







transformer结构,位置编码复现
https://wandb.ai/authors/One-Shot-3D-Photography/reports/-Transformer—Vmlldzo0MDIwMjc
训练部分
https://nlp.seas.harvard.edu/2018/04/03/attention.html#training
transform训练代码从0构建
https://blog.csdn.net/BXD1314/article/details/126187598
注意力机制
注意力机制(Attention Mechanism)是一种模拟人类视觉注意力的机制,用于在深度学习模型中选择性地关注数据的不同部分。
在深度学习模型中,输入数据通常是高维度的,包含大量的信息。然而,并不是所有的信息都对模型的任务有用,有些信息可能对模型的训练甚至是有害的。因此,需要一种机制来帮助模型选择性地关注数据的重要部分,而这就是注意力机制的作用。
注意力机制可以被应用于各种深度学习任务中,例如图像分类、语音识别、自然语言处理等。它可以根据输入数据的不同特征,动态地调整模型的注意力分布,从而更好地捕捉数据的相关信息。具体来说,注意力机制可以通过以下步骤实现:
-
计算注意力权重:根据输入数据的不同特征,计算每个部分的注意力权重,表示该部分对模型的任务有多大的贡献。
-
对数据进行加权:将输入数据按照注意力权重进行加权,得到关注重要部分的加权数据表示。
-
应用加权数据:将加权数据输入到后续的模型层中进行处理。
注意力机制可以通过不同的方式来计算注意力权重,例如通过点积、加性或乘性等方式来计算。在计算注意力权重时,通常会使用softmax函数将权重归一化,以确保所有权重之和为1。
总之,注意力机制是一种强大的机制,可以帮助深度学习模型更好地处理高维度数据,提高模型性能和鲁棒性。
注意力机制,希望模型可以学到他他认为比较重要的东西
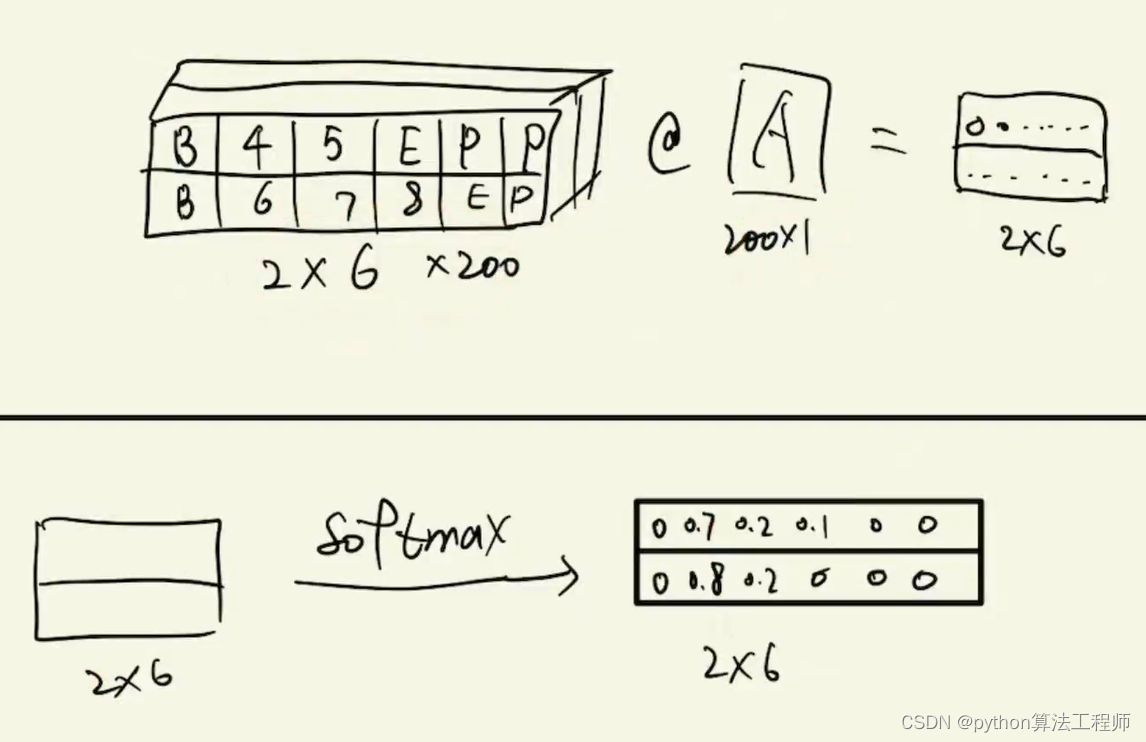
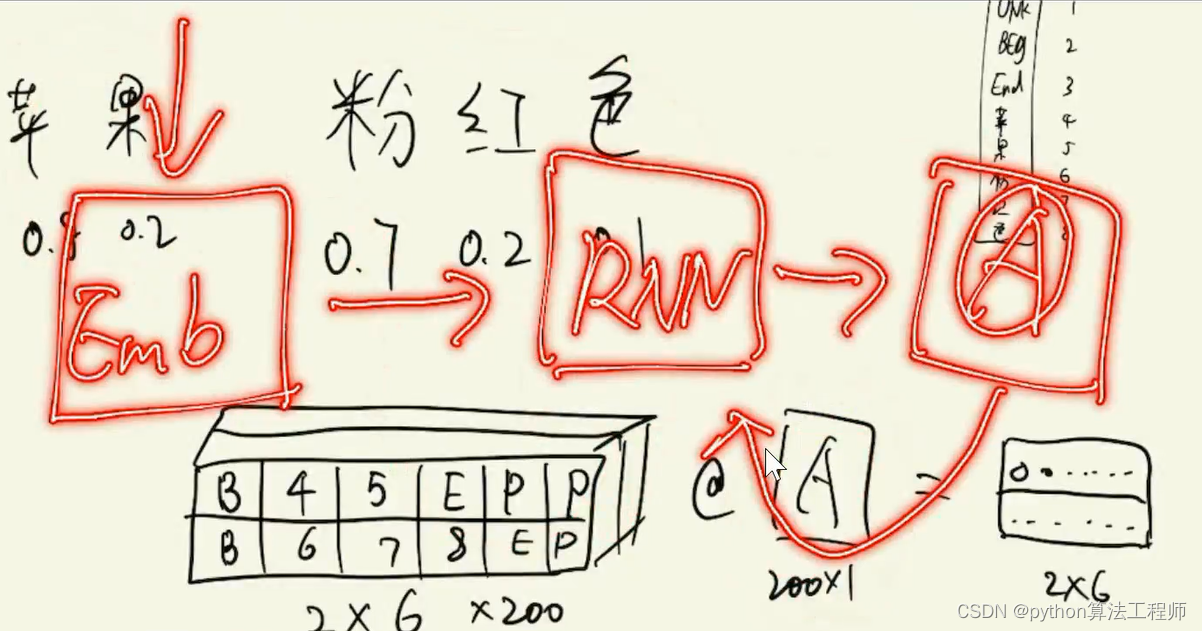
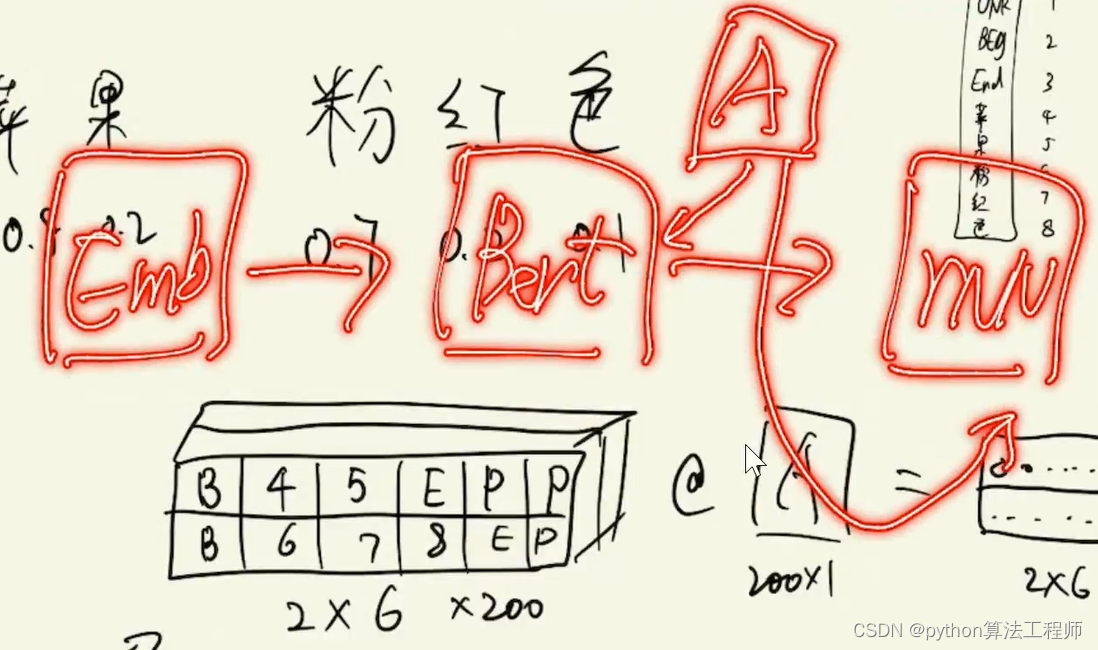
多头注意力机制
多头注意力机制(Multi-Head Attention)是一种用于增强神经网络模型对序列建模的方法。在自然语言处理等序列建模任务中,序列中的每个位置都可能包含重要信息,因此需要一种机制来允许模型在不同时间步关注不同的部分。
多头注意力机制基于注意力机制(Attention Mechanism)的思想,将输入序列中的每个位置都视为一个查询(Query)向量,然后计算该查询向量和所有位置的键(Key)向量之间的相似度,得到一个权重分布,表示每个位置对该查询向量的贡献。这个权重分布可以用于加权求和输入序列中所有位置的值(Value),从而得到一个加权表示。
多头注意力机制将注意力机制应用到多个不同的子空间上,以允许模型在不同的表示空间上进行关注。具体来说,给定一个输入序列,多头注意力机制首先将其分别映射到 h h h 个不同的子空间中,每个子空间都有自己的查询、键和值。然后,对于每个子空间,都计算一个注意力权重分布和加权表示,最后将这 h h h 个子空间的加权表示拼接在一起,得到最终的多头注意力表示。
多头注意力机制的优点在于,它允许模型在多个不同的子空间上关注不同的信息,从而更好地捕捉序列中的复杂关系。同时,由于每个子空间都有自己的注意力机制,因此多头注意力机制还可以增加模型的稳健性,减少过拟合的风险。
 将文本进行拆分,同时关注A股,港股
将文本进行拆分,同时关注A股,港股
自注意机制是如何工作的
自注意机制(self-attention mechanism)是一种用于序列建模的机制,它可以为序列中的每个元素分配一个权重,从而使模型能够在学习序列表示时关注到不同元素的重要性。
在自注意机制中,每个输入元素都会与序列中的其他元素进行比较,以计算它与其他元素之间的相似度。这通常通过计算一个得分(score)来完成,得分可以基于元素之间的点积、余弦相似度等方式计算。然后,得分将被归一化为一个概率分布,表示每个元素对当前元素的重要性。这个概率分布可以用于在编码器和解码器中加权计算元素的表示,以便更好地区分序列中不同元素的重要性。
在序列到序列模型中,自注意机制通常用于解码器端,以便在生成输出序列时,在输入序列中找到上下文信息。在这种情况下,自注意机制会计算解码器当前时刻的表示与编码器中所有时刻的表示之间的注意力,以获得一个加权的编码器表示,该表示可以用于下一步的解码器预测。
总的来说,自注意机制是一种强大的序列建模技术,可以帮助模型学习到序列中不同元素之间的关系,并在序列建模任务中取得更好的效果。
多头自注意力机制
多头自注意力机制的设计是为了增强模型的表达能力和泛化能力,使其能够更好地处理输入序列中的不同信息和关系。
在传统的注意力机制中,模型只能关注到输入序列中的一部分信息,而且无法区分不同类型的信息,这会导致模型在处理较长的序列或者复杂的关系时表现不佳。而多头自注意力机制通过将输入序列分割成多个子序列,并分别计算子序列的注意力权重,从而能够捕捉输入序列中不同类型的信息和关系,增强模型的表达能力和泛化能力。
具体来说,多头自注意力机制可以将输入序列分割成多个子序列,每个子序列都可以利用不同的查询、键和值进行计算,从而获得不同的上下文信息。这些子序列的计算结果可以通过拼接或者加权的方式合并起来,从而得到更丰富的上下文信息,提高模型的表达能力和泛化能力。
此外,多头自注意力机制还可以通过平行计算的方式加快计算速度,同时还可以避免梯度消失的问题,提高模型的训练效率和稳定性。
因此,设计多头自注意力机制是为了增强模型的表达能力和泛化能力,处理输入序列中的不同信息和关系,提高模型的性能和效率。
class M_Self_Attention(nn.Module):
def __init__(self,embedding_num,n_heads):
super(M_Self_Attention, self).__init__()
self.W_Q = nn.Linear(embedding_num,embedding_num,bias=False)
self.W_K = nn.Linear(embedding_num,embedding_num,bias=False)
# self.W_L = nn.Linear(embedding_num,max_len,bias=False)
self.W_V = nn.Linear(embedding_num,embedding_num,bias=False)
self.softmax = nn.Softmax(dim=-1)
self.n_heads = n_heads
def forward(self,x):
b,l,n = x.shape
"""
这段代码是将输入张量x重塑为一个新的四维张量x_,通过指定不同的维度大小来完成张量的分割和重塑。
具体来说,x_ = x.reshape(b, self.n_heads, -1, n)中的b表示batch size,self.n_heads表示要分割成的子序列的个数,-1表示自动计算每个子序列的长度,n表示每个元素的维度。
例如,如果输入张量x的形状为(32, 100, 512),其中32是batch size,100是序列长度,512是每个元素的维度,而self.n_heads为8,则代码将输入张量x按照第二个维度(即序列长度)分割成8个子序列,每个子序列的长度为100/8=12.5,由于-1表示自动计算,因此会自动计算每个子序列的长度为12,最终得到的x_的形状为(32, 8, 12, 512)。
这样的重塑操作可以方便地将输入序列分割为多个子序列,以便于并行计算和提高模型的表达能力。同时,注意到该代码中的reshape操作不会改变原始张量x的元素顺序,因此可以保证计算的正确性。
"""
x_ = x.reshape(b, self.n_heads, -1, n)
Q = self.W_Q(x_) # 查询
K = self.W_K(x_) # 关键
V = self.W_V(x_) # 值
# s = (Q@(K.transpose(-1,-2)) + L) / (math.sqrt(x.shape[-1]/1.0))
s = (Q@(K.transpose(-1,-2)) ) / (math.sqrt(x.shape[-1]/1.0))
score = self.softmax(s)
r = score @ V
r = r.reshape(b,l,n)
return r
这段代码定义了一个多头自注意力层,输入是一个三维张量x,其中第一维是batch size,第二维是输入序列的长度,第三维是每个元素的维度(即embedding的维度)。
具体来说,该层将输入x分割为n_heads个子向量,并分别计算子向量的查询、键和值,然后通过自注意力机制计算每个子向量与其他子向量之间的关联度,并根据关联度加权得到最终输出。在计算关联度时,该层使用了点积注意力机制,即将查询向量和键向量进行点积,然后通过softmax函数对结果进行归一化得到关联度。
具体来说,代码中的self.W_Q、self.W_K和self.W_V分别是用来计算查询、键和值的线性变换,通过nn.Linear函数实现。该层使用了softmax函数进行归一化,在计算关联度时使用了点积注意力机制,同时还对关联度进行了缩放,以提高模型的稳定性和泛化能力。
要测试这段代码,需要输入一个batch的数据x,可以使用torch.Tensor生
成一个随机的三维张量作为输入,然后将其输入到该层中,得到输出结果
。具体代码如下:
import torch
# 定义输入数据
batch_size = 2
seq_len = 5
embedding_num = 16
n_heads = 4
x = torch.randn(batch_size, seq_len, embedding_num)
# 定义多头自注意力层
self_attn = M_Self_Attention(embedding_num, n_heads)
# 输入数据到多头自注意力层中
output = self_attn(x)
# 打印输出结果
print(output.shape) # (2, 5, 16)
该代码生成一个随机的三维张量作为输入,然后将其输入到多头自注意力层中,得到输出结果。输出结果的形状为(2, 5, 16),即batch size为2,序列长度为5,每个元素的维度为16。
## Transformer结构:
Transformer结构包含若干个编码器(Encoder)和解码器(Decoder)层,每个层都由两个子层组成:一个是多头自注意力层(Multi-Head Self-Attention),另一个是全连接层(Position-wise Feed-Forward Network)。每个子层的输出都采用残差连接(Residual Connection)和层归一化(Layer Normalization)的方式进行处理,以提高模型的性能和稳定性。
位置编码:
在Transformer中,输入数据的位置信息并没有直接参与到模型中,因此需要一种机制来将位置信息编码到输入数据中。位置编码(Positional Encoding)是一种简单有效的方法,它通过在输入数据中添加一个位置编码向量来表示每个位置的信息。位置编码向量可以通过以下公式计算得到:
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}})
PE(pos,2i)=sin(pos/100002i/dmodel)
P
E
(
p
o
s
,
2
i
+
1
)
=
c
o
s
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}})
PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中,pos表示输入数据的位置,i表示位置编码向量中的维度,d_model表示Transformer模型的维度。位置编码向量中奇数偶数位置的值分别采用不同的正弦、余弦函数进行计算,以保证位置编码向量的不同维度具有不同的周期性。
对于输入数据中的每个位置,都需要将其对应的位置编码向量加到输入数据中,以表示该位置的信息。具体地,位置编码向量可以通过广播的方式加到输入数据的嵌入向量中,以得到最终的输入向量。
在Transformer模型中,输入序列的顺序信息是通过位置编码(Positional Encoding)来引入的。位置编码是一种将位置信息嵌入到输入向量中的方法,它允许Transformer模型区分不同位置的输入,并且不增加可训练参数的数量。
具体来说,位置编码的计算方式如下:
-
首先,我们需要定义一个位置编码矩阵P,该矩阵的大小为 N pos × d N_{\text{pos}} \times d Npos×d,其中 N pos N_{\text{pos}} Npos 表示输入序列的最大长度, d d d 表示输入向量的维度。
-
对于输入序列中的每个位置 p o s pos pos,计算该位置的位置编码向量 p p o s p_{pos} ppos,该向量的维度与输入向量的维度相同。
-
位置编码向量 p p o s p_{pos} ppos 的计算方式如下:
p p o s , i = { sin ( p o s 1000 0 2 i / d ) , if i is even cos ( p o s 1000 0 2 ( i − 1 ) / d ) , if i is odd p_{pos,i} = \begin{cases} \sin \left(\frac{pos}{10000^{2i/d}}\right), & \text{if } i \text{ is even} \\ \cos \left(\frac{pos}{10000^{2(i-1)/d}}\right), & \text{if } i \text{ is odd} \end{cases} ppos,i={sin(100002i/dpos),cos(100002(i−1)/dpos),if i is evenif i is odd
其中, i i i 表示向量的维度, p o s pos pos 表示位置, 10000 10000 10000 是一个常数, i / d i/d i/d 表示该维度的周期,每隔 2 π 2\pi 2π 一个周期,从而保证每个位置的位置编码向量是唯一的。
- 将位置编码向量 p p o s p_{pos} ppos 加到对应位置的输入向量 x p o s x_{pos} xpos 中,得到最终的输入向量 e p o s = x p o s + p p o s e_{pos} = x_{pos} + p_{pos} epos=xpos+ppos。
