







注:log在表示信息量时一般默认底为2
一、熵
信息量,假设每件事请发生的概率为P(i)

熵用来标识所有的信息量的期望值

二、相对熵(KL散度)
对于一同一个随机变量x有两个单独的概率分布P(x)和Q(x),用KL散度(Kullback-Leibler (KL) divergence) 来衡量这两个分布的差异。

训练过程就是要把D(KL)最小化,使得预测值和准确值更加接近。
三、交叉熵
3.1公式变形可以得到

p代表准确值,q代表预测值,训练过程中 H(p(x)) 不变
用此来评估label和predicts之间的差距效果较好,多数机器学习模型都直接用交叉熵作为loss。
交叉熵H(p,q)

四、softmax_cross_entropy
tensorflow中函数softmax_cross_entropy_with_logits
用来计算label和logits之间的softmax交叉熵(此处的label必须是one-hot形式的,可以通过tf.one_hot转化)
函数传入的logits是unscaled的,即没有经过softmax或者sigmoid的,函数内部自动高效的softmax处理。
计算过程:
1、首先对输入softmax处理

2、计算交叉熵
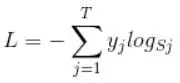
Sj为经过softmax后的每一个第 j 个值,表示该样本属于第 j 类的概率。由于one-hot形式的label中只有一个位置是为1,其他位置都为0,通过交叉熵公式后去掉 yi 为0的项后公式可以简化为
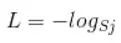
只保留剩下位置为1的那一项就OK了。
sparse_softmax_cross_entropy_with_logits 是 softmax_cross_entropy_with_logits 算法实现是一样的
*****所以在训练过程中,我们将 L 最小化。因为当Sj越接近于1的时候L进越接近于0,这就是我们优化训练最终目的。
五、binary_cross_entropy
此为二分‘;类的交叉熵,实际上是softmax_cross_entropy的一种特殊情况。
method1:利用softmax_cross_entropy_with_logits来计算二分类的交叉熵
method:条用逻辑回归的代价函数计算二分类的交叉熵

yi为正确值,hw(xi)为预测值
当 yi 为0的时候L= - log(1-hw(xi))这时候最小化L,则 1-hw(xi)会趋于1,即预测值趋于0
当yi为1的时候 L= - log (hw(xi)) 当最小化L的时候,则hw(xi) 趋于1 ,即预测值趋于1.
这就是训练优化原理。
六、sigmoid_cross_entropy
tensorflow中的函数sigmoid_cross_entropy_with_logits
用于测试每个独立且不相互排斥的离散分类任务中的概率。(可做多标签分类,它将one-hot形式代表 的label向量上的每一个值都当成一个二分类问题,eg:【1,0,1,0,0,0,1】,在每一个位置上都被视为一个二分类问题,这是一个数据项的多个标签类别)
比如一条法律案件可能触犯的法律条目有很多条。就是一种多标签问题。
这也是softmax_cross_entropy_with_logits 和 sigmoid_cross_entropy_logits的差别所在,
前者将整个label看成一个整体来进行计算,结果是整个维度的损失值;
后者将每一个元素都视为一个独立的单位,都是一个二分类问题,都有一个损失值。
声明:内容参考https://www.jianshu.com/p/47172eb86b39















 1489
1489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









