gs_people3-name,
gs_people3-country,
gs_people3-city.
*嵌入--嵌入结构体变量--使用AS的
DATA: BEGIN OF gs_people4.
INCLUDE STRUCTURE gs_people3 AS ren.
DATA: phone TYPE c LENGTH 10,
END OF gs_people4.
gs_people4-ren-name = 'WWisAS SUK'.
gs_people4-ren-country = 'CHINA'.
gs_people4-ren-city = 'Beijing'.
gs_people4-phone = '123456789'.
WRITE :/ gs_people4-ren-name,
gs_people4-ren-country,
gs_people4-ren-city,
gs_people4-phone.
*嵌入--嵌入结构体变量--不用AS的简写
DATA: BEGIN OF gs_people5.
INCLUDE STRUCTURE gs_people3.
DATA: phone TYPE c LENGTH 10,
END OF gs_people5.
gs_people5-name = 'WWnotAS SUK'.
gs_people5-country = 'CHINA'.
gs_people5-city = 'Beijing'.
gs_people5-phone = '123456789'.
WRITE :/ gs_people5-name,
gs_people5-country,
gs_people5-city,
gs_people5-phone.
2.3:ABAP数据字典类型数据
数据字典的数据类型为全局数据类型
三种形式:
- 表以及视图
- 数据类型:数据元素,结构体,表类型
- 类型组
创建方式:
T-CODE:SE11创建、查询、修改数据字典
*数据字典
*参照表,视图声明数据类型
DATA: gs_sflight TYPE sflight."参考sflght表来生产变量 并进行赋值查询
SELECT SINGLE * FROM sflight INTO gs_sflight WHERE carrid = 'AA'.
WRITE:/ gs_sflight-carrid,
gs_sflight-connid.
*参照表的部分字段进行定义变量
DATA: gv_carrid TYPE sflight-carrid,
gv_connid TYPE sflight-connid,
gv_fldate TYPE sflight-fldate.
gv_carrid = 'AA'.
gv_connid = 0017.
gv_fldate = sy-datum.
WRITE: gv_carrid,
gv_connid,
gv_fldate.
*参照基本数据类型进行定义变量
*数据元素
DATA gs_carrid TYPE s_carr_id. "TYPE SFLIGHT-CARRID的数据元素
gs_carrid = 'AA'.
WRITE: 'Carrid:',gs_carrid.
*结构体 用se11 命令新建的数据字典的结构体
DATA gs_struct TYPE zstruct.
gs_struct-col1 = '1'.
gs_struct-col2 = 'Structure'.
gs_struct-col3 = 'ABAP Dictionary Test'.
WRITE: gs_struct-col1,gs_struct-col2,gs_struct-col3.
*利用类型组的TYPE 定义
DATA: gv_tgrpl TYPE ztgrp_typ1,
gv_tgrp2 TYPE ztgrp_typ2.
gv_tgrpl ='Type Group'.
gv_tgrp2-coll ='Test'.
gv_tgrp2-col2 =7.
WRITE:gv_tgrp1,gv_tgrp2-coll,gv_tgrp2-col2,ztgrp_name.
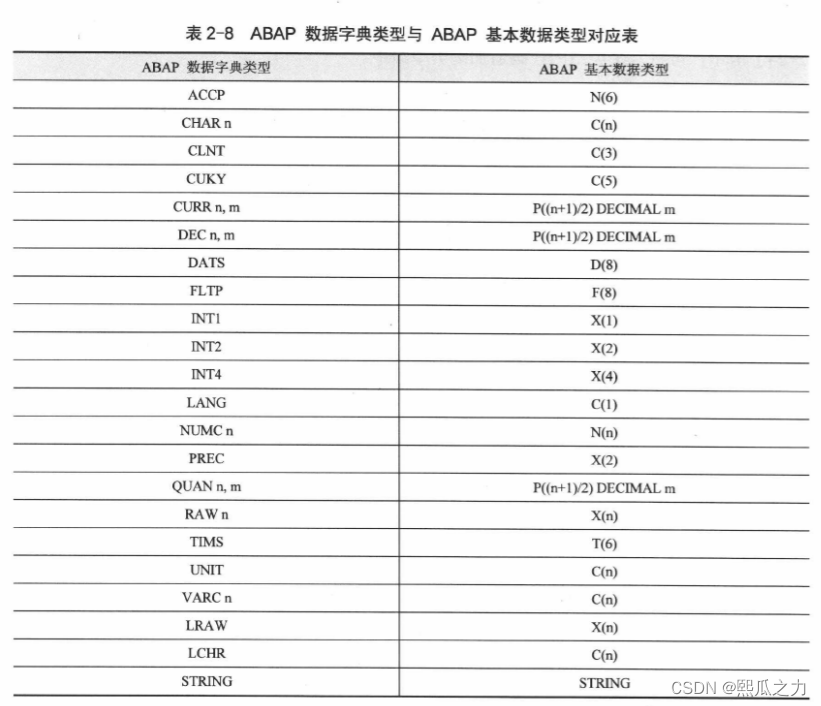
2.3.1:数据元素与域
数据元素是构成结构、表的基本组件,域又定义了数据元素的技术属性。
将技术信息从Data element提取出来为Domain域的好处:技术信息形成的Domain可以共用,而每个表字段的业务含意不一样,会导致其描述标签、搜索帮助不一样,所以牵涉到业务部分的信息直接Data element中进行描述,而与业务无关的技术信息部分则分离出来形成Domain
1:Data element
Data element主要附带Search Help、Parameter ID、以及标签描述
2:Domain
Domain主要从技术方面描述了Data element,如Data Type数据类型、Output Length输出长度、Convers. Routine转换规则、以及Value Range取值范围
2.4:赋值
2.4.1:给变量赋值
实际处理时,用MOVE 或者WRITE TO 语句来给变量赋值。
move a to b. a的数据类型还会被转换成b类型 (除了D和T以外,所有数据类型可以互相转换)
b=a.
write a to b.
都是把a的值赋值给b
*move-corresponding
如果想对结构体赋值
那么要使用
move-corresponding string1 to string2.
会按照名字相同的字段进行赋值
如果用move 则是单纯的按顺序赋值
*结构体赋值
DATA: BEGIN OF gs_ren1,
name(20) VALUE 'Kim Sung Joon',
country(10) VALUE 'China',
city(20) VALUE 'Beijing',
END OF gs_ren1.
DATA: BEGIN OF gs_info,
name(20),
city(20),
phone(10) VALUE '1234567890',
END OF gs_info.
