










一、项目简介
注意(本项目完全是用python编写)
1、本项目为实训项目,并无实际参考意义,望周知。
2、本次项目使用51job和中华英才网的相关数据
3、由于两个网站的数据爬取部分相似便只给出一个的源代码,另一个以截图截出重要代码。
二、数据收集
数据
提取码:s7bd
1、创建项目以及其相应的爬虫主文件
scrapy startproject shixun #在终端创建scrapy项目
scrapy genspider job 51job.com #创建相关爬虫主文件
2、item.py的编写(爬取字段列表的编写)
import scrapy
class Shixun2Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 职位名称
name = scrapy.Field()
# 工资
money = scrapy.Field()
# 招聘公司
comply = scrapy.Field()
# 工作地点
didian = scrapy.Field()
# 工作经验
jingyan = scrapy.Field()
# 学历要求
xueli = scrapy.Field()
# 工作内容、任职要求
neirong = scrapy.Field()
#发布时间
time = scrapy.Field()
3、爬虫(job.py)的编写
# -*- coding: utf-8 -*-
import scrapy
from shixun2.items import Shixun2Item
class JobSpider(scrapy.Spider):
name = 'job'
allowed_domains = ['51job.com']
start_urls = []
for num in range(1, 1400):
# 遍历页码,生成初始网址
urls = 'https://search.51job.com/list/000000,000000,0000,00,9,99,java,2,' + str(
num) + '.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
start_urls.append(urls)
def parse(self, response):
url_box = response.xpath('//*[@class="el"]')
# 获取每个网址的二级页面
for url in url_box:
sec_url = str(url.xpath('p/span/a/@href').extract_first())
if not sec_url == "None":
yield scrapy.Request(sec_url, callback=self.parse_de)
def parse_de(self, response):
item = Shixun2Item()
# 获取所需字段
item['name'] = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/h1/text()').extract_first()
item['money'] = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/strong/text()').extract_first()
item['comply'] = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[1]/a[1]/text()').extract_first()
item['didian'] = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()[1]').extract_first()
item['jingyan'] = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()[2]').extract_first()
item['xueli'] = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()[3]').extract_first()
item['time'] = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()[5]').extract_first()
item['neirong'] = response.xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div/p/text()').extract()
print(item['name'])
return item
4、存数据库的编写(pipelines.py)
from pymongo import MongoClient
class Shixun2Pipeline:
#将数据添加到mongodb数据库中