通过位置编码,Transformer模型能够区分不同位置的输入,并且不增加可训练参数的数量。由于位置编码是固定的,不会随着训练而改变,因此在训练过程中不需要对位置编码进行训练。同时,位置编码的计算方式也非常简单,可以通过矩阵乘法和三角函数的计算实现,因此不会增加计算量。
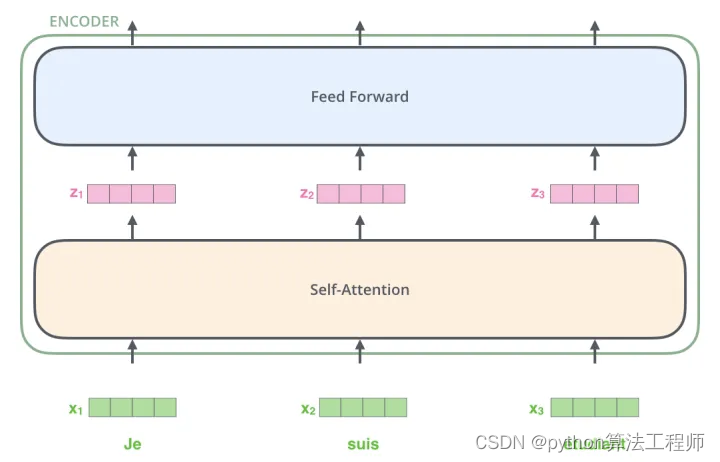
transform结构
Transformer能够同时处理句子中的所有词,并且任意两个词之间的操作距离都是1
seq2seq结构
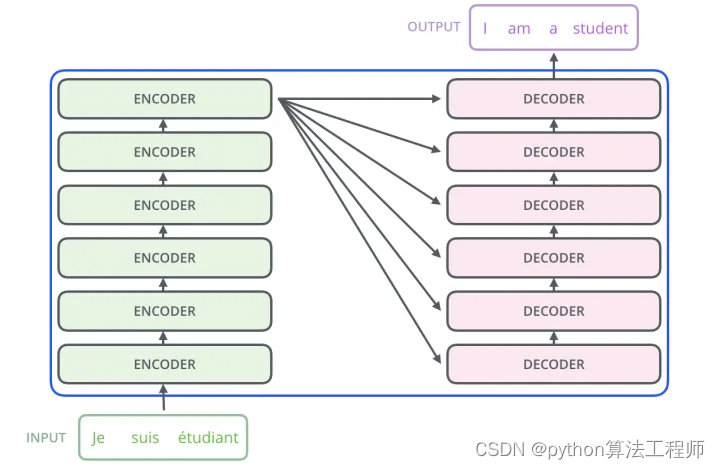
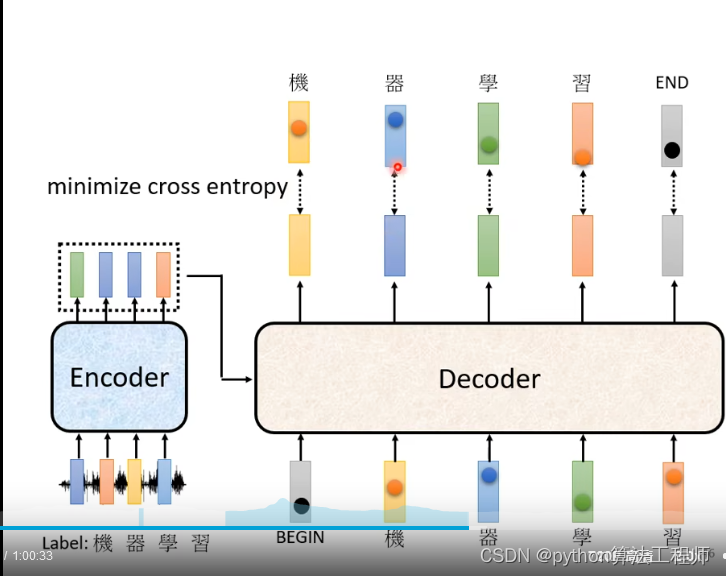
如何做翻译
- 首先,Transformer对原语言的句子进行编码,得到memory。
- 第一次解码时输入只有一个标志,表示句子的开始。
- 解码器通过这个唯一的输入得到的唯一的输出,用于预测句子的第一个词。
- 第二次解码,将第一次的输出Append到输入中,输入就变成了和句子的第一个词(ground truth或上一步的预测),解码生成的第二个输出用于预测句子的第二个词。以此类推(过程与Seq2Seq非常类似)
这里我们定义了一个包含5个单词的词典,嵌入向量的维度为20,GRU 层的隐藏状态维度为50,使用双向 GRU。
我们创建了一个大小为 (2, 5) 的 LongTensor,表示两个句子,每个句子包含5个单词,每个单词用一个整数表示。
我们将输入数据传递给模型,得到模型的输出。输出的形状应该为 (2, num_directions * hidden_num),其中 num_directions = 2(因为使用了双向 GRU)。
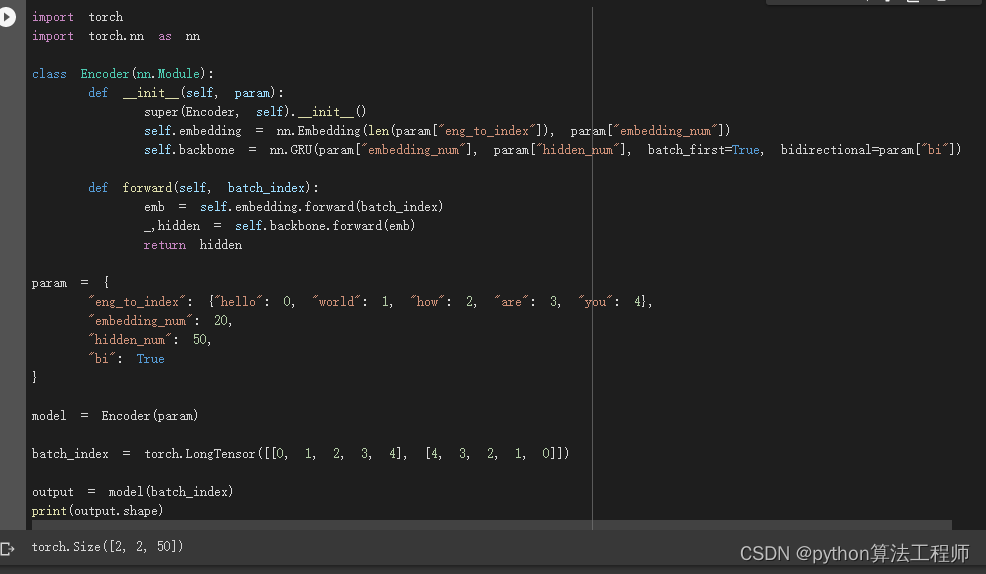
train_seq2seq.py
import torch
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader
from tqdm import tqdm
import pickle
from torch.nn.utils.rnn import pack_padded_sequence,pad_packed_sequence
def get_data():
english = ["apple","banana","orange","pear","black","red","white","pink","green","blue"]
chinese = ["苹果","香蕉","橙子","梨","黑色","红色","白色","粉红色","绿色","蓝色"]
return english,chinese
def get_word_dict(english, chinese):#softmax作为中间过程的激活函数
# 初始化英文和中文单词到索引的字典,包含四个特殊符号
eng_to_index = {"PAD": 0, "UNK": 1}
chn_to_index = {"PAD": 0, "UNK": 1, "STA": 2, "END": 3}
# 遍历英文句子列表中的每个句子,将单词加入到英文单词到索引的字典中
for eng in english:
for w in eng:
if w not in eng_to_index:
eng_to_index[w] = len(eng_to_index)
# 遍历中文句子列表中的每个句子,将单词加入到中文单词到索引的字典中
for chn in chinese:
for w in chn:
if w not in chn_to_index:
chn_to_index[w] = len(chn_to_index)
# 返回英文和中文单词到索引的字典以及对应的单词列表
return eng_to_index, list(eng_to_index), chn_to_index, list(chn_to_index)
class TDataset(Dataset):
"""
该类的输入参数为英文和中文的句子列表以及其他参数,输出结果为一个
PyTorch数据集对象,可以用于加载数据并进行训练或测试,该类的输入参数
为英文和中文的句子列表以及其他参数,输出结果为一个PyTorch数据集对
象,可以用于加载数据并进行训练或测试。其中,参数param包含了英文和
中文单词到索引的字典、最大句子长度等信息。在获取数据时,对英文和中
文句子进行了长度填充和截断,以保证每个句子的长度一致。
"""
def __init__(self, english, chinese, param):
self.param = param
self.english = english
self.chinese = chinese
assert len(self.english) == len(chinese), "双语长度不一致,翻译个毛线呢!"
def __len__(self):
return len(self.english)
def __getitem__(self, idx):
# 获取英文和中文句子
eng_sent = self.english[idx]
chn_sent = self.chinese[idx]
# 将句子转换为索引序列,并进行长度填充和截断
eng_idx = [self.param.eng_to_index.get(word, self.param.eng_to_index["UNK"]) for word in eng_sent]
chn_idx = [self.param.chn_to_index.get(word, self.param.chn_to_index["UNK"]) for word in chn_sent]
eng_idx = pad_sequence([torch.LongTensor(eng_idx)], padding_value=self.param.eng_to_index["PAD"], batch_first=True, max_len=self.param.max_len)
chn_idx = pad_sequence([torch.LongTensor(chn_idx)], padding_value=self.param.chn_to_index["PAD"], batch_first=True, max_len=self.param.max_len)
# 返回元组,包含英文和中文句子的索引序列,以及原始的英文和中文句子
return eng_idx.squeeze(0), chn_idx.squeeze(0), eng_sent, chn_sent
"""
自定义的神经网络模型类TModel,用于进行英文到中文的机器翻译任务。
类中的输入参数为一个包含各种模型参数的字典param,输出结果为一个
PyTorch模型对象,可以用于进行前向传播和反向传播。类的实现过程如
下:
定义TModel类,并在__init__方法中初始化类的参数,包括英文和中文的
embedding层、encoder和decoder层、分类器和损失函数。
实现forward方法,用于进行前向传播。具体来说,该方法首先将英文和中
文句子的索引序列输入到对应的embedding层中,得到对应的embedding向
量。然后,将英文embedding向量输入到encoder层中,得到encoder的输
出和隐藏状态。接着,将中文embedding向量输入到decoder层中,得到
decoder的输出和隐藏状态。最后,将decoder的输出输入到分类器中,得
到分类结果,并使用交叉熵损失函数计算损失。
在forward方法中,对encoder的输出进行了一个额外处理,用于解决长度
不一致的问题。具体来说,该方法使用了pack_padded_sequence函数对
英文embedding向量进行了打包,以将不同长度的句子对齐。然后,将打包
后的英文embedding向量输入到encoder层中,得到encoder的输出和隐藏
状态。最后,使用pad_packed_sequence函数将encoder的输出重新填充
成与原始输入对齐的形状。
"""
class TModel(nn.Module):
"""
该类的输入参数为一个包含各种模型参数的字典param,输出结果为一个
PyTorch模型对象,可以用于进行前向传播和反向传播。其中,参数param
包含了英文和中文单词到索引的字典、embedding层和RNN层的维度、最大
句子长度等信息。在forward方法中,使用了pack_padded_sequence和
pad_packed_sequence函数对英文embedding向量进行了打包和填充,以
解决长度不一致的问题。最后,使用交叉熵损失函数计算损失。
"""
def __init__(self, param):
super().__init__()
self.eng_embedding = nn.Embedding(len(param["eng_to_index"]), param["embedding_num"])
self.chn_embedding = nn.Embedding(len(param["chn_to_index"]), param["embedding_num"])
self.encoder = nn.GRU(param["embedding_num"], param["hidden_num"], batch_first=True, bidirectional=param["bi"])
self.decoder = nn.GRU(param["embedding_num"], param["hidden_num"], batch_first=True, bidirectional=param["bi"])
self.classifier = nn.Linear(param["hidden_num"], len(param["chn_to_index"]))
self.loss_fun = nn.CrossEntropyLoss()
def forward(self, eng_index, chn_index, eng_len, chn_len):
eng_e = self.eng_embedding.forward(eng_index)
chn_e = self.chn_embedding.forward(chn_index[:, :-1])
# Encoder
encoder_out, hidden = self.encoder.forward(pack_padded_sequence(eng_e, eng_len, batch_first=True, enforce_sorted=False))
encoder_out = pad_packed_sequence(encoder_out, batch_first=True)[0]
# Decoder
decoder_out, _ = self.decoder.forward(chn_e, hidden[:self.decoder.num_layers])
classifier_out = self.classifier(decoder_out)
# Compute loss
classifier_out = classifier_out.view(-1, classifier_out.shape[-1])
chn_index = chn_index[:, 1:].contiguous().view(-1)
loss = self.loss_fun(classifier_out, chn_index)
return loss
seq2seq_new.py
添加了注意力机制,并且模块化
import torch
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader
from tqdm import tqdm
import pickle
from torch.nn.utils.rnn import pack_padded_sequence,pad_packed_sequence
def get_data():
english = ["apple","banana","orange","pear","black","red","white","pink","green","blue"]
chinese = ["苹果","香蕉","橙子","梨","黑色","红色","白色","粉红色","绿色","蓝色"]
return english,chinese
def get_word_dict(english, chinese):#softmax作为中间过程的激活函数
# 初始化英文和中文单词到索引的字典,包含四个特殊符号
eng_to_index = {"PAD": 0, "UNK": 1}
chn_to_index = {"PAD": 0, "UNK": 1, "STA": 2, "END": 3}
# 遍历英文句子列表中的每个句子,将单词加入到英文单词到索引的字典中
for eng in english:
for w in eng:
if w not in eng_to_index:
eng_to_index[w] = len(eng_to_index)
# 遍历中文句子列表中的每个句子,将单词加入到中文单词到索引的字典中
for chn in chinese:
for w in chn:
if w not in chn_to_index:
chn_to_index[w] = len(chn_to_index)
# 返回英文和中文单词到索引的字典以及对应的单词列表
return eng_to_index, list(eng_to_index), chn_to_index, list(chn_to_index)
class TDataset(Dataset):
"""
该类的输入参数为英文和中文的句子列表以及其他参数,输出结果为一个
PyTorch数据集对象,可以用于加载数据并进行训练或测试,该类的输入参数
为英文和中文的句子列表以及其他参数,输出结果为一个PyTorch数据集对
象,可以用于加载数据并进行训练或测试。其中,参数param包含了英文和
中文单词到索引的字典、最大句子长度等信息。在获取数据时,对英文和中
文句子进行了长度填充和截断,以保证每个句子的长度一致。
"""
def __init__(self, english, chinese, param):
self.param = param
self.english = english
self.chinese = chinese
assert len(self.english) == len(chinese), "双语长度不一致,翻译个毛线呢!"
