






目录
1、研究背景
量化金融在国外已经有数十年的历程,而在国内兴起还不到十年。这是一个极具挑战的领域。量化金融结合了数理统计、金融理论、社会学、心理学等多学科的精华,同时特别注重实践。由于市场博弈参与个体的差异性和群体效应的复杂性,量化金融极具挑战与重大的机遇的特点。 本赛事通过大数据与机器学习的方法和工具,理解市场行为的原理,通过数据分析和模型创建量化策略,采用历史数据,验证量化策略的有效性,并且通过实时数据进行评测。
2、数据描述
(1)、给定训练集(含验证集), 包括10只(不公开)股票、79个交易日的L1snapshot数据(前64个交易日为训练数据,用于训练;后15个交易日为测试数据,不能用于训练), 数据已进行规范化和隐藏处理,包括5档量/价,中间价,交易量等数据。
| 字段 | 含义 | 说明 |
|---|---|---|
| date | 日期 | sequantial标号:既保留跨标的的可比性,也隐去实际时间 |
| time | 时间戳 | 保留实际时间戳,3s一档行情 |
| sym | 股票编号 | 分别为0~9号股票 |
| close | 最新价/收盘价 | 以涨跌幅表示 |
| amount_delta | 成交量变化 | 从上个tick到当前tick发生的成交金额 |