def open_spider(self,spider):
self.db = MongoClient('localhost',27017).shixun
self.collection = self.db.bigdata
def process_item(self, item, spider):
self.collection.insert_one(dict(item))
return item
def close_spider(self,spider):
self.collection.close()
5、反爬机制的设置(setting.py的编写)
ROBOTSTXT_OBEY = False #robots协议
COOKIES_ENABLED = False #cookie
#设置请求头
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
LOG_LEVEL = 'WARN' #改变输出等级,方便观察输出
#存mongoodb需要
ITEM_PIPELINES = {
'shixun2.pipelines.Shixun2Pipeline': 300,
}
6、运行项目
需要在相应的文件的目录下运行如下代码
scrapy crawl job #job为爬虫文件名称
保证数据爬取下来了过后便可以往后操作(建议数据在20万条以上)
三、数据处理
1、数据处理思路
1.1、用scrapy爬取并存入到mongoodb
1.2、从本地传输到虚拟机上
1.3、通过flume监听虚拟机文件夹并上传到hdfs并收集日志
1.4、hive新建数据库、数据表、固定结构
1.5、导入数据形成数据表
1.6、用hive分析数据并得出相应结果
2、flume数据传输
flume配置文件的编写
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/data/
a1.sources.r1.fileHeader = true
a1.sources.r1.ignorePattern = ([^ ]*\.tmp)
a1.sources.r1.inputCharset = UTF-8
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://master:9000/flume/upload/%Y%m%d/%H
a1.sinks.k1.hdfs.filePrefix = upload-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 1
a1.sinks.k1.hdfs.roundUnit = hour
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.batchSize = 1000
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 180
a1.sinks.k1.hdfs.rollSize = 134217700
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.minBlockReplicas = 1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
上传过后的文件夹
文件
hive新建的数据库、表等
hive> show databases;
OK
default
movie
qimo
shixun
Time taken: 0.24 seconds, Fetched: 4 row(s)
hive> use shixun;
OK
Time taken: 0.061 seconds
hive> show tables;
OK
bigdata
data_collect
data_dev
data_fenxi
Time taken: 0.036 seconds, Fetched: 4 row(s)
数据相关查询截图
将数据转存mysql数据库
bin/sqoop export --connect jdbc:mysql://master:3306/hive_shixun --username root --password 12345678 --table data_collect --export-dir /user/hive/warehouse/shixun.db/data_collect --input-fields-terminated-by ','
bin/sqoop export --connect jdbc:mysql://master:3306/hive_shixun --username root --password 12345678 --table bigdata --export-dir /user/hive/warehouse/shixun.db/bigdata --input-fields-terminated-by ','
…
在这里就不完全粘贴出来了