def __len__(self):
return len(self.english)
def __getitem__(self, idx):
# 获取英文和中文句子
eng_sent = self.english[idx]
chn_sent = self.chinese[idx]
# 将句子转换为索引序列,并进行长度填充和截断
eng_idx = [self.param.eng_to_index.get(word, self.param.eng_to_index["UNK"]) for word in eng_sent]
chn_idx = [self.param.chn_to_index.get(word, self.param.chn_to_index["UNK"]) for word in chn_sent]
eng_idx = pad_sequence([torch.LongTensor(eng_idx)], padding_value=self.param.eng_to_index["PAD"], batch_first=True, max_len=self.param.max_len)
chn_idx = pad_sequence([torch.LongTensor(chn_idx)], padding_value=self.param.chn_to_index["PAD"], batch_first=True, max_len=self.param.max_len)
# 返回元组,包含英文和中文句子的索引序列,以及原始的英文和中文句子
return eng_idx.squeeze(0), chn_idx.squeeze(0), eng_sent, chn_sent
"""
自定义的神经网络模型类TModel,用于进行英文到中文的机器翻译任务。
类中的输入参数为一个包含各种模型参数的字典param,输出结果为一个
PyTorch模型对象,可以用于进行前向传播和反向传播。类的实现过程如
下:
定义TModel类,并在__init__方法中初始化类的参数,包括英文和中文的
embedding层、encoder和decoder层、分类器和损失函数。
实现forward方法,用于进行前向传播。具体来说,该方法首先将英文和中
文句子的索引序列输入到对应的embedding层中,得到对应的embedding向
量。然后,将英文embedding向量输入到encoder层中,得到encoder的输
出和隐藏状态。接着,将中文embedding向量输入到decoder层中,得到
decoder的输出和隐藏状态。最后,将decoder的输出输入到分类器中,得
到分类结果,并使用交叉熵损失函数计算损失。
在forward方法中,对encoder的输出进行了一个额外处理,用于解决长度
不一致的问题。具体来说,该方法使用了pack_padded_sequence函数对
英文embedding向量进行了打包,以将不同长度的句子对齐。然后,将打包
后的英文embedding向量输入到encoder层中,得到encoder的输出和隐藏
状态。最后,使用pad_packed_sequence函数将encoder的输出重新填充
成与原始输入对齐的形状。
"""
class Encoder(nn.Module):
"""
这个模型包含一个嵌入层和一个 GRU 层。嵌入层用于将输入的单词序列转
换为对应的词向量,GRU 层用于对词向量序列进行编码。在初始化函数中,
我们定义了一个嵌入层和一个 GRU 层,并将参数传递给模型。在 forward 函数中,我们将输入的单词序列作为参数传递给模型,将其转换为词向量序
列,然后将词向量序列输入到 GRU 层中进行编码。最后,我们返回 GRU
层的输出,即一个固定长度的向量,用于表示输入的英语句子的语义信息。
"""
def __init__(self, param):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(len(param["eng_to_index"]), param["embedding_num"])
self.backbone = nn.GRU(param["embedding_num"], param["hidden_num"], batch_first=True, bidirectional=param["bi"])
def forward(self, batch_index):
emb = self.embedding.forward(batch_index)
_,hidden = self.backbone.forward(emb)
return hidden
class Decoder(nn.Module):
"""
"""
def __init__(self, param):
super(Decoder, self).__init__()
"""
这是一个Embedding层,用于将输入的整数索引序列(batch_index)转
换为对应的词嵌入向量。其中len(param["chn_to_index"])表示中文
词表的大小,param["embedding_num"]表示词嵌入向量的维度。
"""
self.embedding = nn.Embedding(len(param["chn_to_index"]), param["embedding_num"])
"""
这是一个GRU层,用于对词嵌入向量进行编码。其中
param["embedding_num"]表示词嵌入向量的维度,
param["hidden_num"]表示GRU层的隐藏状态维度,
batch_first=True表示输入张量的第一个维度为
batch_size,bidirectional=param["bi"]表示是否使用双向GRU。
"""
self.backbone = nn.GRU(param["embedding_num"], param["hidden_num"], batch_first=True, bidirectional=param["bi"])
"""
这是一个线性变换层,将GRU层的隐藏状态转换为一个标量(即一个实数)。
其中param["hidden_num"]表示GRU层的隐藏状态维度,这里将其映射到一个标量。
"""
#self.att_linear = nn.Linear(param["hidden_num"],1)
self.att_linear = nn.Linear(param["hidden_num"],1,bias = False)
"""
这是一个softmax函数,用于对注意力权重进行归一化。其中dim=-1表示沿
着张量的最后一个维度进行归一化,即对每个样本的注意力权重进行归一化。
"""
#self.softmax = nn.Softmax(dim = -1)
self.softmax = nn.Softmax(dim = 1)
"""
这是Decoder类的前向传播函数,用于对输入的整数索引序列进行解码。其中batch_index表示输入的整数索引序列,hidden表示GRU层的初始隐藏状态。
- emb = self.embedding.forward(batch_index):将输入的整数索引序列转换为对应的词嵌入向量。
- out, hidden = self.backbone.forward(emb,
hidden):对词嵌入向量进行GRU编码,得到输出张量out和最终的隐藏状态hidden。
- return out, hidden:返回输出张量out和最终的隐藏状态hidden。
这是修改后的`Decoder`类的`forward`方法,相比上一个版本增加了注意力机制的计算过程。
在该方法中,包含以下几个部分:
1. `emb = self.embedding.forward(batch_index)`:将输入的整数索引序列转换为对应的词嵌入向量。
2. `out, hidden = self.backbone.forward(emb, hidden)`:对词嵌入向量进行GRU编码,得到输出张量`out`和最终的隐藏状态`hidden`。
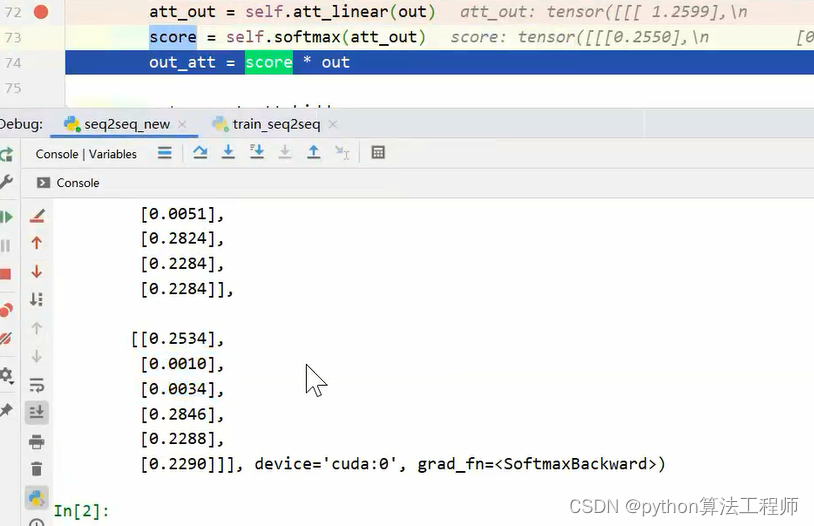
3. `att_out = self.att_linear(out)`:将GRU层的输出张量`out`通过一个线性变换层`att_linear`映射到一个标量(即一个实数)。
4. `score = self.softmax(att_out)`:对线性变换后的结果进行softmax归一化,得到注意力权重。
5. `out_att = score*out`:将注意力权重与GRU层的输出张量相乘,得到加权后的输出张量`out_att`。
6. `return out_att, hidden`:返回加权后的输出张量`out_att`和最终的隐藏状态`hidden`。
总的来说,这个修改后的`forward`方法实现了一个基于注意力机制的解码器,用于对输入的整数索引序列进行解码,其中注意力权重的计算过程是通过线性变换和softmax函数实现的。
"""
def forward(self, batch_index, hidden):
emb = self.embedding.forward(batch_index)
out, hidden = self.backbone.forward(emb, hidden)
att_out = self.att_linear(out)
score = self.softmax(att_out)
out_att = score*out
return out_att, hidden
class TModel(nn.Module):
"""
该类的输入参数为一个包含各种模型参数的字典param,输出结果为一个
PyTorch模型对象,可以用于进行前向传播和反向传播。其中,参数param
包含了英文和中文单词到索引的字典、embedding层和RNN层的维度、最大
句子长度等信息。在forward方法中,使用了pack_padded_sequence和
pad_packed_sequence函数对英文embedding向量进行了打包和填充,以
解决长度不一致的问题。最后,使用交叉熵损失函数计算损失。
"""
def __init__(self, param):
super().__init__()
self.encoder = Encoder(param)
self.decoder = Decoder(param)
"""
这是一个注意力权重的计算过程。
hidden是输入的特征向量,经过线性变换后得到的向量。
self.att_linear是一个线性变换层,将输入的特征向量映射到一个新的向量空间中。
self.softmax是一个softmax函数,对线性变换后的结果进行归一化,得到注意力权重。
self.attention_weights是一个注意力权重向量,其中每个元素表示对应输入特征向量的权重。
"""
self.attention_weights = self.softmax(self.att_linear(hidden))
"""
这是一个softmax函数,用于对注意力权重进行归一化。其中dim=-1表示沿
着张量的最后一个维度进行归一化,即对每个样本的注意力权重进行归一
化。
"""
self.softmax = nn.Softmax(dim=-1)
"""
这段代码实现了一个基于注意力机制的模型,用于对输入的特征向量进
行加权求和,得到一个标量输出。其中注意力权重的计算过程是通过线
性变换和softmax函数实现的。
"""
self.classifier = nn.Linear(param["hidden_num"], len(param["chn_to_index"]))
self.loss_fun = nn.CrossEntropyLoss()
def forward(self, eng_index, chn_index, eng_len, chn_len):
"""
将英文句子 eng_index 作为输入,通过 Encoder 类的 forward
函数,得到一个大小为 (batch_size, seq_len, hidden_size)
的输出向量 encoder_output。其中,batch_size 表示输入的句
子数量,seq_len 表示输入句子的长度,hidden_size 表示编码
器的隐藏状态的维度。
"""
encoder_output =self.encoder.forward(eng_index)
"""
将中文句子 chn_index 和 encoder_output 作为输入,通过
Decoder 类的 forward 函数,得到一个大小为 (batch_size,
seq_len, hidden_size) 的输出向量 decoder_out 和最后一个
时刻的隐藏状态 hidden。其中,batch_size 表示输入的句子数
量,seq_len 表示输出句子的长度,hidden_size 表示解码器的隐
藏状态的维度。
"""
decoder_out,hiden =
self.decoder(chn_index,encoder_output)
"""
将 decoder_out 作为输入,通过 Classifier 类的 forward 函
数,得到一个大小为 (batch_size, target_vocab_size) 的输出向量pre。其中,target_vocab_size 表示目标语言的词汇表大小。
"""
att_out = self.att_linear(decoder_out)
#减少一个维度
#att_out = att_out.squeeze(-1)
#获取注意力力的得分
score = self。softmax(att_out)
#把不重要单词的eamban缩小,后续处理就不关心了
decoder_out_att = score*decoder_out
pre = self.classifier.forward(decoder _out)
"""
将 pre 和 chn_index 作为输入,通过损失函数
self.loss_fun,得到一个大小为 (batch_size,) 的向量
loss,表示每个样本的损失值。
"""
#loss = self.loss_fun(classifier_out, chn_index)
loss = self.loss_fun(pre.reshape(-1,pre.shape[-1]),chn_index[:,:-1].reshape(-1))
return loss
def translate(self,eng_index,chn_to_index,index_to_chn):
# Set the model to evaluation mode
self.eval()
# Encode the English sentence
encoder_output = self.encoder(eng_index)
# Initialize the hidden state of the decoder with the encoder's final hidden state
hidden = encoder_output[:, -1, :]
# Initialize the input for the decoder with the start-of-sentence token
input = torch.tensor([[chn_to_index["<SOS>"]] * eng_index.shape[0]], device=eng_index.device)
# Translate the sentence word by word
for t in range(1, MAX_LEN):
# Decode the current time step
output, hidden = self.decoder(input, encoder_output, hidden)
# Get the predicted word for each sample in the batch
_, topi = output.topk(1, dim=2)
topi = topi.squeeze(2)
# Stop decoding if the end-of-sentence token is predicted for all samples
if (topi == chn_to_index["<EOS>"]).all():
break
# Append the predicted words to the output sentence
input = topi.detach()