MOVE-CORRESPONDING gs_ren1 TO gs_info.
WRITE:/ gs_info-name,gs_info-city,gs_info-phone.
*write 语句有两种用法
1:输入报表
2:变量赋值 加TO
将a的数据类型转换成C后进行赋值给b。
前提是a是可以转换成C类型的。
2.4.2:用offset 进行赋值
DATA: a(8) VALUE 'ABCDEFGH',
b(8),
m TYPE i VALUE 2,
n TYPE i VALUE 3.
MOVE a+2(3) TO b. "CDE"
MOVE a+m(n) to b. "CDE"
MOVE a+m(n) to b+p(q). "前后两个都可以偏移"
*b值为CDE 意思是从a开头往后2个开始,也就是第三个字符开始C,起始点,然后偏移3个字符,C\D\E。
*CLEAR 清除变量内容 回归默认值
2.4.3:结构体之间的计算操作
ADD-CORRESPONDING
SUBTRACT-CORRESPONDING
MULTIPLY-CORRESPONDING
DIVIDE-CORRESPONDING
DATA: BEGIN OF gs rate,"比重
peng TYPE f VALUE '0.8'
Zhou TYPE fVALUE'1.0',
END OF gs rate.
DATA: BEGIN OF gs result,
Peng TYPE i VALUE 95.
Zhou TYPEi VALUE 70.
END OF gs result.
MULTIPLY-CORRESPONDING gs_result BY gs_rate.
WRITE:'Test Result',Peng:',gs_result-Peng,'Zhou:',gs_result-Zhou.
2.5:其他变量
程序中经常使用的值可以定义为常量。
定义常量后在程序内不可以进行修改。
*常量
CONSTANTS: c_company(10) VALUE 'LG CNS'.
CONSTANTS: BEGIN OF c_people,
name(20) VALUE'Zhou Wen Woo',
country(10) VALUE 'China',
END OF c_people.
WRITE:c_company,c_people-name,c_people-country.
*静态变量
DO 3 TIMES."指定子程序循环3次
PERFORM call_subr.
ENDDO.
DO 3 TIMES."指定子程序循环3次
PERFORM call_subr2.
ENDDO.
FORM call_subr."子程序块 要写在报表后面
STATICS lv_val TYPE i.
lv_val = lv_val + 1.
WRITE :/'STATIC Variable:',lv_val.
ENDFORM.
*不用静态变量
FORM call_subr2."子程序块
DATA lv_val TYPE i.
lv_val = lv_val + 1.
WRITE :/'NOT STATIC Variable:',lv_val.
ENDFORM.
*TABLE
TABLES:scarr.
SELECT FROM scarr.
WRITE:scarr-carrid,scarr-carrname.
ENDSELECT.
3:SQL
- DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等;
- DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(数据);
- DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别;
- DQL(Data Query Language):数据查询语言,用来查询记录(数据)
3.1:sql种类
- OPEN SQL:
- ABAP 语言使用 只能使用DML语言 (以及select)
- 比native sql使用简单
- 可以使用本地缓冲器
- NATIVE SQL:数据库接口操作数据库
- 可以直接连接数据库使用DML DDL 语言
- 还可以使用OPEN SQL 的语句 (select update delete)
3.2:sql与本地缓冲器
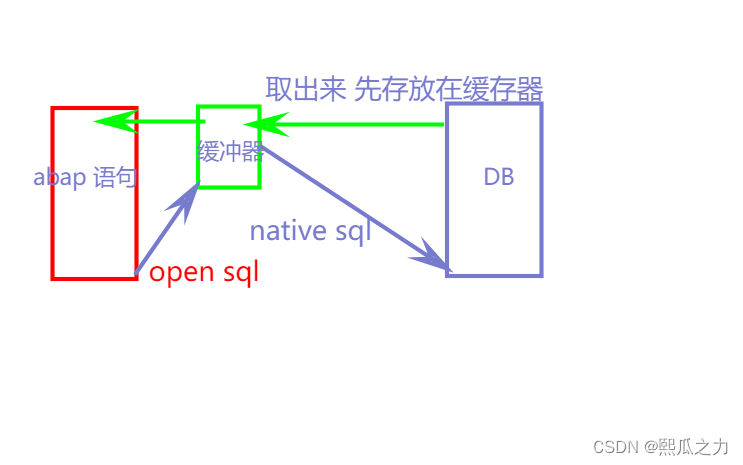
3.3:OPEN SQL
| 关键字 | 功能 |
|---|---|
| SELECT | 从数据库表中读取数据 |
| INSERT | 往数据库表中追加数据 |
| UPDATE | 修改数据库表的数据 |
| MODIFY | 执行的是INSERT + UPDATE功能。存在此条数据 用update;不存在 就是用insert |
| DELETE | 删除数据库表数据 |
所有的OPEN SQL 成功后:
- 会修改系统变量 SY-SUBRC 为 0;
- SY-DBCNT 为返回的数据个数;
读取数据命令
| 语句 | 功能 |
|---|---|
| SELECT | |
| INTO | 指定查询结果数据存储的变量,并在程序中应用 |
| FORM | 查询表名 |
| WHERE | 条件查询 |
| GROUP BY | 分组查询 |
| HAVING | 限制GROUP BY条件 |
| ORDER BY | 用于排序 |
3.3.1:SELECT:
-
select single :只从数据库内取一条数据,多条中的任意一条 select single :只从数据库内取一条数据,多条中的任意一条 select *:所有字段全查出来 select :结果有多条时,结果会保存到内表 select distinct :用于删除重复值,查出结果全是去重了的 *1---select使用into的结果如果不是内表,而是结构体(工作区)或者字段时候,就需要endselect SELECT * INTO gs_wa FROM sflight WHERE carrid EQ 'AA'. ENDSELECT. *1---要使用 endselect结束,相当于是在loop循环中执行select使,每取出一条数据,就把他追加到结构体中。 select cols as othername "给字段指定别名"
3.3.2:into
-
查一条数据时用结构体,工作区接数据
SELECT ... INTO [CROSSPONDING FIELDS OF] wa.当查询多个关键字的时候,使用crossponding fields of来进行自动匹配同名字段
-
查多条数据时用内表
select ... into|appending [crossponding fields of] TABLE itab [package size n]- appending:直接在原有内表上追加数据
- into:先清空内表数据,然后插入数据
- package size of:设置一次追加到内表的条数,查询条数大于n,就一次只追加n条。
- 一次是指一次select,但并非表示查到n个就不查了,会在endselect区间内一直查下去,每一个endselect区间内都是一次循环查询,一次查n个出来清空内表后放进内表(如果用into)。
- 此时要用endselect来结束语句。
-
查个别字段用变量:
-
查询数据库内个别数据库字段
-
into后面列出两个以上目标地时需要用括号分别指定变量名,如果空白,会报错
SELECT ... INTO (f1,f2)...在select 语句里面查询两个字段的语句如下所示
SELECT carrid connid INTO (gv_carrid,gv_connid) FROM SFLIGHT
-
3.3.3:FROM
用于指定数据库表或视图。
可用AS添加别名,动态指定数据库表名
两个作用:
- 定义表的选项
- 控制访问数据库表的选项
- select … FROM TABLE option.