由于个人能力原因,剩下的我选择了在python中获取数据并对hive数据进行分析和可视化操作。
导入后在MySQL中查询出表格
[root@master conf]# mysql -u root -p
Enter password:
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)
[root@master conf]# mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 115
Server version: 5.7.28 MySQL Community Server (GPL)
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| big_data |
| hive |
| mysql |
| performance_schema |
| qimo |
| shixun |
| sys |
| test |
+--------------------+
9 rows in set (0.00 sec)
mysql> use shixun;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+------------------+
| Tables_in_shixun |
+------------------+
| bigdata |
| bigdata_1 |
| china_data |
| tab_1 |
| tab_2 |
| tab_3 |
+------------------+
6 rows in set (0.00 sec)
mysql>
3、数据处理、可视化操作
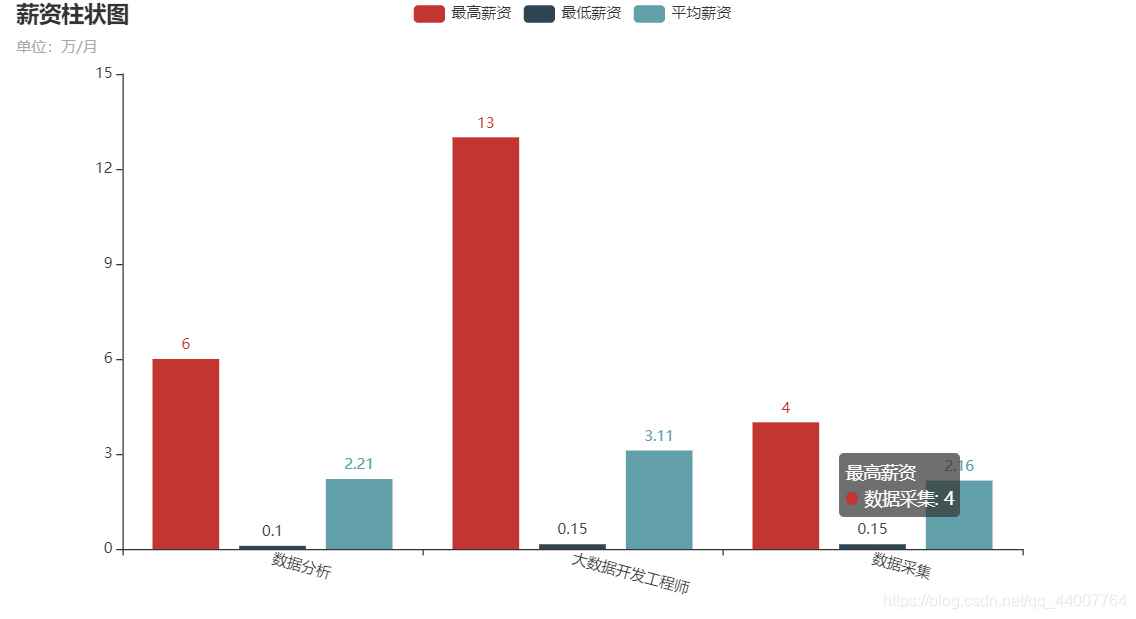
3.1、分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资,并作条形图将结果展示出来;
#导入相应的包以及模块
import pymysql
from pyecharts.charts import Bar
from pyecharts import options as opts
from func import gongzi
#创建所需要的列表,方便后面使用
data_analysis = []
Big_data = []
data_collection_data = []
#创建mysql链接
conn = pymysql.connect(
host='ip',
user='root',
password='12345678',
port=3306,
db='shixun'
)
# 数据分析相关
def data_analyst():
#创建游标
cursor = conn.cursor()
#创建查询有关数据分析的数据的sql语句
sql = "select * from bigdata where name like '数据分析%'"
try:
#查询并取出
conn.begin()
cursor.execute(sql)
data = cursor.fetchall()
#遍历其中的元组并将数据添加到例表中
for d in data:
sec_data = []
for x in d:
sec_data.append(str(x).strip("\xa0\xa0"))
# print(sec_data[:3])
# print(d)
data_analysis.append(sec_data[1])
print("data_analysis TAG: {}".format(data_analysis))
conn.commit()
except Exception as e:
print(e)
#调用计算最高、最低、平均工资的方方法
a = gongzi(data_analysis)
return a
'''
因为三个的方法是一样的,所以我就只写明了第一个的相关注释,大数据开发工程师和数据采集相关的方法一样
'''
# 大数据开发工程师
def Big_data_development():
cursor = conn.cursor()
sql_data = "select * from bigdata where name like '大数据开发工程师%'"
try:
conn.begin()
cursor.execute(sql_data)
data = cursor.fetchall()
for d in data:
sec_data_dev = []
for x in d:
sec_data_dev.append(str(x).strip("\xa0\xa0"))
# print(sec_data[:2])
Big_data.append(sec_data_dev[1])
conn.commit()
print("Big_data TAG:{}".format(Big_data))
except Exception as e:
print(e)
b = gongzi(Big_data)
return b
