







软件设计师备考笔记
| 上午题 | 下午题 |
|---|---|
| 计算机网络概述 | 数据流图设计(下午试题一) |
| 程序设计语言基础知识 | 数据库设计(下午试题二) |
| 标准化和知识产权 | UML分析与设计(下午试题三) |
| 数据库 | 面向对象程序设计与实现(下午试题六) |
| 操作系统 | 算法设计与C语言实现(下午试题四) |
| 结构化开发与方法 | |
| 软件工程 | |
| 网络与信息安全 | |
| 数据结构 | |
| 算法分析设计 |
1 算法基础知识
算法是对特定问题求解步骤的一种描述,它是指令的有限序列,其中每一条指令表示一个或多个操作
5个重要特性:有穷性、确定性、可行性、输入、输出
2 算法分析基础
2.1 算法的复杂度
2.1.1 时间复杂度
时间复杂度是指程序运行从开始到结束所需要的时间。通常分析时间复杂度的方法是从算法中选取一种对于所研究的问题来说是基本运算的操作以该操作重复执行的次数作为算法的时间度量。一般来说,算法中原操作重复执行的次数是规模n的某个函数T(n)。由于许多情况下要精确计算T(n)是困难的,因此引入了渐进时间复杂度在数量上估计一个算法的执行时间。其定义如下:
- 如果存在两个常数c和m,对于所有的n,当 n ≥ m 时有 f(n) ≤ cg(n) ,则有 f(n) = O(g(n)) 。也就是说,随着n的增大,f(n)渐进地不大于g(n)。例如,一个程序的实际执行时间为T(n) = 3n3 + 2n2 + n,则T(n)=O(n3)
- 常见的对算法执行所需时间的度量:O(1) < O(log2n) < O(n) < O(nlog2n) < O(n2) < O(n3) < O(2n)
2.1.2 空间复杂度
空间复杂度是指对一个算法在运行过程中临时占用存储空间大小的度量。一个算法的空间复杂度只考虑在运行过程中为局部变量分配的存储空间的大小
3 查找
3.1 顺序查找
将待查找的关键字为key的元素从头到尾与表中元素进行比较,如果中间存在关键字为key的元素,则返回成功;否则,则查找失败
顺序查找的时间复杂度为:时间复杂度为O(n)
3.2 折半(二分)查找
- 设查找表的元素存储在一维数组r[1…n]中,在表中元素已经按照关键字递增方式排序的情况下,进行折半查找的方法是:
- 1、首先将待查元素的关键字(key)值与表r中间位置上(下标为mid)记录的关键字进行比较,若相等,则查找成功
- 2、若key > r[mid].key,则说明待查记录只可能在后半个子表r[mid+1…n]中,下一步应在后半个子表中查找
- 3、若key < r[mid].key,说明待查记录只可能在前半个子表r[1…mid-1]中,下一步应在r的前半个子表中查找
- 4、重复上述步骤,逐步缩小范围,直到查找成功或子表为空失败时为止
- 折半查找的时间复杂度为:O(log2n)
3.3 哈希表
- 散列(哈希)表:根据设定的哈希函数H(key)和处理冲突的方法,将一组关键字映射到一个有限的连续的地址集上,并以关键字在地址集中的“像”作为记录在表中的存储位置

- 在上图中,很明显,哈希函数产生了冲突,使用的是线性探测法解决冲突,还有其他方法如下:
- 线性探测法:按物理地址顺序取下一个空闲的存储空间
- 伪随机数法:将冲突的数据随机存入任意空闲的地址中
- 再散列法:原有的散列函数冲突后,继续用此数据计算另外一个哈希函数,用以解决冲突
4 排序
- 排序的分类
- 稳定与不稳定排序:依据是两个相同的值在一个待排序序列中的顺序和排序后的顺序应该是相对不变的,即开始时21在21前,那排序结束后,若该21还在21前,则为稳定排序;不改变相同值的相对顺序
- 内排序和外排序:依据排序是在内存中进行的还是在外部进行的
- 排序的算法:
- 插入类排序:直接插入排序、希尔排序
- 交换类排序:冒泡排序、快速排序
- 选择类排序:简单选择排序、堆排序
- 归并排序
- 基数排序
4.1 直接插入排序
直接插入排序是一种简单的排序方法,具体做法是:在插入第i个记录时,R1、R2、…、Ri-1。已经排好序,这时将Ri的关键字ki依次与关键字ki-1、ki-2等进行比较,从而找到应该插入的位置并将Ri插入,插入位置及其后的记录依次向后移动
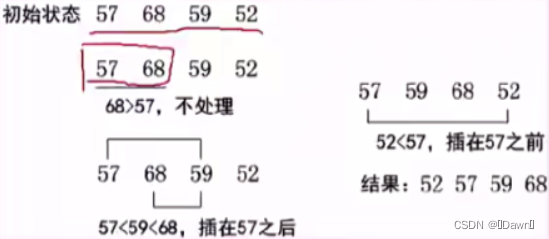
4.2 希尔排序
希尔排序的基本思想是:先将整个待排记录序列分割成若干子序列,然后分别进行直接插入排序,待整个序列中的记录基本有序时,再对全体记录进行一次直接插入排序。具体做法是:先取一个小于n的整数di作为第一个增量,把文件的全部记录分成d1个组,即将所有距离为d1倍数序号的记录放在同一个组中,在各组内进行直接插入排序;然后取第二个增量d2(d2 < d1),重复上述分组和排序工作,依此类推,直到所取的增量di = 1(di < di-1 < … < d2 < d1),即所有记录放在同一组进行直接插入排序为止

