







多任务原理
什么叫多任务? ? ?
- 现代操作系统(Windows. Mac OS、Linux、 UNIX等)都支持
多任务 - 操作系统同时可以运行多个任务
单核CPU实现多任务原理
操作系统轮流让各个任务交替执行,QQ执行2us,切换到微信,在执行2us, 再切换到陌陌,执行.2…表面是看,每个任务反复执行下去
但是CPU调度执行速度太快了,导致我们感觉就像所有任务都在同时执行一样
多核CPU实现多任务原理
真正的并性执行多任务,只能在多核CPU上实现,但是由于任务数量远远多于CPU的核心数量,所以,操作系统也会自动把很多任务轮流调度到每个核心上执行
并发:看上去一起执行,任务书数多于CPU核心数并行:真正起执行,任务数小于等于CPU核心数
实现多任务的方式:
- 多进程模式
- 多线程模式
- 协程模式
- 多进程+多线程模式
进程
对于操作系统而言,一个任务就是一个进程。
进程是系统中程序执行和资源分配的基本单位,每个进程都有属于自己的数据段、代码段、堆栈段,互不干扰,互不影响
单任务现象
import time
def run():
while True:
print("aaa")
time.sleep(1.2)
if __name__ == "__main__":
while True:
print("jack")
time.sleep(1)
# 永远也不会执行到run方法,只有上面的while循环结束才可以执行。
# 这是单任务现象。
run()
运行结果:

永远也执行不到上面的run方法中的aaa,这就是单线程,只能等一个执行完了再执行另一个
启动进程实现多任务
import os
from multiprocessing import Process
import time
# 子进程需要执行的代码
def run(value):
while True:
# os.getpid()获取当前进程的id号
# os.getppid()获取当前进程的父进程的id号
print("aaa----%s----%s----%s" % (value, os.getpid(), os.getppid()))
time.sleep(1.2)
if __name__ == "__main__":
print("主(父)进程启动 %s" % (os.getpid()))
# 创建子进程
# target说明进程执行的任务
# args可以传参,因为是元组,所以只传一个参数要加逗号
p = Process(target=run, args=("ok",))
# 启动进程
p.start()
while True:
print("jack")
time.sleep(1)
运行结果:

可以很明显的看到,两个是同时进行的,因为停顿的秒数不同,但确确实实是两个while True在运行,很神奇,另外(target=run),方法是不需要加括号的,只需要传入方法名就行
父进程和子进程的先后顺序
from multiprocessing import Process
import time
def run():
print("子进程开始")
time.sleep(2)
print("子进程结束")
def eat():
print("开始吃")
time.sleep(1)
print("吃完了")
if __name__ == "__main__":
print("父进程开始")
p = Process(target=run)
p.start()
p1 = Process(target=eat)
p1.start()
# 可以发现,父进程根本也没有等子进程执行完在结束,而是各执行各的
time.sleep(1)
print("父进程结束")
运行结果:

可以发现,父进程根本也没有等子进程执行完在结束,而是各执行各的,但是这并不符合常规
正常的应该是老板(父进程)指挥员工(子进程)做事
让父进程等待子进程执行完之后再结束
from multiprocessing import Process
import time
def run():
print("子进程开始")
time.sleep(2)
print("子进程结束")
def eat():
print("开始吃")
time.sleep(1)
print("吃完了")
if __name__ == "__main__":
print("父进程开始")
p = Process(target=run)
p.start()
p1 = Process(target=eat)
p1.start()
# 要想让父进程等待子进程执行完在结束,在下面加个.join()
p.join()
p1.join()
time.sleep(1)
print("父进程结束")
运行结果:

启动大量子进程
查看电脑核心数的方法
1、打开任务管理器
2、点击性能
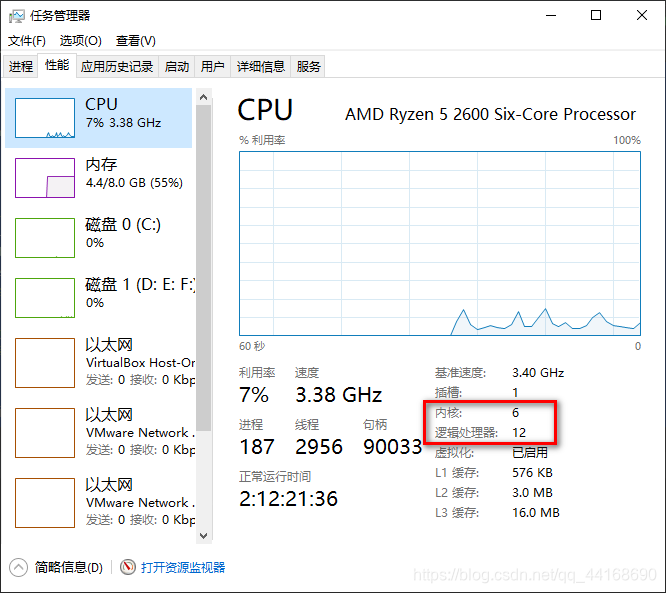
3、查看核心数,上面显示的是6核心,12个逻辑处理器,说明我们可以同时进行12个任务
例子:
import os
import random
import time
from multiprocessing import Pool
def run(name):
print("子进程%d启动--%s" % (name, os.getpid()))
start = time.time()
time.sleep(random.choice([1, 2, 3]))
end = time.time()
print("子进程%d结束--%s--耗时%.2f" % (name, os.getpid(), end - start))
if __name__ == "__main__":
print("父进程启动")
# 创建多个进程
# 进程池
# Pool(n) n表示可以同时执行的进程数量,不写的话,默认大小为CPU核心数
pool = Pool(4)
for i in range(1, 6):
# 创建进程,放入进程池统一管理
pool.apply_async(run, args=(i,))
# 在调用join之前必须先调用close,调用close之后就不能再继续添加新的进程了
pool.close()
pool.join()
print("父进程结束")
运行结果:

请看仔细一点,在进程2结束的瞬间,进程5启动,而且他们用的是同一个进程号,是这个进程工作完立马去工作下一个!
笔者因为偷懒,所以用循环处理一种方法,如果要进行不同的进程
例子:
# 我们可以这样
if __name__ == "__main__":
print("父进程启动")
# 因为要执行的进程大于我们池子的容量,才看得出效果
pool = Pool(2)
# 定义不同的进程
pool.apply_async(run1)
pool.apply_async(run2)
pool.apply_async(run3)
pool.close()
pool.join()
print("父进程结束")
因为笔者比较偷懒,故没有作演示,请见谅
全局变量在多个进程中不能共享
from multiprocessing import Process
import time
num = 100
def run():
print("子进程开始")
# 若想在函数内部对函数外的变量进行操作,就需要在函数内部声明其为global
global num
num += 1
time.sleep(2)
print("子进程结束")
def eat():
print("开始吃")
time.sleep(3)
print("吃完了")
if __name__ == "__main__":
print("父进程开始")
print(num)
p = Process(target=run)
p.start()
p.join()
# 在子进程中修改全局变量对父进程中的全局变了没有影响
# 在创建子进程时对全局变量做了一个备份,父进程中的与子进程中的num是两个完全不同的两个变量
# 两个子进程中也不能共享
print("父进程结束")
运行结果:

可以看到,num数并没有改变,所以每个子进程都是单独工作的,全局变量在多个进程中不能共享
单进程拷贝文件
文件是15个空白的文本文档
import os
import time
def copy(readPath, writePath):
# 读取两个文件
fr = open(readPath, "rb")
fw = open(writePath, "wb")
# 读并写入
context = fr.read()
fw.write(context)
# 关闭
fr.close()
fw.close()
path = r"D:\新建文件夹\copy"
topath = r"D:\新建文件夹\tocopy"
# 读取path下的所有的文件
fileList = os.listdir(path)
# 启动for循环处理每一个文件
start = time.time()
for fileName in fileList:
copy(os.path.join(path, fileName), os.path.join(topath, fileName))
end = time.time()
print("总耗时:%.5f" % (end - start))
运行结果:
总耗时:0.00400
多进程拷贝文件
import os
import time
from multiprocessing import Pool
def copy(readPath, writePath):
# 读取两个文件
fr = open(readPath, "rb")
fw = open(writePath, "wb")
# 读并写入
context = fr.read()
fw.write(context)
# 关闭
fr.close()
fw.close()
path = r"D:\新建文件夹\copy"
topath = r"D:\新建文件夹\tocopy"
if __name__ == "__main__":
# 读取path下的所有的文件
fileList = os.listdir(path)
start = time.time()
pool = Pool(6)
for fileName in fileList:
pool.apply_async(copy, args=(os.path.join(path, fileName), os.path.join(topath, fileName)))
pool.close()
pool.join()
end = time.time()
print("总耗时:%.5f" % (end - start))
运行结果:
总耗时:0.19804
对比一下,是不是很惊讶,为什么多进程比单进程慢呢?
极少的数据,多进程会比单进程慢,只有多的数据才能体现出优势- 但是要是100个进程一起工作,理论上也不会快很多,因为因为多进程
启动也费时间和资源,销毁也费时间与资源
我们现在测试一下2G,27个资源
- 单进程:总耗时:19.93352
- 多进程:总耗时:15.03159
总而言之,多进程理论上是比单进程快些
封装进程对象
我们先创建进程类
名字叫jackProcess.py
import time
from multiprocessing import Process
import os
# 继承自Process
class JackProcess(Process):
def __init__(self, name):
Process.__init__(self)
self.name = name
def run(self):
print("子进程(%s--%s)启动" % (self.name, os.getpid()))
time.sleep(2)
print("子进程(%s--%s)结束" % (self.name, os.getpid()))
然后再把类实例化
创建一个新文件
from jackProcess import JackProcess
if __name__ == "__main__":
print("父进程启动")
# 创建子进程
pool = JackProcess("test")
# 自动调用pool进程对象的run方法
pool.start()
pool.join()
print("父进程结束")
运行结果:

不知道大家有没有注意,我们这里并没有调用run方法,然后也可以执行,这是为什么呢?
因为我们使用pool.start的时候,它会自动调用类里面的方法,很方便,如果有100个方法需要我们去调用,那把进程封装进对象,这样无疑是最方便最快速的
进程间通信
进程中的子进程是不能共享数据的,但是能互相拿数据和给数据
用multiprocessing中的Queue类
相当于把子进程A的东西传到队列中去,然后子进程B再从队列中拿数据
from multiprocessing import Process, Queue
import os
import time
def write(queue):
print("启动写子进程--%s" % (os.getpid()))
for i in range(1,5):
# 把数据给队列
queue.put(i)
time.sleep(1)
print("结束写子进程--%s" % (os.getpid()))
def read(queue):
print("启动读子进程--%s" % (os.getpid()))
while True:
# 从队列里面拿数据,True是一直拿
value = queue.get(True)
print("value = " + str(value))
print("结束读子进程--%s" % (os.getpid()))
if __name__ == "__main__":
print("父进程开始")
# 父进程创建队列,并传递给子进程
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 虽然这两个先是pw在前,但是不一定执行的时候是pw在前
pw.start()
pr.start()
pw.join()
print("父进程结束")
为什么拿要用死循环呢?因为read方法如果从队列里面拿的话,根本不知道什么时候拿,拿什么,所以我们要一直拿
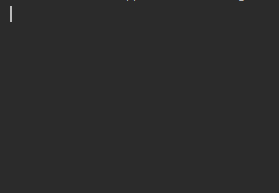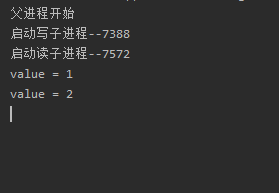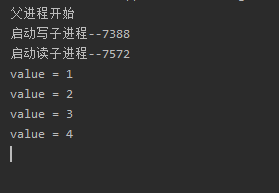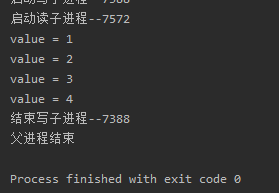
运行结果:
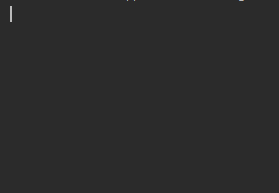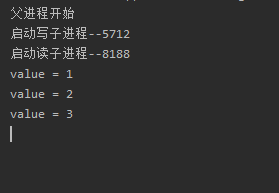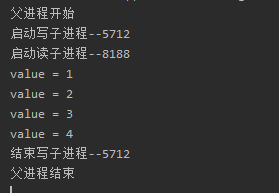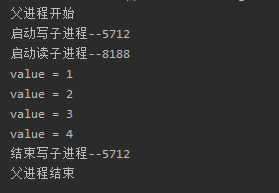
有发现,我们的程序一直都在运行,这是为什么呢?因为我们的read方法是死循环,根本结束不了,所以我们要强制性结束
pw.join()
# pr进程里面是个死循环,无法等待其结束,只能强行结束
pr.terminate()
print("父进程结束")
运行结果:
如果有错误或者有疑问,请私信我喔,感谢观看














 447
447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