#数据采集
def data_collection():
cursor = conn.cursor()
sql = "select * from bigdata where name like '%数据采集%'"
try:
conn.begin()
cursor.execute(sql)
data = cursor.fetchall()
for d in data:
sec_data_collect = []
for x in d:
sec_data_collect.append(x)
# print(sec_data_collect[:2])
data_collection_data.append(sec_data_collect[1])
conn.commit()
print("data_collection_data TAG:{}".format(data_collection_data))
except Exception as e:
print(e)
c = gongzi(data_collection_data)
return c
#分别调用三个函数并去出其返回值
data_analyst_data = data_analyst()
Big_data_development_data = Big_data_development()
data_collection_data_d = data_collection()
#分别将前面所取出的数据加入到low:最低、hight(最高)、avg(平均)工资的列表里面
low = [data_analyst_data[0],Big_data_development_data[0],data_collection_data_d[0]]
hight = [data_analyst_data[1],Big_data_development_data[1],data_collection_data_d[1]]
avg = [data_analyst_data[2],Big_data_development_data[2],data_collection_data_d[2]]
print("TAG------------------------------")
print( low + hight + avg)
print("TAG------------------------------")
#图标所需要的x轴的坐标名称
name_list = ["数据分析","大数据开发工程师","数据采集"]
#使用pyecharts绘出柱状图
c = (
Bar()
.add_xaxis(name_list)
.add_yaxis("最高薪资", hight)
.add_yaxis("最低薪资", low)
.add_yaxis("平均薪资", avg)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title="薪资柱状图", subtitle="单位:万/月"),)
.render("薪资柱状图.html")
)
效果图如下
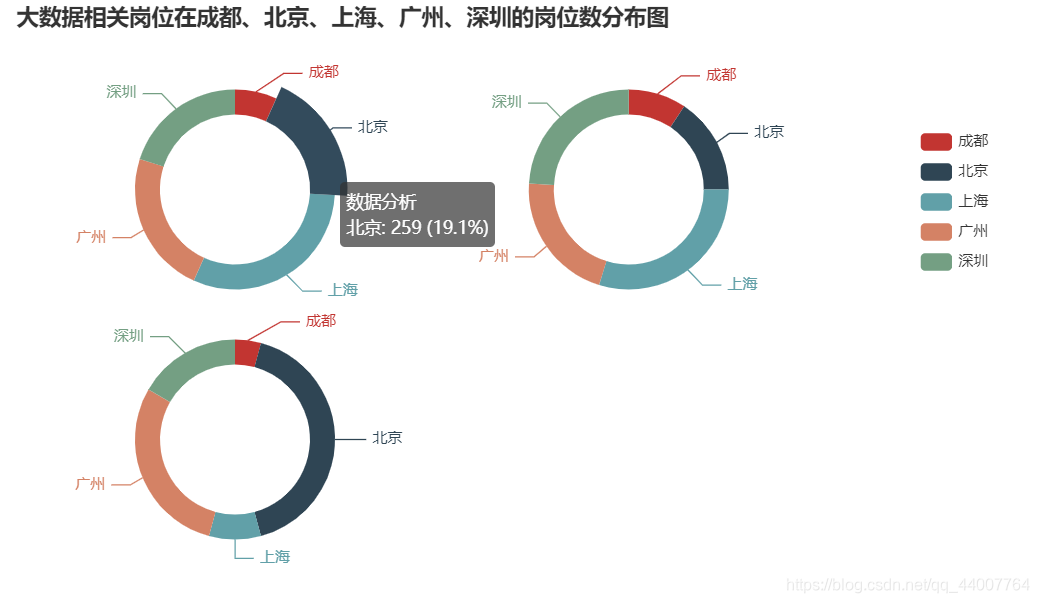
3.2、分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数,并做饼图将结果展示出来。
import pymysql
from pyecharts import options as opts
from pyecharts.charts import Pie
from func import count
data_analysis = []
Big_data_dve = []
data_collection_data = []
zhiwei_list = ["数据分析", "大数据开发工程师", "数据采集"]
area_list = ["成都", "北京", "上海", "广州", "深圳"]
conn = pymysql.connect(
host='192.168.20.134',
user='root',
password='12345678',
port=3306,
db='shixun'
)
# 获取游标
cursor = conn.cursor()
#获取相关数据的函数
def get_data(zhiwei_list, area_list):
#设置三个全局变量
global data_analysis, Big_data_dve, data_collection_data
for zhiwei in zhiwei_list:
if zhiwei == "数据分析":
for area in area_list:
sql = "select * from bigdata where name like '%" + zhiwei + "%' and didian like '%" + area + "%'"
data_analysis = count(zhiwei, area, sql, data_analysis)
print(zhiwei + ":" + str(data_analysis))
