







【论文笔记】An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale(Vision Transformer, ViT)
- 文章题目:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- 作者:Dosovitskiy, A., Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, M. Dehghani, Matthias Minderer, Georg Heigold, S. Gelly, Jakob Uszkoreit and N. Houlsby
- 时间:2020
- 来源:ICLR 2021 / ArXiv
- paper:http://arxiv.org/pdf/2010.11929v1
- code:https://github.com/google-research/vision_transformer , https://github.com/lucidrains/vit-pytorch , https://github.com/likelyzhao/vit-pytorch
- 引用:Dosovitskiy, A., Beyer, L., Kolesnikov, A., et al (2020). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.ArXiv, abs/2010.11929.
感性认识
- 研究的基本问题
将Transformer直接应用于图像领域,进行图像分类任务,而不修改Transformer架构,也不使用CNN。 - 主要想法
将image分割成大小一致的patch,对应于NLP中的token,再将其进行嵌入表示,成为Transformer的输入。在patch前加入一个class表示,对应全局信息(图片分类),进行最终的预测。 - 结果与结论
在中规模数据上,表现一般。在大规模数据集预训练下,表现优异。且节省训练开销。 - 不足与展望
1.无法保留图像的二维结构信息(局部特性,归纳偏置),要依靠大量数据来弥补。
2.预训练与微调的开销问题。如何更有效利用自监督的预训练。
3.将transformer应用于cv中的其他领域。
理性认识
1. 摘要(abstract)
尽管Transformer架构已经在自然语言处理领域大杀特杀,但是在计算机视觉领域只有有限的应用。在视觉领域中,注意力机制要么与卷积网络结合使用,要么在保持整体结构不变的情况下,替换卷积网络的某些组件。我们证明了,对CNN的依赖不是必要的,在图象识别任务中,在图像块(image patches)的序列上应用纯粹的Transformer模型也可以表现得很好。当使用大量数据进行预训练,再迁移到多个中小型图象识别基准库后,ViT得到了优异的结果,相比于最先进(SOTA)的卷积网络,而训练所需要的计算资源更少。
2. 引言(INTRODUCTION)
基于Self-attention的架构,特别是Transformer,已经成为自然语言处理(NLP)的不二选择。其主要方法是在一个大型文本语料库上进行预训练,然后在一个较小的特定于任务的数据集上进行微调。得益于Transformer的计算效率和可扩展性,它可以训练具有超过100B的参数的超大模型。而且随着模型和数据集的增长,性能仍然没有饱和的迹象。
当然,在计算机视觉中,卷积仍然占主导地位。受NLP成功的启发,许多工作尝试将Self-attention融合进cnn架构,甚至一些人使用Self-attention替换卷积。后一种模型虽然理论上有效,但还没有在现代硬件加速器上得到有效扩展。因此,在大规模图像识别中,经典的ResNet(残差网络)式结构仍然是最先进的。
受NLP中Transformer成功的启发,我们尝试将一个标准Transformer直接应用到图像上,尽可能少的修改。为此,我们将图像分割成小块,并将这些块转化为线性嵌入序列,作为Transformer的输入。图像块(image patches)就相当于NLP任务中的单词(token)来做处理。并以有监督的方式训练图像分类模型。
当在中等规模的数据集(如ImageNet)上进行训练时,模型的准确率比同等规模的resnet低几个百分点。这一看似令人沮丧的结果是意料之中的:Transformer缺乏cnn所固有的一些归纳偏置(inductive biases),如平移不变性(translation equivariance)和局部性(locality),因此在数据量不足的情况下训练时不能很好地泛化。
然而,如果在更大的数据集(1400 -300万张图像)上训练模型,情况就会发生变化。我们发现大规模的训练可以克服归纳偏置(inductive biases)。当ViT在足够的规模上进行预先训练,并迁移到具有较少数据量的任务时,可以获得出色的结果。
3.相关工作
Transformer是由Vaswani等人提出,应用于机器翻译,并已成为许多自然语言处理任务中最先进的方法。基于Transformer的大型模型通常在大型语料库上进行预先训练,然后针对当前的任务进行微调。
单纯地对图像进行Self-attention需要每两个像素计算attention。这是像素的平方倍的开销。为了将Transformer应用到图像中,尝试许多近似方法。Parmar等人对每个query像素只在局部邻域计算Self-attention,而非全局。这种局部多头点积Self-attention块可以完全替代卷积。其他的,稀疏Transformer采用可扩展的近似全局Self-attention,以适用于图像。计算attentio的另一种方法是将其应用于不同大小的块中,在极端情况下,仅沿着单个轴。这些专门的注意力架构在计算机视觉任务中表现出了很好的效果,但需要复杂的工程设计。
最为相关的是Cordonnier等人的模型,该模型从输入图像中提取大小为2 × 2的小块,并在之上使用完全的Self-attention。这个模型与ViT非常相似,但我们的工作进一步证明,大规模的预培训可以使香草Transformer与最先进的cnn竞争(甚至更好)。此外,Cordonnier 使用的是2 × 2像素的小块,这使得该模型仅适用于小分辨率的图像,而我们也可以处理中等分辨率的图像。
最近的另一种相关模型是image GPT (iGPT),它在降低图像分辨率和颜色空间后,对图像像素使用Transformer。该模型以无监督的方式作为生成模型进行训练,然后可以对结果表示进行微调或线性探测以提高分类性能,在ImageNet上达到72%的最大精度。
4.方法(Method)
在模型设计中,尽可能地遵循原Transformer结构。这样做的优点是可扩展性和易实现——几乎可以开箱即用。
4.1 VIT
结构图:
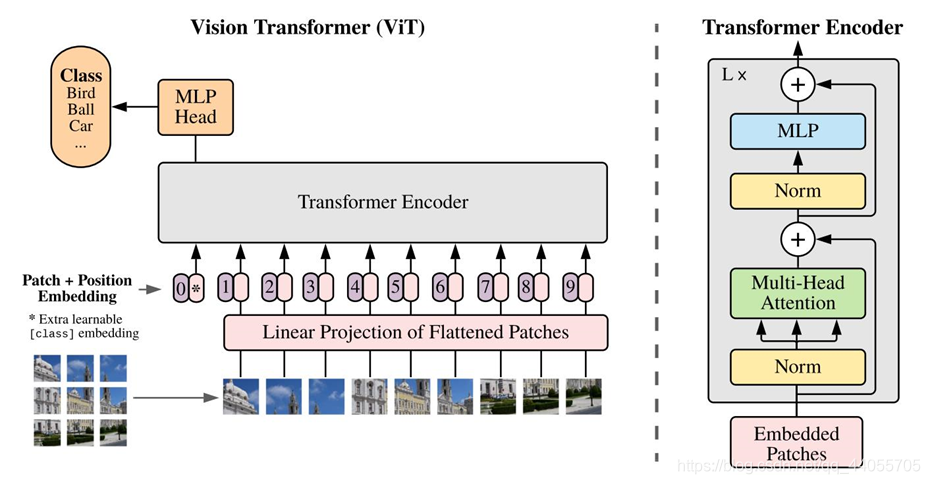
标准的接受token的一维嵌入向量作为输入。为了处理二维数据,要进行reshape。
原始图像输入:(H,W)是图片分辨率,C是通道数 x ∈ R H × W × C \text{x\ }\in \ \mathbb{R}^{H\times W\times C} x ∈
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 327
327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