表类型:
-
静态的表(固定表),可以使用AS设置别名,别名设置后,该语句内不能再用本来的名字。
-
动态表(用个变量存放表的名字),此时该变量内存放的表名字必须是大写字母,并且要在数据字典中存在。
DATA tname type c. tname = 'MYTABLE'."MYTABLE 要大写,并且要在数据字典中存在该表"
3.3.4:JOIN
在关系型数据库内同时取得多个数据库表值时,用JOIN来连接。
TYPES: BEGIN OF t_str,
carrid TYPE sflight-carrid,
carrname TYPE scarr-carrname,
END OF t_str.
DATA: gs str TYPE t_str.
SELECT SINGLE a~carrid b~carrname INTO CORRESPONDING FIELDS OF gs_str FROM sflight AS a INNER JOIN scarr AS b ON a~carrid EQ b carrid WHERE a~carrid ='AA'.
WRITE:gs str-carrid,gs_str-carrname.
内连接查询
两张表交集的部分
隐式内连接:
SELECT 字段列表 FROM 表1, 表2 WHERE 条件 ...;
显式内连接:
SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 连接条件 ...;
显式性能比隐式高
外连接查询
左外连接:
查询左表所有数据,以及两张表交集部分数据
SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 ...;
相当于查询表1的所有数据,包含表1和表2交集部分
ABAP OPEN SQL中只能用左外连接。
3.3.5:限制查询个数
select ... FROM
4:内表
类似于C语言的动态数组。
INITIAL SIZE 后没有直接占用内存,而是预约了内存空间。
4.1:表
DATA 表名 TYPE 表类型.
INITIAL SIZE 件数.
TYPES: BEGIN OF s_type,
no(6) TYPE c,
name(10) TYPE c,
part(16) TYPE c,
END OF s_type.
TYPES t_type TYPE STANDARD TABLE OF s_type INITIAL SIZE 100.
DATA struct1 TYPE t_type.
struct1-name = 'wyx'."此时只是在为结构体赋值
APPEND struct1."append命令是追加的意思,在向内表插入值。
struct1-name = 'zcy'.
APPEND struct1.
4.1.1:内表的定义
主要有三种
-
参照结构体类型
-
参照已经有的结构体变量
-
只能用like table of 不能用type
-
like line of与like table of和like
-
like line of: 生成的是结构体
LIKE LINE OF后面只能接一个内表,表示一个DATA参数具有和内表一样的结构(structure),例如有一个TABLES:Z_USER,Z_USER有两个字段,一个ID,一个NAME,那么
DATA:WA LIKE LINE OF Z_USER 表示WA和Z_USER的STRUCTURE一样,可以吧WA当做Z_USER的WORK AREA来用。
-
like table of: 生成的是内表
LIKE TABLE OF 后面接一个STRUCTURE,表示一个DATA参数是一个内表,这个内表的结构和后面接的那个结构一样,例:
DATA:BEGIN OF WA, ID TYPE I, NAME(10) TYPE C, END OF WA. DATA: ITAB LIKE TABLE OF WA.这里的ITAB直接就是一个内表了,WA是它的WORK AREA。
-
like:
可以跟内表,可以跟结构体,复制出来的就是后面的东西
-
-
-
参照数据库表
*内表定义 赋值 输出
TYPES: BEGIN OF s_type,
no(6) TYPE c ,
name(10) TYPE c,
part(16) TYPE c,
END OF s_type.
DATA struct TYPE STANDARD TABLE OF s_type WITH NON-UNIQUE KEY NO WITH HEADER LINE.
struct-no = '001'.
struct-name = 'wyx'."此时只是在为结构体赋值
APPEND struct."append命令是追加的意思,在向内表插入值。
struct-no = '002'.
struct-name = 'yx'."此时只是在为结构体赋值
APPEND struct."append命令是追加的意思,在向内表插入值。
LOOP AT struct.
WRITE :/ struct-no,struct-name.
ENDLOOP.
*内表定义 DATA LIKE table DATA
DATA: BEGIN OF s_data,
no(6) TYPE c ,
name(10) TYPE c,
part(16) TYPE c,
END OF s_data.
DATA struct_2 LIKE STANDARD TABLE OF s_data WITH NON-UNIQUE KEY no WITH HEADER LINE.
*参照全局表定义内表
DATA struct_3 LIKE SORTED TABLE OF scarr WITH UNIQUE KEY carrid."按全局表来定义struct3
DATA struct_4 LIKE LINE OF struct_3."按struct3的类型来定义内表
SELECT * INTO TABLE struct_3 FROM scarr.
LOOP AT struct_3 INTO struct_4.
WRITE :/ struct_4-carrid,struct_4-carrname.
ENDLOOP.
*LOOP AT struct_3. 没有表头 必须用工作区才能够进行操作
* WRITE :/ struct_3-carrid,struct_3-carrname.
*ENDLOOP.
4.1.2:表头的操作
*表头 带表头的内表操作 实际上是表头工作区和表名相同 故省略了工作区
TYPES: BEGIN OF t_str,
col1 TYPE i,
col2 TYPE i,
END OF t_str.
DATA gt_itab TYPE TABLE OF t_str WITH HEADER LINE.
DO 3 TIMES.
gt_itab-col1 = sy-index."DO循环的次数 sy-index
gt_itab-col2 = sy-index ** 2."2次方
APPEND gt_itab.
ENDDO.
LOOP AT gt_itab.
WRITE:/ gt_itab-col1,gt_itab-col2.
ENDLOOP.
一般建议使用以下书写方式 就算有表头的内表 在操作时也写出与内表同名的工作区
DATA gt_itab TYPE TABLE OF t_str WITH HEADER LINE.
DO 3 TIMES.
gt_itab-col1 = sy-index."DO循环的次数 sy-index
gt_itab-col2 = sy-index ** 2."2次方
APPEND gt_itab To gt_itab.
ENDDO.
