







论文引用:
Hosseini, A., Hashemzadeh, M., & Farajzadeh, N. (2022). UFS-Net: A unified flame and smoke detection method for early detection of fire in video surveillance applications using CNNs. J. Comput. Sci., 61, 101638.
论文地址:
 https://github.com/alihosseinice/UFS-Net
https://github.com/alihosseinice/UFS-Net1. 摘要
基于机器的火灾检测可能是现代监视系统中最重要的任务之一。大多数现有的基于计算机视觉的火灾检测方法仅能够检测出一种火焰或烟雾。在这项研究中,提出了一种基于深度学习的统一火焰和烟雾检测方法,称为“ UFS-NET”。高效且量身定制的卷积神经网络体系结构旨在检测视频框架中的火焰和烟雾。 UFS-NET能够通过将视频帧分为八类来识别火灾危害:1)火焰,2)白烟,3)黑烟,4)火焰和白烟,5)火焰和黑烟,6)黑烟和黑烟白烟,7)火焰,白烟和黑烟,以及8)正常状态。为了进一步提高UFS-NET的可靠性,应用了基于投票方案的决策模块。此外,一个名为“ UFS-DATA”的丰富注释数据集,其中包括849,640张图像和26个视频,从各种数据源捕获收集了本研究中的各种数据源和人工图像,准备训练和评估UFS-NET。在“ UFS-DATA ”和其他基准数据集(即“ Mivia ”,“ Bowfire ”和“ Firenet ”)上进行的广泛实验,以及与最先进方法的比较,确认UFS-Net 的高性能网。
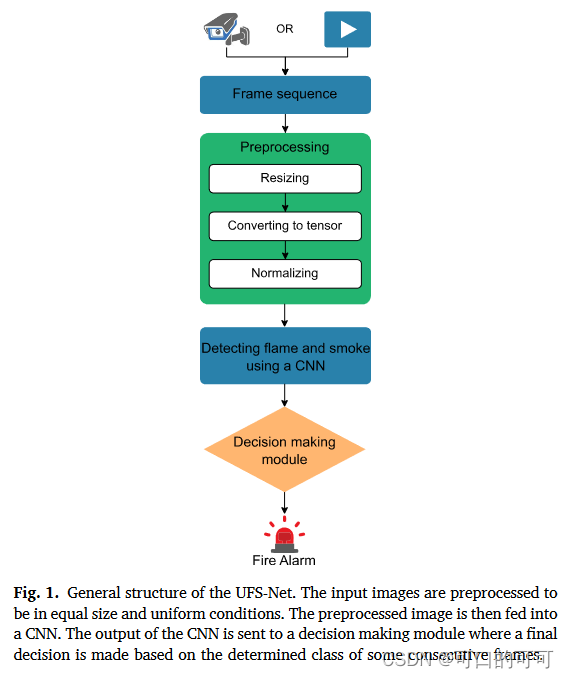
2. 整体结构
UFS-NET的一般结构如图1所示。如图所示,系统开始从各种来源接收一系列视频帧,例如监视摄像机或视频文件。来自不同来源的输入图像可能处于不同的状况和大小。因此,他们将经历一个由三个连续操作组成的预处理阶段。然后,每个预处理图被传入CNN中并分为8类:1)火焰,2)白烟,3)黑烟,4)火焰和白烟,5)火焰和黑烟,6)黑烟和白烟,7)火焰,白烟和黑烟,以及8)正常状态。之后,将CNN的输出发送到决策模块,其中根据某些连续帧的确定类做出最终决策。下面的每个步骤将在下面详细说明。
