









论文: An image is worth 16x16 words: Transformers for image recognition at scale.
Github code(PyTorch Implementation):https://github.com/lucidrains/vit-pytorch
目录
Procedure 1 & 2:split an image into fixed-size patches & linearly embed them
Procedure 3:add position embeddings for each patches
Procedure 4:feed the resulting sequence of vectors to a standard Transformer encoder
3、 from einops import rearrange, repeat
Model Overview

1、split an image into fixed-size patches
2、linearly embed each of patches. In order to perform classification, we use the standard approach of adding an extra learnable “classification token” to the sequence.
3、add position embeddings for each patches,
4、feed the resulting sequence of vectors to a standard Transformer encoder.
Github Code Usage
import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)Procedure 1 & 2:split an image into fixed-size patches & linearly embed them

对应论文描述:

对应 code:https://github.com/lucidrains/vit-pytorch/blob/main/vit_pytorch/vit.py#L91
这里删除了与该步骤无关的代码,放出核心实现代码:
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim),
)
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape其中代码里的 b 是 batch size;c 是 channels,也就是图片的通道数 3;n 也就是每张图片的 patch 数量;
按照 Usage 里的设置,这里的 dim = 1024,也就是说每个 patch 被 linearly embed 成 1024 的维度,也就是所说的 token。
(这里的 Rearrange 挺有意思,之前没接触过,放后面介绍)
Procedure 2:In order to perform classification, we use the standard approach of adding an extra learnable “classification token” to the sequence.
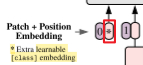
对应论文描述:

对应 code:
https://github.com/lucidrains/vit-pytorch/blob/main/vit_pytorch/vit.py#L97
这里删除了与该步骤无关的代码,放出核心实现代码:
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
def forward(self, img):
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
# input to encoder
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]再深究了一下这里 class token 的作用:
在计算机视觉的transform中,token有什么实际意义?或者说class token有什么意义? - 知乎

这就对应了代码:x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
Procedure 3:add position embeddings for each patches

对应论文描述:

对应 code:
vit-pytorch/vit.py at main · lucidrains/vit-pytorch · GitHub
https://github.com/lucidrains/vit-pytorch/blob/main/vit_pytorch/vit.py#L116
这里删除了与该步骤无关的代码,放出核心实现代码:
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
num_patches = (image_height // patch_height) * (image_width // patch_width)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.dropout = nn.Dropout(emb_dropout)
def forward(self, img):
b, n, _ = x.shape
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)注意,self.pos_embedding 的维度是(1, num_patches + 1, dim),而 x 的维度是 (batch_size, num_patches + 1, dim)。
也就是说,这里的 x += self.pos_embedding[:, :(n + 1)] 用了 python 的广播(broadcasting)机制。
Procedure 4:feed the resulting sequence of vectors to a standard Transformer encoder

对应论文描述:

![]()
对应 code:
https://github.com/lucidrains/vit-pytorch/blob/main/vit_pytorch/vit.py#L119
https://github.com/lucidrains/vit-pytorch/blob/main/vit_pytorch/vit.py#L64
https://github.com/lucidrains/vit-pytorch/blob/main/vit_pytorch/vit.py#L35
https://github.com/lucidrains/vit-pytorch/blob/main/vit_pytorch/vit.py#L22
这里删除了与该步骤无关的代码,放出核心实现代码:
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
# x are ready encoded into tokens
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)关于 Transformer 的知识可以参考 李宏毅 老师的 PPT 或者 Video:
https://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2019/Lecture/Transformer%20(v5).pptx
https://www.youtube.com/watch?v=ugWDIIOHtPA&list=PLJV_el3uVTsOK_ZK5L0Iv_EQoL1JefRL4&index=58
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return xclass PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)补充学习 PyTorch 代码细节
1、torch.chunk()
pytorch每日一学30(torch.chunk())将一个tensor分为指定数量的块_Fluid_ray的博客-CSDN博客_chunk tensor
2、torch.nn.Identity()
pytorch torch.nn.Identity() 是干啥的,解释。_artistkeepmonkey的博客-CSDN博客_torch.nn.identity()
3、 from einops import rearrange, repeat
einops张量操作神器(支持PyTorch)_木盏-CSDN博客_einops















 2082
2082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