LOOP AT gt_itab into gt_itab.
WRITE:/ gt_itab-col1,gt_itab-col2.
ENDLOOP.
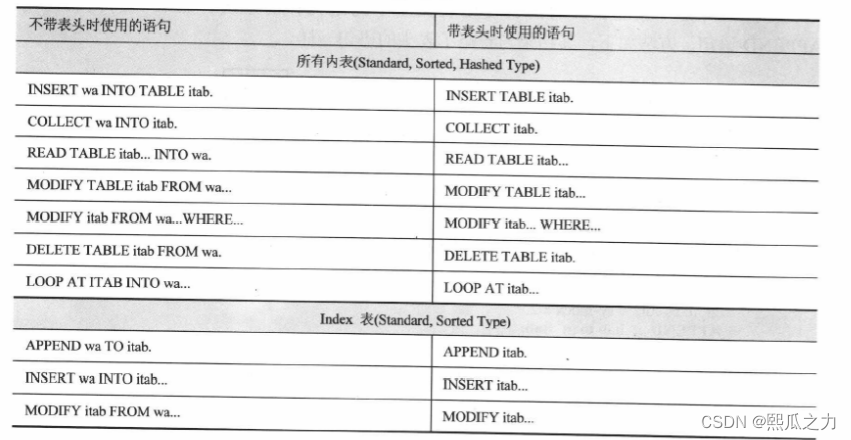
4.2:内表的类型
ABAP内边包含三种类型:标准表、排序表、散列表。
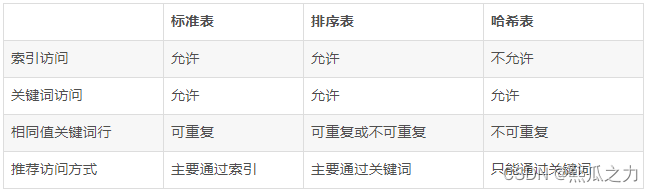
标准表:用key查询(On)
标准表是一种索引表(Index Table),可以不指定Key(即没有主键)。或者指定不唯一的主键(NON-UNIQUE KEY),但不能指定唯一的主键(UNIQUE KEY)。
可以使用(INDEX)和主键(KEY)或者字段来查询标注表,但最常用的就是索引访问。
标准表的特点就是填充表的速度快。若需要经常使用索引访问表,就选择标准表,标注表也是最常用的内部表。
排序表:用key查询(Ologn)
排序表也是一种索引表,其与标准表的区别是排序表是按主键自动进行排序的,而标准表只能采用SORT来进行排序。
必须指定KEY作为排序参考字段,主键(KEY)可以是唯一的或者是不唯一的。
排序表可以使用INDEX或者KEY来查询。
排序表已经按照KEY来排序,因此可以不用在排序,如果需要经常使用键来访问数据,或者希望数据能够自动排序,就用排序表。
排序表可以采用二分查找(BINARY SEARCH)方法。
散列表:用key查询(O1)
与标准表和排序表不同,散列表不是一种索引表,散列表内部的标识记录的散列值是根据散列算法计算的出来的,散列表可以提供快速的插入和查找操作。
散列表必须指定KEY,并且是UNIQUE KEY,不可使用索引(INDEX)来查询,只能使用主键(KEY)查询。
查询散列表耗费的事件与表的记录数量无关,如果记录量非常大并且需要主键访问,就可以考虑使用散列表。
4.2.1:标准表 索引表
data a type standard table of b
TYPE STANDARD TABLE OF
WITH DEFAULT KEY "即使不写这句 也默认存在 ,并且会将内表中以char类型定义的前几个字段定义成g"
-
标准表关键字并非唯一的 ,可以有很多个;
- 特别是设置了with default key 后,会把全部的c类型的字段全部设置为关键字
- 如果没有设置任何的key,默认也是with default key 这个效果
-
标准表只能设置key是 with non-unique key,也就是允许关键字非主键,可以有同列重复的字段在其中
-
可以通过索引访问
read table gt_itab index 2.
标准表定义与使用
*标准表
TYPES: BEGIN OF t_line,
field1 TYPE c LENGTH 5,
field2 TYPE c LENGTH 4,
field3 TYPE i,
END OF t_line.
TYPES t_standard TYPE STANDARD TABLE OF t_line.
DATA gt_itab2 TYPE t_standard WITH HEADER LINE.
gt_itab2-field1 = 'En'.
gt_itab2-field2 = 'ABAP'.
gt_itab2-field3 = 2.
APPEND gt_itab2.
gt_itab2-field1 = 'Enjoy'.
gt_itab2-field2 = 'ABAP'.
gt_itab2-field3 = 1.
APPEND gt_itab2.
4.2.2:排序表 索引表
*排序表
TYPES: BEGIN OF t_line2,
seq TYPE c,"如果是default key 那么会根据第一个c类型来当主键
col TYPE c,
END OF t_line2.
TYPES t_tab TYPE SORTED TABLE OF t_line2 WITH UNIQUE/NON-UNIQUE DEFAULT KEY/ KEY col."必须指定是唯一的还是非唯一的,如果是非唯一的,就算key的字段有重复也可以进行insert插入.
DATA gt_itab3 TYPE t_tab WITH HEADER LINE.
gt_itab3-col = 'B'.
gt_itab3-seq = '1'.
INSERT TABLE gt_itab3.
gt_itab3-col = 'A'.
gt_itab3-seq = '2'.
INSERT TABLE gt_itab3.
gt_itab3-col = 'C'.
gt_itab3-seq = '1'.
INSERT TABLE gt_itab3.
CLEAR gt_itab3.
READ TABLE gt_itab3 INDEX 2.
WRITE:/ gt_itab3-col,gt_itab3-seq.
- 排序表UNIQUE的时候,插入相同的插不进去,但不会报错
- 用NON-UNIQUE的时候可以插进去
- 排序表用append 进行追加的时候,如果追加顺序是相悖的就会造成排序问题从而报错
4.2.3:哈希表
*哈希表
**L.STRUCTURE Type定义
TYPES:BEGIN OF t_line3,
col TYPE c,
seq TYPE i,
END OF t_line3.
**2.定义标准表类型
TYPES t_tab3 TYPE HASHED TABLE OF t_line3 WITH UNIQUE KEY col.
**3.定义内表
DATA gt_itab4 TYPE t_tab3 WITH HEADER LINE.
gt_itab4-col ='B'.
gt_itab4-seq ='1'.
INSERT TABLE gt_itab4.
gt_itab4-col ='A'.
gt_itab4-seq ='2'.