| n_midprice | 中间价 | 标准化后的中间价,以涨跌幅表示 |
| n_bid1 | 买一价 | 标准化后的买一价,以下类似 |
| n_bsize1 | 买一量 | 标准化后的买一量,以下类似 |
| n_bid2 | 买二价 | / |
| n_bsize2 | 买二量 | / |
| n_bid3 | 买三价 | / |
| n_bsize3 | 买三量 | / |
| n_bid4 | 买四价 | / |
| n_bsize4 | 买四量 | / |
| n_bid5 | 买五价 | / |
| n_bsize5 | 买五量 | / |
| n_ask1 | 卖一价 | / |
| n_asize1 | 卖一量 | / |
| n_ask2 | 卖二价 | / |
| n_asize2 | 卖二量 | / |
| n_ask3 | 卖三价 | / |
| n_asize3 | 卖三量 | / |
| n_ask4 | 卖四价 | / |
| n_asize4 | 卖四量 | / |
| n_ask5 | 卖五价 | / |
| n_asize5 | 卖五量 | / |
| label5 | 5tick价格移动方向 | 5tick之后中间价相对于当前tick的移动方向,0为下跌,1为不变,2为上涨 |
| label10 | 10tick价格移动方向 | / |
| label20 | 20tick价格移动方向 | / |
| label40 | 40tick价格移动方向 | / |
| label60 | 60tick价格移动方向 | / |
(2)、行情频率:3秒一个数据点(也称为1个tick的snapshot);
(3)、每个数据点包括当前最新成交价/五档量价/过去3秒内的成交金额等数据;
(4)、训练集中每个数据点包含5个预测标签的标注;允许利用过去不超过100tick(包含当前tick)的数据,预测未来N个tick后的中间价移动方向。
(5)、预测时间跨度:5、10、20、40、60个tick,5个预测任务;即在t时刻,分别预测t+5tick,t+10tick,t+20tick,t+40tick,t+60tick以后:最新中间价相较t时刻的中间价:下跌/不变/上涨。
(6)、认定方法:
①、若N个tick之后的价格较当前tick价格的涨跌幅上升超过a,则认为上涨,标注为2;
②、若下降幅度超过a,则认为下跌,标注为0;
③、否则认为价格不变,标注为1。
其中,