2.1 预处理
在将其传入CNN之前,对每个输入图像(视频帧)进行了一些预处理操作,包括调整大小,转换为张量和归一化。从不同监视摄像机接收的帧序列通常具有不同的尺寸,例如1920×1080,1280×720,640×480像素,有时图像的方向也可能是不同的。每个输入图像的大小为224×224像素。根据我们的经验,这种大小足以满足我们系统的条件。
训练脚本中预处理代码:
# Preprocessing Operations
transform = transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.4486, 0.4339, 0.4241], [0.2409, 0.2420, 0.2494])
])调整大小的图像被转换为3D张量(红色,绿色和蓝色通道),并最终使用Z评分归一化。最初计算用于训练CNN的图像中颜色通道的平均值和标准偏差。然后应用等式。 对于输入图像的所有像素,计算每个像素的颜色通道的三个新值。

模型代码中的对于三个通道的处理:
def _transform_input(self, x):
# type: (Tensor) -> Tensor
if self.transform_input:
x_ch0 = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_ch1 = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_ch2 = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat((x_ch0, x_ch1, x_ch2), 1)
return x处理效果:

2.2 CNN结构
整体结构
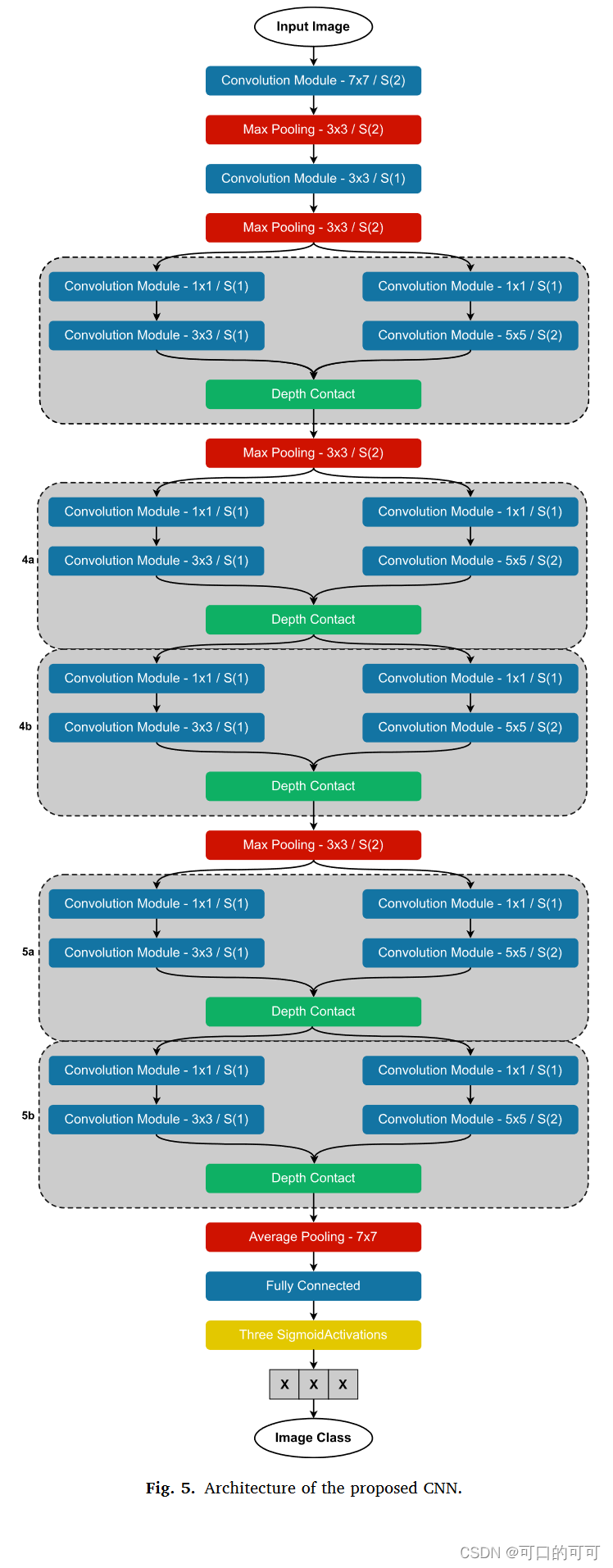
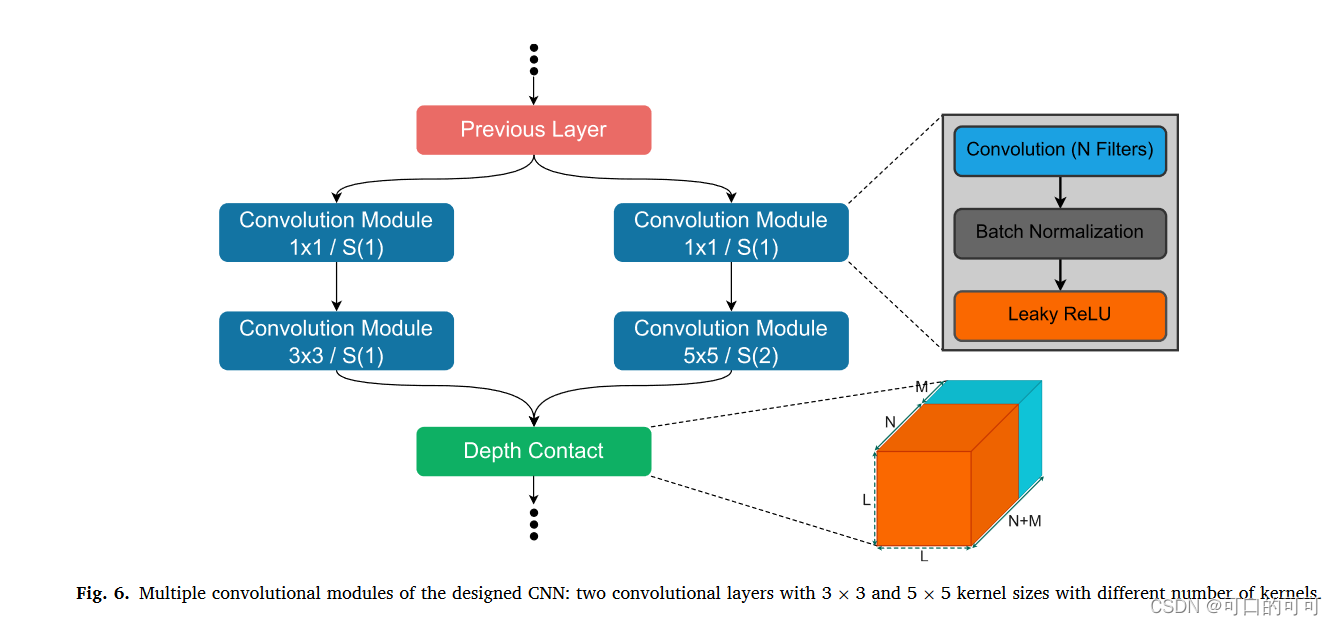
muitiple convolution 结构
如图6所示,在设计的CNN的多重卷积模块中,有两个卷积层,具有3×3和5×5的内核大小,具有不同数量的核。由于处理资源的局限性以及这些卷积层的沉重处理负载,来自上一模块的特征图需要先通过一个卷积核为1×1的卷积模块,这个1×1的卷积层显然减少了CNN处理载荷。通过这种节省,我们可以增加3×3 5×5 filters 的数量,从而提高最终模型的性能。
