







实验:Keras 多层感知器 手写数字识别
【因为该博文修改过,增添了相应的代码,模型建立模块不再是简单的拥有 “256个神经元” 的隐藏层,已将隐藏层的神经元修改为 “1000个神经元”(可自行修改),并增加了 “隐藏层2” 、增添了Dropou功能。所以 “拓展” 部分了解即可。】
【具体过程还需大家自行体验, 所以大家可以自己尝试着运行】
【本博文仅供参考,仅限于学术交流】
1. 下载 MNIST数据集(前提)
- 导入Keras及相关模块
#导入相关模块
import numpy as np
import pandas as pd
from keras.utils import np_utils
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
import matplotlib.pyplot as plt
np.random.seed(10)
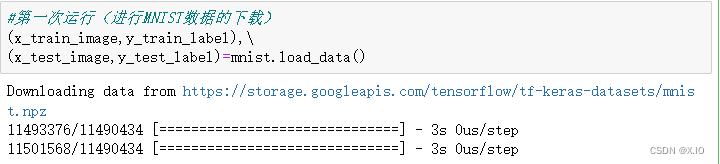
- 第一次运行(进行MNIST数据的下载)【如果已经下载数据集,可以省略该步骤】
(x_train_image,y_train_label),\
(x_test_image,y_test_label)=mnist.load_data()
"""
第一次执行mnist.loat_data()方法,程序会检查用户目录下是否已经有MNIST数据集文件,如果还没有,就会下载文件。
因为必须要下载文件,所以运行时间比较长。
"""
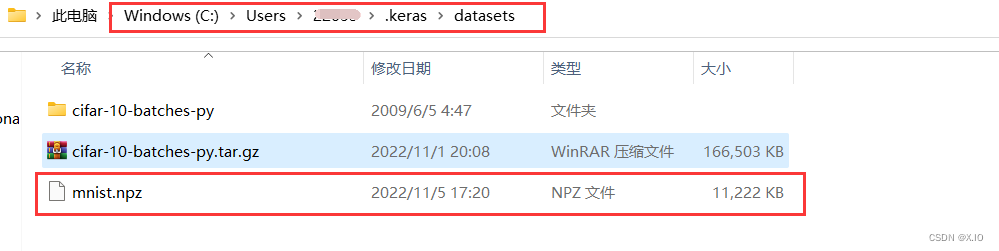
- 查看下载的MNIST数据文件
MNIST数据文件下载后会存储在用户个人的文件夹中,所以下载后会存储在目录【C:\Users\用户名称.keras\datasets】中,文件名是mnist.npz,
- 读取 &查看 MNIST 数据
#读取 MNIST数据
(x_train_image,y_train_label), \