INSERT TABLE gt_itab4.
CLEAR gt_itab4.
READ TABLE gt_itab4 WITH TABLE KEY col ='A'.
WRITE:/ gt_itab4-col,gt_itab4-seq.
- 哈希内表不存在索引,不能用read table a index 1访问。
- 只能用read table a with table key col 或者 read table a with key col的方式访问
4.2.4:READ 命令
*read.
READ TABLE gt_itab2 WITH KEY field3 = 2.
WRITE :/ gt_itab2-field1,gt_itab2-field2,gt_itab2-field3.
READ TABLE gt_itab2 INDEX 1.
WRITE :/ gt_itab2-field1,gt_itab2-field2,gt_itab2-field3.
READ TABLE gt_itab2 INDEX 2.
WRITE :/ gt_itab2-field1,gt_itab2-field2,gt_itab2-field3.
4.2.4.1:工作区
同名工作区会保存最近的一次改变的内容在其中
4.2.5:with table key 和with key
-
with table key 时候,要指定所有定义的关键字
READ TABLE gt_itab2 with table key a = '1' b = '2' c = '3'. -
with key时候,只用指定一个关键字
READ TABLE gt_itab2 with key a = '1'.
4.2.6:内表的旧式定义
旧方式定义的表只能是标准表,不能使用排序表或者哈希表
TYPES a TYPE/LIKE b OCCURS n. "n=0时,代表内存大小没有限制,其他数字没有意义。
等于
TYPES|DATA <itab> TYPE|LIKE STANDARD TABLE OF <linetype> WITH NON-UNIQUE DEFALUT KEY INITIAL KEY INITIAL SIZE <n> [WITH HEADER LINE].
TYPES: BEGIN OF t_line,
col TYPE c,
seq TYPE i,
END OF t_line.
DATA gt_itab TYPE t_line OCCURS 0 WITH HEADER LINE.
gt_itab-col = 'A'.
gt_itab-seq = '1'.
INSERT table gt_itab.
CLEAR gt_itab.
READ TABLE gt_itab INDEX 1.
WRITE:/ gt_itab-col,gt_itab-seq.
4.3:比较内表的速度
插入:用标准表快 append
查找:用排序表、哈希表快 read 哈希最快
排序表默认是已经排序,并且默认read是用二分查找法查找,不能添加BINARY SEARCH命令。
标准表要想用二分查找,需要先用SORT排序,然后用BINARY SEARCH进行二分查找。
SORT itab BY col1 col2 col3.
READ TABLE itab WITH KEY col1 = 500 col2 = 200 col3 = 300 BINARY SEARCH.
4.4:内表命令
4.4.1:内表赋值
内表采用MOVE进行赋值。
MOVE itab1 TO itab2.
"如果带表头的用该方法赋值时,只复制了itab1的表头中的数据给itab2
"和itab2 = itab1一样
MOVE itab1[] TO itab2[].
"会复制表体数据给itab2
"和itab2 = itab1一样
类型不同的时候,用下面这个,不管两个表的字段顺序咋样,只有有相同名字的字段就可以赋值
MOVE-CORRESPONDING itab1 TO itab2. "也是对结构体赋值的命令
- itab1[]:代表表体
- itab1:有表头时代表表头工作区;没有表头时代表整个内表
没有表头的内表,需要定义一个结构体作为工作区,使用 like line of 就可以定义出一个与内表结构一样的结构体
4.4.2:内表初始化
内表初始化:清空内容,保留结构
- CLEAR:
- clear itab:有表头时候,只初始化表头;没有表头,初始化全部
- clear itab[]:可以清空表体,不清空表头
- clear a:a是基本类型变量,可以清空内容,重置为默认值
- REFRESH:仅仅清楚内标,专门清除内表的,不能清除基本变量
- FREE:free itab 会直接释放itab所占据的内存空间
4.4.3:内表排序
SORT:
默认是用 ASCENDING 升序排列。
不能用于排序表,会发生错误。
只能用于标准表和哈希表。
sort itab ASCENDING|DESCENDING
1:对没有指定关键字的标准表使用sort
将组合字符串类型的字段作为关键字进行排序,默认的排序方法为ASCENDING。
2:指定排序字段:
SORT itab [ASCENDING|DESCENDING] BY f1 [ASCENDING|DESCENDING] f2[ASCENDING|DESCENDING]
f1字段如果存在null值,会字段排除此列
3:stable sort
- 排序算法是有稳定性存在的:稳定就是指相同数据排序时原始在前面的排序后仍然在前面。
- 而sort是不稳定排序的,会造成排序的相对次序改变,在实际业务中会造成取值异常的问题。
- 如果用stable sort就可以解决,会达到稳定的排序的目标,但是耗时会比sort更长。
4.4.4:内表属性
DESCRIBE TABLE itab [LINES gv_line][OCCURS gv_init][KIND gv_kind].
DESCRIBE语句确认内表属性
LINES:表示内表包含的数据件数,最常用。
OCCURS:返回内表的初始大小
KIND:返回内表的类型 【T标准表|S排序表|H哈希表】
4.4.5:追加内表数据
INSERT:
-
利用关键字追加一条数据
insert line into table itab执行成功后会让系统变量 SY-SUBRC返回0。
如果内表存在唯一键,当执行insert时,若表中已经有了相同关键字的数据,系统变量SY-SUBRC会返回4,但是不报错
-
利用关键字追加多条数据
利用insert语句追加多条数据,但是itab1与itab2表类型要相同
insert lines of itab1 [from n1][TO n2] into table itab2 "从itab1的n1行到n2行的数据全插入 -
利用索引追加一/多条数据
insert line into table itab2 [index i]. insert lines OF itab1 INTO itab2 into [index i]. -
不同类型内表 insert效果不一样
- 标准表:
- 追加到内表最后一行
- 与append语句有相同的效果
- 排序表
- 按照内表排序号的顺序追加数据
- 插入行不可以打乱按照关键字排序的顺序,否则插入不成功
- 如果是NON-UNIQUE KEY 类型的,那么相同关键字的数据会插入已经有的上一行
- 哈希表
- 插入过程中系统按照关键字的哈希索引顺序进行追加,有可能插入到已有数据前
- 标准表:
APPEND:
-
只能用索引 哈希表不支持append
-
追加一条数据
append line TO itab. *追加成功后,系统变量SY-TABIX中保存追加数据的内表行,即索引编号。 -
追加多条数据
APPEND LINES OF itab1 [FROM n1] [TO n2] TO itab2. -
对于排序表,也必须按原定顺序插入,否则会发生错误
-
APPEND INITIAL LINE
APPEND INITIAL LINE TO itab."创建一个空内表" -
APPEND SORTED BY 自动以字段F为基准降序排序descending 后追加数据,仅仅适合标准表,另外还需要在创建内表变量的时候INITIAL SIZE 指定大小。
由于会对表内数据进行排序,所以可能会因为initial size 的大小使得插入时截掉原有数据
APPEND wa TO itab SORTED BY f
COLLECT:
collect在非数值字段相同的情况下,起到了数值字段汇总作用。
- 非数值字段不同的情况下,效果和append相同执行插入内表操作
- 当非数值字段相同的时候,则相当于modify的效果,只不过是将数值字段进行汇总相加后更新。汇总非数值字段,把相同非数值字段的数值加起来。
- 操作时,内表除了关键字以外的必须是数字类型才可以正常操作。
COLLECT wa INTO itab.