4.3 简单选择排序
n个记录进行简单选择排序的基本方法是:通过 n-i ( 1 ≤ i ≤ n )在次关键字之间的比较,从 n-i+1 个记录中选出关键字最小的记录,并和第i个记录进行交换,当i等于n时所有记录有序排列

4.4 堆排序

- 堆排序的方法可分为两步:
- 1、依据给出的待排序关键字建立初始堆
- 2、输入堆顶元素,并调整堆。重复上述步骤

4.5 冒泡排序
n个记录进行冒泡排序的方法是:首先将第一个记录的关键字和第二个记录的关键字进行比较,若为逆序,则交换这两个记录的值,然后比较第二个记录和第三个记录的关键字,依此类推,直到第n-1个记录和第n个记录的关键字比较过为止。上述过程称为第一趟冒泡排序,其结果是关键字最大的记录被交换到第n个记录的位置上。然后进行第二趟冒泡排序,对前n-1个记录进行同样的操作,其结果是关键字次大的记录被交换到第n-1个记录的位置上。最多进行n-1趟,所有记录有序排列。若在某趟冒泡排序过程没有进行相邻位置的元素交换处理,则可结束排序过程
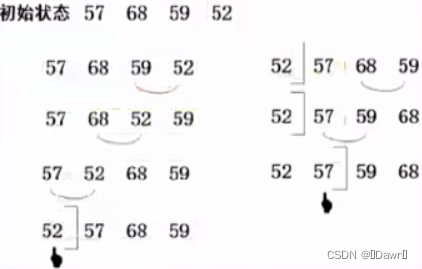
4.6 快速排序
快速排序的基本思想是:通过一趟排序将待排的记录划分为独立的两个部分,其中一部分记录的关键字均不大于另一部分记录的关键字,然后再分别对这两部分记录继续进行快速排序,以达到整个序列有序
4.7 归并排序
所谓“归并”,是将两个或两个以上的有序文件合并成为一个新的有序文件。归并排序是把一个有n个记录的无序文件看成是由n个长度为1的有序子文件组成的文件,然后进行两两归并,得到 n 2 \frac{n}{2} 2n个长度为 2 或 1 的有序文件,再两两归并,如此重复,直到最后形成包含n个记录的有序文件为止。这种反复将两个有序文件归并成一个个有序文件的排序方法称为两路归并排序
4.8 基数排序
基数排序是一种借助多关键字排序思想对单逻辑关键字进行排序的方法。基数排序不是基于关键字比较的排序方法,它适合于元素很多而关键字较少的序列。基数的选择和关键字的分解是根据关键字的类型来决定的,例如关键字是十进制数,则按个位、十位来分解
4.9 排序算法总结
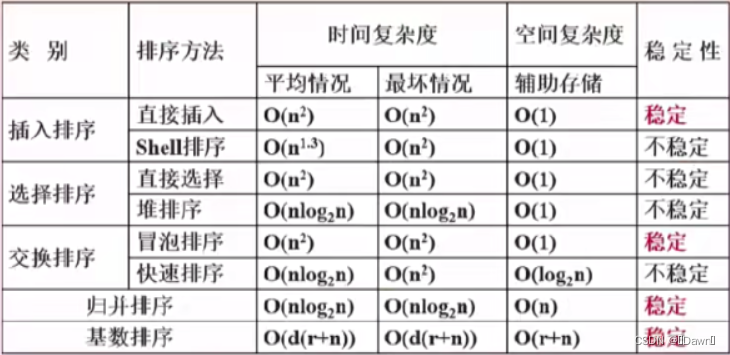
- 空间复杂度中,大部分排序都是比较交换,无需多余空间,快速排序则是需要存储每次的基准值,归并排序需要一个新表,基数排序需要新表,还需要存储关键字的空间
- 时间复杂度中,与堆、树、二分有关的算法都是 nlogn ,直接的算法都是 nn
5 常用算法原理
5.1 分治法
- 递归:指子程序(函数)直接调用自己活通过一系列调用语句间接调用自己,是一种描述问题和解决问题的常用方法
- 递归两个基本要素:
- 边界条件(确定递归何时终止,即递归出口)
- 递归模式(大问题如何分解成小问题,即递归体)
分治法:对于一个规模为n的问题,若该问题可以容易地解决则直接解决,否则将其分解为k个规模较小的子问题,这些子问题互相独立且与原问题形式相同,递归地解决这些子问题,然后将各子问题的解合并得到原问题的解- 步骤: 分解(将原问题分解成一系列子问题)――求解(递归地求解各子问题,若子问题足够小,则直接求解)――合并(将子问题的解合并成原问题的解)
凡是涉及到分组解决的都是分治法(二分查找、归并排序等)
5.2 回溯法