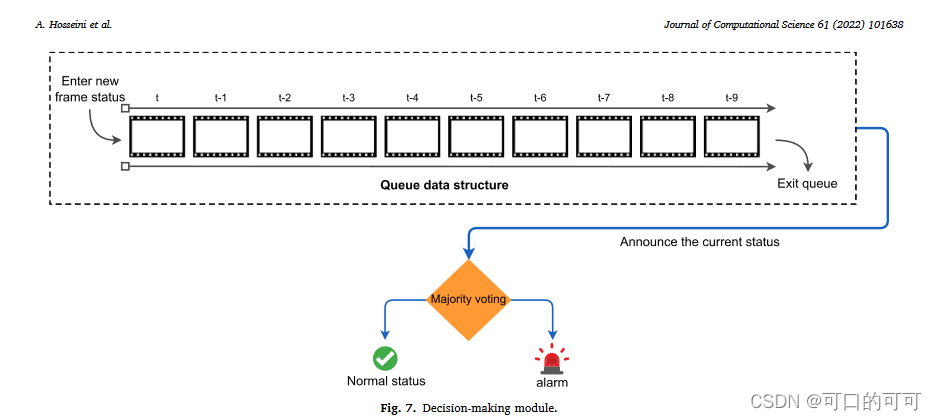
3. 决策模块
为了提高系统可靠性,尤其是降低错误警报率,我们使用连续几个帧上的检测结果来做出最终的警报决定。为了确定环境的当前状态,我们使用检测到火灾随后的10帧画面(个人理解)。如图7所示,这是由队列数据结构(尺寸= 10)和投票阈值完成的,以做出决定。因此,在对输入图像进行分类之后,预测标签被送入队列。该队列包含最后十帧的状态。如果这十个框架中至少有70%处于危险之中(火焰/烟雾),则将环境的最终状态宣布为危险,并触发警报。在此决策模块中使用的70%的阈值值实际上是根据对不同视频的实验选择的。但是,对于此阈值,系统性能在55〜85%的范围内没有显着变化。文中提供了有关选择队列大小和投票阈值的详细信息。大火开始时,系统将被延迟10 frame 宣布状态。但是,由于现代摄像机通常具有超过10的帧速率,因此延迟不到一秒钟。
4. 数据集
基于深度学习的方法会自动从原始数据中提取所需的功能。因此,适当且充分的培训数据集是他们培训中最具影响力的因素之一。如果培训数据还不够,该模型将尝试学习具有不足数据的大量参数,从而导致过度拟合的问题。由于缺乏烟雾和火焰检测场中的标准,足够和标记的数据集,我们收集了一个名为“ UFS-DATA”的丰富注释的火灾数据集,其中包括各种不同的火灾场景和条件,来自不同来源培训和评估所提出的方法。此外,我们在我们的评估中使用了其他三个基准数据集,即“ Mivia (2)”“ Bowfire” [25]和“ Firenet” [3]。在以下内容中,介绍了如何提供UFS-DATA的详细信息,并引入了这三个基准数据集。
4.1 UFS-Data
该数据集由两个部分组成:1)总共26个标记为Videos,2)总计849,640个标记的图像。为了提供第一部分,我们从不同的火灾场景中录制了15个视频。通过搜索 Aparat(3) 和 Shutter Stock(4)中的相关关键字来收集其他视频。ShutterStock收集的视频中的颜色和纹理与Fire条件最相似。
(2) https://mivia.unisa.it/datasets/video-analysis-datasets/fire-detection-dataset/
(3) https://www.aparat.com/
