






HashMap集合put元素的底层代码分析
一.HashMap集合put元素时的过程初步分析
Map接口的实现类有HashMap、TreeMap、LinkedHashMap HashTable等。
底部的数据结构:
HashMap: 数组为基础 数组元素使用地址指向的方式 挂着 链表和红黑树
LinkedHashMap:是HashMap的子类 底层仍然是数组+链表/红黑树结构,不过多维护了一个双向链表来记录插入顺序或访问顺序。
TreeMap:使用红黑树数据结构进行存储
HashTable:使用数组+链表的数据结构。
除开TreeMap其余三个HashMap、LinkedHashMap和HashTable 都使用数组作为基础数据结构,链表和红黑树用于处理哈希冲突。我就以HashMap为例来解释put元素时的底层过程。
1.基本数据结构:
HashMap底层主要使用**数组和 链表 加 红黑树****来存储数据。- 数组是
HashMap的主体,链表或红黑树则是解决哈希冲突的工具。
2.put元素流程:
- 计算键的哈希值。
- 根据哈希值和数组长度计算索引。
- 检查该索引位置是否有元素。
- 如果没有,直接存储。
- 如果有,遍历链表或红黑树:
- 如果键已存在,更新值。
- 如果键不存在,添加到链表末尾或红黑树中。
- 如果元素数量超过阈值,进行扩容。
二.put方法的主要步骤:
1. 计算键的哈希值
使用键的hashCode()方法计算其哈希值。(611-613行)

计算hash值:(337-340行)

我们解释一下hash值:比如自己定义一个类 按
alt shift s就会有生成hashcode的选项,我们可以看一下;

创建了一个Person类 里面具备三个属性:性别 年龄 名字;
我们可以看一下hashcode生成器

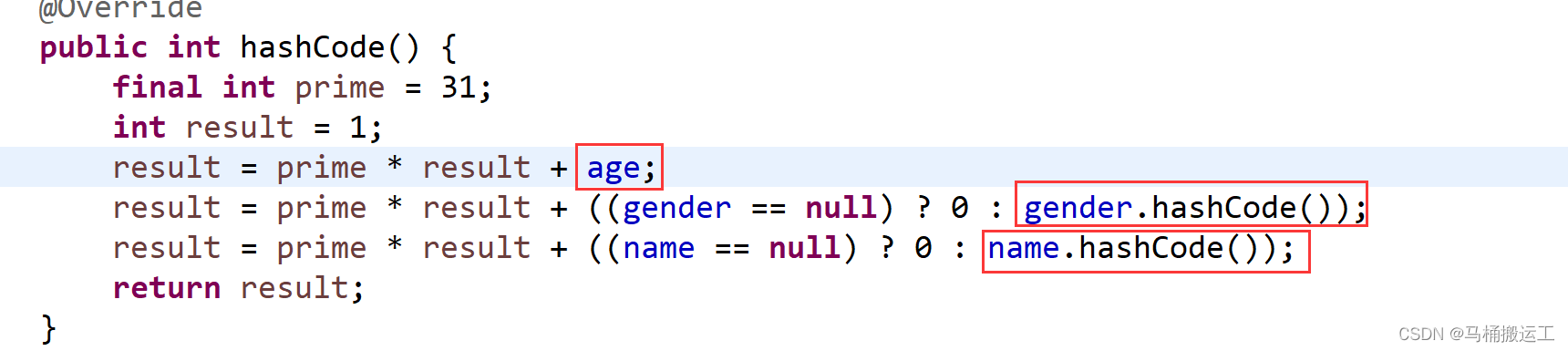
这个方法的hash值其中32位 都是通过自己属性值来决定的,属性值不同hash值也不同,那么用equals比较也不同;所以我们甚至可以自己写hashcode方法 比如说32位,前15位由第一个gender决定,后15位由name决定,后2位由age决定,是一样的;
判断两个对象是否相等 也是判断hash值与equals一起使用的;
上文的return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);的h与上自己 无符号右移16位的值 再异或,相当于哈希值前面16位高位没有发生变化(前十六位异或0不会变化) 后面16位变成原来的后十六位与前十六位的异或信息;
这样做的目的是 后面有一个对该hash值与(或者求余操作)来决定存放的位置,但是这个操作的另一个是一个n-1 即这个n-1的操作数 比较小 常常是后16位才有值的数 前面都是0,而求出来哈希值 却只有后面的哈希值参与了计算,这样不能充分发挥该哈希值所代表的差异性,如果不对该32位数进行运算直接去求位置,这样的运算不够充分,结果也一定不够离散;
所以要对其进行异或操作 把高位信息与低位信息都引入这个通过hash值求位置的操作里面;这样不同对象 在存放的时候 才会尽可能的离散;
2. 定位数组索引
通过哈希值和数组长度计算出一个索引值
求位置:
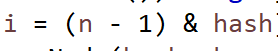
以前版本:(使用哈希值对数组长度取模 hashtable中还在这么用)。