回溯法:有 “通用的解题法” 之称,可以系统地搜索一个问题的所有解或任一解。在包含问题的所有解的解空间树中,按照深度优先的策略,从根节点触发搜索解空间树。搜索至任一结点时,总是先判断该结点是否肯定不包含问题的解,如果不包含,则跳过对以该结点为根的子树的搜索,逐层向其祖先结点回溯;否则,进入该子树;继续按深度优先的策略进行搜索- 可以理解为先进行深度优先搜索,一直向下探测,当此路不通时,返回上一层探索另外的分支,重复此步骤,这就是回溯,意为先一直探测,当不成功时再返回上一层
一般用于解决迷宫类的问题
5.3 动态规划法
动态规划法:在求解问题中,对于每一步决策,列出各种可能的局部解,再依据某种判定条件,舍弃哪些肯定不能得到最优解的局部解,在每一步都经过筛选,以每一步都是最优解来保证全局是最优解- 本质也是将复杂的问题划分成一个个子问题,与分治法不同的是每个子问题间不是相互独立的,并且不全都相同
常用于求解具有某种最优性质的问题- 此算法会将大量精力放在前期构造表格上面,其会对每一步,列出各种可能的答案,这些答案会存储起来,最终要得出某个结果时,是通过查询这张表来得到的动态规划法不但每一步最优,全局也最优
5.4 贪心法
贪心法:总是做出在当前来说是最好的选择,而并不从整体上加以考虑,它所做的每步选择只是当前步骤的局部最优选择,但从整体来说不一定是最优的选择。由于它不比为了寻找最优解而穷尽所有可能解,因此其耗费时间少,一般可以快速得到满意的解,但得不到最优解- 局部贪心,只针对当前的步骤取最优,而非整体考虑
判断此类算法,就看算法是否是每一步都取最优,并且整体题意没有透露出最终结果是最优的
5.5 分支限界法
分支限界法:与回溯法类似,同样是在问题的解空间树上搜索问题解的算法- 搜索原理:在分支限界法中,每一个活结点只有一次机会成为扩展结点。活结点一旦成为扩展结点,就一次性产生其所有儿子结点。在这些儿子结点中,导致不可行解或导致非最优解的儿子结点被舍弃,其余儿子结点被加入活结点表中。此后,从活结点表中取下一结点成为当前扩展结点,并重复上述结点扩展过程。这个过程一直持续到找到所需的解或活结点表为空时为止
- 与回溯法的区别:
- 1、
求解目标是找出满足约束条件的一个解,或是在满足约束条件的解中找出使某一目标函数值达到极大或极小的解,即在某种意义下的最优解 - 2、以
广度优先或以最小耗费(最大收益)优先的方式搜索解空间树
- 1、
- 从活节点表中选择下一个扩展节点的类型:
- 队列式(FIFO)分支限界法:按照队列先进先出(FIFO)原则选取下一个节点为扩展节点
- 优先队列式分支限界法:按照优先队列中规定的优先级选取优先级最高的节点成为当前扩展节点
5.6 概率算法
概率算法:在算法执行某些步骤时,可以随机地选择下一步该如何进行,同时允许结果以较小的概率出现错误,并以此为代价,获得算法运行时间的大幅度减少(降低算法复杂度)- 基本特征是对所求解问题的同一实例用同一概率算法求解两次,可能得到完全不同的效果
- 如果一个问题没有有效的确定性算法可以在一个合理的时间内给出解,但是该问题能接受小概率错误,那么采用概率算法就可以快速找到这个问题的解
- 四类概率算法:
- 数值概率算法(数值问题的求解)
- 蒙特卡洛算法(求问题的精确解)
- 拉斯维加斯算法(不会得到不正确的解)
- 舍伍德算法(总能求得问题的一个正确解)
- 概率算法的特征:
- 概率算法的输入包括两部分,一部分是原问题的输入,另一部分是一个供算法进行机选择的随机数序列
- 概率算法在运行过程中,包括一处或多处随机选择,根据随机值来决定算法的运路径
- 概率算法的结果不能保证一定是正确的,但能限制其出错概率
- 概率算法在不同的运行过程中,对于相同的输入实例可以有不同的结果,因此,对于相同的输入实例,概率算法的执行时间可能不同
5.7 近似算法
