







文章目录
分组函数
功能
用作统计使用,又称为聚合函数或统计函数或组函数
分类
- sum 求和、
- avg 平均值、
- max 最大值、
- min 最小值、
- count 计数(非空)
特点
- sum,avg一般用于处理数值型max,min,count可以处理任何类型
- 以上分组函数都忽略nul1值
- 可以和distinct搭配实现去重的运算
- count函数的单独介绍一般使用count(*)用作统计行数
- 和分组函数一同查询的字段要求是group by后的字段
条件查询
使用WHERE 子句,将不满足条件的行过滤掉,WHERE 子句紧随 FROM 子句。
语法
- select <结果> from <表名> where <条件>
比较查询
- = ------> 并非赋值, Eg: sex = ‘男’
- != 或 <> ------> 不等于
- < , > ------> 小于 , 大于
- <= , >= ------> 小于等于 , 大于等于
逻辑查询
- and 多个条件同时成立 Eg: sex = ‘男’ and score > 60
- or 多个条件满足一个即可
- not 配合is null 使用
模糊查询
- like – 是否匹配于一个模式 一般和通配符搭配使用,可以判断字符型数值或数值型.
- 通配符 – % 任意多个字符,包含0个字符 _ 任意单个字符
- between and – 两者之间,包含临界值;
- in – 判断某字段的值是否属于in列表中的某一项
- is null(为空的)或 IS NOT NULL(不为空的)
SELECT * FROM yhlz_tea WHERE tea_age BETWEEN 60 AND 100
-- in(值1,值2,值n) 在那个范围内
SELECT * FROM yhlz_tea WHERE tea_num IN(0,6)
-- not in 不在不是
SELECT * FROM yhlz_tea WHERE tea_num NOT IN(0,6)
-- 性别不为空
SELECT * FROM yhlz_tea WHERE tea_sex IS NOT NULL
-- like % 匹配多个字符
SELECT * FROM yhlz_tea WHERE tea_name LIKE '牛%'
-- like _ 只能匹配一个
SELECT * FROM yhlz_tea WHERE tea_name LIKE '牛_'
SELECT * FROM yhlz_tea WHERE tea_name LIKE '_奶'
SELECT * FROM yhlz_tea WHERE tea_name LIKE '%奶'




union查询
UNION用的比较多,union all是直接连接,取到得是所有值,记录可能有重复 union 是取唯一值,记录没有重复
union语法
[SQL 语句 1]
UNION
[SQL 语句 2]
SELECT tea_name,tea_sex FROM yhlz_tea WHERE tea_num > 5
UNION
SELECT tea_name,tea_sex FROM yhlz_tea WHERE tea_age > 60
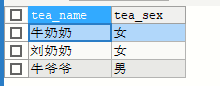
union all 语法
[SQL 语句 1]
UNION ALL
[SQL 语句 2]
SELECT tea_name,tea_sex FROM yhlz_tea WHERE tea_num > 5
UNION ALL
SELECT tea_name,tea_sex FROM yhlz_tea WHERE tea_age > 60
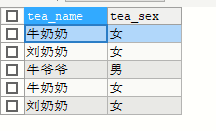
union 和 union all效率对比
- 对重复结果的处理:UNION在进行表链接后会筛选掉重复的记录,Union All不会去除重复记录。
- 对排序的处理:Union将会按照字段的顺序进行排序;UNION ALL只是简单的将两个结果合并后就返回。
从效率上说,UNION ALL 要比UNION快很多,所以,如果可以确认合并的两个结果集中不包含重复数据且不需要排序时的话,那么就使用UNION ALL。
排序查询
查询结果排序,使用 ORDER BY 子句排序 order by 排序列 ASC/DESC
- asc代表的是升序,desc代表的是降序,如果不写,默认是升序
- order by子句中可以支持单个字段、多个字段、表达式、函数、别名
-- 顺序 asc
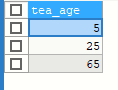
SELECT tea_age FROM yhlz_tea WHERE tea_sex = '男' ORDER BY tea_num
-- 逆序 desc
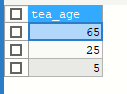
SELECT tea_age FROM yhlz_tea WHERE tea_sex = '男' ORDER BY tea_num DESC
1.顺序
2.逆序
数量限制查询
limit子句:对查询的显示结果限制数目 (sql语句最末尾位置)
语句 : SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset;
- SELECT * FROM table LIMIT 5;
- SELECT * from table LIMIT 0,5;
- SELECT * FROM table LIMIT 2 OFFSET 3;
limit 后面跟一个参数是取多长的量
limit 后面跟俩个参数时,第一个参数表示要眺过的量/ 从第几个开始,第二个参数是,要取的量
limit 和 offset组合时,limit后的数表示要取的量,offset后面的数字表示要跳过的量/从第几个开始
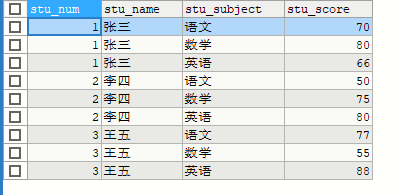
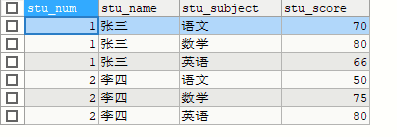
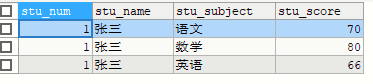
原表信息