(4) https://www.shutterstock.com/

UFS-DATA的第二部分总共包含849,640个标记的图像(如表4所述),这是从三个来源的组合:1)现实世界视频,2)现实世界图像和,3)人造图像。在下文中,详细描述了从上述三个来源收集数据集的这一部分的过程。
4.1.1 Real-world videos
现实世界的视频:此集合包含2050个火灾视频和350个非火灾视频(正常状态),在不同的条件和场景中。这些是通过在YouTube和ShutterStock网站上搜索不同关键字来收集的。这些视频的一些示例帧如图9(文中)所示。由于视频中的连续帧没有很大不同,因此我们从每个视频中提取连续六个帧之一(即帧1、7、13,...) 。提取的图片用表4中定义的八个类手动注释。

4.1.2 Real-world images
现实世界图像:此集合包含各种单独的图像。这些图像的一部分是从[3]中使用训练数据集中收集的,其余的来自Flickr网站(5),这是不同类别图像的重要来源。在表5中,显示了在 flickr website 中搜索的使用的关键字的详细信息以及每个关键字所获得的图像的数量。从不同类别收集了总共30,668张图像,并根据其内容手动注释为不同的类。
4.1.3 Artificial images
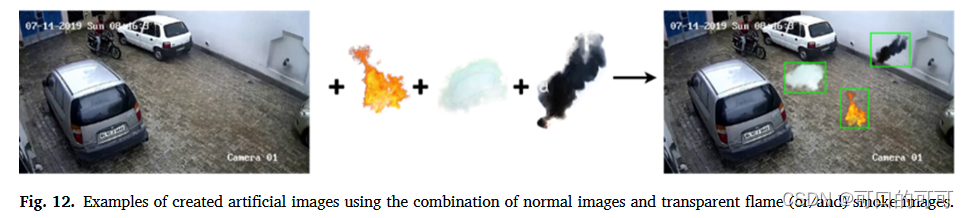
人造图像:为了丰富我们的培训数据集,我们在不同的火灾情况下人为地创建火影图像。为此,我们使用在现实世界中录制的65个YouTube监视摄像机视频,呈现正常情况(无火的场景)。我们从这些视频中的每个视频中提取每20个连续的帧之一,从而产生大图。这些图像的一些示例如图10所示。然后,我们从收集的数据集中分别提取火焰区域,白烟区和黑烟区域的472、425和417透明图像(.png)。这些透明图像的某些样本如图11所示。之后,通过随机选择正常图像和一个(或更多)透明图像的火焰或烟雾,我们将它们组合起来以创建新的图像,以呈现火。通过这种方式,在不同类型的不同条件下创建了大量多样化的人造火图像数据集。
为了确保更高的多样性,我们执行操作的随机组合,例如水平翻转,垂直翻转,随机角度旋转,放大并放大选定的PNG图像,然后将它们放在正常图像上。这使得CNN能够在训练集中具有场景的正常状态和同一场景的各种情况,并从图像差异中学习更好。图12中说明了获得的人造火图像的一些示例。