elif zhiwei == "大数据开发工程师":
for zhiwei in zhiwei_list:
if zhiwei == "大数据开发工程师":
for area in area_list:
sql = "select * from bigdata where name like '%" + zhiwei + "%' and didian like '%" + area + "%'"
Big_data_dve = count(zhiwei, area, sql, Big_data_dve)
print(zhiwei + ":" + str(Big_data_dve))
elif zhiwei == "数据采集":
for zhiwei in zhiwei_list:
if zhiwei == "数据采集":
for area in area_list:
sql = "select * from bigdata where name like '%" + zhiwei + "%' and didian like '%" + area + "%'"
data_collection_data = count(zhiwei, area, sql, data_collection_data)
print(zhiwei + ":" + str(data_collection_data))
get_data(zhiwei_list, area_list)
#绘图工具进行绘图
def new_label_opts():
return opts.LabelOpts( position="left")
c = (
Pie()
.add(
zhiwei_list[0],
[list(z) for z in zip(area_list, data_analysis)],
center=["20%", "30%"],
radius=[60, 80],
label_opts=new_label_opts(),
)
.add(
zhiwei_list[1],
[list(z) for z in zip(area_list, Big_data_dve)],
center=["55%", "30%"],
radius=[60, 80],
label_opts=new_label_opts(),
)
.add(
zhiwei_list[2],
[list(z) for z in zip(area_list, data_collection_data)],
center=["20%", "70%"],
radius=[60, 80],
label_opts=new_label_opts(),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="大数据相关岗位在成都、北京、上海、广州、深圳的岗位数分布图"),
legend_opts=opts.LegendOpts(
type_="scroll", pos_top="20%", pos_left="80%", orient="vertical"
),
)
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
)
.render("第二题.html")
)
效果图如下
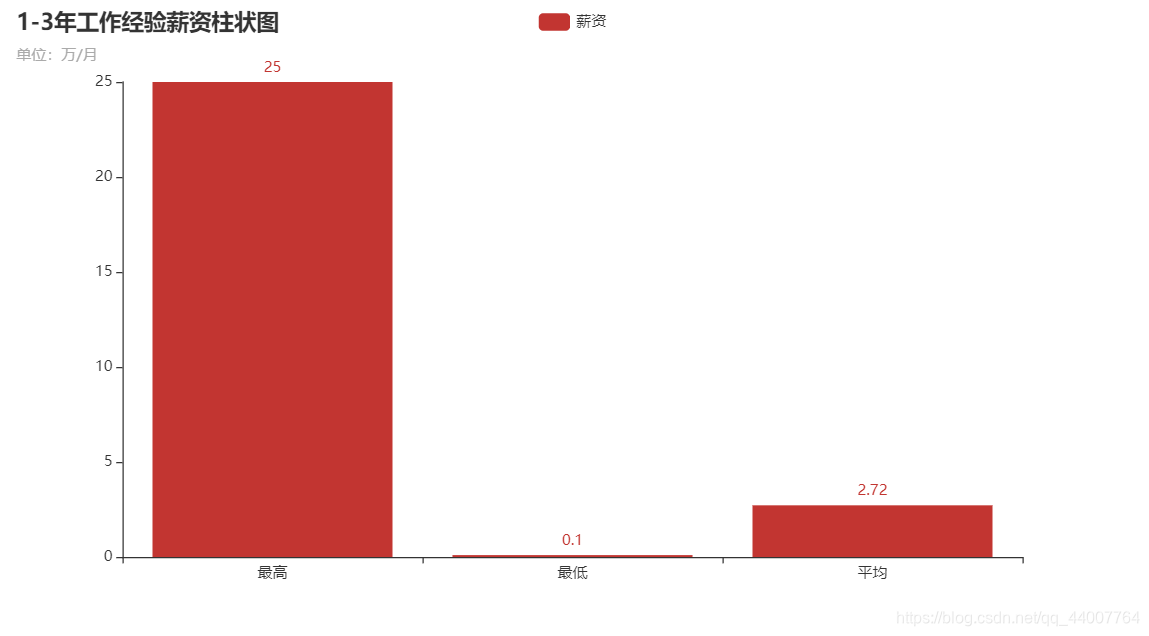
3.3、分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资),并做出条形图展示出来;
import pymysql
import pyecharts.options as opts
from pyecharts.charts import Line
conn = pymysql.connect(
host='ip',
user='root',
password='12345678',
port=3306,
db='shixun'
)
cursor = conn.cursor()
conn.begin()
sql = "select time ,count(*) from tab_3 group by time;"
#select * from bigdata where name like '%大数据%' and time like '%-%'
cursor.execute(sql)
data = cursor.fetchall()
data_0 = []
for da in data:
d = []
for x in da:
d.append(str(x).strip("\xa0\xa0"))
data_0.append(d)
time = []
frequency = []
for a in data_0:
time.append(a[0])
frequency.append(a[1])
print(time)
print(frequency)
(
Line(init_opts=opts.InitOpts(width="1600px", height="800px"))
