









手写数字识别
mnist——keras多层感知器识别手写数字
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hH7VWDuN-1570422464746)(C:\Users\72451\Desktop\MNIST数据集.png)]
1.进行数据预处理
导入所需模块
from keras.utils import np_utils
import numpy as np
np.random.seed(10)
读取MNIST数据集
from keras.datasets import mnist
(x_train_image, y_train_label),\
(x_test_image, y_test_label) = mnist.load_data()
将feature(数字图像特征值)使用reshape转换
将 28*28 转换为 784 个Float数
x_Train = x_train_image.reshape(60000, 784).astype('float32')
x_Test = x_test_image.reshape(10000, 784).astype('float32')
将features(数字图像特征值)标准化
提高准确度
x_Train_normalize = x_Train / 255
x_Test_normalize = x_Test / 255
lable(数字真实的值)以 One-hot Encoding 进行转换
y_Train_OneHot = np_utils.to_categorical(y_train_label)
y_Test_OneHot = np_utils.to_categorical(y_test_label)
2.建立模型
输入层有784个神经元,隐藏层有1000个神经元,输出层有10个神经元
导入需要模块
from keras.models import Sequential
from keras.layers import Dense
建立Sequential模型
建立一个线性堆叠模型
model = Sequential()
建立输入层,隐藏层
model.add(Dense(units = 1000, # 定义隐藏层神经元的个数为1000
input_dim = 784, # 设置输入层神经元个数为784
kernel_initializer = 'normal', # 使用 normal distribution 正态分布的随机数来初始化weight(权重)和 bias(偏差)
activation = 'relu')) # 定义激活函数relu(小于0的值为0,大于0的值不变)
建立输出层
加入Dense神经网络层,使用softmax激活函数进行转换,可以将神经元的输出转换为预测每一个数字的概率
model.add(Dense(units = 10, # 定义输出层的神经元一共有10个
kernel_initializer = 'normal', # 使用 normal distribution 正态分布的随机数来初始化 weight 和 bias
activation = 'softmax')) # 定义激活函数
#不需要设置input_dim,Keras会自动按照上一层的units是256个神经元,设置这一次的input_dim是256
查看模型的摘要
print(model.summary())
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 1000) 785000
_________________________________________________________________
dense_2 (Dense) (None, 10) 10010
=================================================================
Total params: 795,010
Trainable params: 795,010
Non-trainable params: 0
_________________________________________________________________
None
3.进行训练
定义训练方式
model.compile(loss = 'categorical_crossentropy', #设置损失函数(交叉熵损失函数)
optimizer = 'adam', # 优化器使用
metrics = ['accuracy'])
ps:
-
交叉熵刻画的是两个概率分布之间的距离,或可以说它刻画的是通过概率分布q来表达概率分布p的困难程度,p代表正确答案,q代表的是预测值,交叉熵越小,两个概率的分布约接近。
-
Adam优化算法的基本机制
Adam 算法和传统的随机梯度下降不同。随机梯度下降保持单一的学习率(即 alpha)更新所有的权重,学习率在训练过程中并不会改变。而 Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独的自适应性学习率。
优点:
高效的计算
所需内存少
梯度对角缩放的不变性(第二部分将给予证明)
适合解决含大规模数据和参数的优化问题
适用于非稳态(non-stationary)目标
适用于解决包含很高噪声或稀疏梯度的问题
超参数可以很直观地解释,并且基本上只需极少量的调参
开始训练
train_history = model.fit(x = x_Train_normalize, # 特征值
y = y_Train_OneHot, # 真实值
validation_split = 0.2, # 分割比例,将60000*0.8作为训练数据,60000*0.2作为验证数据
epochs = 10, # 设置训练周期
batch_size = 200, # 每批训练200个数据
verbose = 2) # 显示训练过程
Train on 48000 samples, validate on 12000 samples
Epoch 1/10
- 1s - loss: 0.4379 - accuracy: 0.8830 - val_loss: 0.2182 - val_accuracy: 0.9408
Epoch 2/10