4.2 Mivia video dataset
该数据集包括14个视频,其中包含火焰和17个没有火焰的视频。一些带有普通标签(无火焰)的视频包含烟雾。由于UFS-NET中的统一火焰和烟雾检测,该数据集中的此类视频被重新检查,并将适当的标签分配给每个帧。所获得的数据集的详细信息在表6中汇总。该数据集的一些示例视频帧如图13所示。

4.3 BoWFire image dataset
该数据集包含226个不同的图像,其中119张图像包含不同条件下的火灾,而107张图像是正常和非火焰图像。该数据集的示例如图14所示。尽管大小很小,但该数据集包含红色和类火目标,太阳光,火颜色的灯,等等。
4.4 FireNet image dataset
该数据集包含593个不同的火灾图像和300张普通图像,这对于评估系统的错误警报率非常具有挑战性[3]。该数据集的一些示例如图15所示。
只使用UFS-DATA的第二部分(即849,640张图像)用于训练提出的方法,其余数据集(即UFS-Data中的26个视频,Mivia ,Bowfire和Firenet数据集用于评估该方法。获得的结果将在下一部分中介绍。
5. 评估
5.1 评估指标
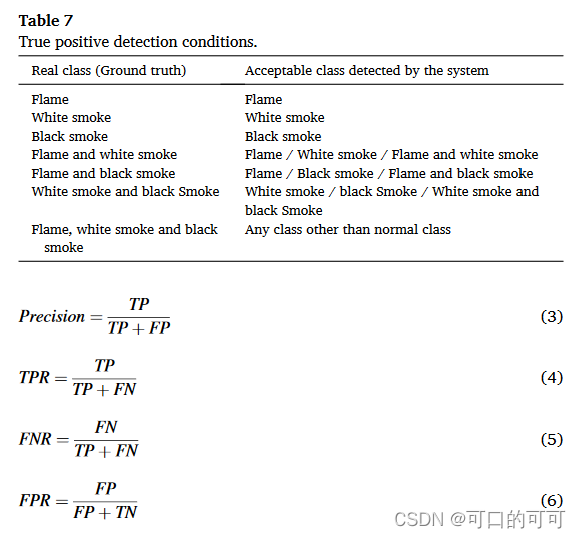
在获得每个帧的系统输出并将其与相应的过 ground truth(数据集中的相应标签)进行比较之后,可能会发生四种不同的检测条件:

TP : 预测到的火焰或者烟雾与 ground truth 相同或者有一个符合就属于TP, 如表7
TN : 框架的预测标签是“正常”的,ground truth 也是“正常的”。
FN : frame的预测标签是“正常的”,ground truth 是另外一回事。
FP : frame 的预测标签是火焰,白烟,黑烟,火焰和白烟,火焰和黑烟,白烟和黑烟,火焰和白烟和黑烟,ground truth 是“正常的”。
四个上述状态用于计算 Accuracy,Precision,TPR(真正的正率),FNR(假阴性率)和FPR(假阳性率)的评估指标,如下:
![]()
5.2 评估结果
实验1:UFS-NET的性能评估并将其与其他方法进行比较