(x_test_image,y_test_labe) = mnist.load_data()
"""
当再次执行 mnist.load_data()时,
由于之前已经下载文件,因此不需要再进行下载,只需要读取文件,这样运行速度就会快很多。
"""
#查看 MNIST数据
print('train data=',len(x_train_image))
print('test data=',len(x_test_image))
"""
下载后,可以使用上述指令查看MNIST数据集的数据项数。
"""

从执行结果可知,数据分为两部分:
·train 训练数据 60000项
·test 测试数据 10000项
- 查看训练数据
#1.查看训练数据
print('x_train_image:',x_train_image.shape)
print('y_train_labe:',y_train_label.shape)
#2.定义Plot_image函数,为了能够显示images数字图像。
def plot_image(image):
#设置显示图形的大小
fig = plt.gcf()
fig.set_size_inches(2,2)
#使用plt.imshow显示图形,传入参数image是28×28的图形,cmap参数设置为binary,以黑白灰度显示。
plt.imshow(image,cmap='binary')
#开始绘图
plt.show()
#3.执行plot_image函数查看第0个数字图像
plot_image(x_train_image[0])
#4.查看第0项label数据
y_train_label[0]
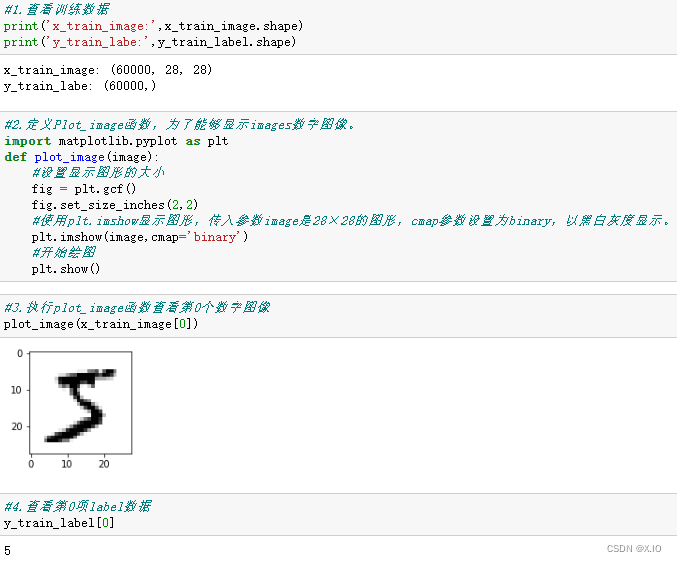
6. 查看多项训练数据
#查看多项训练数据images与label
#1.创建plot_images_labels_prediction()函数
def plot_images_labels_prediction(images,labels,prediction,idx,num=10):