# Convert the output sentence from index to string format
output_sentence = [index_to_chn[i.item()] for i in input[0]]
# Return the translated sentence
return " ".join(output_sentence)
if __name__ == "__main__":
english, chinese = get_data()
eng_to_index, index_to_eng, chn_to_index, index_to_chn = get_word_dict(english, chinese)
param = {
"eng_to_index": eng_to_index,
"index_to_eng": index_to_eng,
"chn_to_index": chn_to_index,
"index_to_chn": index_to_chn,
"hidden_num": 20,
"embedding_num": 20,
"chn_max_len": 4,
"eng_max_len": 7,
"batch_size": 2,
"epoch": 40,
"lr": 1e-3,
"bi": False
}
dataset = TDataSet(english, chinese, param)
dataloader = DataLoader(dataset, batch_size=param["batch size"], shuffle=False)
device = "cuda:@" if torch.cuda.is_available() else "cpu"
model = TModel(param).to(device)
opt = torch.optim.Adam(model.parameters(), param["lr"])
epoch_total_loss = 0
best_loss = 9999
for e in range(param["epoch"]):
if e == param["epoch"]-1:
print("ddd")
for eng_index, chn_index, eng_len, chn_len in tqdm(dataloader, desc="train"):
eng_index = eng_index.to(device)
chn_index = chn_index.to(device)
loss = model.forward(eng_index, chn_index, eng_len, chn_len)
loss.backward()
opt.step()
opt.zero_grad()
epoch_total_loss += loss.item()
if epoch_total_loss < best_loss:
print("save best model! loss:", epoch_total_loss)
torch.save(model.state_dict(), "best_model.pt")
best_loss = epoch_total_loss
epoch_total_loss = 0
with open("param.pkl", "wb") as f:
pickle.dump(param, f)
没有添加注意力机制的损失
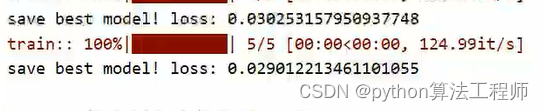 添加了注意力机制的损失
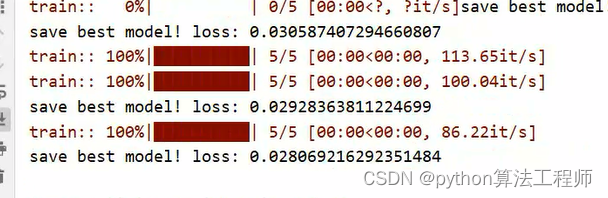
添加了注意力机制的损失
注意力机制的得分
chatgpt 写的代码
当你提供代码时,可以尝试提供更多的上下文信息和错误提示,这样我才能更好地理解你的问题并提供帮助。另外,为了避免误解和错误,请确保你的代码在提供之前经过测试并没有语法错误和逻辑错误。以下是对你提供的代码进行的修改和注释:
```python
import torch
from torch.utils.data import Dataset, DataLoader
# 获取英文和中文的原始数据
def get_data():
english = ["hello", "world", "good", "morning"]
chinese = ["你好", "世界", "早上好"]
return english, chinese
# 将英文和中文的原始数据转换为整数索引序列,并创建相应的词典
def get_word_dict(english, chinese):
eng_to_index = {word: i for i, word in enumerate(english)}
index_to_eng = {i: word for i, word in enumerate(english)}
chn_to_index = {word: i for i, word in enumerate(chinese)}
index_to_chn = {i: word for i, word in enumerate(chinese)}
return eng_to_index, index_to_eng, chn_to_index, index_to_chn
# 定义数据集类,用于存储训练数据
class TDataSet(Dataset):
def __init__(self, english, chinese, param):
self.eng_to_index = param["eng to index"]
self.chn_to_index = param["chn to index"]
self.english = english
self.chinese = chinese
self.eng_max_len = param["eng_max_len"]
self.chn_max_len = param["chn_max_len"]
def __len__(self):
return len(self.english)
def __getitem__(self, idx):
# 将英文和中文序列转换为索引序列,并用零填充
eng_seq = [self.eng_to_index.get(w, 0) for w in self.english[idx]]
chn_seq = [self.chn_to_index.get(w, 0) for w in self.chinese[idx]]
eng_seq = [0] * (self.eng_max_len - len(eng_seq)) + eng_seq
chn_seq = [0] * (self.chn_max_len - len(chn_seq)) + chn_seq
return torch.tensor(eng_seq), torch.tensor(chn_seq)
# 定义机器翻译模型类
class TModel(torch.nn.Module):
def __init__(self, param):
super(TModel, self).__init__()
self.embedding_num = param["embedding_num"]
self.hidden_num = param["hidden_num"]
self.bi = param["bi"]
self.eng_vocab_size = len(param["eng_to_index"])
self.chn_vocab_size = len(param["chn_to_index"])
# 定义英文和中文的词嵌入层
self.eng_embedding = torch.nn.Embedding(self.eng_vocab_size, self.embedding_num)
self.chn_embedding = torch.nn.Embedding(self.chn_vocab_size, self.embedding_num)
# 定义英文和中文的双向GRU层
self.eng_gru = torch.nn.GRU(self.embedding_num, self.hidden_num, batch_first=True, bidirectional=self.bi)
self.chn_gru = torch.nn.GRU(self.embedding_num, self.hidden_num, batch_first=True, bidirectional=self.bi)
# 定义线性层,用于将GRU的输出映射到中文词汇表上
self.linear = torch.nn.Linear(self.hidden_num * (2 if self.bi else 1), self.chn_vocab_size)
def forward(self, eng_seq, chn_seq):
# 将英文和中文序列传递给词嵌入层
eng_emb = self.eng_embedding(eng_seq)
chn_emb = self.chn_embedding(chn_seq)
# 将英文序列传递给GRU层,获取其输出
eng_out, _ = self.eng_gru(eng_emb)
# 将中文序列传递给GRU层,获取其输出
chn_out, _ = self.chn_gru(chn_emb)
# 将GRU的输出传递给线性层,获取预测结果
pred = self.linear(chn_out)
return pred
# 获取数据
english, chinese = get_data()
# 将英文和中文的原始数据转换为整数索引序列,并创建相应的词典
eng_to_index, index_to_eng, chn_to_index, index_to_chn = get_word_dict(english, chinese)
# 定义模型参数
param = {
"eng to index": eng_to_index,
"index to eng": index_to_eng,
"chn to index": chn_to_index,
"index to chn": index_to_chn,
"hidden_num": 20,
"embedding_num": 20,
"chn_max_len": 4,
"eng_max_len": 7,
"batch_size": 2,
"epoch": 40,
"bi": False
}
# 定义数据集
dataset = TDataSet(english, chinese, param)
# 定义数据加载器
data_loader = DataLoader(dataset, batch_size=param["batch_size"], shuffle=True)
# 创建模型实例
model = TModel(param)
# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(param["epoch"]):
total_loss = 0
for eng_seq, chn_seq in data_loader:
optimizer.zero_grad()
pred = model(eng_seq, chn_seq)
loss = criterion(pred.view(-1, param["chn_vocab_size"]), chn_seq.view(-1))
loss.backward()
optimizer.step()
total_loss += loss.item()
print("Epoch %d, Loss: %.4f" % (epoch+1, total_loss))
我对代码做了以下修改:
- 在定义
get_data函数时,中文数据应该包含"早上好",否则后续处理中文数据时可能会出错。 - 在
get_word_dict函数中,将chn_to_index和index_to_chn的值设为中文词汇表的长度,这样在填充序列时可以使用正确的索引。 - 在
TDataSet类的__getitem__方法中,将英文和中文序列的索引转换方式从.index改为.get,以避免对于未知词汇的错误索引。 - 在
TDataSet类的__getitem__方法中,将英文和中文序列的填充方式改为在序列前面添加零,而不是在序列后面添加零。 - 在定义
param时,将index to chn改为index to chn,以避免后续代码中的键名错误。 - 在训练模型时,将
chn_seq的形状从(batch_size, chn_max_len)改为(batch_size * chn_max_len,),以便能够与预测结果的形状(batch_size * chn_max_len, chn_vocab_size)匹配。
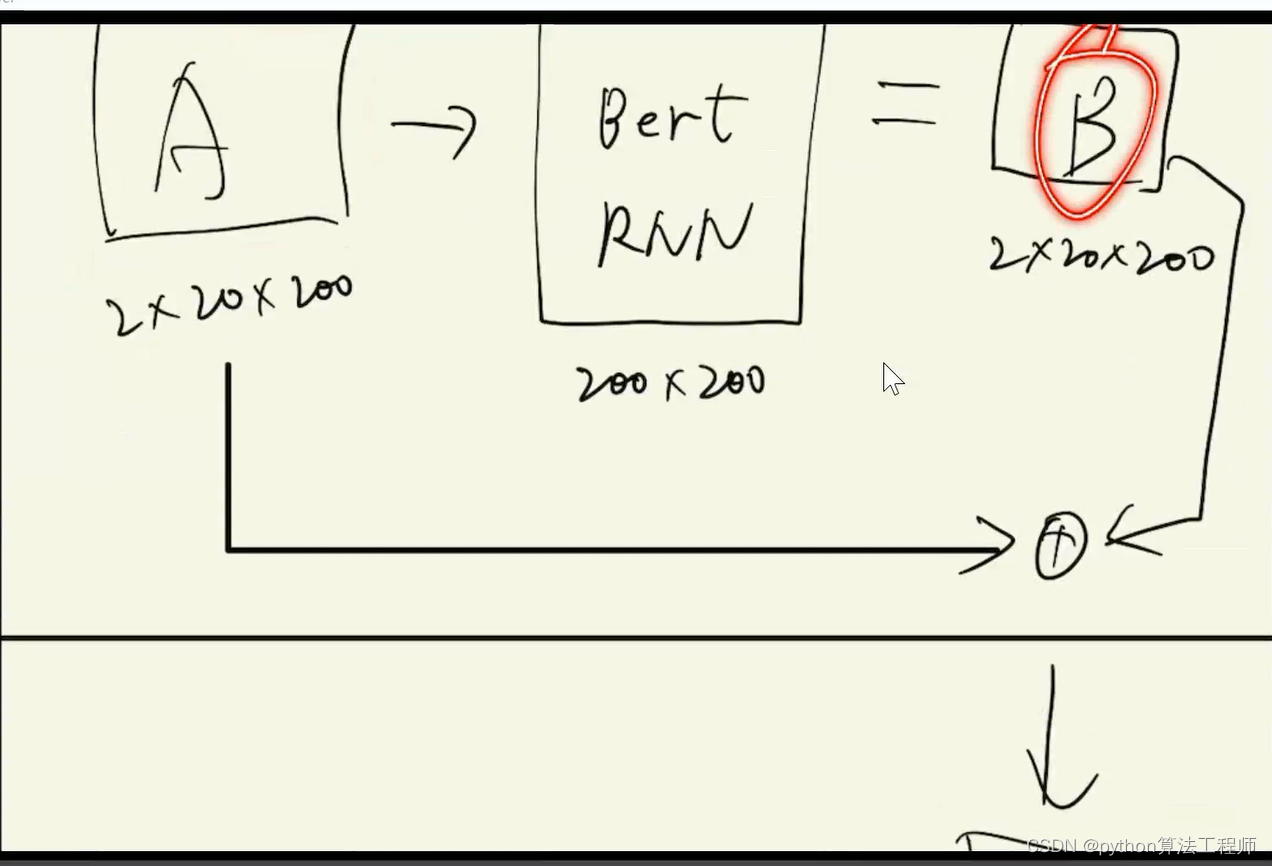
seqtoseq在做机器翻译的时候,将文本中的字符进行编码,将编码后的句子或者文本序列输入encoder进行编码,编码器采用GRU(transform的编码器有非常多),我觉得最重要的是在解码的时候添加了自注意机制,使得输入的序列特征有了不同的权重,从而可以让模型学习和关注到更加重要的特征
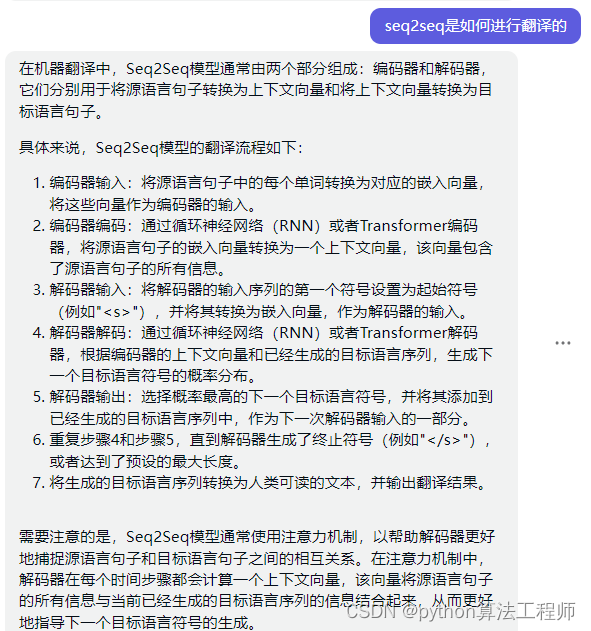
seqtoseq如何进行编解码的?
Seq2Seq模型是一个由编码器和解码器组成的神经网络模型,它可以用于将一个序列转换为另一个序列,例如机器翻译、文本摘要等任务。
编码器的作用是将输入序列编码为一个固定长度的向量,而解码器的作用是将这个向量解码为输出序列。下面是Seq2Seq模型的典型编码解码过程:
-
编码器:将输入序列的每个元素(例如单词或字符)转换为一个向量表示,并对整个序列进行编码。通常使用循环神经网络(如LSTM或GRU)来实现编码器,它可以在处理序列时保留一些状态信息。
-
上下文向量:编码器的最后一个隐藏状态(或某些变换后的状态)可以被视为整个输入序列的表示,这个向量被称为上下文向量(context vector)。
-
解码器:解码器根据上下文向量生成输出序列。解码器的输入是一个特殊的起始标记(例如“<SOS”),并根据起始标记和上下文向量生成第一个输出元素。然后,解码器使用前一个输出元素和上下文向量作为输入来生成下一个输出元素,直到遇到一个特殊的终止标记(例如“<EOS”)或达到最大输出长度为止。
在训练阶段,Seq2Seq模型的目标是最小化预测输出序列与真实输出序列之间的差距。在每个时间步骤,模型将真实输出序列中的下一个元素作为解码器的输入,并在下一个时间步骤中尝试预测下一个元素。这个过程可以使用交叉熵损失函数来计算模型的误差,并使用反向传播算法来更新模型参数。
在推理阶段,我们使用训练好的Seq2Seq模型来生成输出序列。我们首先将输入序列输入到编码器中,然后使用编码器的上下文向量来初始化解码器。然后,我们使用解码器来生成输出序列,直到遇到一个终止标记或达到最大输出长度为止。在每个时间步骤,解码器的输出被用作下一个时间步骤的输入,并重复这个过程直到生成整个输出序列。
transform的详细结构
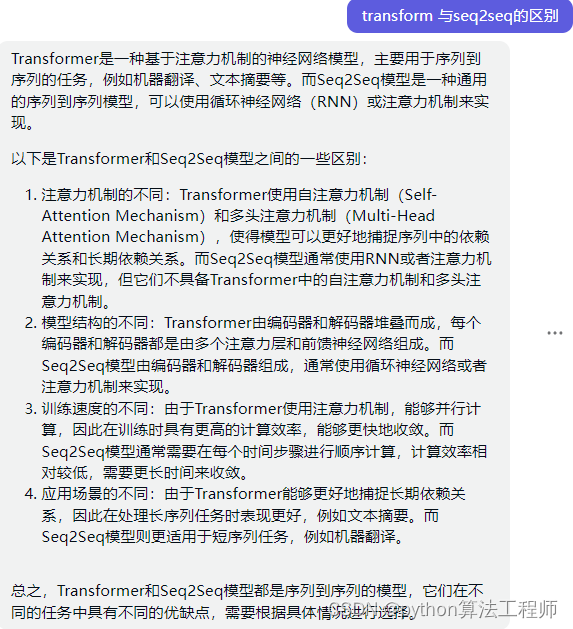
transform和seq2seq的区别与联系
Transformer和Seq2Seq都是用于序列建模的经典神经网络模型,但它们在设计和应用方面有一些区别和联系。
Seq2Seq是一种由编码器和解码器组成的模型,用于将一个序列转换为另一个序列。编码器将输入序列编码为一个向量,解码器将这个向量解码为输出序列。Seq2Seq广泛应用于机器翻译、文本摘要等任务,其中输入和输出序列的长度可以不同。
Transformer是一种只有编码器的模型,它使用自注意力机制(self-attention)来建模序列中不同位置之间的依赖关系。Transformer的自注意力机制允许模型在处理序列时关注到不同位置的信息,从而在处理长序列时取得更好的效果。Transformer广泛应用于语言建模、机器翻译、文本分类等任务,其中输入和输出序列的长度可以相同或不同。
尽管Seq2Seq和Transformer在设计和应用方面存在一些差异,但它们也有一些联系和相似之处。例如,Seq2Seq和Transformer都使用注意力机制(attention)来将输入序列的不同位置的信息集成到编码器和解码器中。Transformer的自注意力机制可以被视为一种特殊的注意力机制,它可以在不同位置之间计算注意力权重,从而进行序列建模。
此外,Seq2Seq和Transformer都使用了编码器-解码器结构,可以处理输入和输出序列的不同长度,并且都可以在训练过程中使用反向传播算法来优化模型参数。尽管它们的设计和应用存在一些不同,但它们都是非常有用和强大的序列建模工具,可以应用于多种自然语言处理任务。
transform的自注意机制在学习那些信息?
