






KMP算法
- 简介:解决字符串匹配问题,用模式串 p 匹配文本串 T。暴力匹配的时间复杂度是 O(mxn)。KMP 算法是针对暴力匹配算法的一次巧妙的改进。核心思想就是将匹配失败的信息利用起来,减少回退的次数,使文本串的指针可以始终向前推进。所以如何利用失败信息呢?
- 具体实现步骤:当文本串第
k+1个元素匹配失败时,我们知道前面k个字符都是匹配上了的,即P[0:k] = T[q:q+k](左闭右开区间)。这里面是有信息可以使用的,我们可以尝试找到P[0:k]中最长的前缀0 ~ j,满足与后缀k-j ~ k相同,那就可以只回退模式串指针来比较P[j+1]与T[q+k],如果相等比较继续进行,如果失败继续回退模式串。 - next 数组:这样就需要维护一个能指示回退位置的 next 数组,注意这个数组仅与模式串有关,可以在执行匹配前实现好。next 数组是前缀表,存储的是模式串的不同子串所具有的相同前后缀的最大长度。注意前缀表的作用是当前位置匹配失败时,指示模式串指针应回退到哪个位置。

- 关于前后缀的定义:前缀是不包含最后一个字符的所有以第一个字符开头的连续子串;后缀是不包含第一个字符的所有以最后一个字符结尾的连续子串。
- 时间复杂度分析:KMP 算法中文本串的指针是始终向前的,即 O(n)。但是获得 next 数组需要额外的开销,因此总体时间复杂度为 O(m+n)。
- next 数组的获取。可以使用 left、right 双指针来实现,初始时
left = 0, right = 1。left 代表相同前缀的最后位置,right 代表后缀的最后位置,同时 left 也是相等前后缀的长度。
如果p[left] != p[right],那就需要回退 left,这与字符串匹配失败是类似的,我们要尽量保留已经确定相等的前后缀(利用已经匹配的信息),所以我们使用相同的方式回退即可(循环过程的不变量);如果二者相等,left 向后更新一个位置。
由以上的分析可知,left 之前都是已经确定的相等前缀,即 p[0, left) = p[right-left, right)。当不相等发生时,我们要利用已经匹配的信息,从 p[0, left) 中选择最长前缀使之与 p[right-left, right) 的后缀相等。具体做法是若 j = next[left- 1],即p[0, j) = p[left-j, left) = p[right-j, right),我们就又找到了一段长为 j 的已经判断相等的前后缀,继续比较 p[j] 和 p[right] 就可以了。
class Solution{
public:
void getNext(int* next, string s){
int left = 0;
next[0] = left;
for(int right = 1; right < s.size(); right++){
while(left > 0 && s[left] != s[right]){
left = next[left - 1];
}
if(s[left] == s[right]){
left++;
}
next[right] = left;
}
}
int strStr(string haystack, string needle){
int i = 0; // 文本串指针
int j = 0; // 模式串指针
int next[needle.size()];
getNext(next, needle);
for(; i < haystack.size(); i++){
while(j > 0 && haystack[i] != needle[j]){
j = next[j - 1];
}
if(haystack[i] == needle[j]){
j++;
}
if(j == needle.size()){
return (i - needle.size() + 1);
}
}
return -1;
}
};
有一些实现中,next 数组取值为前缀表整体减1,其实和这种原封不动使用前缀表的实现相比,原理是一样的,只是 KMP 算法不同的实现而已。但要注意回退时的下标与遍历时的下标,整体减1的实现中,在比较时模式串指针应该在 j+1 的位置,回退时则不需要进行 j-1 的操作,j = next[j]。
class Solution{
public:
void getNext(int* next, string s){
int left = -1;
next[0] = left;
for(int right = 1; right < s.size(); right++){
while(left > -1 && s[left + 1] != s[right]){
left = next[left];
}
if(s[left + 1] == s[right]){
left++;
}
next[right] = left;
}
}
int strStr(string haystack, string needle){
int i = 0; // i为文本串指针
int j = -1; // j+1为模板串指针
int next[needle.size()];
getNext(next, needle);
for(; i < haystack.size(); i++){
while(j > -1 && haystack[i] != needle[j+1]){
j = next[j];
}
if(haystack[i] == needle[j+1]){
j++;
}
if(j == needle.size() - 1){
return (i - needle.size() + 1);
}
}
return -1;
}
};
重复的子字符串