#images(数字图像)、label(真实值)、prediction(预测结果)、idx(开始显示的数据index)、num(要显示的数据项数,默认是10,不超过25)。
#设置显示图形的大小
fig = plt.gcf()
fig.set_size_inches(12,14)
#如果显示项数参数大于25,就设置为25,以免发生错误
if num>25: num =25
#for循环执行程序块内的程序代码,画出num个数字图形。
for i in range(0,num):
#建立subgraph子图形为5行5列
ax=plt.subplot(5,5,1+i)
#画出subgraph子图形
ax.imshow(images[idx],cmap='binary')
#设置子图形title,显示标签字段
title="label="+str(labels[idx])
#如果传入了预测结果
if len(prediction)>0:
#标题title加入预测结果
title+=",predict="+str(prediction[idx])
#设置子图形的标题title与大小
ax.set_title(title,fontsize=10)
#设置不显示刻度
ax.set_xticks([]);ax.set_yticks([])
#读取下一项
idx+=1
#开始画图
plt.show()
#2.查看训练数据前10项数据
plot_images_labels_prediction(x_train_image,y_train_label,[],0,10)


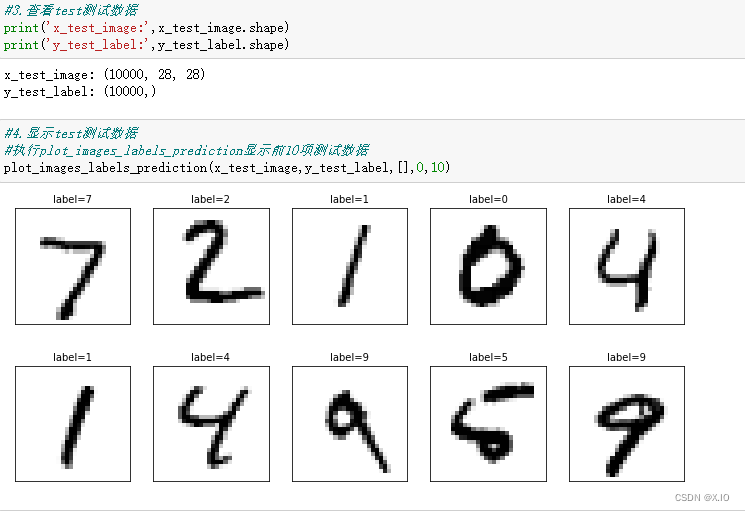
7. 查看测试数据
#3.查看test测试数据
print('x_test_image:',x_test_image.shape)
print('y_test_label:',y_test_label.shape)
#4.显示test测试数据