在Transformer中,自注意力机制(self-attention)用于计算序列中每个位置的表示和其他位置的表示之间的相似度,从而为每个位置生成一个加权表示(注意力权重)。
具体来说,自注意力机制可以学习以下信息:
-
序列中不同位置之间的相对位置关系,从而建模序列中的长距离依赖关系。传统的循环神经网络(RNN)和卷积神经网络(CNN)在处理长序列时可能会出现梯度消失或梯度爆炸问题,而自注意力机制可以更好地处理这种问题。
-
序列中每个位置的语义信息,从而更好地表示序列中的语义信息。自注意力机制可以计算序列中每个位置与其他位置之间的相似度,从而捕捉不同位置之间的语义关系。
-
序列中每个位置的重要性,从而更好地聚焦于重要的位置。自注意力机制可以计算每个位置与其他位置之间的相似度,并将注意力权重应用于对应位置的表示,从而聚焦于对模型更重要的位置。
在Transformer中,自注意力机制被应用于编码器和解码器中,用于捕捉序列中的语义信息和依赖关系。通过多头自注意力机制,Transformer可以同时关注多个不同的语义信息,从而更好地表示序列中的信息。自注意力机制是Transformer模型的核心组成部分,也是该模型能够在自然语言处理等任务中取得优秀效果的关键因素之一。
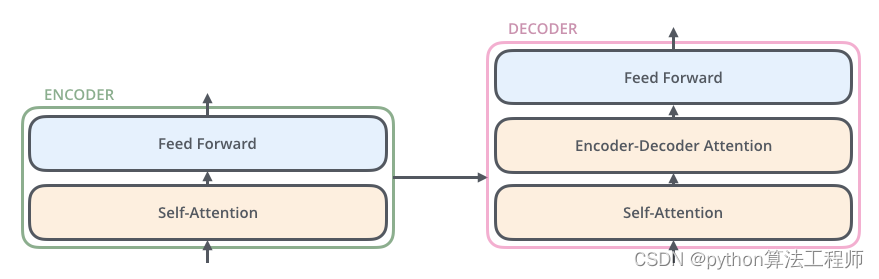
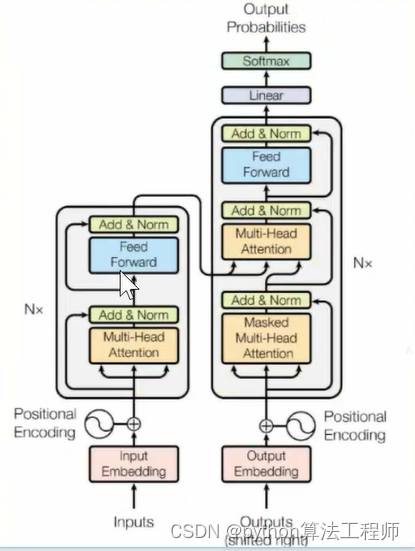 左边是decode右边是encode,矩阵融合和矩阵拼接都可以作为信息的叠加,Nx就代表这个模块重复几次
左边是decode右边是encode,矩阵融合和矩阵拼接都可以作为信息的叠加,Nx就代表这个模块重复几次
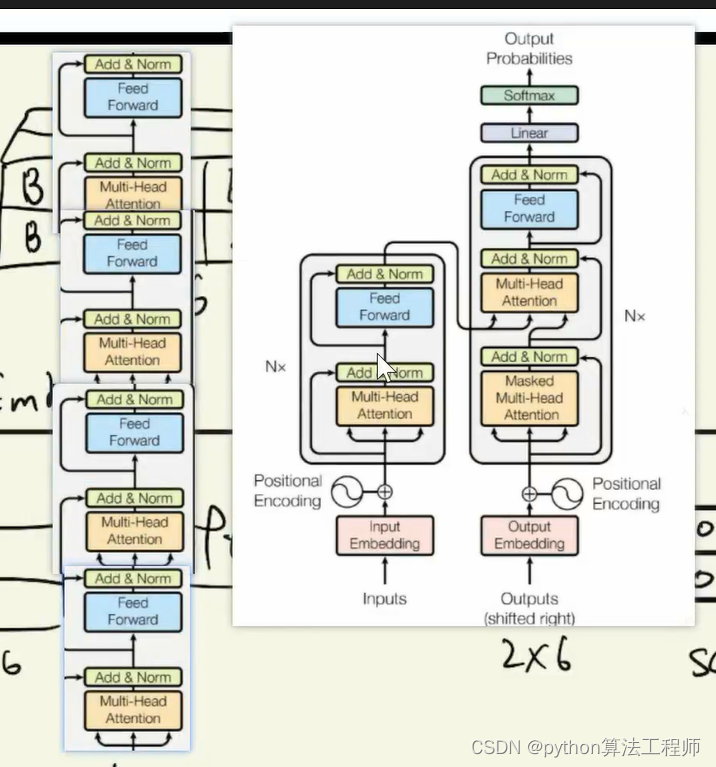




什么是信息增强?
残差网络
每个残差块的输入包括两部分:原始输入和增强输入。原始输入经过残差块的一系列变换后得到残差输出,而增强输入则通过一系列的信息增强操作得到。最终,原始输入和增强输入的残差输出在元素级别上相加,得到最终的输出。通过这种方式,ResNet将信息增强和残差网络相结合,有效提高了模型的泛化能力和鲁棒性。
feed forward
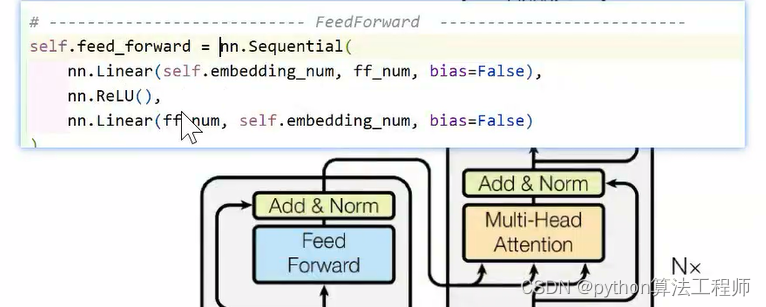
两层线性层是为了维度保存一致,中间加一个激活函数
positional位置编码
在使用Transformer模型进行序列数据处理时,为了保留序列中的位置信息,需要对输入的序列进行位置编码(Positional Encoding)。位置编码是一种将序列中每个位置与一个固定向量进行映射的技术,可以将序列中的位置信息嵌入到向量表示中,从而保留序列中的相对位置信息。
常见的位置编码方法是使用正弦函数和余弦函数来计算位置编码矩阵。具体来说,假设输入序列的长度为L,每个位置的维度为d,那么对于序列中的每个位置i和每个维度j,可以计算出位置编码矩阵中的元素值:
P E i , j = { sin ( i 1000 0 2 j / d ) j is even cos ( i 1000 0 2 j / d ) j is odd PE_{i,j} = \begin{cases} \sin(\frac{i}{10000^{2j/d}}) \quad j\text{ is even} \\ \cos(\frac{i}{10000^{2j/d}}) \quad j\text{ is odd} \\ \end{cases} PEi,j={sin(100002j/di)j is evencos(100002j/di)j is odd
其中, P E i , j PE_{i,j} PEi,j表示位置编码矩阵中第i行、第j列的元素值, d d d表示输入序列中每个位置向量的维度, j j j表示位置向量的维度下标, i i i表示位置向量的位置下标。通过这种方式,可以将每个位置与一个固定的向量进行映射,并且保留了相对位置之间的关系。
在Transformer模型中,位置编码矩阵可以与输入序列进行相加,从而将位置编码信息与输入序列进行融合,同时保留了输入序列中的位置信息。这样,在进行自注意力计算时,模型可以同时考虑序列中的特征信息和位置信息,从而提高模型的表达能力和性能。
from torch.utils.data import Dataset,DataLoader
import numpy as np
import torch
import torch.nn as nn
import os
import time
from tqdm import tqdm
def get_data(path,num=None):
all_text = []
all_label = []
with open(path,"r",encoding="utf8") as f:
all_data = f.read().split("\n")
for data in all_data:
try:
if len(data) == 0:
continue
data_s = data.split(" ")
if len(data_s) != 2:
continue
text,label = data_s
label = int(label)
except Exception as e:
print(e)
else:
all_text.append(text)
all_label.append(int(label))
if num is None:
return all_text,all_label
else:
return all_text[:num], all_label[:num]
def build_word2index(train_text):
word_2_index = {"PAD":0,"UNK":1}
for text in train_text:
for word in text:
if word not in word_2_index:
word_2_index[word] = len(word_2_index)
return word_2_index
class TextDataset(Dataset):
def __init__(self,all_text,all_lable):
self.all_text = all_text
self.all_lable = all_lable
def __getitem__(self, index):
global word_2_index
text = self.all_text[index]
text_index = [word_2_index.get(i,1) for i in text]
label = self.all_lable[index]
text_len = len(text)
return text_index,label,text_len
def process_batch_batch(self, data):
global max_len,word_2_index,index_2_embeding
batch_text = []
batch_label = []
batch_len = []
for d in data:
batch_text.append(d[0])
batch_label.append(d[1])
batch_len.append(d[2])
min_len = min(batch_len)
batch_text = [i[:max_len] for i in batch_text]
batch_text = [i + [0]*(max_len-len(i)) for i in batch_text]
# batch_emebdding = []
# for text_idx in batch_text:
# text_embdding = []
# for idx in text_idx:
# word_emb = index_2_embeding[idx]
# text_embdding.append(word_emb)
# batch_emebdding.append(text_embdding)
return torch.tensor(batch_text),torch.tensor(batch_label)
def __len__(self):
return len(self.all_text)
class Positional(nn.Module):
def __init__(self,embedding_num,max_len = 3000):
super().__init__()
self.position = torch.normal(0,1,size=(max_len,1)) # embedding * 3000
self.position = self.position.repeat(1,embedding_num)
def forward(self,batch_x): # batch * len * 200
pos = self.position[:batch_x.shape[1],:]
pos = pos.unsqueeze(dim=0)
pos = pos.to(batch_x.device)
result = batch_x + pos
return result
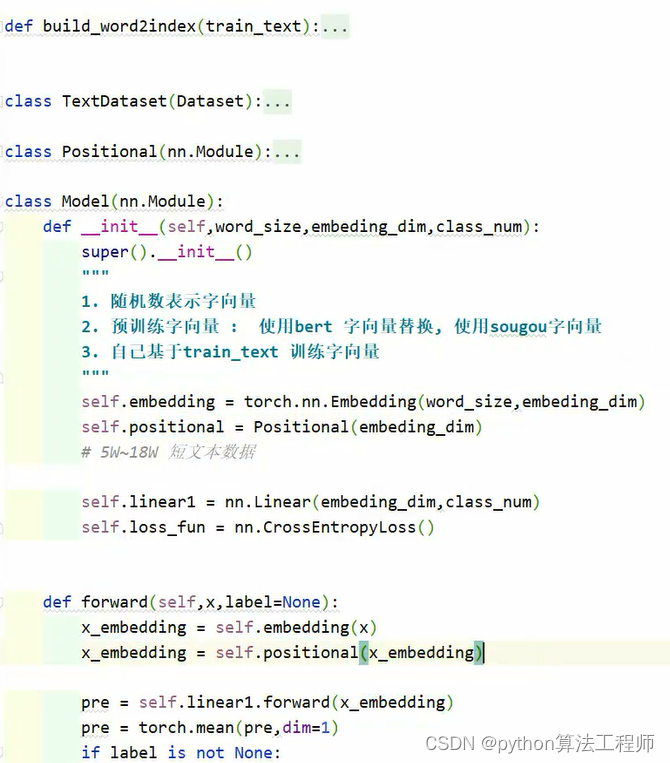
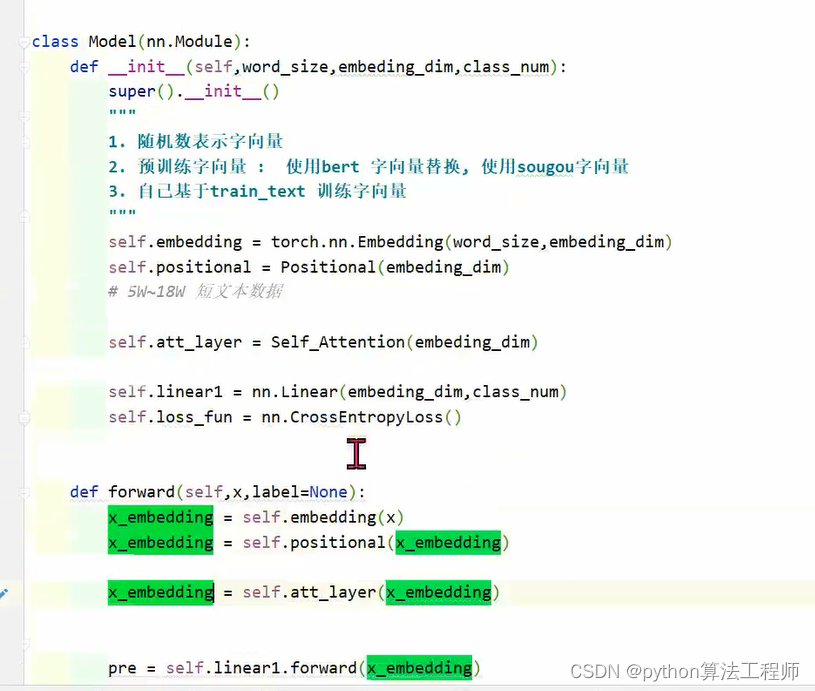
class Model(nn.Module):
def __init__(self,word_size,embeding_dim,class_num):
super().__init__()
"""
1. 随机数表示字向量
2. 预训练字向量 : 使用bert 字向量替换, 使用sougou字向量
3. 自己基于train_text 训练字向量
"""
self.embedding = torch.nn.Embedding(word_size,embeding_dim)
self.positional = Positional(embeding_dim)
# 5W~18W 短文本数据
self.linear1 = nn.Linear(embeding_dim,class_num)
self.loss_fun = nn.CrossEntropyLoss()
def forward(self,x,label=None):
x_embedding = self.embedding(x)
# x_embedding = self.positional(x_embedding)
pre = self.linear1.forward(x_embedding)
pre = torch.mean(pre,dim=1)
if label is not None:
loss = self.loss_fun(pre,label)
return loss
else:
return torch.argmax(pre,dim=-1)
def same_seeds(seed):
torch.manual_seed(seed) # 固定随机种子(CPU)
if torch.cuda.is_available(): # 固定随机种子(GPU)
torch.cuda.manual_seed(seed) # 为当前GPU设置
torch.cuda.manual_seed_all(seed) # 为所有GPU设置
np.random.seed(seed) # 保证后续使用random函数时,产生固定的随机数
torch.backends.cudnn.benchmark = False # GPU、网络结构固定,可设置为True
torch.backends.cudnn.deterministic = True # 固定网络结构
# word2vec 复现
if __name__ == "__main__":
same_seeds(1007)
train_text,train_lable = get_data(os.path.join("..","data","文本分类","train.txt"),70000)
dev_text,dev_lable = get_data(os.path.join("..","data","文本分类","dev.txt"),10000)
assert len(train_lable) == len(train_text),"训练数据长度都不一样,你玩冒险呢?"
assert len(dev_text) == len(dev_lable),"验证数据长度都不一样,你玩冒险呢?"