我们当然可以想到暴力解法,即遍历不同长度的前缀,使之与 s 进行匹配,由于子串需要重复,这里我们只需要遍历能被s.size()整除的长度,并且只需要遍历到 s 长度的一半位置。
上面算法的时间复杂度基本就是 O(n^2)。
移动匹配
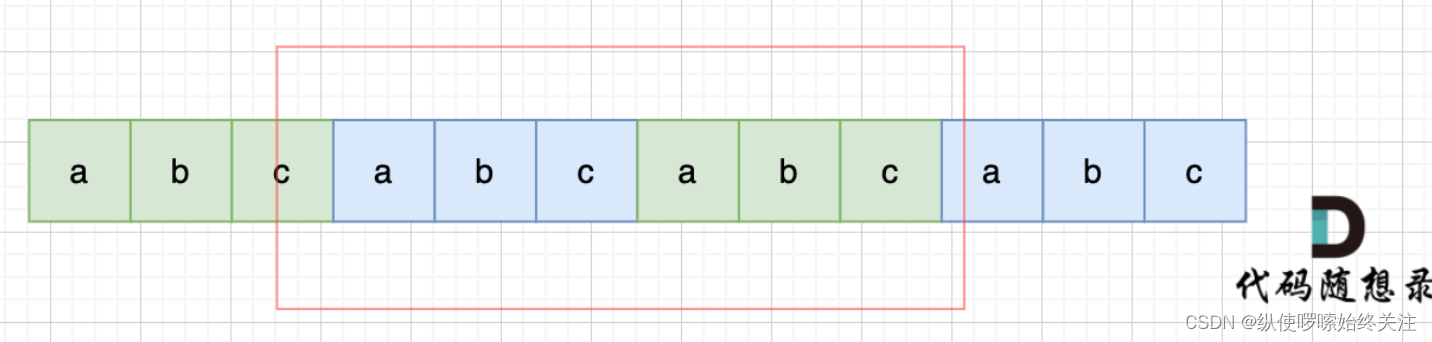
如果一个字符串可以由重复的子串组成,那么当两个这样相同的字符串 s 拼接成一个新字符串 t=s+s 时,一定可以在掐头去尾的 t 中找到原字符串 s,也就是肯定可以由原字符串的后缀和前缀拼出一个原字符串。
class Solution{
public:
bool repeatedSubstringPattern(string s){
string t = s + s;
t.erase(t.begin());
t.erase(t.begin() + t.size() - 1);
if(t.find(s) == std::string::npos) return false;
return true;
}
};
库函数find()的时间复杂度为 O(m+n),不一定是 KMP 算法。本方法的时间复杂度为 O(n)。
KMP 算法实现
KMP 算法本来是用来进行字符串匹配的,与确定重复子串有什么关系呢?先说结论:在重复子串组成的字符串中,最长相等前后缀不包含的子串就是最小重复子串。
我们知道当前位置匹配失败时,KMP 算法通过 next 数组来确定回退位置。next 数组就是前缀表,里面是以各个位置为终点的子字符串的最长相等前后缀的长度。如下图所示,最长相等前后缀的性质使得不被包含的子串可以递推地传递下去。

这样就容易判断了,如果不包含的子串长度可以整除原字符串的长度,证明原字符串可以由不包含的子串重复组成。
class Solution{
public:
bool repeatedSubstringPattern(string s){
int len = s.size();
int next[len];
int left = 0;
next[0] = left;
for(int right = 1; right < s.size(); right++){
while(left > 0 && s[left] != s[right]){
left = next[left - 1];
}
if(s[left] == s[right]){
left++;
}
next[right] = left;
}
return next[len - 1] != 0 && len % (len - next[len - 1]) == 0;
}
};















 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