#执行plot_images_labels_prediction显示前10项测试数据
plot_images_labels_prediction(x_test_image,y_test_label,[],0,10)
2. 进行数据预处理
#1.将features(数字图像特征值)使用reshape转换
x_Train = x_train_image.reshape(60000,784).astype('float32')
x_Test = x_test_image.reshape(10000,784).astype('float32')
#2.将features(数字图像特征值)标准化
x_Train_normalize =x_Train/255
x_Test_normalize =x_Test/255
#3.label(数字真实的值)以One-Hot Encoding进行转换
y_Train_OneHot = np_utils.to_categorical(y_train_label)
y_Test_OneHot = np_utils.to_categorical(y_test_label)

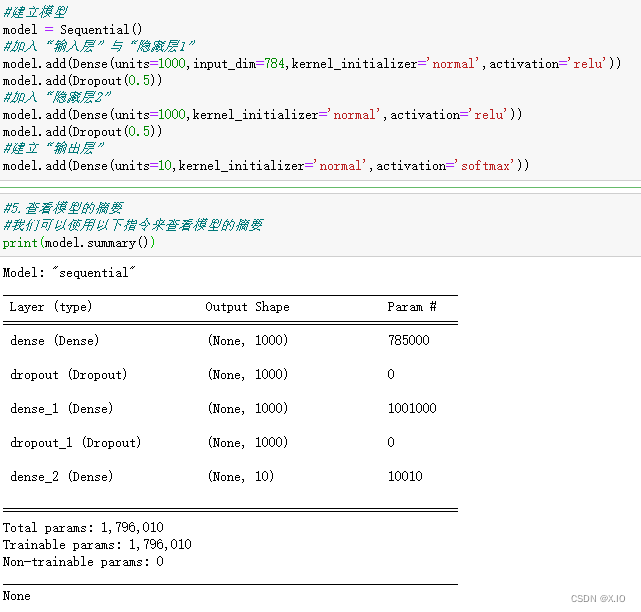
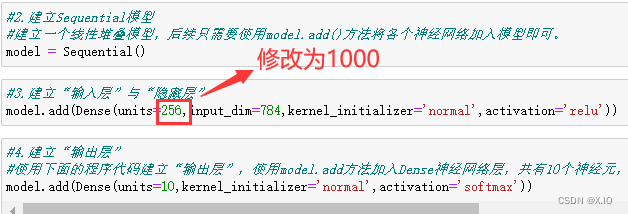
3. 建立模型
#建立模型
model = Sequential() #建立一个线性堆叠模型,后续只需要使用model.add()方法将各个神经网络加入模型即可。
#加入“输入层”与“隐藏层1”
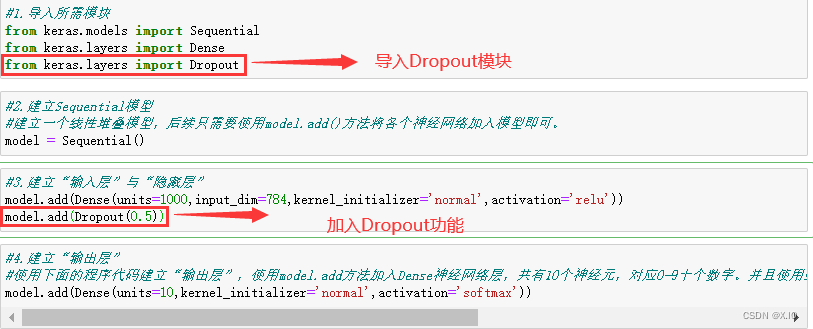
model.add(Dense(units=1000,input_dim=784,kernel_initializer='normal',activation='relu'))
model.add(Dropout(0.5))
#加入“隐藏层2”
model.add(Dense(units=1000,kernel_initializer='normal',activation='relu'))