当N=5,10时,a = 0.0005;当N=20,40,60时,a = 0.001。
3、手册Baseline思路
(1)、数据可视化:对任意一支股票可视化,观察买价、卖价的相关走势,提及点差金融理论概念,以卖价与买价的差值量化股票的流通性;同时也提及加权平均价格(WAP),以此反映股票波动情况。
(2)、量化时间特征:手册中的Baseline将时间量化为时、分、秒三列特征,以此探究不同时间阶段的信息规律。
(3)、模型验证:采用Catboost模型进行训练及交叉验证。
4、My_Baseline思路
(1)、数据预处理:
①、数据中的“uuid”列用来统计各csv文件中的样本个数,对于预测股票涨跌目标无有用信息,予以删除;
②、通过观察数据集,发现信息统计时间段是相同的,且tick间隙固定位3s。为了避免引入过多特征,对于时间特征采用序号编码,将时、分、秒三列信息压缩为一列。
(2)、数据统计:利用Pandas对各特征进行数据统计。
①、我们可以发现,超过一半的特征数据均符合正态分布,由于很多算法基于原数据是正态分布的假设,因此该分布对机器学习算法的良好发挥打下了基础。
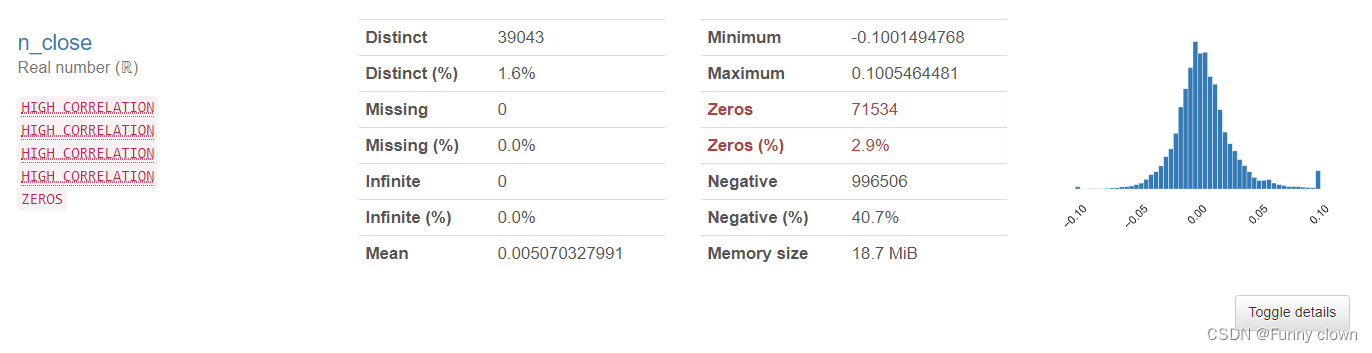