- 1s - loss: 0.1908 - accuracy: 0.9454 - val_loss: 0.1557 - val_accuracy: 0.9553
Epoch 3/10
- 1s - loss: 0.1354 - accuracy: 0.9615 - val_loss: 0.1257 - val_accuracy: 0.9647
Epoch 4/10
- 1s - loss: 0.1026 - accuracy: 0.9703 - val_loss: 0.1118 - val_accuracy: 0.9683
Epoch 5/10
- 1s - loss: 0.0809 - accuracy: 0.9771 - val_loss: 0.0982 - val_accuracy: 0.9715
Epoch 6/10
- 1s - loss: 0.0658 - accuracy: 0.9820 - val_loss: 0.0932 - val_accuracy: 0.9725
Epoch 7/10
- 1s - loss: 0.0543 - accuracy: 0.9851 - val_loss: 0.0916 - val_accuracy: 0.9738
Epoch 8/10
- 1s - loss: 0.0458 - accuracy: 0.9876 - val_loss: 0.0830 - val_accuracy: 0.9762
Epoch 9/10
- 1s - loss: 0.0379 - accuracy: 0.9902 - val_loss: 0.0823 - val_accuracy: 0.9762
Epoch 10/10
- 1s - loss: 0.0315 - accuracy: 0.9916 - val_loss: 0.0811 - val_accuracy: 0.9762
测试
val_loss, val_acc = model.evaluate(x_Test_normalize, y_Test_OneHot, 1) # 评估模型对样本数据的输出结果
print(val_loss) # 模型的损失值
print(val_acc) # 模型的准确度
10000/10000 [==============================] - 4s 379us/step
0.07567812022235794
0.9760000109672546
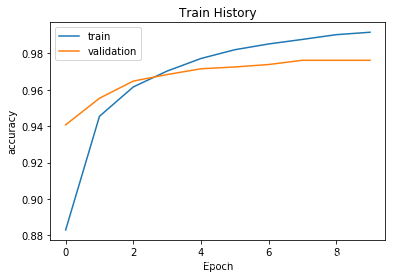
建立show_train_history 显示训练过程
import matplotlib.pyplot as plt
def show_train_history(train_history, train, validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc = 'upper left')
plt.show()
show_train_history(train_history, 'accuracy', 'val_accuracy')
# accuracy 是使用训练集计算准确度
# val_accuracy 是使用验证数据集计算准确度
4.实验参数
| 激活函数 | 神经元数量 | 训练平均运行时间 | 准确度 |
|---|---|---|---|
| relu | 256 | 1s | 0.9760 |
| relu | 1000 | 3-4s | 0.9801 |
| Sigmoid | 256 | 1s | 0.9645 |
| tanh | 256 | 1s | 0.9753 |
| rlu | 256 | 1s | 0.9749 |
| kernel_initializer | 准确度 |
|---|---|
| normal | 0.9760 |
| random_uniform | 0.9778 |
256个神经元
激活函数:relu
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 256) 200960
_________________________________________________________________
dense_2 (Dense) (None, 10) 2570
=================================================================
Total params: 203,530
Trainable params: 203,530
Non-trainable params: 0
_________________________________________________________________
None
Train on 48000 samples, validate on 12000 samples
Epoch 1/10
- 1s - loss: 0.4379 - accuracy: 0.8830 - val_loss: 0.2182 - val_accuracy: 0.9407
Epoch 2/10
- 1s - loss: 0.1909 - accuracy: 0.9454 - val_loss: 0.1559 - val_accuracy: 0.9555
Epoch 3/10
- 1s - loss: 0.1355 - accuracy: 0.9617 - val_loss: 0.1260 - val_accuracy: 0.9649
Epoch 4/10
- 1s - loss: 0.1027 - accuracy: 0.9704 - val_loss: 0.1119 - val_accuracy: 0.9683
Epoch 5/10
- 1s - loss: 0.0810 - accuracy: 0.9773 - val_loss: 0.0979 - val_accuracy: 0.9721
Epoch 6/10
- 1s - loss: 0.0659 - accuracy: 0.9817 - val_loss: 0.0936 - val_accuracy: 0.9722
Epoch 7/10
- 1s - loss: 0.0543 - accuracy: 0.9851 - val_loss: 0.0912 - val_accuracy: 0.9737
Epoch 8/10