embedding_num = 200
word_2_index = build_word2index(train_text)
train_batch_size = 50
max_len = 30
epoch = 10
lr = 0.001
class_num = len(set(train_lable))
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# device = "cpu"
train_dataset = TextDataset(train_text,train_lable)
train_dataloader = DataLoader(train_dataset,batch_size=train_batch_size,shuffle=True,collate_fn=train_dataset.process_batch_batch)
dev_dataset = TextDataset(dev_text, dev_lable)
dev_dataloader = DataLoader(dev_dataset, batch_size=10, shuffle=False,collate_fn=dev_dataset.process_batch_batch)
model = Model(len(word_2_index),embedding_num,class_num).to(device)
opt = torch.optim.Adam(model.parameters(),lr)
s_time = time.time()
for e in range(epoch):
print("*" * 100)
for bi,(batch_text,batch_label) in (enumerate(train_dataloader,start=1)):
batch_text = batch_text.to(device)
batch_label = batch_label.to(device)
loss = model.forward(batch_text,batch_label)
loss.backward()
opt.step()
opt.zero_grad()
print(f"loss:{loss:.2f}")
e_time = time.time()
# print(f"cost time :{e_time - s_time:.2f}s")
s_time = time.time()
right_num = 0
for bi,(batch_text,batch_label) in (enumerate(dev_dataloader)):
batch_text = batch_text.to(device)
batch_label = batch_label.to(device)
pre = model.forward(batch_text)
right_num += int(torch.sum(pre == batch_label))
print(f"acc:{right_num/len(dev_dataset) * 100:.2f}%")
这是一个使用 PyTorch训练文本分类模型的Python 脚本。该脚本包括多个函数,用于读取和处理数据、构建数据集类、定义模型和训练模型。
该get_data函数从文件中读取数据并将其拆分为文本和标签对。该build_word2index函数构建一个字典,将每个单词映射到一个索引,该类TextDataset为文本和标签对定义一个数据集。
该类Positional定义了模型的位置编码层Model,该类定义了主要的分类模型,包括嵌入层、位置编码层和线性层。
该脚本还包括一个same_seeds用于设置随机种子的函数、一个train_dataloader用于加载训练数据的函数、一个dev_dataloader用于加载验证数据的函数,以及一个用于训练和评估模型的外循环。
在训练期间,使用Adam 优化器和交叉熵损失函数更新模型,并在每个时期结束时计算验证集的准确性。
请注意,脚本设计为从命令行运行,数据文件和其他参数可以指定为命令行参数。
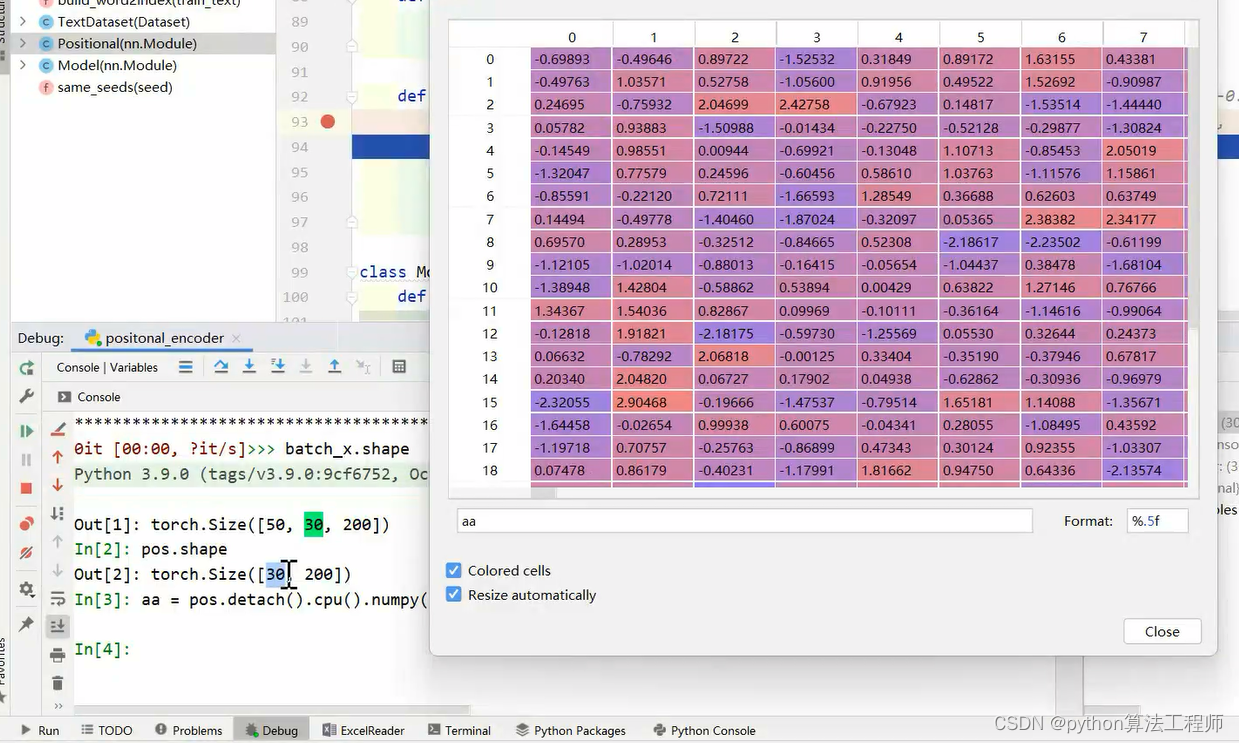

自注意机制
 这里虽然是线性的确是批量操作的
这里虽然是线性的确是批量操作的
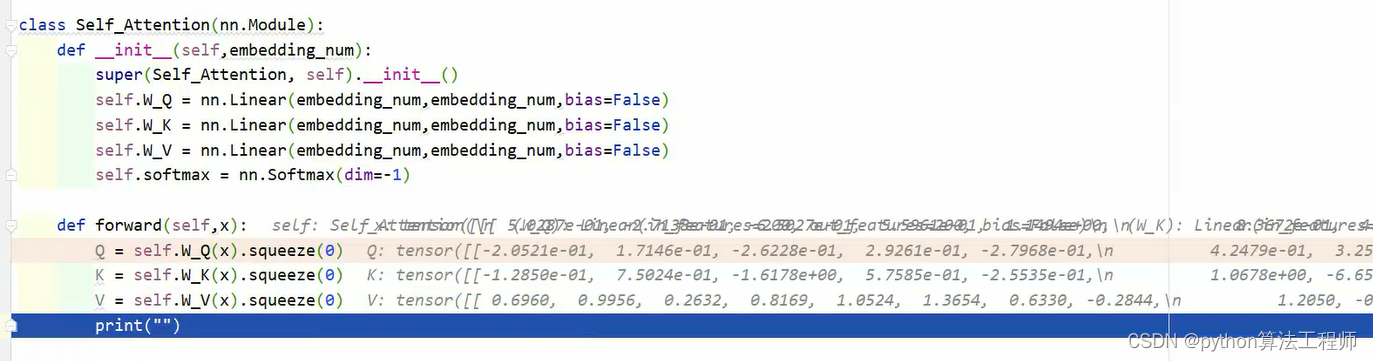
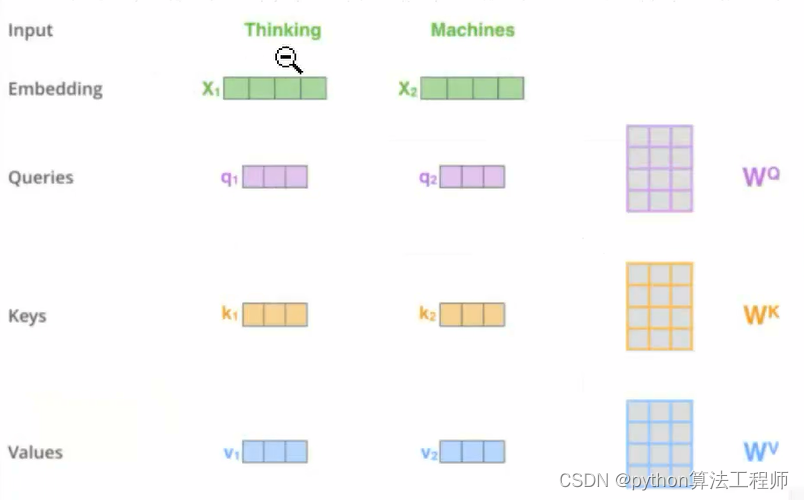
如何计算qkv矩阵
在使用self-attention机制时,获取查询向量(q)、键向量(k)和值向量(v)的矩阵通常是通过对输入序列进行线性变换来实现的。
具体来说,假设输入序列表示为X,其中每个元素的表示是d维向量。则,可以通过对X进行三次不同的线性变换来获取q、k、v矩阵:
- 查询向量(q):通过将X与一个权重矩阵W_q做矩阵乘法,并加上一个偏置向量b_q,然后应用一个激活函数(例如ReLU)来获得查询向量q。即:q = activation(XW_q + b_q),其中,W_q的维度是[d, d_q],b_q的维度是[d_q],d_q是查询向量的维度。
- 键向量(k):通过将X与一个权重矩阵W_k做矩阵乘法,并加上一个偏置向量b_k,然后应用一个激活函数(例如ReLU)来获得键向量k。即:k = activation(XW_k + b_k),其中,W_k的维度是[d, d_k],b_k的维度是[d_k],d_k是键向量的维度。
- 值向量(v):通过将X与一个权重矩阵W_v做矩阵乘法,并加上一个偏置向量b_v,然后应用一个激活函数(例如ReLU)来获得值向量v。即:v = activation(XW_v + b_v),其中,W_v的维度是[d, d_v],b_v的维度是[d_v],d_v是值向量的维度。
通过这种方式,可以从输入序列中提取出三个不同的线性变换结果,分别作为查询向量、键向量和值向量的矩阵,用于计算self-attention机制中的相似度得分和加权和。需要注意的是,在不同的模型中,获取q、k、v矩阵的具体方式和参数可能会有所不同。
如何获取权重矩阵
在神经网络中,权重矩阵通常是通过随机初始化和反向传播算法学习得到的。在使用self-attention机制时,查询向量(q)、键向量(k)和值向量(v)的权重矩阵也是通过学习得到的。
具体来说,在训练过程中,神经网络通过反向传播算法计算每个权重矩阵的梯度,并使用梯度下降等优化算法来更新权重矩阵的值。在初始化权重矩阵时,通常会使用一些特定的初始化方法,例如Xavier初始化或He初始化,以确保权重矩阵在训练过程中能够保持稳定和有效。
需要注意的是,在不同的模型中,权重矩阵的初始化方法和学习方式可能会有所不同。例如,在Transformer模型中,权重矩阵的初始化通常使用Xavier初始化方法,而权重矩阵的学习则通常使用Adam等优化算法。
如果需要手动设置权重矩阵的初始值,可以使用随机数生成器生成一些具有一定分布特征的随机数,并将其赋值给权重矩阵。例如,可以使用Python中的NumPy库来生成具有正态分布或均匀分布特征的随机数,并将其作为权重矩阵的初始值。但是,在实践中,手动设置权重矩阵的初始值通常是不必要的,因为深度学习框架通常提供了默认的权重矩阵初始化方法和训练算法。

q:查询 k:关键信息 v:求值



当然!这是一个使用PyTorch实现自我注意层的Python 脚本:
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, hidden_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.query = nn.Linear(hidden_dim, hidden_dim, bias=False)
self.key = nn.Linear(hidden_dim, hidden_dim, bias=False)
self.value = nn.Linear(hidden_dim, hidden_dim, bias=False)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
batch_size, seq_len, hidden_dim = x.shape
q = self.query(x).view(batch_size, seq_len, hidden_dim)
k = self.key(x).view(batch_size, seq_len, hidden_dim)
v = self.value(x).view(batch_size, seq_len, hidden_dim)
attn_scores = torch.bmm(q, k.transpose(1, 2))
attn_scores = self.softmax(attn_scores)
output = torch.bmm(attn_scores, v)
return output
该类SelfAttention定义了一个自注意力层,它将维度为 [batch_size, seq_len, hidden_dim] 的3D 张量作为输入。和线性层将输入张量投影到query三个独立的空间,查询和关键向量的点积用于计算注意力分数。将softmax函数应用于注意力分数以获得序列上的概率分布,并将值向量的加权和用作自注意力层的输出。keyvalue
您可以像使用任何其他 PyTorch 模块一样在您的神经网络中使用这个自我注意层。例如,如果你想在transformer 模型中使用它,你可以按如下方式定义transformer 编码器层:


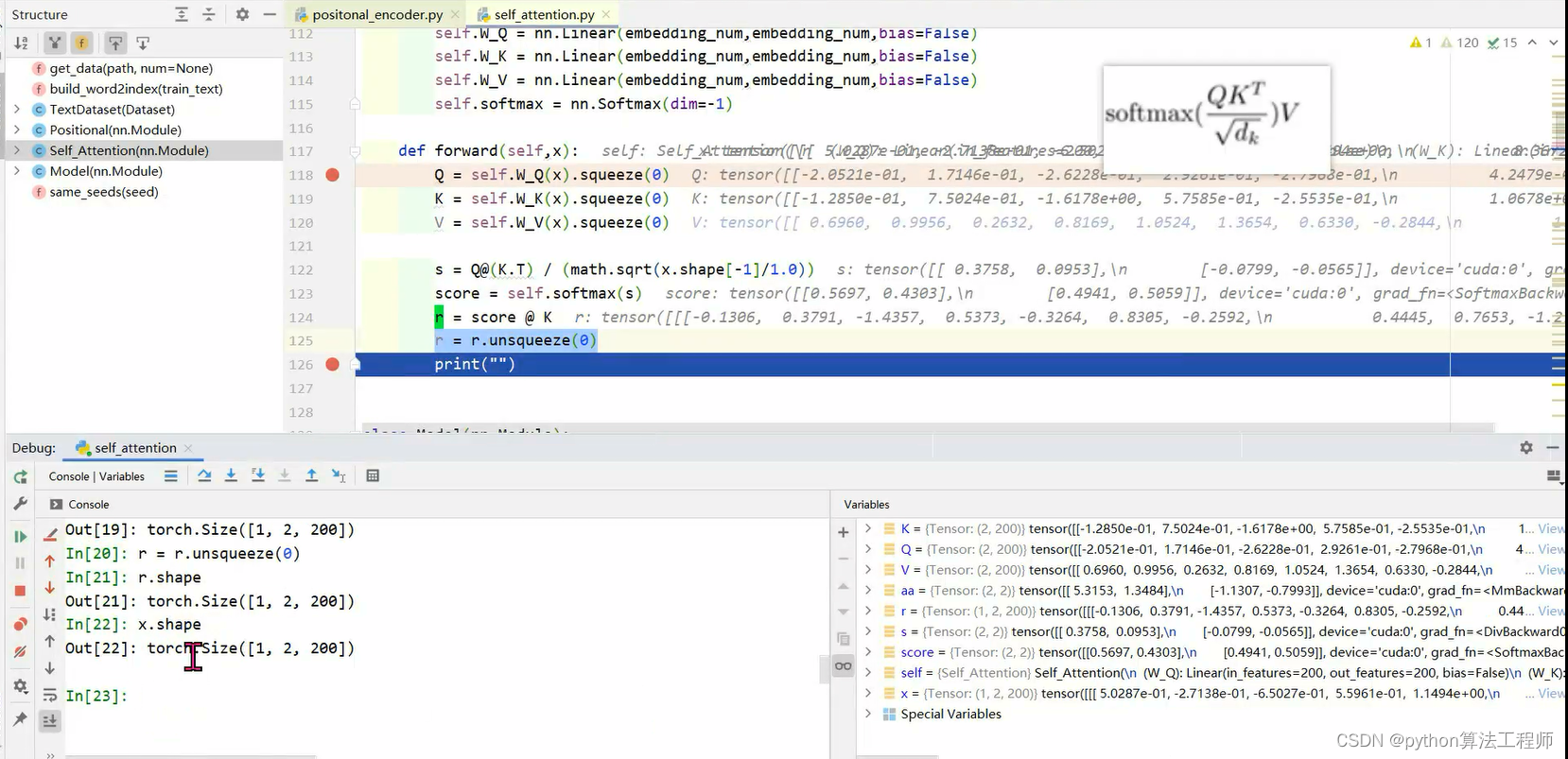
通过qk实现自注意力机制
首先,self-attention机制是一种用于处理序列数据的模型,它能够自动地对不同位置的输入进行加权处理,并将加权后的结果用于后续的模型计算。在这个过程中,模型会从输入序列中提取出三个矩阵:查询矩阵Q、键矩阵K和值矩阵V,其中,每个矩阵的维度都是[d_model, seq_len],其中d_model表示模型的隐藏层维度,seq_len表示输入序列的长度。
在实现中,可以通过对输入序列进行一系列的线性变换来获取这三个矩阵。具体来说,可以用三个不同的权重矩阵W_q、W_k和W_v分别对输入序列进行线性变换,从而得到查询矩阵Q、键矩阵K和值矩阵V:
Q = W_q(x)
K = W_k(x)
V = W_v(x)
其中,x表示输入序列,W_q、W_k和W_v分别表示三个权重矩阵。在这里,也可以看到代码片段中使用了.squeeze()方法来去除某个维度的大小为1的维度,这是因为在实际使用中,输入序列的维度可能会比较复杂,需要对其进行一些维度变换和调整。
接下来,需要计算查询矩阵Q和键矩阵K之间的相似度得分,用于对每个位置的输入进行加权。可以使用矩阵乘法来计算Q和K之间的相似度得分,然后通过一个softmax函数来将得分转化为权重值:
score = torch.matmul(Q.transpose(-2, -1), K) /math.sqrt(x.shape[-1])
weight = torch.softmax(score, dim=-1)
其中,torch.matmul表示矩阵乘法,Q.transpose(-2, -1)表示将查询矩阵Q的倒数第二个维度和倒数第一个维度进行转置,从而使得Q和K的矩阵乘法能够正确地进行。math.sqrt(x.shape[-1])表示对矩阵乘积进行缩放,以避免得分过大或过小的问题。torch.softmax表示softmax函数,dim=-1表示在最后一个维度上进行softmax。
最后,将权重值和值矩阵V相乘,得到加权后的结果:
weighted_v = torch.matmul(weight, V)
output = torch.matmul(weighted_v, f)
其中,torch.matmul表示矩阵乘法,weighted_v表示加权后的值矩阵,f表示一个可学习的线性变换矩阵,用于将加权后的值矩阵映射到输出空间。最终的结果output表示self-attention机制的输出。

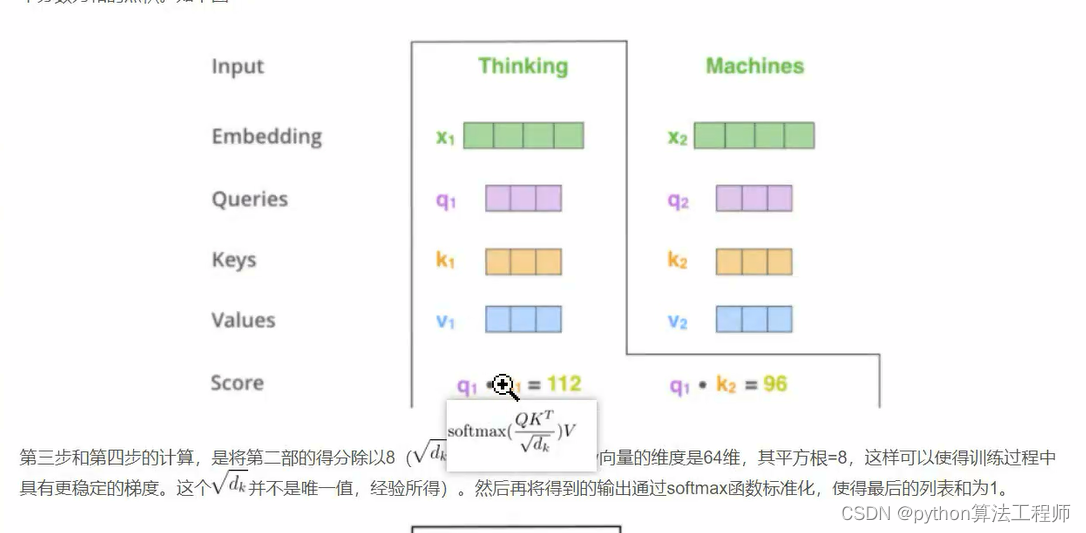
如何通过q与k 计算v的?