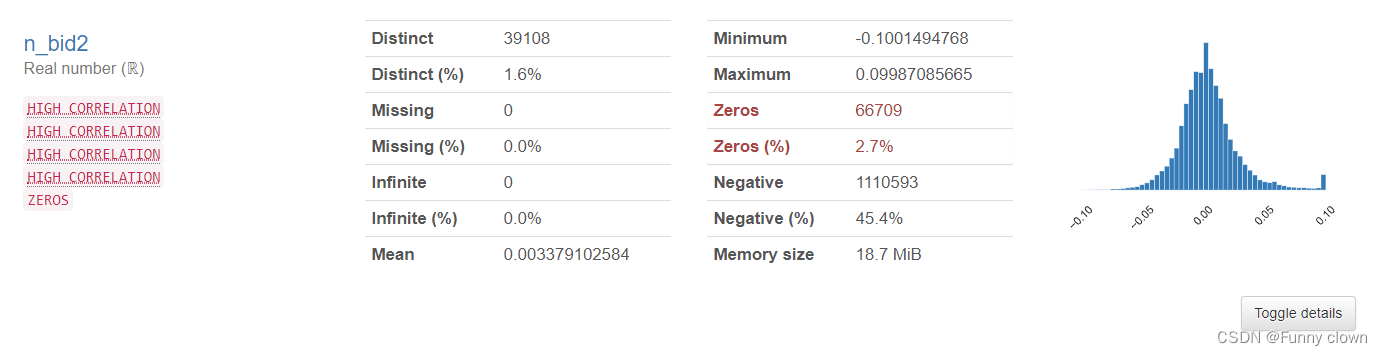


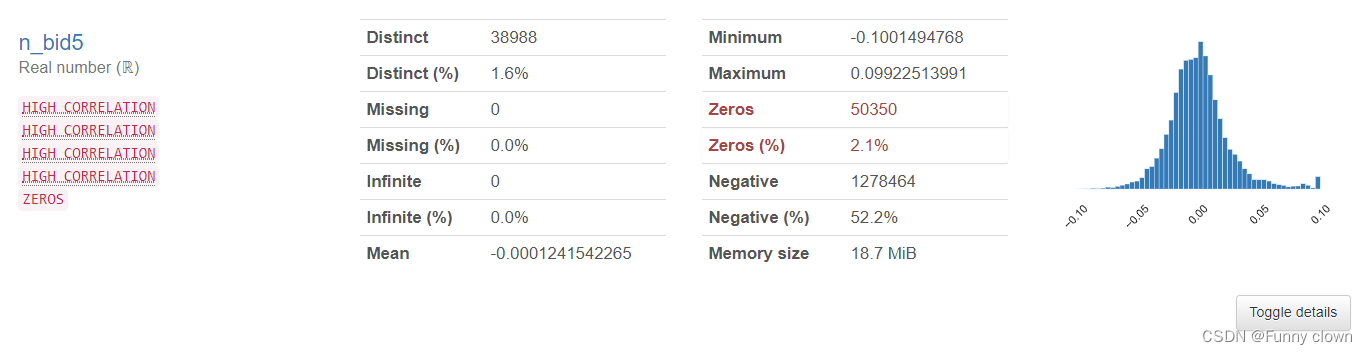
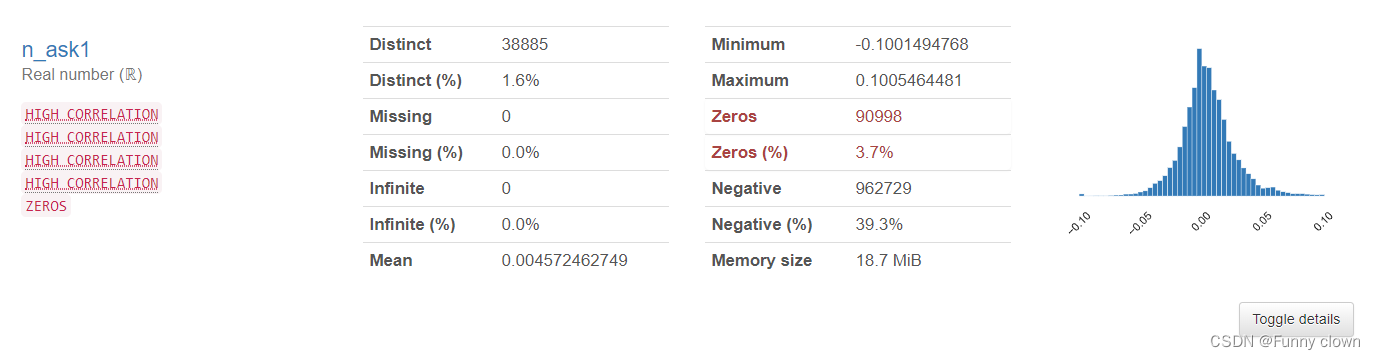
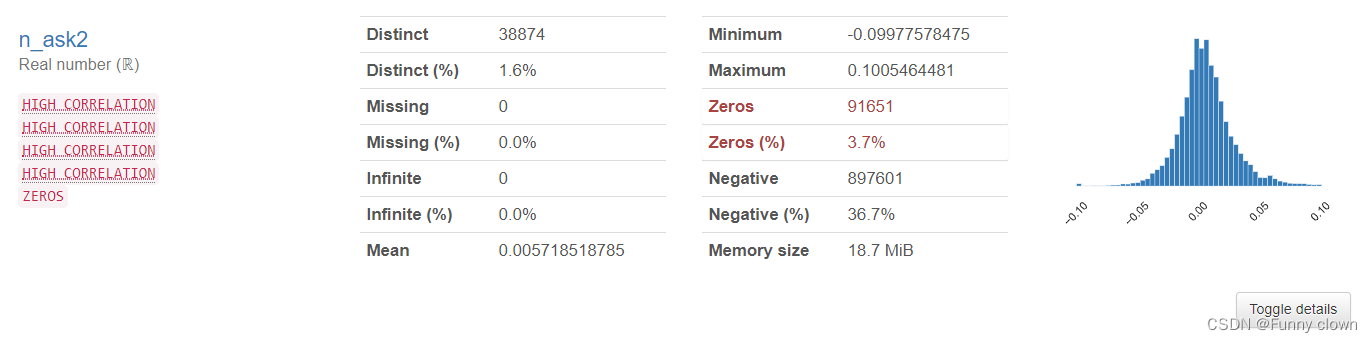
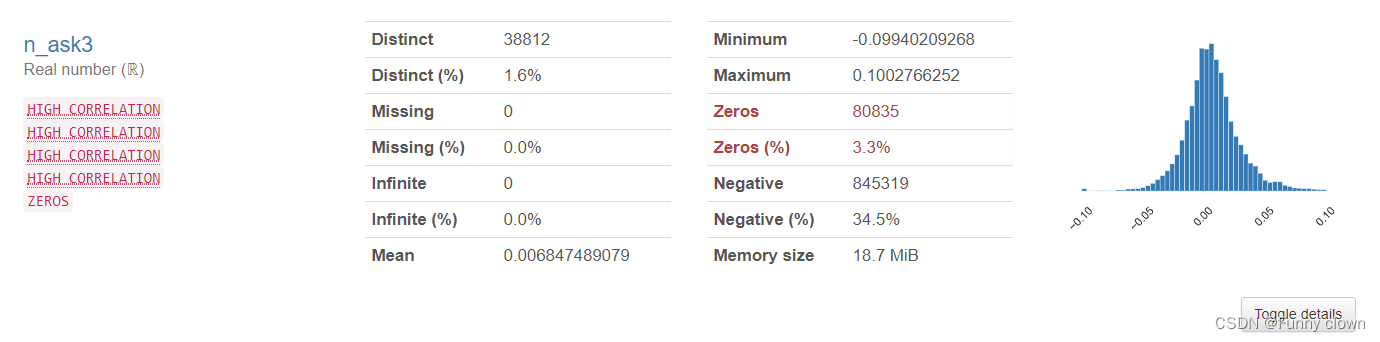
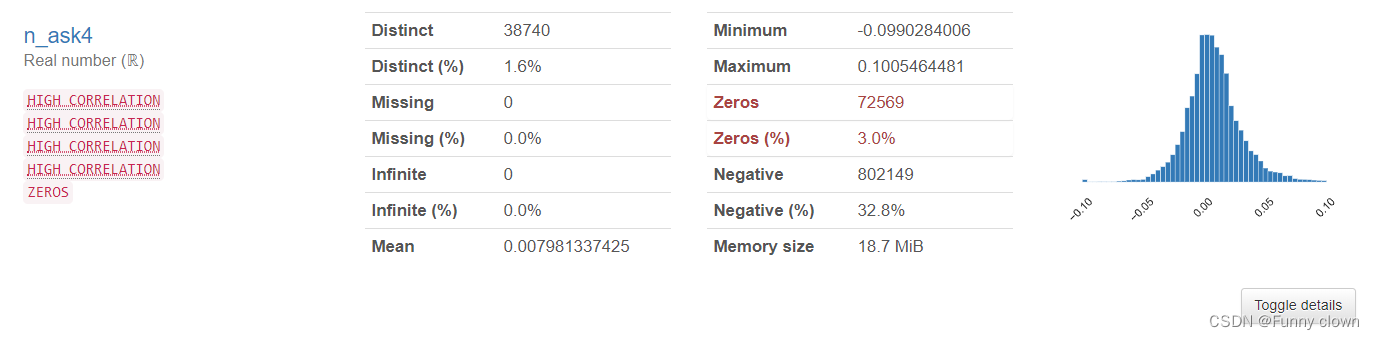
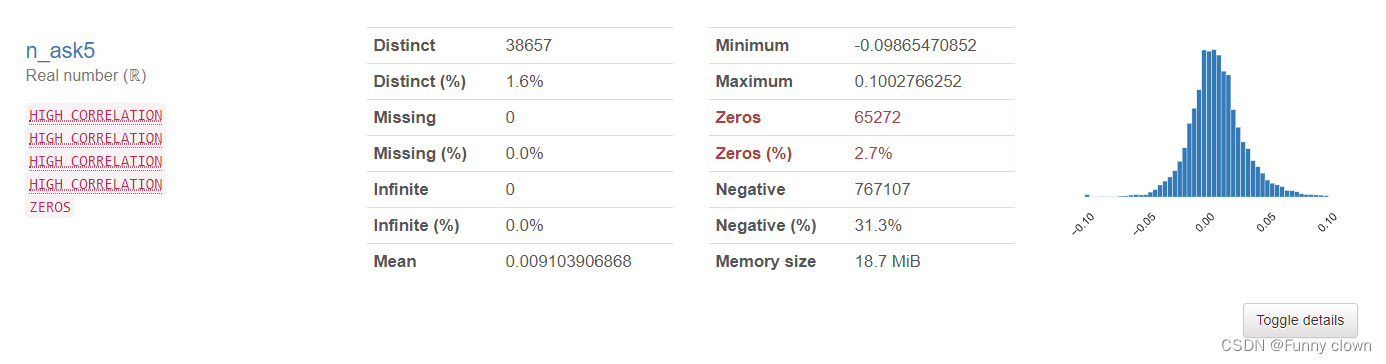
图1 部分正态特征的统计分析图表
②、对于日期特征来说,我们可以发现,不同日期的样本数有些许差别,但没有表现出周期性规律。同时,由于训练集与测试集的日期是时序的,且目标属性以tick为单位,所以可以考虑忽略该特征。
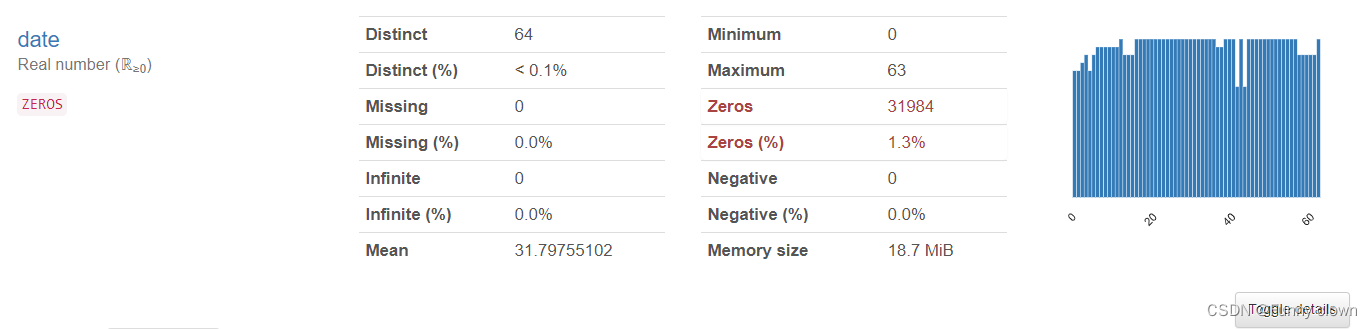
图2 “date”特征统计分析图表
每个tick成交量的变化特征存在17.6%的0值,最大值甚至达到了10E9量级,标准差也达到了10E6量级,说明该特征包含较大的信息量。
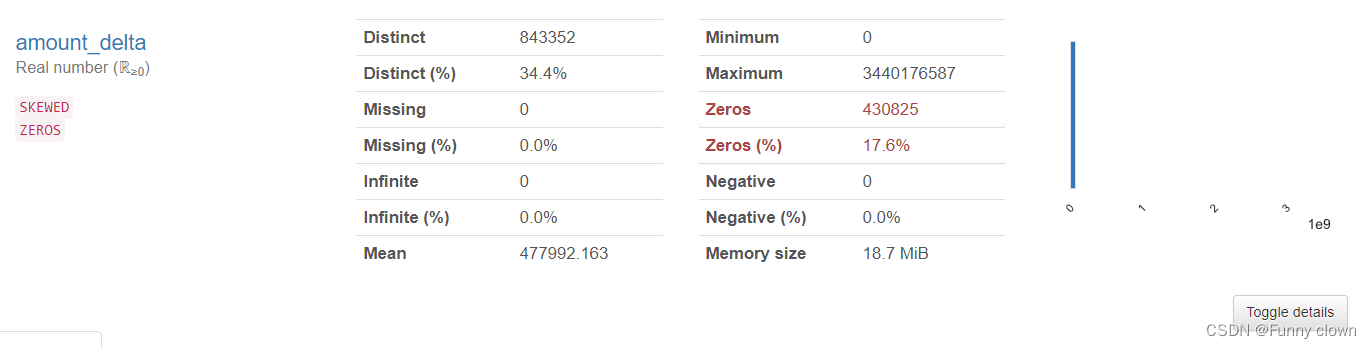