本节根据以上提出的评估指标以及使用引入的测试数据集评估了UFS-NET的性能。因此,由于该领域中的大多数现有方法会单独进行火焰或烟雾检测,因此,我们将UFS-NET与火焰或烟熏方法分别比较。根据实验中使用的数据集的可用性以及相关出版物中这些数据集报告的结果选择这些方法,这使得可以公正地将所提出方法的结果与它们进行比较。由于其他方法对每个帧单独执行分类操作,以确保进行公平的比较,因此我们禁用系统中的决策模块,并单独进行分类。同样,随着对每个数据集的比较方法的结果呈现出不同的评估标准,报告了每个数据集的评估结果并使用不同的指标进行比较(在表9-12中)。
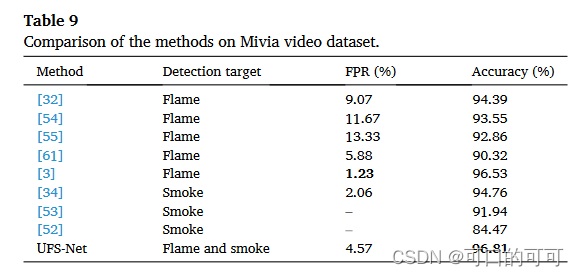
Mivia视频数据集上的结果
表9将UFS-NET的结果与Mivia视频数据集上的其他方法进行了比较。所有结果均为百分比。 [3,32,54,55,61]中的方法只能检测到火焰但是对包含烟雾的图像不发出火灾警报。相反,[34,52,53]中的方法只能检测到烟雾,把含有火焰的图像视为正常。 [3,32,34]中方法的结果已直接从相应的文章中报道,其他方法的结果已从[3,32,34]引用。 “ - ”符号表示未用于该参考的测量值。在表9中,最佳结果是大胆的。根据表9,UFS-NET在所有方法中的精度最高。但是,它在FPR方面排名第三。这可能是由于并发火焰和烟雾检测。还应注意,UFS-NET的决策模块是不活动的。如果该模块被激活,则该指标将大大降低。
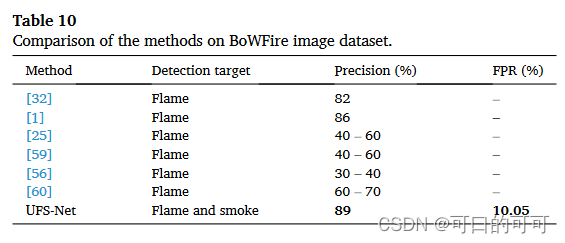
Bowfire图像数据集上的结果
表10将UFS-NET的结果与Bowfire图像数据集上的其他方法进行了比较。方法[1,32]的结果直接从相关报告,并从这些参考文献[1,32]中引用了其他方法的结果。在精度测量方面,UFS-NET显然具有最高的性能。但是,它在FPR方面的表现略有弱,并将图18中所示的图像错误分类为火。但是,由于该数据集无法使用其他方法的FPR,因此不能将该指标与其他方法进行比较。由于该数据集中有具有挑战性的图像,因此其他方法的FPR非常弱。此外,如图18所示,这些图像确实具有与火相似的挑战。
[1] K. Muhammad, J. Ahmad, I. Mehmood, S. Rho, S.W. Baik, Convolutional neural networks based fire detection in surveillance videos, IEEE Access 6 (2018) 18174–18183.