TYPES:BEGIN OF TY_TEST,
ID(3) TYPE C,
MENGE TYPE I,
END OF TY_TEST.
DATA:I_TEST TYPE TABLE OF TY_TEST,
W_TEST TYPE TY_TEST.
DATA:I_TEST2 TYPE TABLE OF TY_TEST.
W_TEST-ID = '001'.
W_TEST-MENGE = 10.
APPEND W_TEST TO I_TEST.
W_TEST-ID = '001'.
W_TEST-MENGE = 70.
APPEND W_TEST TO I_TEST.
W_TEST-ID = '002'.
W_TEST-MENGE = 20.
APPEND W_TEST TO I_TEST.
W_TEST-ID = '002'.
W_TEST-MENGE = 50.
APPEND W_TEST TO I_TEST.
W_TEST-ID = '002'.
W_TEST-MENGE = 80.
APPEND W_TEST TO I_TEST.
W_TEST-ID = '003'.
W_TEST-MENGE = 30.
APPEND W_TEST TO I_TEST.
W_TEST-ID = '003'.
W_TEST-MENGE = 90.
APPEND W_TEST TO I_TEST.
LOOP AT I_TEST INTO W_TEST.
COLLECT W_TEST INTO I_TEST2."关键一步。。。"
CLEAR:W_TEST.
ENDLOOP.
WRITE:/ 'Collect前的内容:' .
WRITE:/1(12) '编号' , '数量'.
LOOP AT I_TEST INTO W_TEST.
WRITE:/ W_TEST-ID, ' ',W_TEST-MENGE.
CLEAR:W_TEST.
ENDLOOP.
WRITE:/ .
WRITE:/ 'Collect后的结果:' .
WRITE:/1(12) '编号' , '数量'.
LOOP AT I_TEST2 INTO W_TEST.
WRITE:/ W_TEST-ID , ' ',W_TEST-MENGE.
CLEAR:W_TEST.
ENDLOOP.
4.4.6:修改内表数据
MODIFY语句可以修改内表内的一条数据。
LOOP AT i_list.
IF i_list-werks = '1000'.
i_list-matnr = '4001'.
ENDIF.
MODIFY i_list.
CLEAR i_list.
ENDLOOP.
MODIFY itab2 FROM ls_itab1 INDEX 3 TRANSPORTING field2 WHERE field1 = 'a'.
"不循环的方式,操作工作区"
"INDEX 3 只修改表itab2的第3行"
"只修改field2的值,不修改field1"
"当field1=a时才执行操作"
*transporting 修改指定字段。
SELECT carrid connid INTO CORRESPONDING FIELDS OF TABLE gt_itab FROM sflight.
*CORRESPONDING FIELDS OF 匹配select 后面字段与into table后面的字段,名字不对应就没有值
*from 是指定从哪张数据库表中取数据
4.4.7:AT NEW & AT END OF & AT FIRST & AT LAST
- AT NEW t:t以及t左边的列为一组,一旦与上一条比值发生改变发生改变,那么执行随后的语句。
- AT END OF t:t以及t左边的列为一组,一旦与下一条比值发生改变,那么执行随后的语句。
at new col2.
语句."以col1 和col2 两列为一组 如果与上一条数据比有变化,那么就执行"
endat.
- AT FIRST.:一是内表第一条数据时执行。
- AT LAST.:是内表的最后一条数据时执行。
4.4.8:删除内表数据
-
利用表关键字删除一条数据
在关键字不唯一的标准表中使用with table key
delete table itab [from wa] with key k1=f1. delete table itab with table key k1=f1.... -
利用where条件删除多条数据
delete itab where cond. -
利用索引删除内表数据
delete itab [index idx]. delete itab from n1 to n2. delete itab form n1. "从n1开始到结束" delete itab to n2."从开始到n2" -
利用ADJACENT DUPLICATE
需要先用sort 语句排序内表,才能有删除重复行的效果。
delete adjacent duplicate entries from itab[comparing f1 f2....]."不使用comparing的话,默认是删除关键字重复的数据"
4.4.9:读取内表数据
-
利用关键字读取数据
READ TABLE <EMPTAB>. READ TABLE <EMPTAB> WITH KEY <k1> = <v1>… <kn> = <vn>. READ TABLE <EMPTAB> WITH TABLE KEY <k1> = <v1> … <kn> =<vn>. READ TABLE <EMPTAB> WITH KEY = <value>. READ TABLE <EMPTAB> WITH KEY . . . BINARY SEARCH. READ TABLE <EMPTAB> INDEX <i>. READ TABLE <EMPTAB> COMPARING <f1> <f2> . . . . READ TABLE <EMPTAB> COMPARING ALL FIELDS. READ TABLE <EMPTAB> TRANSPORTING <f1> <f2> . . . . READ TABLE <EMPTAB> TRANSPORTING NO FIELDS.KEY|TABLE KEY: 通过内表的主键字段查找 BINARY SEARCH: 二分法查找,使用该方法时,在READ TABLE之前,必须对内表排序 INDEX: 根据内表索引查找 设置查找: COMPARING:只查找设置的字段 COMPARING ALL FIELDS:查找内表所有的字段 设置输出: TRANSPORTING: 只输出设置的字段数据 TRANSPORTING NO FIELDS: 不输出任何数据 -
利用索引读取数据
READ TABLE itab INDEX idx INTO result. *成功SY-SUBRC 返回0 失败返回4 *同时成功后 SY-TABIX保存内表的index序号
5:模块化程序
5.1:Form
子例程 FORM
使用 PERFORM frm_formname 调用
5.2:Function
函数事物代码: SE37
FUNCTION:
是具有全局可见性的特殊程序。
只能在fuction group中定义并使用。
FUNCTION GROUP:
包含一个以上的函数,是对某一类对象的操作。
专门用作function的主程序。
函数组 T-CODE: SE37
使用 CALL FUNCTION 'FUNCTION_NAME'来调用
5.3:USING 和 CHANGING
orm、Function中的TABLES参数,TYPE与LIKE后面只能接标准内表类型或标准内表对象,如果要使用排序内表或者哈希内表,则只能使用USING(Form)与CHANGING方式来代替。当把一个带表头的实参通过TABLES参数传递时,表头也会传递过去,如果实参不带表头或者只传递了表体(使用了[]时),系统会自动为内表参数变量创建一个局部空的表头
不管是以TABLES还是以USING(Form)非值、CHANGE非值方式传递时,都是以**引用方式(即别名,不是指地址,注意与Java中的传引用区别:Java实为传值,但传递的值为地址的值,而ABAP中传递的是否为地址,则要看实参是否是通过Type ref to定义的)**传递;
三种方式
1.引用传递(CALL BY REFERENCE)
传递参数时将参数的地址(ADDRESS)传至子程序中,也就是子程序中的参数变量与外部程序的参数变量共享地址内的值。又叫CALL BY ADDRESS,若子程序中的参数变量的值发生了改变,那么,外部程序的实际变量的值也发生改变。
FORM CALCULATOR USING NUM1 NUM2 CHANGING NUM3.在这里插入代码片
PERFORM CALCULATOR USING i_num1 i_num2 CHANGING i_num3.`在这里插入代码片`
此时PERFORM 后 在from内部修改NUM值会修改外部值 无论是USING 还是CHANGING的参数
2.值传递(CALL BY VALUE)
FORM <subform> [USING VALUE(f1) VALUE(f2)...]...在这里插入代码片
PERFORM <subform> [USING VALUE(f1) VALUE(f2)...]...