- 1s - loss: 0.0460 - accuracy: 0.9877 - val_loss: 0.0830 - val_accuracy: 0.9767
Epoch 9/10
- 1s - loss: 0.0379 - accuracy: 0.9902 - val_loss: 0.0828 - val_accuracy: 0.9760
Epoch 10/10
- 1s - loss: 0.0316 - accuracy: 0.9917 - val_loss: 0.0807 - val_accuracy: 0.9769
测试:
10000/10000 [==============================] - 4s 374us/step
0.07602789112742801
0.9757999777793884
1000个神经元
激活函数:relu
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 1000) 785000
_________________________________________________________________
dense_2 (Dense) (None, 10) 10010
=================================================================
Total params: 795,010
Trainable params: 795,010
Non-trainable params: 0
_________________________________________________________________
None
Train on 48000 samples, validate on 12000 samples
Epoch 1/10
- 3s - loss: 0.2944 - accuracy: 0.9152 - val_loss: 0.1528 - val_accuracy: 0.9565
Epoch 2/10
- 3s - loss: 0.1179 - accuracy: 0.9661 - val_loss: 0.1073 - val_accuracy: 0.9678
Epoch 3/10
- 3s - loss: 0.0759 - accuracy: 0.9783 - val_loss: 0.0922 - val_accuracy: 0.9724
Epoch 4/10
- 3s - loss: 0.0514 - accuracy: 0.9853 - val_loss: 0.0869 - val_accuracy: 0.9733
Epoch 5/10
- 3s - loss: 0.0357 - accuracy: 0.9905 - val_loss: 0.0754 - val_accuracy: 0.9757
Epoch 6/10
- 4s - loss: 0.0257 - accuracy: 0.9932 - val_loss: 0.0743 - val_accuracy: 0.9778
Epoch 7/10
- 4s - loss: 0.0185 - accuracy: 0.9958 - val_loss: 0.0724 - val_accuracy: 0.9793
Epoch 8/10
- 4s - loss: 0.0132 - accuracy: 0.9971 - val_loss: 0.0718 - val_accuracy: 0.9778
Epoch 9/10
- 4s - loss: 0.0087 - accuracy: 0.9988 - val_loss: 0.0712 - val_accuracy: 0.9798
Epoch 10/10
- 4s - loss: 0.0062 - accuracy: 0.9992 - val_loss: 0.0705 - val_accuracy: 0.9800
测试:
10000/10000 [==============================] - 6s 569us/step
0.06873653566057918
0.9797999858856201
ps:有的时候能超过 0.98
激活函数:Sigmoid
256个神经元
摘要:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 256) 200960
_________________________________________________________________
dense_3 (Dense) (None, 10) 2570
=================================================================
Total params: 203,530
Trainable params: 203,530
Non-trainable params: 0
_________________________________________________________________
None
Train on 48000 samples, validate on 12000 samples
Epoch 1/10
- 1s - loss: 0.7395 - accuracy: 0.8315 - val_loss: 0.3386 - val_accuracy: 0.9109
Epoch 2/10
- 1s - loss: 0.3100 - accuracy: 0.9136 - val_loss: 0.2560 - val_accuracy: 0.9277
Epoch 3/10
- 1s - loss: 0.2492 - accuracy: 0.9290 - val_loss: 0.2233 - val_accuracy: 0.9381
Epoch 4/10
- 1s - loss: 0.2119 - accuracy: 0.9391 - val_loss: 0.1974 - val_accuracy: 0.9424
Epoch 5/10
- 1s - loss: 0.1835 - accuracy: 0.9466 - val_loss: 0.1757 - val_accuracy: 0.9517
Epoch 6/10
- 1s - loss: 0.1608 - accuracy: 0.9533 - val_loss: 0.1607 - val_accuracy: 0.9551