[23] A. Filonenko, D.C. Hern ́ andez, K.-H. Jo, Smoke detection for surveillance cameras based on color, motion, and shape, in: Proceedings of the 2016 IEEE 14th International Conference on Industrial Informatics (INDIN), 2016, pp. 182–185.
FIRENET图像数据集上的结果
本节评估了Ref中的Firenet图像数据集上的UFS-NET的性能。 [3]并比较结果。如表11所示,UFS-NET的准确性,精度和FNR比参考更高。 [3]。但是,它在FPR方面具有相对较低的表现(约1.5%)。这可能是由于该数据集的图像引起的,该数据集与烟熏环境非常相似,因此被检测为烟雾。但是,[3]中的方法仅能够发出火焰检测,并且比提出的方法容易得多。

[3] A. Jadon, M. Omama, A. Varshney, M.S. Ansari, R. Sharma, Firenet: A specialized lightweight fire & smoke detection model for real-time iot applications, arXiv preprint arXiv:1905.11922, 2019.
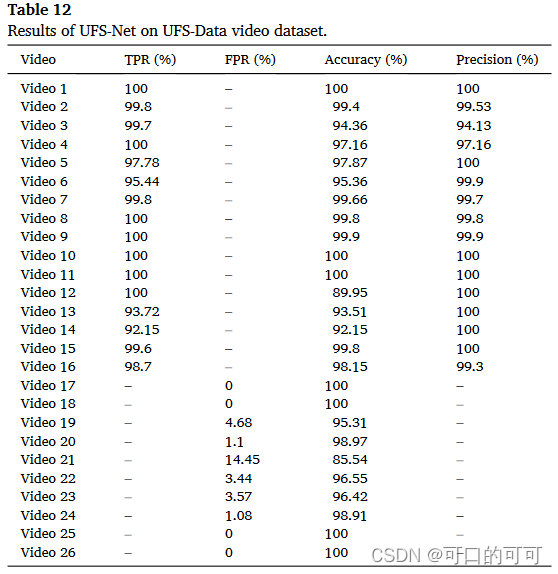
在UFS-DATA上的评估结果
本节评估和测试UFS-NET在我们自己的UFS-DATA上的性能。在本实验中,使用UFS-DATA中的26个视频用于评估所提出的方法。该实验的结果如表12所示。在此表中,如果某个评定方法不能用于某个视频,则标记为“ - 。”。例如,在视频1中,因为框架处于火状态,并且没有正常的框架可以分类为误报,因此FPR值用“ - ”标记。或者,在视频17-26中,由于缺少有火的图像,TPR值以“ - ”标记。
如表12所示,在大多数视频中,UFS-NET的准确性大于90%,在几种情况下,除了89.95和85.54的精度外,在几种情况下,近100%。在视频12上,由于相机与火的距离和图像的低质量,提出的方法无法在某些帧中检测到火,并且精确度为89.95。自然,如果决策模块被灭活,则情况就是这种情况,而如果激活该模块,则可以很好地涵盖这些错误。例如,如果框架中的图像质量低(例如,由于摄像机的颤抖),该系统在那一刻无法正确识别;但是,通过考虑投票计划,它还可以将该框架分类为火。在视频21中,由于该视频中的水波,在质地,颜色和形状方面与白烟非常相似,因此提出的系统的精度最低。在此视频中,有14.45%的框架被错误地归类为烟雾,从而降低了此特殊视频中的系统准确性。
实验2:在复杂的现实情况下评估UFS-NET的鲁棒性
在基于计算机视觉的系统的实际应用中,从监视摄像机获得的图像可能包含各种类型的噪声和不同的质量。为了在不同条件下评估UFS-NET的鲁棒性,从测试数据集随机选择了150张图像,并根据以下情况进行编辑:
1.方案1:清除整个火灾区域:测试图像的火焰或烟区域在该区域覆盖着相似的颜色。