用USING VALUE(NUM)的方法可以只单向传值
3.值传递参数并返回最终值(CALL BY VALUE AND RETURN RESULT)
FORM <subform> [.....] [CHANGING VALUE(f1)...]
PERFORM <subform> [.....] [CHANGING VALUE(f1)...]
用CHANGING VALUE(NUM)的方法传递的虽然是值 但是在子程序结束的时候会返回值给外部变量 不同于地址传递的实时同步数据
5.3:USING 和 CHANGING
orm、Function中的TABLES参数,TYPE与LIKE后面只能接标准内表类型或标准内表对象,如果要使用排序内表或者哈希内表,则只能使用USING(Form)与CHANGING方式来代替。当把一个带表头的实参通过TABLES参数传递时,表头也会传递过去,如果实参不带表头或者只传递了表体(使用了[]时),系统会自动为内表参数变量创建一个局部空的表头
不管是以TABLES还是以USING(Form)非值、CHANGE非值方式传递时,都是以**引用方式(即别名,不是指地址,注意与Java中的传引用区别:Java实为传值,但传递的值为地址的值,而ABAP中传递的是否为地址,则要看实参是否是通过Type ref to定义的)**传递;
三种方式
1.引用传递(CALL BY REFERENCE)
传递参数时将参数的地址(ADDRESS)传至子程序中,也就是子程序中的参数变量与外部程序的参数变量共享地址内的值。又叫CALL BY ADDRESS,若子程序中的参数变量的值发生了改变,那么,外部程序的实际变量的值也发生改变。
FORM CALCULATOR USING NUM1 NUM2 CHANGING NUM3.
PERFORM CALCULATOR USING i_num1 i_num2 CHANGING i_num3.
此时PERFORM 后 在from内部修改NUM值会修改外部值 无论是USING 还是CHANGING的参数
2.值传递(CALL BY VALUE)
FORM <subform> [USING VALUE(f1) VALUE(f2)...]...
PERFORM <subform> [USING VALUE(f1) VALUE(f2)...]...
用USING VALUE(NUM)的方法可以只单向传值
3.值传递参数并返回最终值(CALL BY VALUE AND RETURN RESULT)
FORM <subform> [.....] [CHANGING VALUE(f1)...]
PERFORM <subform> [.....] [CHANGING VALUE(f1)...]
用CHANGING VALUE(NUM)的方法传递的虽然是值 但是在子程序结束的时候会返回值给外部变量 不同于地址传递的实时同步数据
6:字段符号FIELD-SYMBOLS
字段符号FIELD-SYMBOLS 可以看作仅是已经被解引用的指针 是变量的别名 并非真正的指针
在ABAP中引用变量(通过TYPE REF TO定义的变量)才好比C语言中的指针
ASSIGN … TO :将某个内存区域分配给字段符号,这样字段符号就代表了该内存区域,即该内存区域别名
FIELD-SYMBOLS: <FS> [<TYPE>]
当不输入时,继承赋给它的变量的所有属性
当输入时,赋给它的变量必须与同类型
FIELD-SYMBOLS:<F1>.
DATA: DAT(8) VALUE '19920108'.
ASSIGN DAT TO <F1>.
WRITE:/ <F1>.
"<f1> 继承dat属性,为C类型,值为19920108 。"
FIELD-SYMBOLS:<F2> TYPE D.
DATA:DAT(5) TYPE C VALUE '12345'.
ASSIGN DAT TO <F2>. "会直接报错 类型不兼容"
WRITE:/ <F2>.
FIELD-SYMBOLS:<F3> TYPE D.
DATA:DAT(8) VALUE '19920108'.
ASSIGN DAT TO <F3> TYPE 'D'. "会把DAT 先转换成D类型 再分配给<F3>"
WRITE:/ <F3>.
6.1:ASSIGN
6.1.1:隐式转换
Catsing分为隐式型变化和显示型变化两种
ASSSIGN <var> TO <fs> CASTING.
TYPES: BEGIN OF t_line,
col1 TYPE char5,
col2 TYPE char10,
col3 TYPE char15,
END OF t_line.
DATA: gv_addr(30) TYPE c VALUE 'CHINA BEIJING TWIN BUILDING'.
FIELD-SYMBOLS: <fs> TYPE t_line.
ASSIGN gv_addr TO <fs> CASTING.
WRITE: <fs>-col1, <fs>-col2, <fs>-col3.
"运行结果 CHINA BEIJING TWIN BUILDING
在这个例子中,若不使用Casting,则会产生数据类型不一致的错误,因为是结构类型,gv_addr是字符类型。
6.1.2:显式转换
FIELD SYMBOLS 定义为Generic Type(不指定类型)
FIELD-SYMBOLS: <fs> TYPE ANY. "由于定义时未指定具体的类型"
ASSIGN gv_addr TO <fs> CASTING TYPE t_line.