前面那个按位与 十六进制的数 0X7FFFFFFF不必在意 那个是为了保证你是正数的形式 可以理解为做了个绝对值操作。
-
3.处理哈希冲突
putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict)(625-666行)-
如果该索引处为空,则直接在该位置创建一个新的节点存储键值对。

-
如果该索引处已经存在节点(即哈希冲突),则遍历链表或红黑树:
(632-651行)
-
如果链表中已存在相同的键,则替换旧值。(632-636行)
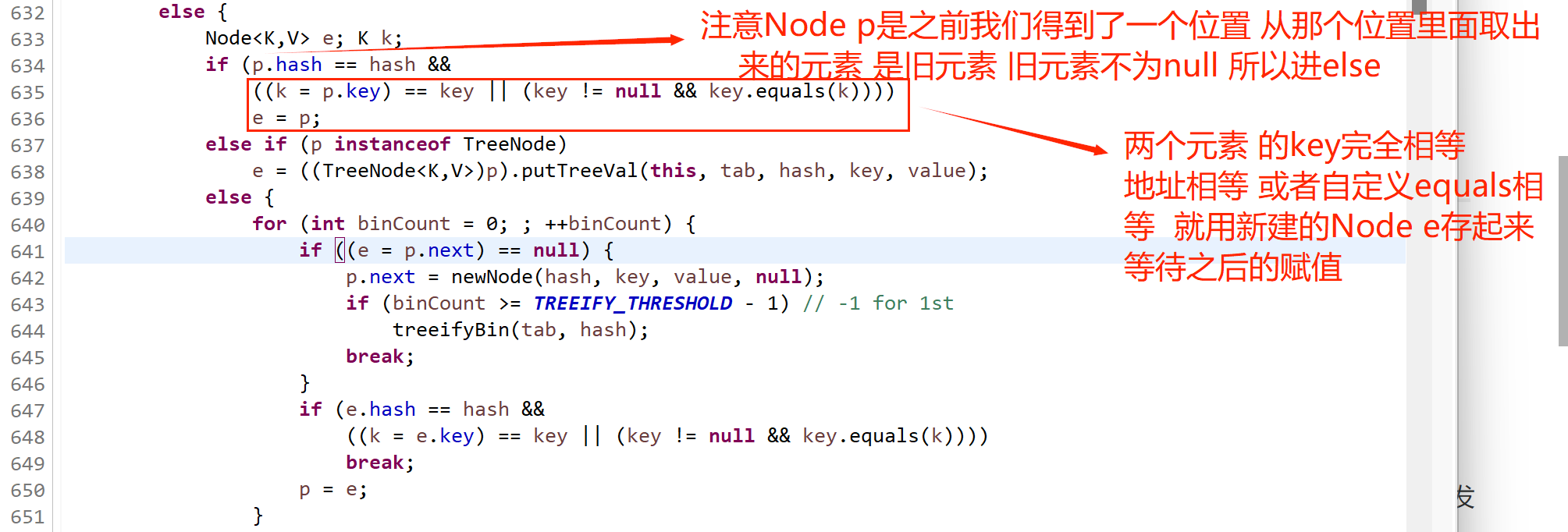
替换旧值 656行

-
如果链表中不存在相同的键,则将新节点添加到链表末尾(或红黑树中)。
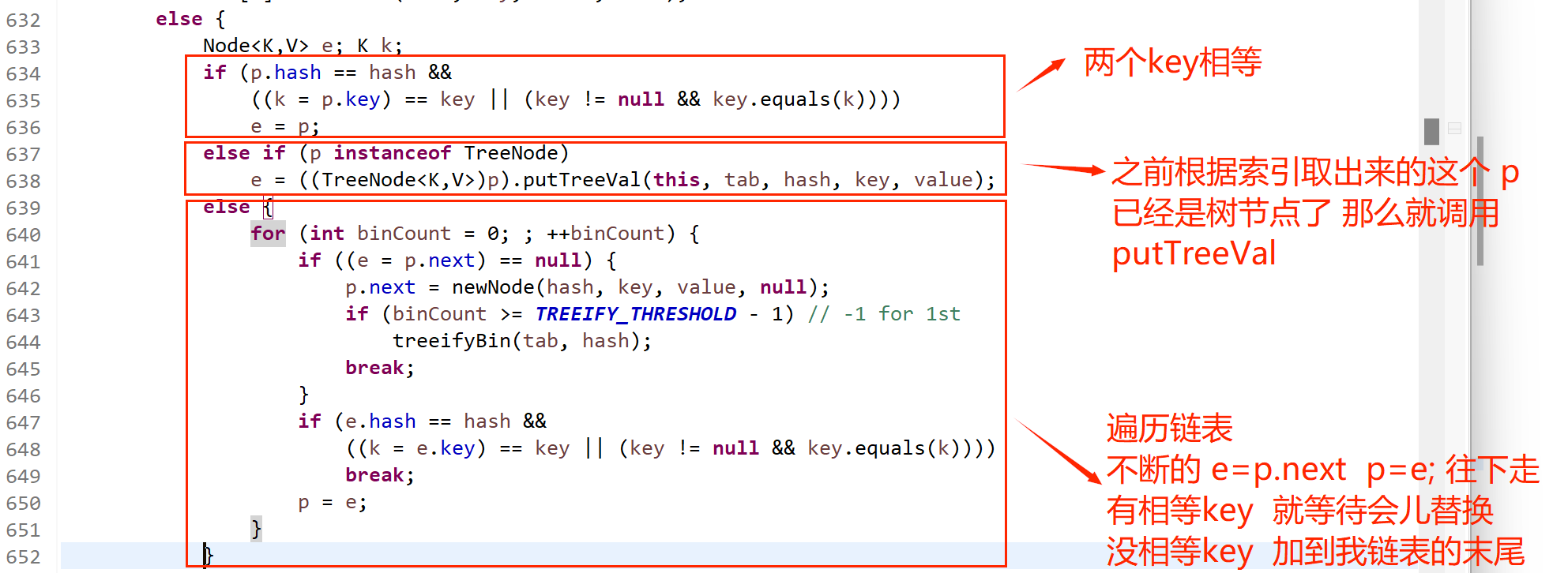
添加到链表末尾:

