






一.简介SaDE 自适应差分进化算法
(self-adaptive Differential Evolution)
1.伪代码:
2.具体流程:
(1)Mutation(变异)
每次变异使用轮盘赌从候选策略池中选择策略,该策略池包含四种变异策略

(2) Crossover(交叉)
突变阶段结束后,对每一对目标向量Xi、G及其对应的突变向量Vi,G进行交叉操作生成一个试验向量Ui,G。在基本版本中,采用二项交叉的方法如下:

(3) Selection(选择)
在选择之前需要先对实验向量Ui,G进行评价,计算Fes值
在这里选择的肯定是更好的那个,具体是大于还是小于是根据评价函数要最大化还是最小化来的。

1. 在这里出现一个问题,SaDE算法是参数自适应的,即参数自动调整,可能很久才出现一次参数比较好,而且下一次会再变动,可能又不那么好了,非常浪费时间以及评价次数。也就是说,用这样的F和Cr来生成一个有希望的试验向量可能需要花费很多Fes,从而导致进化过程的效率较低。许多其他适应性DE变体也有同样的缺点。考虑到这一点,我们将引入一种新的基于ARM的参数自适应策略来加速F和Cr的调整过程。
2. 大多数自适应技术都是通过使用随机数生成器或根据以前成功的存档计算值自动生成新的F和Cr。这意味着,在以前的成功组合中隐藏的F和Cr的潜在有效关联很少被注意到。如果我们可以在迭代过程中挖掘和利用具有更好的适应度值的F和Cr偶,可以避免对F和Cr偶进行许多繁琐的试验,从而使搜索过程更加有效。接下来,我们将介绍ARM中广泛使用的Apriori算法。
二.DE算法中基于关联规则挖掘进行参数F、Cr的调节
在这里引用关联规则挖掘算法中最经典的Apriori算法
1.关联规则挖掘

项集:在关联分析中,包含0个或多个项的集合被称为项集(itemset)。如果一个项集包含k个项,则称它为k-项集。例如:{啤酒,尿布,牛奶,花生} 是一个4-项集。空集是指不包含任何项的项集。
关联规则(association rule):是形如 X → Y 的蕴含表达式,其中X和Y是不相交的项集,即:X∩Y=∅。关联规则的强度可以用它的支持度(support)和置信度(confidence)来度量。
支持度:一个项集或者规则在所有事物中出现的频率,确定规则可以用于给定数据集的频繁程度。σ(X):表示项集X的支持度计数
项集X的支持度:s(X)=σ(X)/N;规则X → Y的支持度:s(X → Y) = σ(X∪Y) / N
通俗解释:简单地说,X==>Y的支持度就是指物品集X和物品集Y同时出现的概率。
概率描述:物品集X对物品集Y的支持度support(X==>Y)=P(X n Y)
实例说明:某天共有1000 个顾客到商场购买物品,其中有150个顾客同时购买了圆珠笔和笔记本,那么上述的关联规则的支持度就是15%。
置信度:确定Y在包含X的事务中出现的频繁程度。c(X → Y) = σ(X∪Y)/σ(X)
通俗解释:简单地说,可信度就是指在出现了物品集X 的事务T 中,物品集Y 也同时出现的概率有多大。
概率描述:物品集X对物品集Y的置信度confidence(X==>Y)=P(X|Y)
实例说明:上该关联规则的可信度就回答了这样一个问题:如果一个顾客购买了圆珠笔,那么他也购买笔记本的可能性有多大呢?在上述例子中,购买圆珠笔的顾客中有65%的人购买了笔记本, 所以可信度是65%。
期望置信度(Expected confidence)
定义:设W 中有e %的事务支持物品集B,e %称为关联规则A→B 的期望可信度度。
通俗解释:期望可信度描述了在没有任何条件影响时,物品集B 在所有事务中出现的概率有多大。
实例说明:如果某天共有1000 个顾客到商场购买物品,其中有250 个顾客购买了圆珠笔,则上述的关联规则的期望可信度就是25 %。
概率描述:物品集A对物品集B的期望置信度为support(B)=P(B)
提升度(lift)
定义:提升度是可信度与期望可信度的比值
通俗解释:提升度反映了“物品集A的出现”对物品集B的出现概率发生了多大的变化。
实例说明:上述的关联规则的提升度=65%/25%=2.6
概率描述:物品集A对物品集B的期望置信度为lift(A==>B)=confidence(A==>B)/support(B)=p(B|A)/p(B)
支持度是一种重要的度量,因为支持度很低的规则可能只是偶然出现,低支持度的规则多半也是无意义的。因此,支持度通常用来删去那些无意义的规则;
置信度度量是通过规则进行推理具有可靠性。对于给定的规则X → Y,置信度越高,Y在包含X的事物中出现的可能性就越大。即Y在给定X下的条件概率P(Y|X)越大。
2.运用关联规则挖掘进行参数调整
在这里运用ARM中的Apriori算法可以找到F和Cr区间(最频繁项集),我们使用这种方法使F和Cr适应DE算法。
需要注意的是,Apriori算法的局限性很少。这种算法需要对数据库进行多次扫描,当数据库很大时,需要花费很长的时间来获取频繁的项目集。在本文中,我们将使用Apriori算法在成功记录的基础上寻找关联规则,这些记录在迭代过程中是小数据集。此外,我们只需要F和Cr关联规则,即频繁的2-itemset。因此,Apriori算法产生的额外CPU时间是可以接受的。Apriori算法的另一个缺点是推导出了很多琐碎的规则,很难提取出最有趣的规则。在本文中,我们将只选择生成的支持度最大的关联规则。