.add_xaxis(xaxis_data=time)
.add_yaxis(
series_name="招聘次数",
y_axis=frequency,
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最大值"),
opts.MarkPointItem(type_="min", name="最小值"),
]
),
markline_opts=opts.MarkLineOpts(
data=[opts.MarkLineItem(type_="average", name="平均值")]
),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="职位需求趋势"),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
toolbox_opts=opts.ToolboxOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
)
.render("temperature_change_line_chart.html")
)
效果图
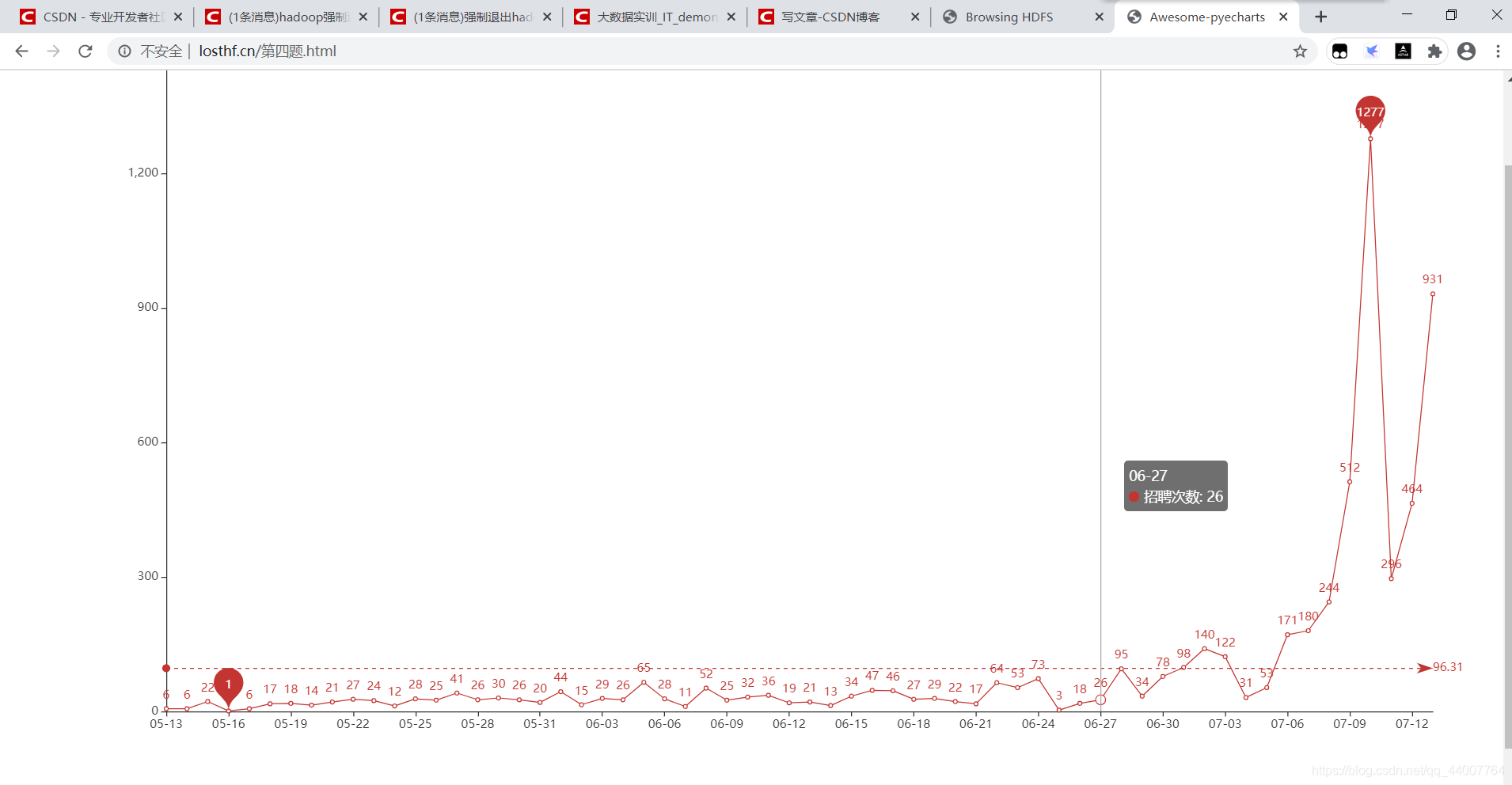
3.4、分析大数据相关岗位几年需求的走向趋势,并做出折线图展示出来;
import pymysql
import pyecharts.options as opts
from pyecharts.charts import Line
conn = pymysql.connect(
host='192.168.20.134',
user='root',
password='12345678',
port=3306,
db='shixun'
)
cursor = conn.cursor()
conn.begin()
sql = "select time ,count(*) from tab_3 group by time;"
#select * from bigdata where name like '%大数据%' and time like '%-%'
cursor.execute(sql)
data = cursor.fetchall()
data_0 = []
for da in data:
d = []
for x in da:
d.append(str(x).strip("\xa0\xa0"))
data_0.append(d)
time = []
frequency = []
for a in data_0:
time.append(a[0])
frequency.append(a[1])
print(time)
print(frequency)
(
Line(init_opts=opts.InitOpts(width="1600px", height="800px"))
.add_xaxis(xaxis_data=time)
.add_yaxis(
series_name="招聘次数",
y_axis=frequency,
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最大值"),
opts.MarkPointItem(type_="min", name="最小值"),
]
),
markline_opts=opts.MarkLineOpts(
data=[opts.MarkLineItem(type_="average", name="平均值")]
),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="职位需求趋势"),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
toolbox_opts=opts.ToolboxOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
)
.render("temperature_change_line_chart.html")
)
效果图
3.5自行编写的方法函数(func.py)
面对的问题不同,处理的方法也不同,根据自己的需求情况编写。
'''
这是一个写方法的文件
'''
import pymysql
conn = pymysql.connect(
host='192.168.20.134',
user='root',
password='12345678',
port=3306,
db='shixun'
)
# 获取游标
cursor = conn.cursor()
# 计算工资的方法
def gongzi(data):
# 先定义相关列表
qian = []
wan = []
nian = []
min_f = []
max_f = []
# 从数据中分别取出工资单位为万/月、千/月、万/年的数据并放入不同的列表
for g in data:
if g is not None:
if g[-3:] == "千/月":