近似算法:解决难解问题的一种有效策略,其基本思想是放弃求最优解,而用近似最优解代替最优解,以换取算法设计上的简化和时间复杂度的降低- 虽然它可能找不到一个最优解,但它总会给待求解的问题提供一个解
- 为了具有实用性,近似算法必须能够给出算法所产生的解与最优解之间的差别或者比例的一个界限,它保证任意一个实例的近似最优解与最优解之间的相差成都。显然,这个差别越小,近似算法越具有实用性
- 衡量近似算法性能两个标准:
- 算法的时间复杂度。近似算法的时间复杂度必须是多项式阶的,这是近似算法的基本目标
- 解的近似程度。近似最优解的近似程度也是设计近似算法的重要目标。近似程度与近似算法本身、问题规模,乃至不同的输入实例有关
5.8 数据挖掘算法
- 概述:
分析爆炸式增长的各类数据的技术,以发现隐含在这些数据中的有价值的信息和知识。数据挖掘利用及其学习方法对多种数据进行分析和挖掘。其核心是算法,主要功能包括分类、回归、关联规则和聚类等 - 分类:是一种有监督的学习过程,根据历史数据预测未来数据的模型
- 分类的数据对象属性:一般属性、分类属性或目标属性
- 分类设计的数据:训练数据集、测试数据集、未知数据
- 数据分类的两个步骤:
- 学习模型(基于训练数据集采用分类算法建立学习模型)
- 应用模型(应用测试数据集的数据到学习模型中,根据输出来评估模型的好坏以及将未知数据输入到学习模型中,预测数据的类型)
- 分类算法:决策树归纳(自顶向下的递归树算法)、朴素贝叶斯算法、后向传播BP、支持向量机SVM
- 频繁模式和关联规则挖掘:挖掘海量数据中的频繁模式和关联规则可以有效地指导企业发现交叉销售机会、进行决策分析和商务管理等。(沃尔玛-啤酒尿布故事)首先要求出数据集中的频繁模式,然后由频繁模式产生关联规则
- 关联规则挖掘算法:类Apriori算法、基于频繁模式增长的方法如FP-growthh,使用垂直数据格式的算法,如ECLAT
- 聚类:是一种无监督学习过程。根据数据的特征,将相似的数据对象归为一类,不相似的数据对象归到不同的类中。物以类聚,人以群分
- 典型算法:基于划分的方法、基于层次的方法、基于密度的方法、基于网格的方法基于统计模型的方法
- 数据挖掘的应用:信用分析、定向促销顾客的分类与聚类等。
5.9 智能优化算法
- 概述:优化技术是一种以数学为基础,用于求解各种工程问题优化解的应用技术
- 人工神经网络ANN:一个以有向图为拓扑结构的动态系统,通过对连续或断续的输入作状态响应而进行信息处理。从信息处理角度对人脑神经元网络进行抽象,建立某种简单模型,按不同的连接方式组成不同的网络
- 遗传算法:源于模拟达尔文的 “优胜劣汰、适者生存” 的进化论和孟德尔.摩根的遗传变异理论,在迭代过程中保持已有的结构,同时寻找更好的结构。其本意是在人工适应系统中设计一种基于自然的演化机制
- 模拟退火算法SA:求解全局优化算法。基本思想来源于物理退火过程,包括三个阶段:加温阶段、等温阶段、冷却阶段
- 禁忌搜索算法TS:模拟人类智力过程的一种全局搜索算法,是对局部邻域搜索的一种扩展
- 蚁群算法:是一种用来寻找优化路径的概率型算法
- 粒子群优化算法PSO:又称为鸟群觅食算法,在鸟群觅食飞行时,在飞行过程中经常会突然改变方向、散开、聚集,其行为不可预测,但其整体总保持一致性,个体与个体间也保持着最适官的距离。通过对类似生物群体行为的研究,发现生物群体中存在着一种信息共享机制,为群体的进化提供了一种优势,这就是基本粒子群算法形成的基础



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