Epoch 7/10
- 1s - loss: 0.1424 - accuracy: 0.9593 - val_loss: 0.1489 - val_accuracy: 0.9587
Epoch 8/10
- 1s - loss: 0.1269 - accuracy: 0.9638 - val_loss: 0.1394 - val_accuracy: 0.9621
Epoch 9/10
- 1s - loss: 0.1141 - accuracy: 0.9677 - val_loss: 0.1291 - val_accuracy: 0.9634
Epoch 10/10
- 1s - loss: 0.1025 - accuracy: 0.9711 - val_loss: 0.1216 - val_accuracy: 0.9659
10000/10000 [==============================] - 4s 380us/step
0.11642538407448501
0.9645000100135803
效果明显差了很多
激活函数tanh
256个神经元
Train on 48000 samples, validate on 12000 samples
Epoch 1/10
- 1s - loss: 0.4394 - accuracy: 0.8801 - val_loss: 0.2483 - val_accuracy: 0.9302
Epoch 2/10
- 1s - loss: 0.2252 - accuracy: 0.9352 - val_loss: 0.1883 - val_accuracy: 0.9479
Epoch 3/10
- 1s - loss: 0.1681 - accuracy: 0.9514 - val_loss: 0.1556 - val_accuracy: 0.9580
Epoch 4/10
- 1s - loss: 0.1313 - accuracy: 0.9631 - val_loss: 0.1374 - val_accuracy: 0.9603
Epoch 5/10
- 1s - loss: 0.1064 - accuracy: 0.9704 - val_loss: 0.1214 - val_accuracy: 0.9652
Epoch 6/10
- 1s - loss: 0.0876 - accuracy: 0.9763 - val_loss: 0.1140 - val_accuracy: 0.9668
Epoch 7/10
- 1s - loss: 0.0728 - accuracy: 0.9802 - val_loss: 0.1063 - val_accuracy: 0.9694
Epoch 8/10
- 1s - loss: 0.0610 - accuracy: 0.9837 - val_loss: 0.0951 - val_accuracy: 0.9731
Epoch 9/10
- 1s - loss: 0.0510 - accuracy: 0.9870 - val_loss: 0.0926 - val_accuracy: 0.9721
Epoch 10/10
- 1s - loss: 0.0426 - accuracy: 0.9894 - val_loss: 0.0866 - val_accuracy: 0.9738
10000/10000 [==============================] - 4s 371us/step
0.08017727720420531
0.9753999710083008
激活函数 rlu(Exponential Linear Units)
256个神经元
Train on 48000 samples, validate on 12000 samples
Epoch 1/10
- 1s - loss: 0.4413 - accuracy: 0.8773 - val_loss: 0.2636 - val_accuracy: 0.9261
Epoch 2/10
- 1s - loss: 0.2476 - accuracy: 0.9284 - val_loss: 0.2049 - val_accuracy: 0.9422
Epoch 3/10
- 1s - loss: 0.1849 - accuracy: 0.9471 - val_loss: 0.1645 - val_accuracy: 0.9557
Epoch 4/10
- 1s - loss: 0.1423 - accuracy: 0.9593 - val_loss: 0.1424 - val_accuracy: 0.9599
Epoch 5/10
- 1s - loss: 0.1139 - accuracy: 0.9676 - val_loss: 0.1232 - val_accuracy: 0.9658
Epoch 6/10
- 1s - loss: 0.0936 - accuracy: 0.9734 - val_loss: 0.1140 - val_accuracy: 0.9674
Epoch 7/10
- 1s - loss: 0.0781 - accuracy: 0.9778 - val_loss: 0.1070 - val_accuracy: 0.9692
Epoch 8/10
- 1s - loss: 0.0670 - accuracy: 0.9807 - val_loss: 0.0976 - val_accuracy: 0.9720
Epoch 9/10
- 1s - loss: 0.0570 - accuracy: 0.9839 - val_loss: 0.0939 - val_accuracy: 0.9725
Epoch 10/10
- 1s - loss: 0.0485 - accuracy: 0.9868 - val_loss: 0.0880 - val_accuracy: 0.9740
10000/10000 [==============================] - 4s 374us/step
0.07968259554752871
0.9749000072479248















 2183
2183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









