






 本文介绍了三种动量更新公式在机器学习和优化算法中的应用,包括基本的梯度下降、引入动量项的改进方法以及考虑二阶导数的二阶动量,这些公式通过调整参数估计与观测值的关系,以加速模型收敛。
本文介绍了三种动量更新公式在机器学习和优化算法中的应用,包括基本的梯度下降、引入动量项的改进方法以及考虑二阶导数的二阶动量,这些公式通过调整参数估计与观测值的关系,以加速模型收敛。
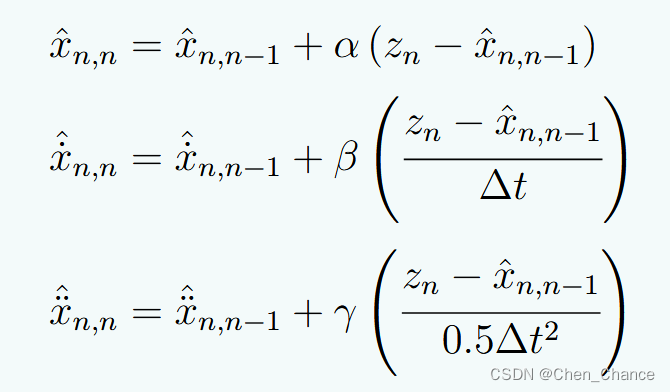
这三个公式描述了动量更新方法,用于优化算法中更新参数的方式。
x ^ n , n = x ^ n , n − 1 + α ( z n − x ^ n , n − 1 ) \hat{x}_{n,n} = \hat{x}_{n,n-1} + \alpha (z_n - \hat{x}_{n,n-1}) x^n,n=x^n,n−1+α(zn−x^n,n−1)
x ^ n , n = x ^ n , n − 1 + β ( z n − x ^ n , n − 1 Δ t ) \hat{x}_{n,n} = \hat{x}_{n,n-1} + \beta \left(\frac{z_n - \hat{x}_{n,n-1}}{\Delta t}\right) x^n,n=x^n,n−1+β(Δtzn−x^n,n−1)
x ^ n , n = x ^ n , n − 1 + γ ( z n − x ^ n , n − 1 0.5 Δ t 2 ) \hat{x}_{n,n} = \hat{x}_{n,n-1} + \gamma \left(\frac{z_n - \hat{x}_{n,n-1}}{0.5\Delta t^2}\right) x^n,n=x^n,n−1+γ(0.5Δt2zn−x^n,n−1)
其中:
- x ^ n , n \hat{x}_{n,n} x^n,n 表示当前时刻 n 的参数估计值
- x ^ n , n − 1 \hat{x}_{n,n-1} x^n,n−1 表示上一时刻 n-1 的参数估计值
- z n z_n zn 表示当前时刻 n 的观测值或目标值
- α \alpha α、 β \beta β、 γ \gamma γ 是步长或学习率参数
- Δ t \Delta t Δt 表示时间步长
这三个公式分别对应不同的动量更新方式,反映了估计值与观测值之间的差异被纳入更新的不同方式。它们常用于机器学习和优化算法中,用于调整模型参数以最小化损失函数或目标函数。
如何推导得来的
这三个公式实际上是描述了三种不同的动量更新方法,它们都是基于牛顿迭代法的思想推导得到的。
第一个公式是最基本的梯度下降法更新公式:
x ^ n , n = x ^ n , n − 1 + α ( z n − x ^ n , n − 1 ) \hat{x}_{n,n} = \hat{x}_{n,n-1} + \alpha (z_n - \hat{x}_{n,n-1}) x^n,n=x^n,n−1+α(zn−x^n,n−1)
其中 α \alpha α 是步长,它根据目标函数对参数 x x x 的梯度进行更新。
第二个公式引入了动量项:
x ^ n , n = x ^ n , n − 1 + β ( z n − x ^ n , n − 1 Δ t ) \hat{x}_{n,n} = \hat{x}_{n,n-1} + \beta \left(\frac{z_n - \hat{x}_{n,n-1}}{\Delta t}\right) x^n,n=x^n,n−1+β(Δtzn−x^n,n−1)
它将目标函数对参数 x x x 的梯度近似为 ( z n − x ^ n , n − 1 ) / Δ t (z_n - \hat{x}_{n,n-1})/\Delta t (zn−x^n,n−1)/Δt,即在时间步长 Δ t \Delta t Δt 内的变化率。 β \beta β 是动量系数,通过加入过去的梯度信息来加速收敛。
第三个公式进一步引入了二阶动量项:
x ^ n , n = x ^ n , n − 1 + γ ( z n − x ^ n , n − 1 0.5 Δ t 2 ) \hat{x}_{n,n} = \hat{x}_{n,n-1} + \gamma \left(\frac{z_n - \hat{x}_{n,n-1}}{0.5\Delta t^2}\right) x^n,n=x^n,n−1+γ(0.5Δt2zn−x^n,n−1)
它将目标函数对参数 x x x 的梯度近似为 ( z n − x ^ n , n − 1 ) / ( 0.5 Δ t 2 ) (z_n - \hat{x}_{n,n-1})/(0.5\Delta t^2) (zn−x^n,n−1)/(0.5Δt2),即在时间步长 Δ t \Delta t Δt 内的加速度变化。 γ \gamma γ 是二阶动量系数,通过加入过去的加速度信息来进一步加速收敛。
这些公式的推导思路源自于牛顿迭代法,通过近似目标函数的一阶和二阶导数并结合前一时刻的状态进行参数更新,从而达到加速优化收敛的目的。不同的动量更新方法对应于不同的导数近似方式。
0.5怎么得到的
公式中0.5的存在是为了近似二阶导数。具体来说:
x ^ n , n = x ^ n , n − 1 + γ ( z n − x ^ n , n − 1 0.5 Δ t 2 ) \hat{x}_{n,n} = \hat{x}_{n,n-1} + \gamma \left(\frac{z_n - \hat{x}_{n,n-1}}{0.5\Delta t^2}\right) x^n,n=x^n,n−1+γ(0.5Δt2zn−x^n,n−1)
这个公式试图用 ( z n − x ^ n , n − 1 ) / ( 0.5 Δ t 2 ) (z_n - \hat{x}_{n,n-1})/(0.5\Delta t^2) (zn−x^n,n−1)/(0.5Δt2) 来近似目标函数对参数 x x x 的二阶导数,即加速度。
在数值计算中,常用有限差分法来近似导数。对于一个函数 f ( x ) f(x) f(x),它的一阶导数可以用如下方式近似:
f ′ ( x ) ≈ f ( x + Δ x ) − f ( x ) Δ x f'(x) \approx \frac{f(x+\Delta x) - f(x)}{\Delta x} f′(x)≈Δxf(x+Δx)−f(x)
而二阶导数可以用如下方式近似:
f ′ ′ ( x ) ≈ f ( x + Δ x ) − 2 f ( x ) + f ( x − Δ x ) Δ x 2 f''(x) \approx \frac{f(x+\Delta x) - 2f(x) + f(x-\Delta x)}{\Delta x^2} f′′(x)≈Δx2f(x+Δx)−2f(x)+f(x−Δx)
注意到上式分母的 Δ x 2 \Delta x^2 Δx2。
将此思路应用到时间域,用 Δ t \Delta t Δt 替代 Δ x \Delta x Δx,就有:
d 2 x d t 2 ≈ x ( t + Δ t ) − 2 x ( t ) + x ( t − Δ t ) Δ t 2 \frac{d^2x}{dt^2} \approx \frac{x(t+\Delta t) - 2x(t) + x(t-\Delta t)}{\Delta t^2} dt2d2x≈Δt2x(t+Δt)−2x(t)+x(t−Δt)
进一步化简,我们可以得到:
d 2 x d t 2 ≈ x ( t + Δ t ) − x ( t ) Δ t 2 / 2 \frac{d^2x}{dt^2} \approx \frac{x(t+\Delta t) - x(t)}{\Delta t^2/2} dt2d2x≈Δt2/2x(t+Δt)−x(t)
所以0.5就是为了对应上面这个二阶导数的近似形式,使得 ( z n − x ^ n , n − 1 ) / ( 0.5 Δ t 2 ) (z_n - \hat{x}_{n,n-1})/(0.5\Delta t^2) (zn−x^n,n−1)/(0.5Δt2) 可以近似加速度项。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