model.add(Dropout(0.5))
#建立“输出层”
model.add(Dense(units=10,kernel_initializer='normal',activation='softmax')) #使用下面的程序代码建立“输出层”,使用model.add方法加入Dense神经网络层,共有10个神经元,对应0-9十个数字。并且使用softmax激活函数进行转换,softmax可以将神经元的输出转换为预测每一个数字的概率。
#5.查看模型的摘要
#我们可以使用以下指令来查看模型的摘要
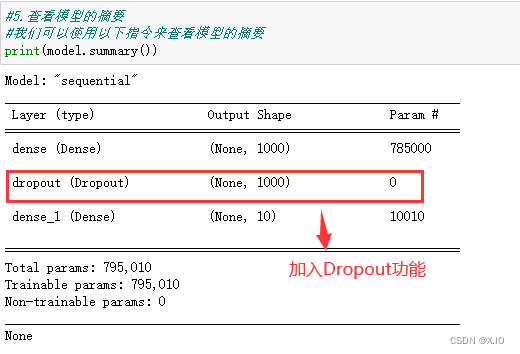
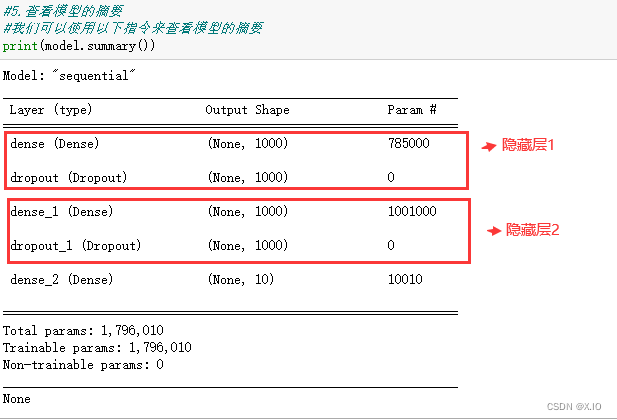
print(model.summary())
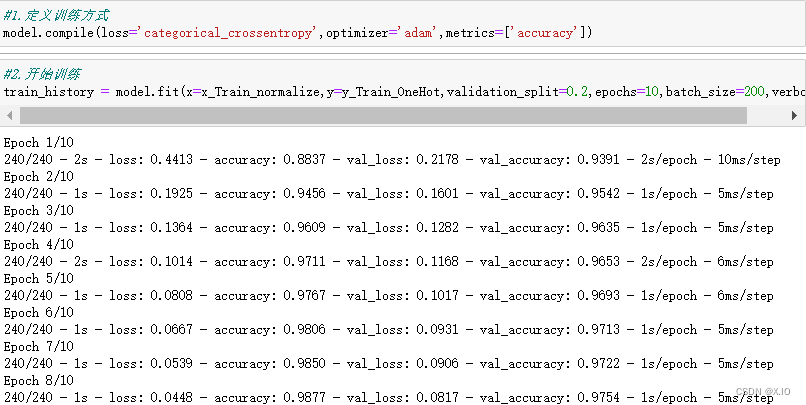
4. 进行训练
#1.定义训练方式
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
#2.开始训练
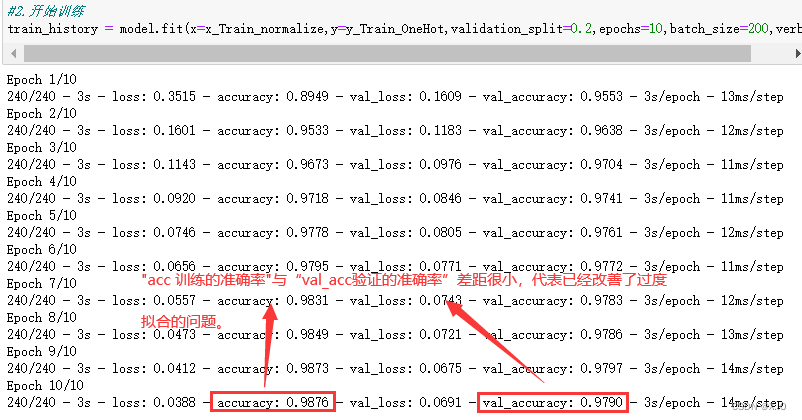
train_history = model.fit(x=x_Train_normalize,y=y_Train_OneHot,validation_split=0.2,epochs=10,batch_size=200,verbose=2)
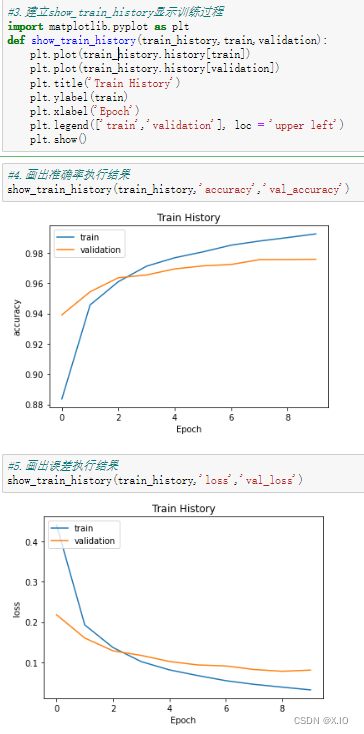
#3.建立show_train_history显示训练过程
def show_train_history(train_history,train,validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train','validation'], loc = 'upper left')