WRITE: <fs>.
"运行结果 CHINA BEIJING TWIN BUILDING
6.1.3:ASSIGN动态分配
FIELD-SYMBOLS:<fs>.
DATA:str(20) TYPE c VALUE 'Output String',
name(20) TYPE c VALUE 'STR'. "str刚好已经定义过"
"静态分配:编译时就知道要分配的对象名
ASSIGN name TO <fs>."结果是<fs>与name变量等同
ASSIGN (name) TO <fs>."动态分配 先找到name的值 name的值如果刚好是已经定义过的变量 那么就将那个已经定义的变量分配给<fs>
FIELD-SYMBOLS:<fs>.
DATA:str(20) TYPE c VALUE 'Output String',
name(20) TYPE c VALUE 'ST',
ST(20) TYPE c VALUE 'Input String'.
"静态分配:编译时就知道要分配的对象名
ASSIGN name TO <fs>."结果是<fs>与name变量等同
WRITE:/ <fs>.
"通过变量名动态访问变量
DO 3 TIMES.
ASSIGN (name) TO <fs>."结果是是<fs>的值为ST变量值
WRITE:/ <fs>.
ENDDO.
6.2:UNASSIGN、CLEAR
UNASSIGN:该语句是初始化字段符号,执行后字段符号将不再引用内存区域, is assigned返回假
CLEAR:与UNASSIGN不同的是,只有一个作用就是初始化它所指向的内存区域,而不是解除分配
7:数据引用
TYPE REF TO data 数据引用data references
TYPE REF TO object 对象引用object references “object不能直接跟在TYPE后面,只能跟在TYPE REF TO后面
TYPE REF TO 后面可接的通用类型只能是data(数据引用)或者是object(对象引用)通用类型,其他通用类型不行
TYPES: BEGIN OF t_struct,
col1 TYPE i,
col2 TYPE i,
END OF t_struct. "定义一个结构体类型作为参考"
DATA: LS_STRUCT TYPE T_STRUCT. "定义一个结构体变量做参考"
DATA: dref TYPE REF TO DATA . "dref即为数据引用,即数据指针,指向某个变量或常量,存储变量地址 用DATA 作为参考就是暂时不指定类型
DATA: ref TYPE REF TO t_struct ."ref以结构体作为参考
FILED-SYMBOLS <FS> TYPE ANY. "参考任意类型"
FILED-SYMBOLS <FS> TYPE t_struct .
7.1.数据引用 Data References
-
Type Ref To 有两种初始化的方法: 必须初始化
1:第一种是用 CREATE DATA 动态开辟内存; (类似C语言定义指针会默认分配一个空间也可以用malloc分配一块空间给指针[指针值就是这块空间的首地址] abap指针必须要手动’malloc’ 一下内存空间)
如果定义 ref 是指定特定的类型或者结构的,那么 CREATE DATA 时 TYPE 可以省略。 无论定义时 ref 是否有特定的类型或者结构,CREATE DATA 时必须指定特定的类型或者结构,不能是data这种泛型的。
一般来说为了使用方便,还是应该指定 Field Symbol 或者 Type Ref To 的类型或者结构,以便之后直接使用。
CREATE DATA dref TYPE C. "dref由于没有定义类型 所以初始化时必须指定类型 此时的类型可以是随便什么的 没有限制 CREATE DATA ref . "ref在定义时就指定了类型 初始化时无需再次指定类型" 2:第二种是用 GET REFERENCE OF 指向已经存在的内存变量.
GETREFERENCE OF LS_STRUCT INTO ref. "效果相当于ref指向变量LS_STRUCT -
Field Symbol 的初始化,则只能指向已经存在的内存变量
FS是已经解引用的指针(类似C语言有指针p,FS就是*p,其本质已经是变量不是地址,而上述TYPE REF TO 得来的引用本质是地址)
ASSIGN LS_STRUCT TO <FS> "初始化FS 必须是已有的变量 而不是类型" -
两者区别
Type Ref To 和 Field Symbol 在用法上目前发现的主要区别:
1) Type Ref To 可以动态开辟内存,在动态内表时,可以等在程序运行时获得结构后再开辟内存,并且赋值给某个 Field Symbol。而光用 Field Symbol 是做不到的,因为 Field Symbol 的初始化需要“挂”在已知结构上。
2)Type Ref To 不像 Field Symbol 那样有LOOP AT it_tab ASSIGNING < fs >的写法,ref->不是指向内表数据,而是类似工作区指向某块内存,所以更改数据后需要 modify 到内表,如果不需要数据了要clear*。而 Field Symbol 则不需要考虑 modify 和 clear。
3)IF = 是比较内存里的值,相对应的是IF ref1-> = ref2->**,而不能判断比较 IF ref1 = ref2 。
-
使用数据引用 包含二级指针使用
DATA: ref1 TYPE REF TO t_struct . "定义指针 指定类型" DATA: ref2 LIKE REF TO ref1. "二级指针 CREATE DATA ref1 . "初始化 分配新的内存空间" CREATE DATA ref2 . ref1 "指针 类似指针p" ref2 "指针的指针 类似q 本质是&p" ref1->* "解引用 一级指针的使用 类似*p" ref2->* "解引用 二级指针的使用 类似*q 本质是p" ref2->*->* "解引用 二级指针的使用 类似**q 本质是*p"
如果定义时指定了特定的类型或者结构,那么 Field Symbol 和 Type Ref To 都可以直接使用
如果定义时没有指定类型或者结构,那么 Type Ref To 必须 ASSIGN 到另外一个 Field Symbol 里间接使用
TYPES: BEGIN OF t_struct,
col1(6) TYPE C,
END OF t_struct.
DATA: dref TYPE REF TO DATA ."dref即为数据引用,即数据指针,指向某个变量或常量,存储变量地址
DATA: ref TYPE REF TO t_struct . "定义一个p指针"
CREATE DATA dref TYPE C LENGTH 6. "使用前必须先指定类型"
FIELD-SYMBOLS <FS> TYPE any. "泛用型类型
ASSIGN dref->* TO <FS>.
<FS> = 'abc'.
CREATE DATA ref . "无需再次指定类型 初始化p指针内存空间"
ref->*-col1 = 'abcd'. "类似 *p-col1 = xx"
WRITE:/ <FS>,
ref->*.














 6784
6784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