-
如果链表长度过长(超过树化阈值,默认为8),则将链表转换为红黑树。

treeifyBin方法

-
-
4.调整数组大小(可选)
如果HashMap中的元素数量超过了其容量和加载因子的乘积(即阈值)或者是上次链表长度大于等于7了而数组长度小于64,则触发数组扩容。扩容通常是将数组长度翻倍,并重新计算所有元素的索引位置。
1.如果
HashMap中的元素数量超过了其容量和加载因子的乘积(即阈值)或者是上次链表长度大于等于7了而数组长度小于64,则触发数组扩容。扩容通常是将数组长度翻倍,并重新计算所有元素的索引位置。

2.链表长度大于7了 但是数组长度小于64

三.几个实现类在put元素时候的区别
HashMap
底部数据结构:
- HashMap使用数组+链表+红黑树以的数据结构。
put元素流程:
- 计算键的哈希值。
- 根据哈希值和数组长度计算索引。
- 检查该索引位置是否有元素。
- 如果没有,直接存储。
- 如果有,遍历链表或红黑树:
- 如果键已存在,更新值。
- 如果键不存在,添加到链表末尾或红黑树中。
- 如果元素数量超过阈值,进行扩容。
TreeMap
底部数据结构:
- TreeMap使用红黑树数据结构进行存储,保证元素按照键的自然顺序或自定义比较器顺序进行排序。
put元素流程:
- 检查树的根节点。
- 如果为空,创建新节点作为根节点。
- 如果不为空,根据比较器或自然顺序,遍历树找到合适的位置插入新节点。
- 插入新节点后,进行红黑树的旋转和颜色调整,以保持树的平衡。
LinkedHashMap
底部数据结构:
- LinkedHashMap是HashMap的子类,它维护了一个双向链表来记录插入顺序或访问顺序。
- 底层仍然是数组+链表/红黑树结构。
put元素流程:
- 执行HashMap的put流程(包括计算哈希值、定位索引、处理冲突等)。
- 将新元素添加到双向链表的尾部,以保持插入顺序。
HashTable
底部数据结构:
- HashTable与HashMap类似,使用数组+链表的数据结构。
- HashTable是线程安全的,但性能相对较低。
put元素流程(与HashMap类似,但考虑线程安全):
- 计算键的哈希值。
- 根据哈希值和数组长度计算索引。
- 检查该索引位置是否有元素。
- 如果没有,直接存储。
- 如果有,遍历链表:
- 如果键已存在,更新值。
- 如果键不存在,添加到链表末尾。
总结
- HashMap、LinkedHashMap和HashTable都使用数组作为基础数据结构,但链表和红黑树用于处理哈希冲突。TreeMap则直接使用红黑树进行排序和存储。
- HashMap和LinkedHashMap在性能上通常优于HashTable,因为HashTable是线程安全的,但性能较低。
- LinkedHashMap在HashMap的基础上维护了一个双向链表,以记录元素的插入顺序或访问顺序。
基础数据结构,但链表和红黑树用于处理哈希冲突。TreeMap则直接使用红黑树进行排序和存储。 - HashMap和LinkedHashMap在性能上通常优于HashTable,因为HashTable是线程安全的,但性能较低。
- LinkedHashMap在HashMap的基础上维护了一个双向链表,以记录元素的插入顺序或访问顺序。
- TreeMap保证元素按照键的顺序或自定义比较器顺序进行排序。















 855
855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