1.limit n
SELECT * FROM stu LIMIT 3
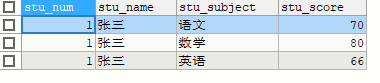
SELECT * FROM stu LIMIT 9
SELECT * FROM stu LIMIT 6
2.limit m,n
SELECT * FROM stu LIMIT 0,3
表示跳过0个/从第0个开始,取3个
SELECT * FROM stu LIMIT 3,3
表示跳过3个/从第3个开始,取3个
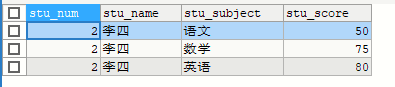
SELECT * FROM stu LIMIT 6,3
表示跳过6个/从第6个开始,取3个

3.limit m offset n
SELECT * FROM stu LIMIT 3 OFFSET 0
表示跳过0个/从第0个开始,取3个
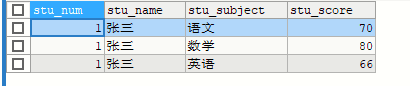
SELECT * FROM stu LIMIT 3 OFFSET 3
表示跳过3个/从第3个开始,取3个
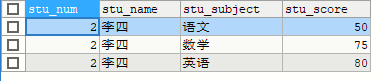
SELECT * FROM stu LIMIT 3 OFFSET 6
表示跳过6个/从第6个开始取3个
分组查询
语法
select 分组函数,列(要求出现在group by的后面)
from 表
[where 筛选条件]
group by 分组的列表
[having 分组后的筛选]
[order by 子句]
注意:查询列表比较特殊,要求是分组函数和group by后出现的字段
分组查询中的筛选条件分为两类:
数据源 源位置 关键字
分组前筛选 原始表 group by子句的前面 where
分组后筛选 分组后的结果集 group by的后面 having
Eg:
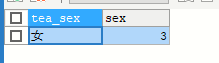
-- 查询性别人数>2 是哪个性别
SELECT tea_sex,COUNT(*) AS sex
FROM yhlz_tea
WHERE tea_num > 3
GROUP BY tea_sex
HAVING sex > 2
ORDER BY sex ASC
LIMIT 1
子查询
出现在其他语句中的select语句,称为子查询或内查询;外部的查询语句,称为主查询或外查询.
分类
按子查询出现的位置
- select后面:仅仅支持标量子查询
- from后面:支持表子查询
- where或having后面:支持标量子查询,列子查询,行子查询(较少)
- exists后面(相关子查询):支持表子查询
按功能、结果集的行列数不同
- 标量子查询(结果集只有一行一列)
- 列子查询(结果集只有一列多行)
- 行子查询(结果集有一行多列)
- 表子查询(结果集一般为多行多列)
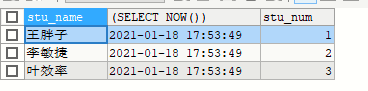
-- 标量子查询 一行一列
SELECT stu_name,(SELECT NOW()),stu_num FROM yhlz_stu
-- 列子查询 一列多行
SELECT * FROM yhlz_stu WHERE stu_grade IN(SELECT stu_grade FROM yhlz_stu WHERE stu_grade > 50)
-- 行子查询 一行多列 学号最大,成绩最大
SELECT * FROM yhlz_stu WHERE (stu_num,stu_grade) = (SELECT MAX(stu_num),MAX(stu_grade)FROM yhlz_stu)
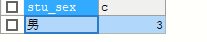
-- 表子查询 多行多列 查询结果当作一章表
SELECT * FROM
(SELECT stu_sex,COUNT(*) AS c FROM yhlz_stu GROUP BY stu_sex) AS t
WHERE t.c > 2
原表信息

1.标量子查询
2. 列子查询

3.行子查询

4.表子查询















 1109
1109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