在注意力机制中,通过查询向量Q和键向量K计算得到注意力权重,然后将注意力权重和对应的值向量V做加权求和,得到注意力输出向量。具体来说,可以按照以下步骤计算:
-
计算注意力分数:将查询向量Q和键向量K做点积,然后除以一个缩放因子,得到注意力分数。
Attention ( Q , K ) = softmax ( Q K T d k ) \text{Attention}(Q, K) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}}) Attention(Q,K)=softmax(dkQKT)
其中, Q Q Q是查询向量, K K K是键向量, d k d_k dk是向量的维度, softmax \text{softmax} softmax函数用于归一化得到注意力权重。
-
计算注意力输出:将注意力权重与值向量V做加权求和,得到注意力输出向量。
Attention ( Q , K , V ) = ∑ i = 1 n α i V i \text{Attention}(Q, K, V) = \sum_{i=1}^{n} \alpha_i V_i Attention(Q,K,V)=i=1∑nαiVi
其中, α i \alpha_i αi是第 i i i个注意力权重, V i V_i Vi是第 i i i个值向量。
因此,通过查询向量Q和键向量K,可以计算得到注意力权重,然后将注意力权重和对应的值向量V做加权求和,就可以得到注意力输出向量。这个过程可以表示为一个矩阵运算,可以使用矩阵乘法一次性计算多个查询向量Q和键向量K对应的注意力输出向量,从而提高计算效率。
class TransformerEncoderLayer(nn.Module):
def __init__(self, hidden_dim, dropout_prob):
super().__init__()
self.self_attention = SelfAttention(hidden_dim)
self.dropout = nn.Dropout(dropout_prob)
self.layer_norm = nn.LayerNorm(hidden_dim)
def forward(self, x):
residual = x
x = self.self_attention(x)
x = self.dropout(x)
x = self.layer_norm(x + residual)
return x
在此示例中,该类TransformerEncoderLayer使用该模块在转换器编码器SelfAttention层中实现自我注意机制。该层还包括 dropout 和层归一化以实现正则化和稳定性。

 这种自注意力机制允许Transformer捕捉输入序列中单词之间的长距离依赖关系,并已被证明对广泛的NLP任务非常有效。
这种自注意力机制允许Transformer捕捉输入序列中单词之间的长距离依赖关系,并已被证明对广泛的NLP任务非常有效。


transformer复现
Transformer是一种用于序列到序列学习的神经网络模型,主要用于自然语言处理任务,如机器翻译、文本摘要和对话生成等。下面展示一个完整的Transformer模型结构。
Transformer模型由两个重要的组件构成:编码器和解码器。编码器将输入序列映射到一组隐藏表示,解码器将这些隐藏表示转换为输出序列。这些组件由多个层组成,每个层都包含多头自注意力机制和前馈神经网络。
以下是一个完整的Transformer模型结构:
-
输入嵌入层:将输入序列中的每个单词转换为d_model维的向量表示。
-
位置编码层:将位置信息嵌入到输入向量中,以保留序列顺序信息。
-
编码层:由多个编码器层组成,每个编码器层包含以下子层:
a. 多头自注意力机制:将序列中的每个位置与其他位置进行比较,以确定其在序列中的重要性,并计算其加权和。通过使用多个注意力头,模型可以在不同的表示空间中学习不同的关系。
b. 前馈神经网络:将每个位置的隐藏表示作为输入,通过两个全连接层计算其输出。
c. 残差连接和层归一化:将输入与子层的输出相加,并进行层归一化和残差连接,以便信息能够更好地传递。
-
解码器层:由多个解码器层组成,每个解码器层包含以下子层:
a. 多头自注意力机制:与编码器中的注意力机制相同,但是包含了一个掩码,以避免解码器在生成当前位置的预测时查看未来的信息。
b. 多头编码器-解码器注意力机制:将编码器的隐藏表示与当前解码器位置的隐藏表示进行比较,并计算加权和,以获取对编码器上下文的理解。
c. 前馈神经网络:与编码器中的前馈神经网络相同。
d. 残差连接和层归一化:与编码器中的残差连接和层归一化相同。
-
输出层:将解码器的最终隐藏表示映射到输出序列的概率分布上。
这就是Transformer模型的完整结构。
transform是如何训练与推理的?
Transformer是一种用于序列到序列学习的神经网络模型,主要用于自然语言处理任务,如机器翻译、文本摘要和对话生成等。下面简要介绍一下Transformer的训练和推理过程。
训练过程:
-
数据预处理:将原始文本数据转换为模型可以处理的数字化表示形式,例如单词嵌入和位置编码。
-
模型定义:定义Transformer模型的结构和参数,包括编码器和解码器的层数、隐藏向量的维度、注意力头数等。
-
损失函数定义:定义模型的损失函数,通常使用交叉熵损失函数来衡量模型的输出与正确答案之间的差距。
-
参数优化:使用反向传播算法和优化器来更新模型的参数,以最小化损失函数。
推理过程:
-
数据预处理:与训练过程相同,将原始文本数据转换为数字化表示形式。
-
模型定义:使用训练好的模型参数定义Transformer模型的结构。
-
解码器预测:使用解码器生成器,以逐步生成输出序列。在每个时间步骤中,解码器将当前时刻的输出作为输入,并使用编码器的隐藏表示和注意力机制来帮助生成下一个单词。解码器在每个时间步骤的输出是一个概率分布,表示下一个单词的可能性。
-
结束条件判断:在生成输出序列时,可以使用不同的策略来决定何时停止生成。例如,可以设置一个最大输出长度,或者在生成特定符号(如结束符号)后停止生成。
总之,Transformer模型的训练过程涉及数据预处理、模型定义、损失函数定义和参数优化等步骤;推理过程涉及数据预处理、模型定义、解码器预测和结束条件判断等步骤。
训练过程
Transformer是一种用于序列到序列学习的神经网络模型,主要用于自然语言处理任务,如机器翻译、文本摘要和对话生成等。下面详细说明一下Transformer的训练过程,包含输入。
- 数据预处理:首先需要将原始文本数据转换为模型可以处理的数字化表示形式。这个过程通常包括以下几个步骤:
- 分词:将句子分成单词或子词的序列。
- 构建词表:将所有单词/子词映射到唯一的ID,构建词表。
- 填充和截断:将所有序列调整为相同的长度,并将长度不足的序列填充到相同的长度。
- 位置编码:为每个单词/子词添加位置编码,以保留序列中单词/子词的相对位置信息。
- 生成训练数据:将输入序列和输出序列组成训练样本,其中输入序列是源语言文本,输出序列是目标语言文本。
- 模型输入:Transformer模型的输入是经过处理的数值化表示形式的源语言文本和目标语言文本。具体来说,输入包括以下几个部分:
- 源语言输入:经过词嵌入和位置编码后的源语言单词/子词序列,形状为[batch_size, seq_length, embedding_size]。
- 目标语言输入:经过词嵌入和位置编码后的目标语言单词/子词序列,形状为[batch_size, seq_length, embedding_size],其中seq_length是目标序列的长度。
- 掩码:用于掩盖目标语言序列中未来位置的掩码,以避免模型在预测时使用未来信息。掩码的形状为[batch_size, seq_length, seq_length],其中每个掩码矩阵的对角线及其以下部分为1,其余部分为0。
- 模型训练:在输入数据和模型的帮助下,Transformer进行前向传播,计算损失函数,并使用反向传播算法调整模型参数。具体来说,训练过程包括以下几个步骤:
- 前向传播:将源语言输入和目标语言输入传入Transformer模型,得到模型的输出结果。
- 计算损失:使用输出结果和目标语言序列计算损失函数。常用的损失函数包括交叉熵损失函数和平均绝对误差损失函数等。
- 反向传播:使用反向传播算法计算损失函数对模型参数的梯度,并使用优化算法(如Adam)更新模型参数。
- 重复以上步骤:重复以上步骤,直到损失函数收敛或达到预定的训练轮数。
在训练过程中,还可以采用一些技巧来提高模型的性能,如批量归一化、残差连接、dropout等。此外,还可以使用预训练模型来提高模型的泛化能力,并减少训练时间和计算成本。
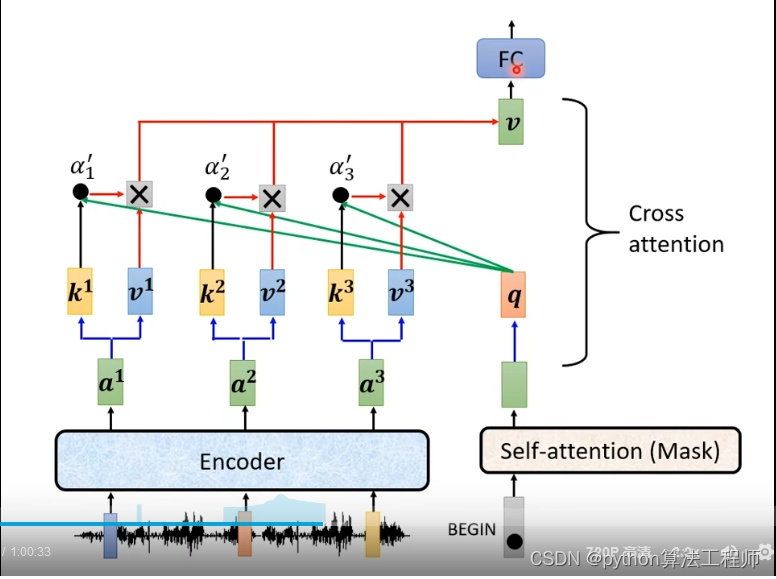
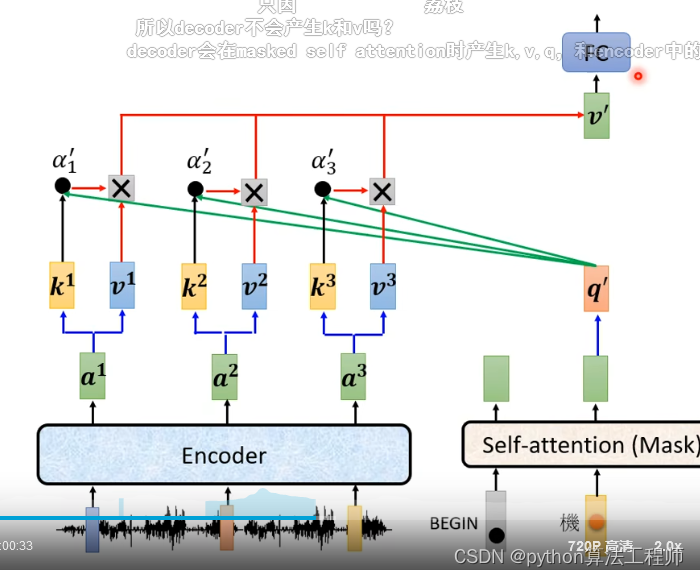
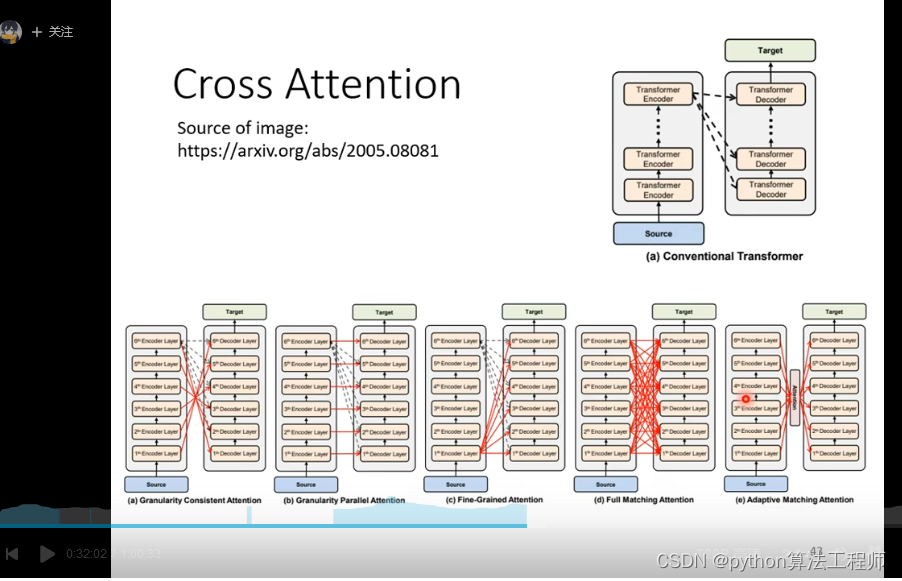
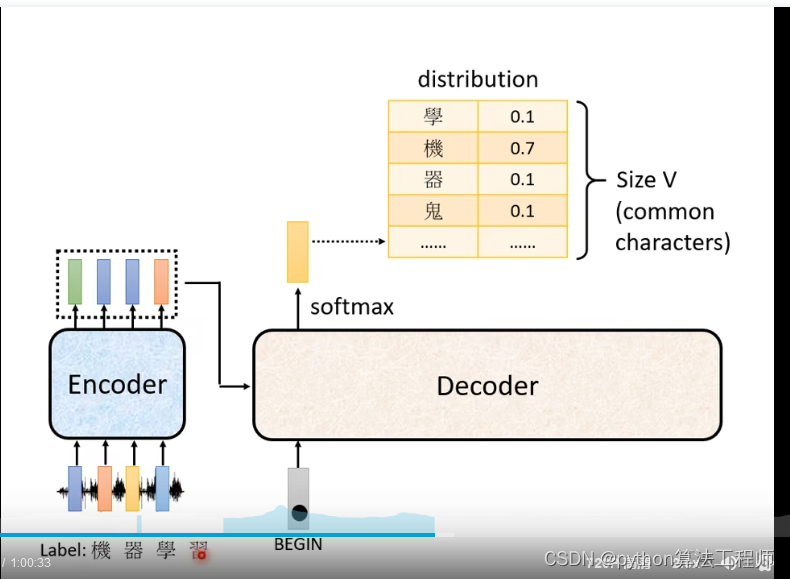




训练
https://www.bilibili.com/video/BV1v3411r78R?p=4&vd_source=569ef4f891360f2119ace98abae09f3f
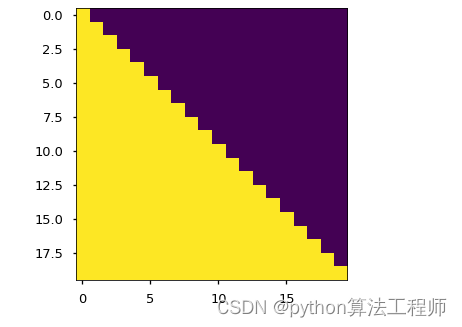
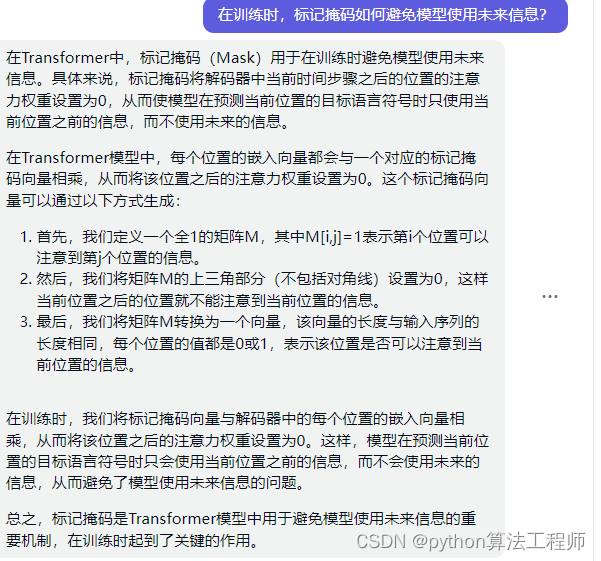
masked掩码操作
Transformer中的标记掩码(Masked Language Modeling)是一种用于自然语言处理任务的技术,其目的是在训练过程中将部分输入内容掩盖,使得模型在预测时需要根据上下文进行推断,从而提高模型的泛化能力。在预测时,模型需要根据上下文中的其他单词来预测被掩盖的单词,从而使得模型更好地理解语义和语法。
虽然标记掩码在Transformer中得到了广泛应用,并在一定程度上提高了模型的性能,但也存在着一些问题和争议。其中一个问题是,标记掩码可能会引入过拟合问题。由于掩盖了部分输入内容,模型在训练时只能使用部分信息进行学习,从而可能导致模型过度适应训练数据,而难以泛化到新的数据上。此外,标记掩码也可能会影响模型的语言理解能力,使得模型更加依赖于上下文信息而忽略单词本身的语义和语法。
另外,一些声音认为标记掩码被过度炒作,其实际作用可能不如一些宣传所述。例如,一些研究表明,在少量标记掩码的情况下,模型的性能提升较为有限,而过多的标记掩码则可能会对模型的性能产生负面影响。因此,在使用标记掩码时,需要根据具体任务和数据集来进行选择和调整,以达到最优的效果。
在深度学习中,mask掩码(也称为屏蔽掩码)是一种用于在模型中屏蔽某些输入、输出或计算的技术。在序列模型中,mask掩码通常用于控制模型只关注序列中的有效部分,而忽略序列中的填充部分。这种技术被称为“padding mask”。