图3 “amount_delta”特征统计分析图表
③、对于"n_bsize1-5"及“n_asize1-5”等出现严重左偏态的特征,笔者对其进行了对数处理,但仍然无法改善其严重的左偏态。可能由于数据集进行了模糊处理,使得这些特征数据的数量级非常小,因此表现出绝对方差值小,但数据偏差度仍然大的现象。按照常理与经验来看,"n_bsize1-5"及“n_asize1-5”的数量级单位应与“amount_delta”特征类似。
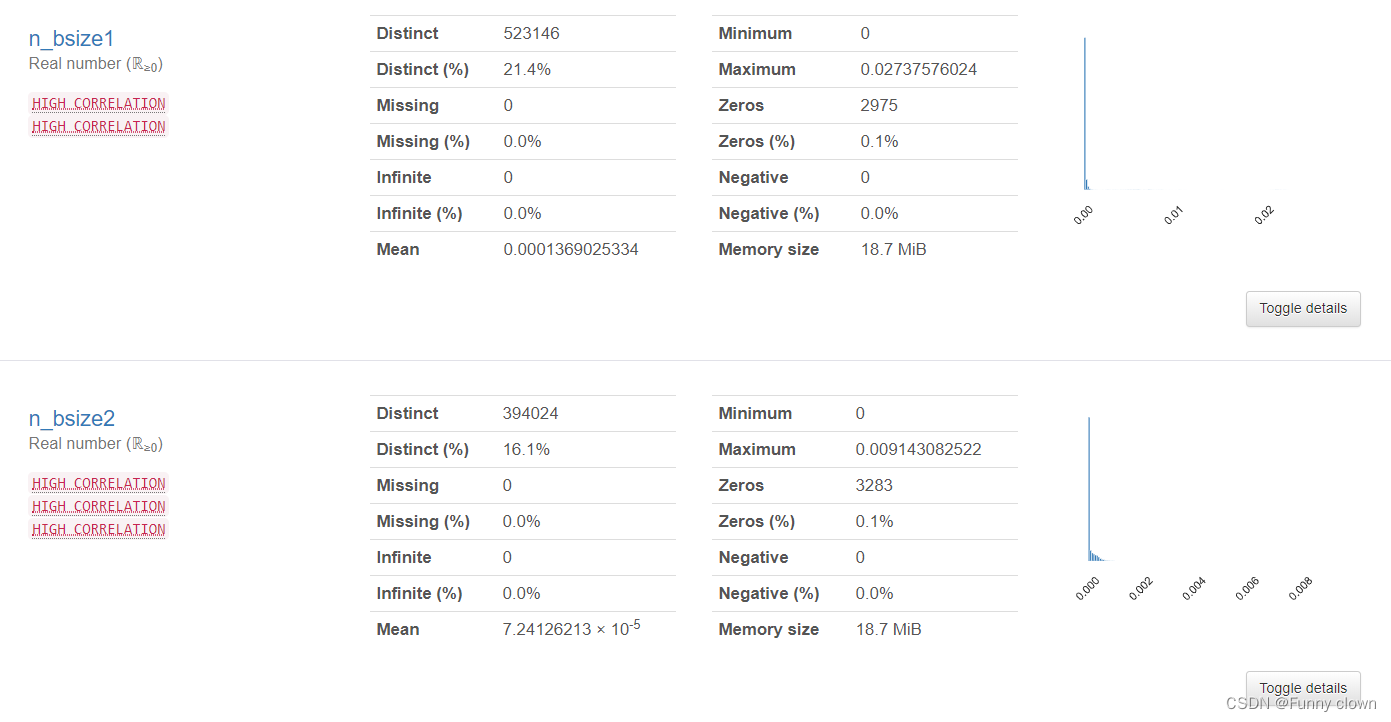
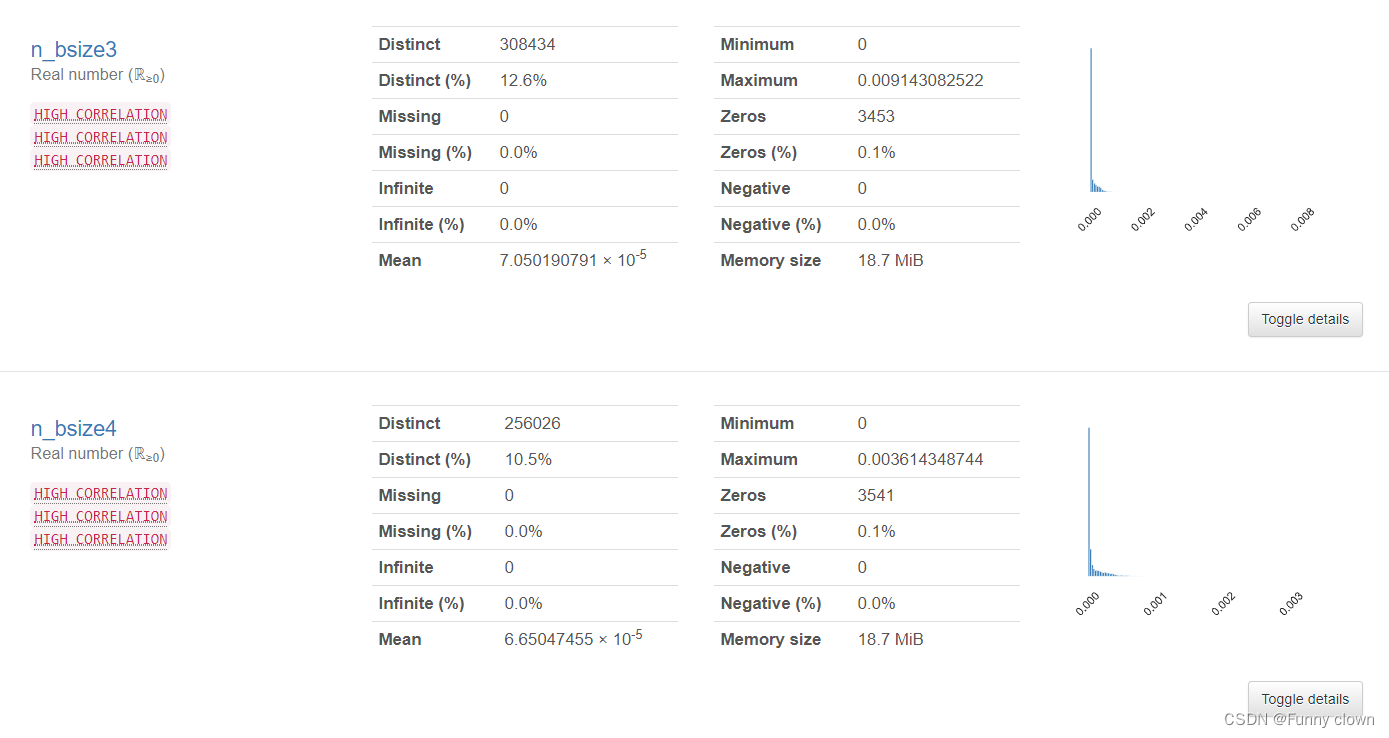
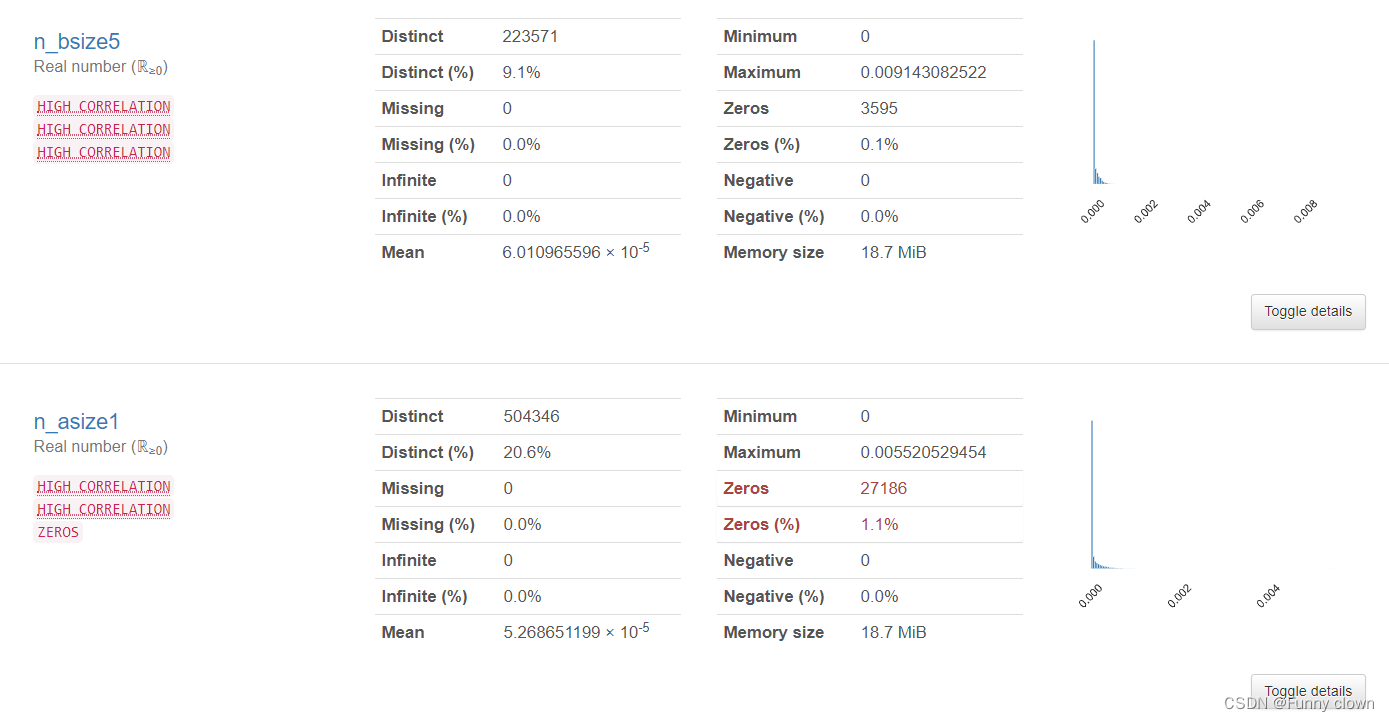
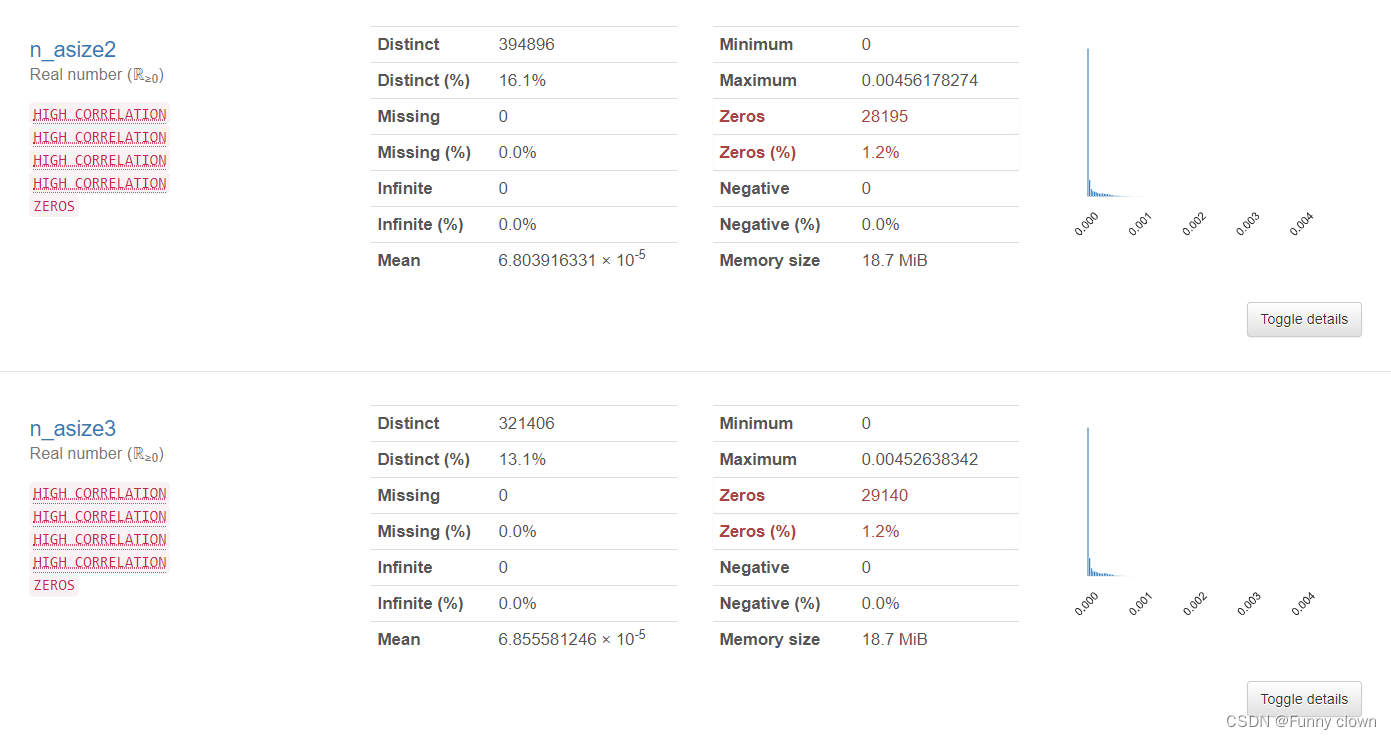
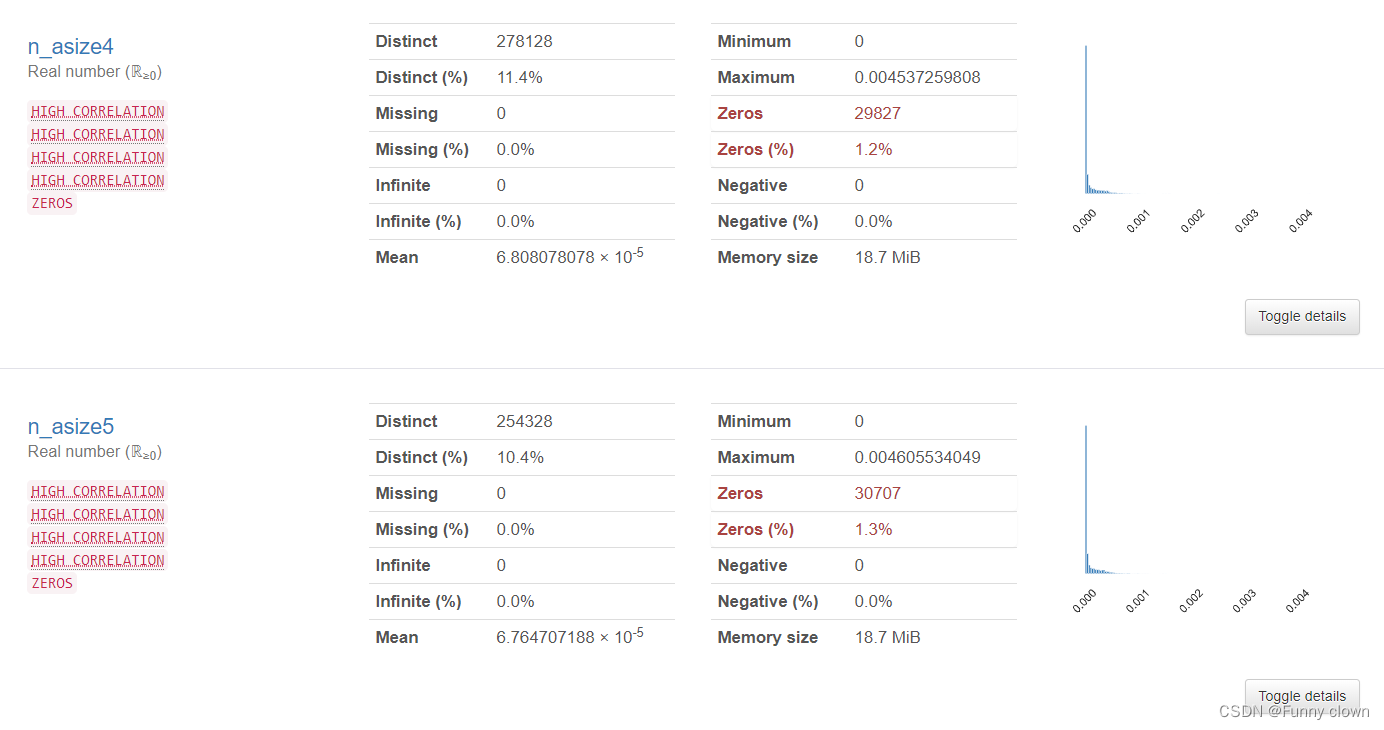
图4 买卖量特征统计分析图表
(3)、相关性分析:由于偏态数据的存在,选择对数据分布限制较小的斯皮尔曼相关系数对特征进行相关性分析。可以明显看出,中间价以及收盘价与买卖价存在着强线性相关性,卖价之间以及买价之间都有强线性相关性。