qian.append(g[:-3].split("-"))
elif g[-3:] == "万/年":
nian.append(g[:-3].split("-"))
else:
wan.append(g[:-3].split("-"))
low = 0
hignt = 0
# 计算工资单位为千/月的工资的最高、最低工资并放入相应的列表中
for q in qian:
num = float(q[0]) * 0.1
h = float(q[1]) * 0.1
min_f.append(round(num, 2))
max_f.append(round(h, 2))
hignt += h
low += num
# 计算工资单位为万/月的工资的最高、最低工资并放入相应的列表中
for x in wan:
if len(x) == 2:
l = float(x[0])
h = float(x[1])
min_f.append(round(l, 2))
max_f.append(round(h, 2))
hignt += h
low += l
# 计算工资单位为万/年的工资的最高、最低工资并放入相应的列表中
for i in nian:
if i is not None:
l = float(i[0]) / 12
h = float(i[1]) / 12
min_f.append(round(l, 2))
max_f.append(round(h, 2))
hignt += h
low += l
# 在相应的列表中取出最大值、最小值并计算出平均工资
list_data = [min(min_f), max(max_f), round((low + hignt) / len(data), 2)]
return list_data
# 获取地点例表
def get_list(zhiwei, area, didianlist, sql_l):
conn.begin()
cursor.execute(sql_l)
data = cursor.fetchall()
didian = []
for da in data:
didian.append(da)
print("len(didian):" + str(len(didian)))
# print(didian)
# 返回相关地点的个数,即列表长度
return len(didian)
# 统计成都、北京、上海、广州、深圳五个地方的相关职位信息
def count(zhiwei, area, sql, get_data_len):
if area == "成都":
cd_get_data = get_list(zhiwei, area, didianlist='cd', sql_l=sql)
# 调用前面的地点信息相关
get_data_len.append(cd_get_data)
elif area == "北京":
bj_get_data = get_list(zhiwei, area, didianlist='bj', sql_l=sql)
get_data_len.append(bj_get_data)
elif area == "上海":
sh_get_data = get_list(zhiwei, area, didianlist='sh', sql_l=sql)
get_data_len.append(sh_get_data)
elif area == "广州":
gz_get_data = get_list(zhiwei, area, didianlist='gz', sql_l=sql)
get_data_len.append(gz_get_data)
elif area == "深圳":
sz_get_data = get_list(zhiwei, area, didianlist='sz', sql_l=sql)
get_data_len.append(sz_get_data)
# 返回一个存储相关数据的列表
return get_data_len
# sql查询方法
def sel(sql, li):
conn.begin()
cursor.execute(sql)
data = cursor.fetchall()
for da in data:
li_1 = []
for d in da:
li_1.append(d)
li.append(li_1[1])
print(len(li))
四、实训总结
本次的实训项目综合了大数据基础相关的绝大部分知识,爬虫、scrapy框架、Hadoop、hive、flume,这些知识的综合应用在我的脑海中形成了一个相对完整的大数据项目结构,从数据采集、数据清洗到数据处理以及相关日志文件收集、本地与虚拟机的文件互传等等。
总体来说,本次实训较大的提升了我对大数据相关的编程的能力,也更加明确了大数据项目编程的方法和思路,这次的实训项目对我的能力提升一很好的帮助。















 879
879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