plt.show()
#4.画出准确率执行结果
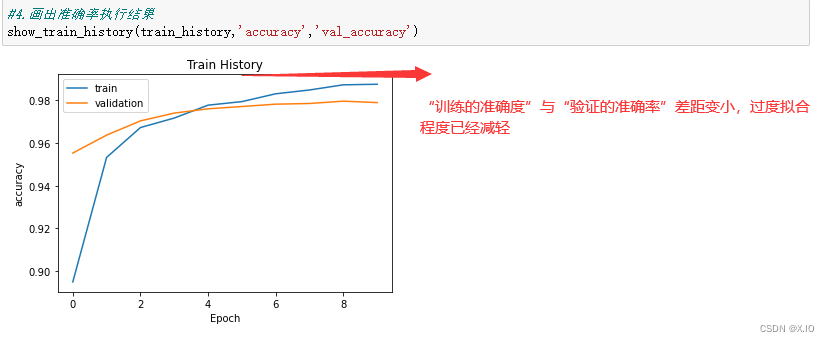
show_train_history(train_history,'accuracy','val_accuracy')
#5.画出误差执行结果
show_train_history(train_history,'loss','val_loss')
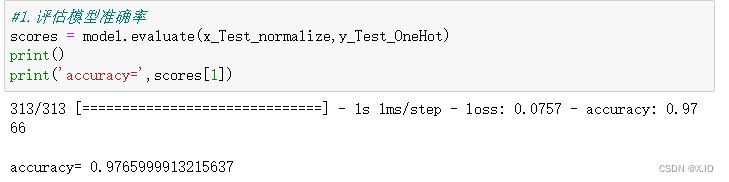
5. 以测试数据评估模型
#1.评估模型准确率
scores = model.evaluate(x_Test_normalize,y_Test_OneHot)
print()
print('accuracy=',scores[1])
6. 进行预测
#1.执行预测
predict_x=model.predict(x_Test)
classes_x=np.argmax(predict_x,axis=1)
prediction = classes_x
print(prediction)
len(prediction)
#2.预测结果
prediction
#3.显示10项预测结果
plot_images_labels_prediction(x_test_image,y_test_label,prediction,idx=340)
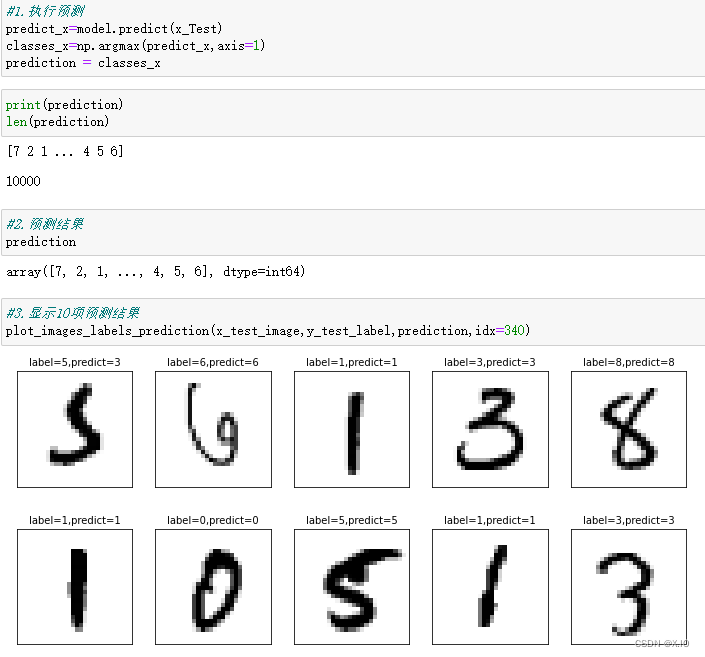
根据执行结果,我们可以看到有一项预测错误:label(真实值)是5,但predict(预测值)是3。但是第一个手写数字图像确实潦草,会识别错误也情有可原。
拓展:
1. 显示混淆矩阵
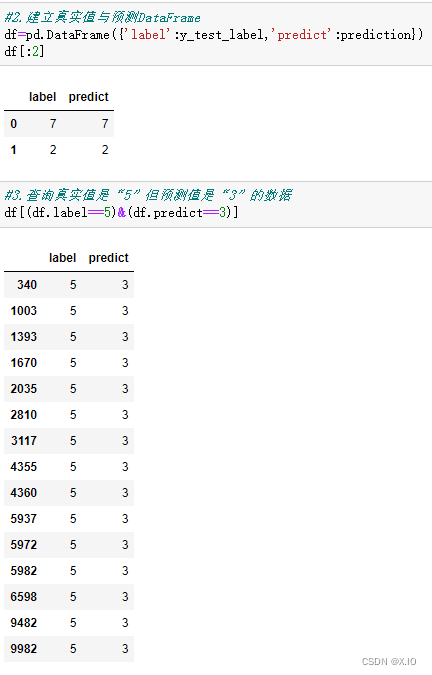
在机器学习领域,特别是统计分类的问题,混淆矩阵也称为误差矩阵(error matrix)是一种特定的表格显示方式,可以让我们以可视化的方式了解有监督的学习算法的结果,看出算法模型是否混淆了两个类(将某一个标签预测成为另一个标签)