除此之外,买卖量之间表现出了稍强的线性相关性,考虑此类特征拥有严重左偏的问题,首先要考虑将其融合为新特征并予以删除,若模型出现了欠拟合问题,再考虑增加该类特征。综上所述,该问题的预测需要全面的特征工程对其进行设计与改造。

图5 Spearman相关系数热力图(忽略右下角5*5目标特征)
(4)、初步特征工程:根据特征相关性分析发现,部分特征之间存在明显的线性关系。因此,需要进一步筛选并融合相应特征。其中,中间价为买一价和卖一价的均值,图5也显示出了三者较强的线性相关性,因此可以尝试以中间价代替买一价与卖一价。同时,吸纳Baseline的经验,尝试将严重偏态且互相具有较强线性相关性的买卖量特征数据融入到加权平均价格当中,改善其数据分布并排除较强相关性。其中,计算公式中的
为极小常系数,避免分母为0。
(5)、训练集与验证集分割:根据该题目参与者的反映,最终的测试集与本地交叉验证效果出现了极大的反差,即出现了较强的过拟合现象。因此,采取分割验证集,以验证集得分尽可能的规避训练集与测试集间的过拟合现象。由于数据量极大,因此采用大数据集分割经验——98%为训练集,2%为验证集。
(6)、模型验证:采用Baseline中提及的Catboost模型进行训练及交叉验证。在初步尝试过程中可以明显看出“label_60”目标变量的预测效果高于其他目标,因此可以应用该标签作为评判准则。与其他参与者出现的情况不同,笔者的模型未出现过拟合现象,而是出现了欠拟合现象,即训练集交叉验证得分与验证集得分相差很小但整体偏低。(iterations=1000,depth=15,learning_rate=0.01)

图6 Catboost模型初步验证
经过适当缩小学习率、提高树深、提高迭代次数等方式增加模型复杂度,训练集交叉验证得分及验证集得分从0.49提高至了0.57。然而,模型仍然表现出了明显的欠拟合。这是由于初步特征工程阶段对特征进行了大量删除,因此可以考虑初步特征工程中提及的方案,增加线性相关性不是很强的买卖量特征至模型当中,模型能力得到较大提升。(iterations=800,depth=15,learning_rate=0.05)

图7 Catboost模型进一步验证
相比于手册的Baseline模型,最终提交成绩也没有突破0.5。因此,可以预知测试集数据与训练集数据的分布有些许差距,可以从时间相关的特征进一步探究与实验。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