2.方案2:添加噪声:将各种类型的噪声添加到包含火焰或烟雾的图像中。
3.方案3:多标签图像中的一个类别的删除:在包含多个类(火焰和烟雾)的图像中,其中一个类别覆盖与该类相同的颜色。
原始图像的一些示例及其相应的编辑图像如图19所示。在每对图像(原始和编辑)上评估了UFS-NET的性能。观察到该系统在所有150对测试图像中都能正常工作。对于原始和编辑的图像,分类器性能都是相同的,在本实验中,准确性为100%。

实验3:检查CNN参数的数量
如前所述,在现实世界中,火灾检测系统通常必须是准确且快速的,这些应用程序通常具有有限的处理资源。为此,它们必须具有尽可能低的计算方法。在本节中,研究了该领域可用的其他基于深度学习的模型并比较了建议的CNN中的参数数量。表13总结了参数的数量和检测不同的基于深度学习的模型的类型。[1,31,34]中有关方法的信息是通过我们实施其CNN模型获得的。该信息尚未在相关出版物中报告。如表13所示,尽管提出的CNN模型可以检测到这两个烟熏火焰,但它的参数比其他模型小得多。这是一个很大的优势,该系统每秒处理和分类68帧,可以轻松地用于现实世界应用程序中。

实验4:决策模块的影响
实验5:评估灰度图像上UFS-NET的性能
6.总结
火灾是不同环境中最危险的情况之一。它具有很高的破坏性和传播能力,并造成重大损害,可能需要数年甚至数十年的时间来补偿。因此,必须开发准确而快速的火灾检测方法来控制火。过去,使用物理和点传感器来检测火灾。这些传感器在大型和开放的环境中具有局限性和弱点。因此,它们被基于计算机视觉技术的新方法取代。因此,这种计算机视觉的应用已成为现实世界中的一个有吸引力和实用的领域。然而,近年来开发的绝大多数基于计算机的火灾检测方法只能检测到一个火因素(火焰或烟雾),并且无法同时检测火焰和烟雾。由于不同且不可预测的火灾条件和场景,因此不可能在现实世界应用中使用这些方法。
在本文中,提出了基于深度学习的统一火焰和烟雾检测系统。在提出的方法中,首先在某些操作下预处理输入图像。然后,使用有效的CNN体系结构,将图像状态分为八个不同的类。目标类别包括“火焰”,“白烟”,“黑烟”,“火焰和白烟”,“火焰和黑烟”,“白烟和黑烟”,“火焰,白烟和黑烟”,和“正常状态”。
该系统的主要要求之一是降低错误警报率。为此,设计了一个具有高检测精度的方便网络,并使用基于投票的专家系统来更准确地做出系统的最终决定。
此外,为了提高模型的性能,收集了来自不同来源的丰富培训数据集,并标记了所有八个类别。在四个基准标记数据集上进行的各种实验的结果,包括各种场景,表明所提出的方法可以实时以适当的准确性检测各种火灾条件。此外,与其他成功方法的比较证明了所提出的系统的优越性。根据这项研究中收获的经验,建议在该领域进行改进的一些未来工作如下:
•在提出的方法中,仅在输入图像中检测到火焰或烟雾的存在。可以在图像中定位火焰或烟雾。
•可以在系统中添加不同大小的火焰或烟雾,例如“小火焰”,“大火”,“小烟”和“大烟”。系统中的类数越高,我们可以从火场景中获取更多信息,从而有效控制火灾。
•可以考虑和评估其他深层神经网络的架构的开发,以提高系统性能。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