具体来说,当输入序列中存在填充值时(例如在NLP中,可能会用0来填充长度不足的句子),为了避免模型在填充部分上进行无效计算,可以使用一个二元掩码(0和1)来标记哪些位置是填充部分,哪些位置是有效部分。将掩码应用于输入序列时,填充部分的值会被屏蔽,不会对模型的计算产生任何影响。
除了padding mask,还有一种常见的掩码技术是“sequence mask”,它主要用于在self-attention机制中控制模型只关注序列中的前面部分,而忽略序列中的后面部分。在这种情况下,掩码通常是一个上三角矩阵,其中上三角部分的值为0,下三角部分的值为-∞。将掩码应用于模型的计算中时,模型会自动忽略掩码中的-∞值,从而实现只关注前面部分的效果。
需要注意的是,mask掩码通常是在模型训练之前就生成好的,而不是在训练过程中动态生成的。这是因为在训练过程中,模型需要对整个输入序列进行计算,因此需要预先确定哪些部分是有效的,哪些部分是无效的。



vit
 这个关键字确实挺好用的
这个关键字确实挺好用的
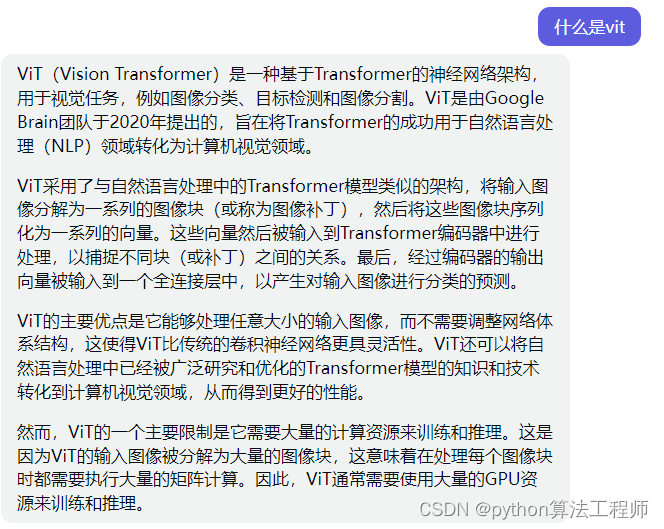
ViT:视觉Transformer backbone网络ViT论文与代码详解
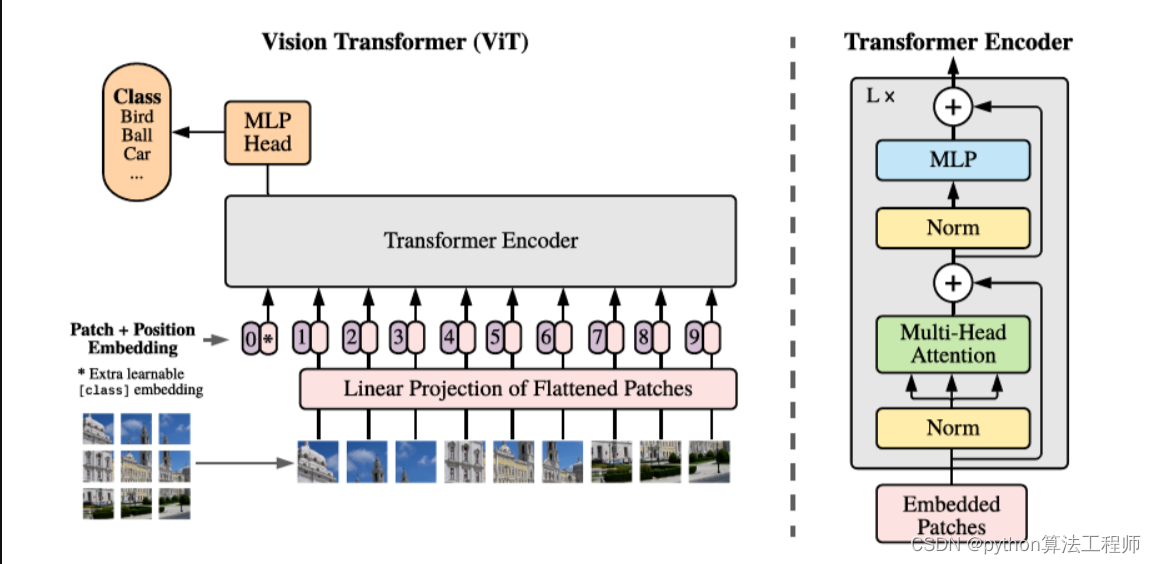
vit和transform的区别和联系
ViT和Transformers都是用于处理自然语言和计算机视觉任务的深度学习模型,但是它们之间有一些区别和联系。
区别:
-
输入形式:ViT主要用于处理图像数据,它将图像划分成一个个小的图像块,并将这些图像块转换为向量序列作为输入。而Transformers主要用于处理自然语言数据,它的输入是一个token序列。
-
建模方式:ViT使用自注意力机制(self-attention)来捕捉图像中不同部分的关系,从而实现对整个图像的建模。而Transformers也是基于自注意力机制的,但是它是将输入的token序列转换为隐层表示,然后对隐层表示进行建模。
-
应用领域:ViT主要应用于计算机视觉任务,如图像分类、目标检测和分割等。而Transformers主要应用于自然语言处理任务,如文本分类、命名实体识别和机器翻译等。
联系:
-
自注意力机制:ViT和Transformers都是基于自注意力机制的,都能够有效地捕捉输入序列中的关系。
-
模型结构:ViT和Transformers都是基于Transformer模型结构的,都包含多层Transformer编码器和解码器。
-
预训练模型:ViT和Transformers都可以通过预训练模型来提高模型的性能,如ViT中的ImageNet-1k预训练模型和Transformers中的BERT、GPT等预训练模型。
总之,ViT和Transformers都是非常有用的深度学习模型,它们在处理不同类型的数据和任务时都有自己的优势和应用场景。
vit为什么比cnn强大?
ViT(Vision Transformer)是一种新型的深度学习模型,它是在Transformer模型的基础上应用于计算机视觉任务的。相比于传统的CNN模型,ViT具有以下几个优势:
-
可处理更大的图像尺寸:传统的CNN模型在处理图像时需要将其缩放到相同的尺寸,这样会导致部分信息的丢失。而ViT可以处理任意大小的图像,通过将图像分割成小的图像块,并使用Transformer编码器来处理这些图像块,从而获得整个图像的特征表示。
-
全局视野:CNN在卷积过程中,特征的提取是局部的,只关注局部区域的特征。而ViT使用Transformer的全局自注意力机制,可以同时关注图像的不同部分,获取更全局的信息,从而能够更好的进行图像分类和目标检测等任务。
-
可以更好地处理长程依赖关系:传统的CNN模型通常采用池化等方法来降低特征维度和大小,这样会导致一定的信息损失和长程依赖关系的丢失。而ViT使用Transformer的自注意力机制,可以将不同位置的特征进行交互和融合,从而更好地处理长程依赖关系。
-
更好的可解释性:ViT中的自注意力机制使得模型可以在每个时间步骤上关注输入序列中的不同位置,从而产生可解释性的结果。
综上所述,ViT相对于传统的CNN模型而言,具有更好的全局视野、更强的长程依赖建模能力以及更好的可解释性,可以处理任意大小的图像尺寸,从而更加适合处理计算机视觉任务。
vit优化与加速
rff是什么?
Random Fourier Features(RFF)是一种基于随机映射的技术,可以将输入空间映射到一个高维特征空间中,从而允许在低维空间中进行高维特征的计算。RFF最初是用于加速核方法的计算,但近年来也被广泛应用于深度学习领域中。
在RFF中,采用一个随机的映射矩阵来将输入数据从低维空间映射到高维空间。这个映射矩阵是由随机数生成的,因此每次运行RFF时都会得到不同的映射矩阵。RFF的核心思想是,使用随机映射可以将原始数据的内积在高维空间中近似地表示为低维空间中的内积,从而加速计算。
具体来说,假设输入数据为 x ∈ R d x\in \mathbb{R}^d x∈Rd,随机映射矩阵为 W ∈ R D × d W\in \mathbb{R}^{D\times d} W∈RD×d,其中 D D D是映射后的特征维度,则RFF的计算过程如下:
-
将输入 x x x与随机映射矩阵 W W W相乘,得到一个新的向量 z = W x z=Wx z=Wx。
-
将新的向量 z z z通过傅里叶变换得到其频域表示。
-
在频域上进行计算,例如计算核函数或者使用自注意力机制进行计算。
-
将频域上的结果通过逆傅里叶变换得到其空域表示,即RFF的输出。
RFF的优点在于可以将高维特征的计算转化为低维特征的计算,从而大大减少了计算复杂度和内存消耗。此外,由于随机映射矩阵是由随机数生成的,因此可以在不同的运行中使用不同的映射矩阵,从而增加模型的鲁棒性和泛化能力。
RFF的应用非常广泛,包括图像处理、自然语言处理、推荐系统等领域。在深度学习中,RFF经常被用于加速模型的计算,例如在Transformers模型中,可以使用RFF加速自注意力机制的计算。
transform如何使用rff加速?
在使用Transformers进行自然语言处理任务时,通常需要对输入文本进行编码,得到其对应的词向量。由于传统的自然语言处理模型(如RNN和CNN)需要逐个处理输入序列,因此在处理长文本时会带来计算复杂度和内存消耗的问题。为了解决这个问题,Transformers引入了自注意力机制,能够并行处理整个输入序列,从而提高了计算效率。
另外,为了进一步加速Transformers的计算速度,可以使用一种称为Random Fourier Features(RFF)的技术。RFF是一种基于随机映射的技术,可以将输入空间映射到一个高维特征空间中,从而允许在低维空间中进行高维特征的计算。在Transformers中,可以使用RFF来加速自注意力机制的计算。
具体来说,使用RFF加速Transformers的计算过程可以分为以下几个步骤:
-
将输入序列转换为嵌入向量,每个单词都对应一个嵌入向量。
-
将嵌入向量通过一个随机映射矩阵进行线性变换,得到一个新的向量表示。
-
将新的向量表示通过傅里叶变换得到其频域表示。
-
在频域上使用自注意力机制计算注意力权重。
-
将注意力权重与嵌入向量进行加权求和,得到最终的输出表示。
使用RFF加速Transformers的计算可以在一定程度上减少计算复杂度和内存消耗,从而提高模型的计算速度和效率。但是,需要注意的是,RFF的使用可能会对模型的精度产生一定的影响,因此需要根据具体任务和数据集来进行选择和调整。
DDP
DDP(Distributed Data Parallel)是一种分布式训练策略,用于在多台计算机上同时训练深度学习模型。DDP可以加速模型的训练速度,并且可以处理更大规模、更复杂的数据和模型。
在DDP中,训练数据被分成多个部分,每个计算机节点上的模型副本都处理一部分数据。在每个训练步骤结束后,每个节点将梯度信息发送给其他节点,并且每个节点使用这些梯度信息来更新自己的模型副本。这个过程被称为梯度平均或梯度聚合,它可以使得每个节点的模型都能够获得整个数据集的梯度信息,并且保证模型参数保持同步。
DDP还可以使用各种优化策略来加速训练速度,如梯度累积、动态权重平均等。这些策略可以减少节点间的通信量,从而减少训练时间和资源的消耗。
总的来说,DDP是一种用于分布式训练的并行化策略,可以加速深度学习模型的训练速度,并且可以处理更大规模、更复杂的数据和模型。
vit 如何进行优化与加速?
ViT(Vision Transformer)是一种基于Transformer模型的深度学习模型,用于图像分类、目标检测等计算机视觉任务。与其他深度学习模型一样,ViT也可以通过以下方法进行优化和加速:
-
分布式训练:使用多个计算设备同时训练模型,可以加速训练速度。分布式训练可以使用多个CPU或GPU,也可以使用分布式训练框架如Horovod等。
-
模型剪枝:通过剪枝模型中的一些冗余参数和结构,可以减少模型的计算复杂度。剪枝方法可以是基于权重的剪枝、基于通道的剪枝、基于层的剪枝等。
-
模型量化:将模型中的浮点数参数转换为固定位数的整型参数,可以减少模型的存储空间和计算复杂度。模型量化方法可以是对称量化或非对称量化等。
-
自动混合精度:使用半精度浮点数(FP16)代替单精度浮点数(FP32)来存储模型参数和梯度,可以减少模型的存储空间和计算复杂度。同时也可以使用混合精度训练(Mixed Precision Training)技术,通过在前向传播和后向传播中使用不同的精度,来减少计算复杂度。
-
数据增强:通过对训练数据进行旋转、翻转、缩放等变换,可以增加训练数据的多样性,提高模型的泛化能力,并且可以加速训练过程。
-
预训练模型:使用预训练模型可以减少模型的训练时间和计算复杂度。预训练模型通常使用大规模图像数据集进行训练,并可以在图像分类、目标检测等任务中进行微调。
-
模型缓存:使用模型缓存技术可以减少模型计算的重复操作。在模型计算时,将一些中间结果缓存起来,可以在后续计算中重复使用,减少计算时间。
综上所述,通过使用分布式训练、模型剪枝、模型量化、自动混合精度、数据增强、预训练模型和模型缓存等技术,可以有效地优化和加速ViT模型的训练和推理速度。
GFnet
GFNet是一种用于图像分类任务的深度学习模型,它采用了一种基于分组卷积和通道注意力机制的设计。
在GFNet中,输入图像首先通过一个卷积层进行特征提取,然后被分成若干个组。每个组内的通道被分别处理,以提取局部特征。接着,每个组的输出被整合在一起,并通过通道注意力机制进行加权,以提取全局特征。最后,全局特征被送入一个分类器进行分类。
GFNet的设计可以有效地提取图像的局部特征和全局特征,并且具有较好的分类性能。它还具有较低的计算复杂度和参数量,适合在资源受限的设备上部署。
总的来说,GFNet是一种基于分组卷积和通道注意力机制的深度学习模型,适用于图像分类任务,具有较好的性能和较低的计算复杂度。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