如果想要进一步知道在所建立的模型中哪些数字的预测准确率最高,哪些数字最容易混淆(例如真实值是5,但是预测值是3),就可以使用混淆矩阵(confusion matrix)来显示。


2. 隐藏层增加1000个神经元
1.将隐藏层原本256个神经元改为1000个神经元
2. 查看模型的摘要

3. 开始训练
共执行了10个训练周期,可以发现误差也来越小,准确率越来越高
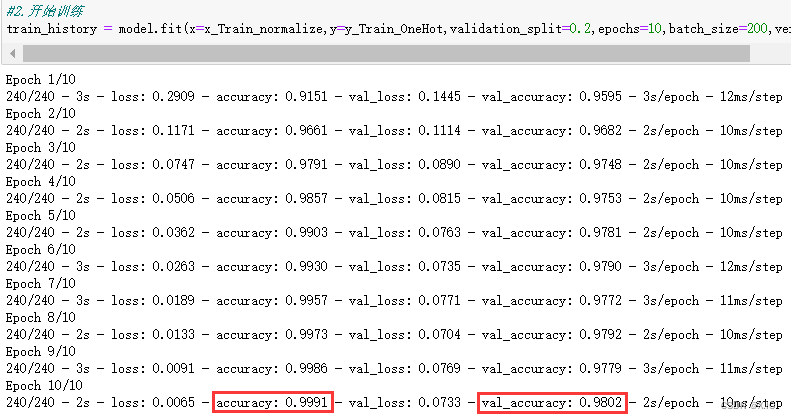
4. 查看训练过程的准确率
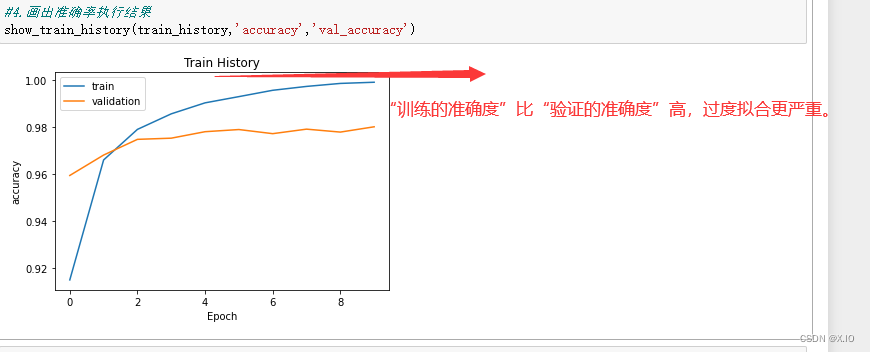
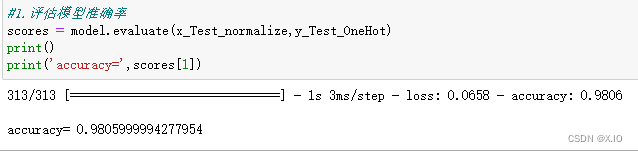
5. 预测准确率
3. 多层感知器加入DropOut 功能以避免过度拟合
- 修改隐藏层加入DropOut功能
- 查看模型的摘要
- 查看训练过程的准确率
- 图示训练过程的准确率
- 查看准确率

从执行结果可知准确率是0.9825,比之前未加入Dropout 时还高,这代表加入了Dropout 不但可以解决过度拟合的问题,还可以增加准确率。
4. 建立多层感知器模型包含两个隐藏层
- 加入两个隐藏层并且加入Dropout 功能

- 查看模型的摘要
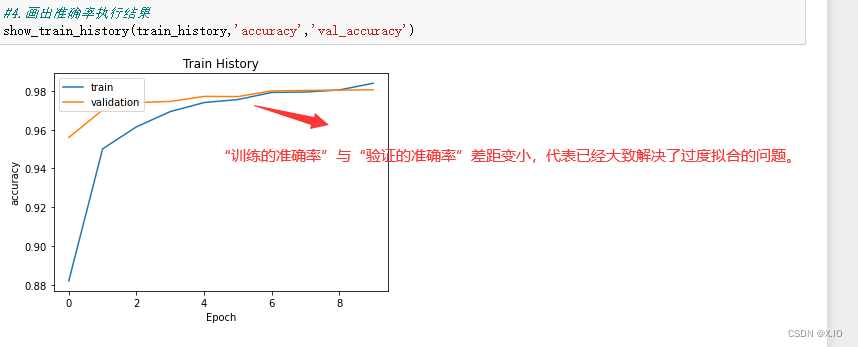
- 查看训练过程的准确率
- 查看准确率

从以上执行结果可知准确率是0.9797,准确率并没有显著提升。
总结:
本次实验,主要使用多层感知器模型来识别 MNIST数据集中的手写数字,并尝试将模型加宽、加深,以提高准确率,并且加入Drop层,以避免过度拟合,准确率接近0.98。
不过,多层感知器有其极限,如果还想进一步提升准确率,可以考虑使用卷积神经网络。
















 5073
5073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