(1)前提:
为了使自适应DEs获得满意的性能,通常采用试错的方法来调整控制参数值。这种机制将消耗许多函数评估(Fes)。同时,在大多数最先进的自适应DE变量中,以前成功的参数值,可能包含潜在的有用的信息和知识,往往未得到充分利用。基于这些观察,我们将ARM合并到自适应DEs中,以生成显式的有希望的参数对,以加速进化。
(2)步骤:
步骤1:将每个成功的F和Cr记录到原始数据集Do中。 在这里如果这对F和Cr所产生的实验向量Ui,G被成功的选择了,就表示是成功的参数对。

步骤2: ==离散化。==在ARM之前,Do应该被预处理成二进制矩阵,命名为Db。F和Cr的不同组合可能会导致不同的搜索行为。例如,F = 1和Cr = 0.9主要是为了保持种群多样性,而F = 0.8和Cr = 0.2则是为了鼓励探索能力。
本文将这两个参数分为5个不同的区间((0,0.1),[0.1,0.4),[0.4,0.6),[0.6,0.9),[0.9,1])来表示不同的行为。因此,根据F和Cr的值,将其离散为5个不同的区间((0,0.1),[0.1,0.4),[0.4,0.6),[0.6,0.9),[0.9,1])。因此,Db是一个十列二进制矩阵,前5列表示F,后5列表示Cr。

步骤3:利用Apriori算法找到最频繁的2项集。 在原有的频繁k项集Apriori算法的基础上,开发了一种改进的Apriori-2算法,该算法可以获得迄今为止最成功的F和Cr的组合。这里,因为我们只需要F和Cr的关联规则,所以k设为2。在本文中,F和Cr最成功的组合,通过Apriori-2算法表示Db最频繁的2项集。换句话说,在Db中,重复次数最多的行代表最频繁的F和Cr间隔。也就是F和Cr最成功的组合。图5给出了一个例子。有一个Db有5行。利用Apriori-2算法,输出最成功的F和Cr对(F [0.6,0.9), Cr[0.6,0.9))。

步骤4:根据上述关联规则生成新值。
通过Apriori-2算法,我们可以得到代表不同F和Cr分布区间的两列数。例如,如果返回L2 =[3,9],则表示F与Cr分布域最常见的关联规则是F∈[0.4,0.6)和Cr∈[0.6,0.9)。同时输出推荐的上限和下限分别为Fu、Fl、Cru和Crl。根据这些F和Cr区间的显式关联规则,可以生成新的F和Cr,具体如下:
每一代中的每个粒子都用下面的公式产生F和Cr
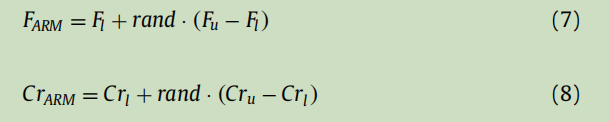
步骤5:使用贪婪算子选择更好的候选参数。 为了保持现有算法的良好搜索性能,将基于arm的参数自适应策略与原有算法相结合,提出了一种贪心算子。在每次迭代中,分别评估两个试验向量Ui和Ui_ARM,分别代表原始参数自适应策略和基于arm的参数自适应策略生成的每个试验向量。然后,选择适应度值较好的试验向量,尝试在选择操作中替换Xi。这个贪婪选择算子可以描述如下:
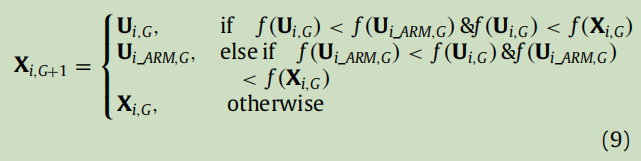
(3)补充:


找K频繁项集有两种算法,第二种算法可以直接产生不重复的2频繁项集,是改进的算法,适合于F、Cr参数的自调整。
三. SaDE-ARM algorithm

整体知识点:
1.在这里其实就是在传统的SaDE基于参数自维护的差分进化算法的基础上改变参数F、Cr的更新方式,自维护的参数自调整没有考虑F、Cr之间的影响,在这里引入关联规则挖掘,目的是学习历史成功的参数的信息,通过经典的2-频繁项集搜索,找到支持度最高的F和Cr的范围,在这个范围内进行搜索F和Cr的值。
2.但是并不是直接用这种方法去替代原先的参数自维护的方式,而是两者结合,同时进行,在选择的阶段选择最优的粒子,并且将成功的参数信息保存下来。
3.并不是每一代都进行ARM算法找F和Cr的最优范围,在这里是每NP代才计算一次最优范围。
4.本实验在最后对种群大小、维度大小、F和Cr范围的划分进行了实验测试,验证本实验采用的参数的正确性或者合适性。















 1268
1268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









