







搭建hadoop HA 之前须知
安装好jdk 以及 zookeeper
jdk安装连接:jdk安装
zookeeper安装连接:zookeeper安装
开始搭建hadoop
三台
hadoop01:192.168.197.111
hadoop02:192.168.197.112
hadoop03:192.168.197.113
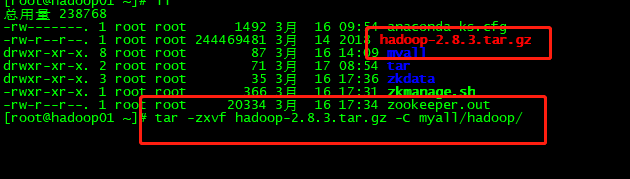
上传解压包 压缩命令
建议下修改hosts 多余两台子机后续用
vim /etc/hosts
tar -zxvf hadoop-2.8.3.tar.gz -C myall/hadoop/
核心配置文件
cd/etc/hadoop目录下

配置core-site.xml
<configuration>
<!--将两个namenode的地址组装成一个集群mycluster-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!--指定hadoop临时目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/myall/hadoop/hadoop-2.8.3/data/tmp</value>
</property>
<!--指定zookeeper地址,指定ZKFC故障自动切换转移-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
</configuration>
编辑 hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为mycluster,需要和core-site.xml中的保持一致
dfs.ha.namenodes.[nameservice id]为在nameservice中的每一个NameNode设置唯一标示符。
配置一个逗号分隔的NameNode ID列表。这将是被DataNode识别为所有的NameNode。
例如,如果使用"mycluster"作为nameservice ID,并且使用"nn1"和"nn2"作为NameNodes标示符
-->
<!--指定副本数-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--完全分布式集群名称-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!--namenode数据的存放地点,也就是namenode元数据存放的地方,记录了hdfs系统中文件的元数据-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/myall/hadoop/hadoop-2.8.3/dfs/name</value>
</property>
<!--datanode数据的存放地点,也就是block块存放的目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/myall/hadoop/hadoop-2.8.3/dfs/data</value>
</property>
<!--开启hdfs的web访问接口,默认端口时50070-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--集群中namenode节点有哪些-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!--nn1的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop01:8020</value>
</property>
<!--nn2的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop02:8020</value>
</property>
<!--nn1的HTTP通信地址-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop01:50070</value>
</property>
<!--nn2的HTTP通信地址-->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop02:50070</value>
</property>
<!--指定namenode元数据在JournalNode的存放位置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/mycluster</value>
</property>
<!--配置隔离机制方法,同一时刻只能有一台服务器对外响应,多个机制用换行分隔,即每个机制暂用一行,也可用shell命令切换-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--进程DFZKFailoverControlle-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--使用隔离机制时需要ssh无密码登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/myall/hadoop/.ssh/id_rsa</value>
</property>
<!--声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/myall/hadoop/hadoop-2.8.cd/data/ha/jn</value>
</property>
<!--关闭权限检查-->
<property>
<name>dfs.permisstions.enable</name>
<value>false</value>
</property>
<!--访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
</configuration>
配置hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/root/myall/jdk/jdk1.8.0_191
修改mapred-site.xml
<configuration>
<!--指定mr框架为yarn方式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--指定mr历史服务器主机,端口-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!--指定mr历史服务器webUI主机,端口-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<!--历史服务器的WEB UI最多显示20000个历史的作业记录信息-->
<property>
<name>mapreduce.jobhistory.joblist.cache.size</name>
<value>20000</value>
</property>
<!--配置作业运行日志-->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/tmp/hadoop-yarn/staging</value>
</property>
</configuration>
配置slaves
hadoop01
hadoop02
hadoop03
配置yarn-site.xml
<configuration>
<!--reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rmCluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop02</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop03</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<!--启动自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
将配置好的hadoop传送到其他三台虚拟机 在此之前已经配置好 ssh了 所以不需要密码
ssh-keygen 如果没配置秘钥的 执行
ssh-copy-id
传送文件
scp -r hadoop/ hadoop02:$PWD
scp -r hadoop/ hadoop03:$PWD
scp -r hadoop/ hadoop04:$PWD
习惯性添加环境变量 vim/etc/profile 四台全需要
export HADOOP_HOME=/root/myall/hadoop/hadoop-2.8.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
生效环境变量 四台全需要
source /etc/profile
第一次启动 一定要按照步骤来 !一定要!
首先启动三台zookeeper
启动zk (这是个启动脚本 集体详情请看上一篇文档:)
zookeeper安装详细过程链接
启动zk
./zkmanage.sh start

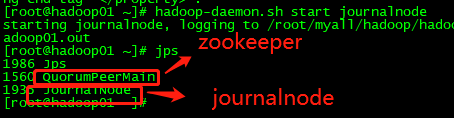
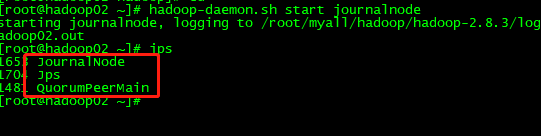
1、在hadoop01 ,hadoop02,hadoop03上分别启动JournalNode集群
hadoop-daemon.sh start journalnode
hadoop01
hadoop02
hadoop03
**2、格式化namenode 在hadoop01上执行命令: **
命令:
hdfs namenode -format

格式化hadoop01 完成 我们在hadoop01上启动namenode
hadoop-daemon.sh start namenode
此时hadoop01 会启动namenode节点 不要动继续往下看
此时就会在hadoop01上生成fsimage文件
我们将文件传给hadoop02
在hadoop02执行
hdfs namenode -bootstrapStandby
传送给hadoop02了以后 我们在hadop02继续启动namenode
hadoop-daemon.sh start namenode
此时hadoop01 hadoop02都启动了namenode
4、我们在hadoop01上启动所有的datanode节点
hadoop-daemons.sh start datanode
hadoop 启动完成! 进入网页看一下!
5、进入网页端
hadoop01:50070

hadoop02:50070

可以看到 三台工作节点

6、yarn
启动YARN
start-yarn.sh
还需要手动在standby上手动启动备份的 resourcemanager
yarn-daemon.sh start resourcemanager
到此,hadoop配置完毕,可以统计浏览器访问。
遇到的问题
1)启动namenode时两台主机都是standby
在bin目录下执行命令:
hadoop-daemon.sh start zkfc
如果执行了命令 (选举一台主机为active)也不好使
解决方式:
进入zookeeper下面的bin目录,执行命令:
zkCli.sh -server hadoop01:2181
这样就选定active!!!















 717
717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









